Downloaded 28 times










![Open transfer sockets vs. time[Image: Don Petravick, NCSA]](https://image.slidesharecdn.com/eresearchnzjune2011-110710083242-phpapp01/75/Accelerating-data-intensive-science-by-outsourcing-the-mundane-18-2048.jpg)




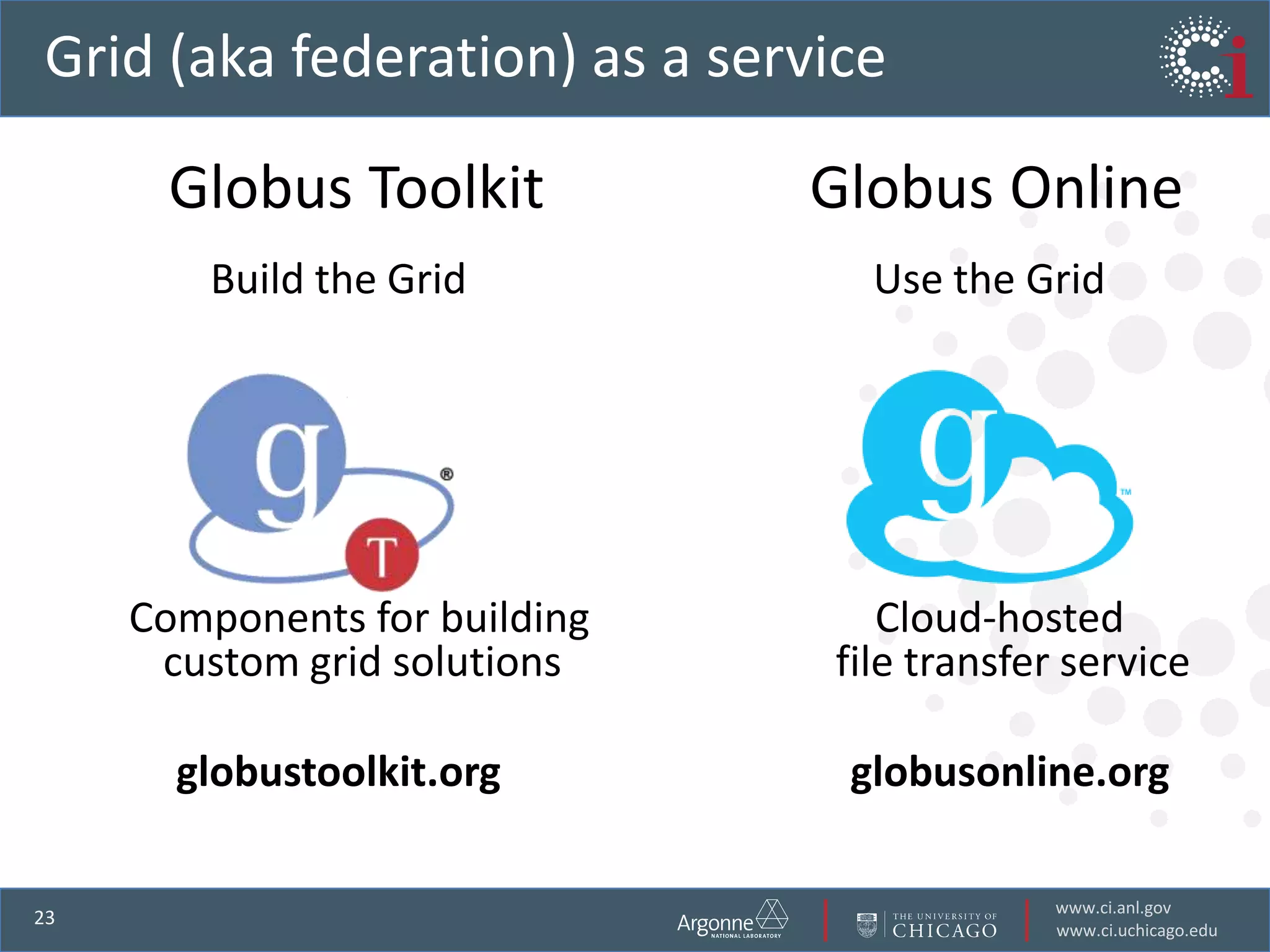
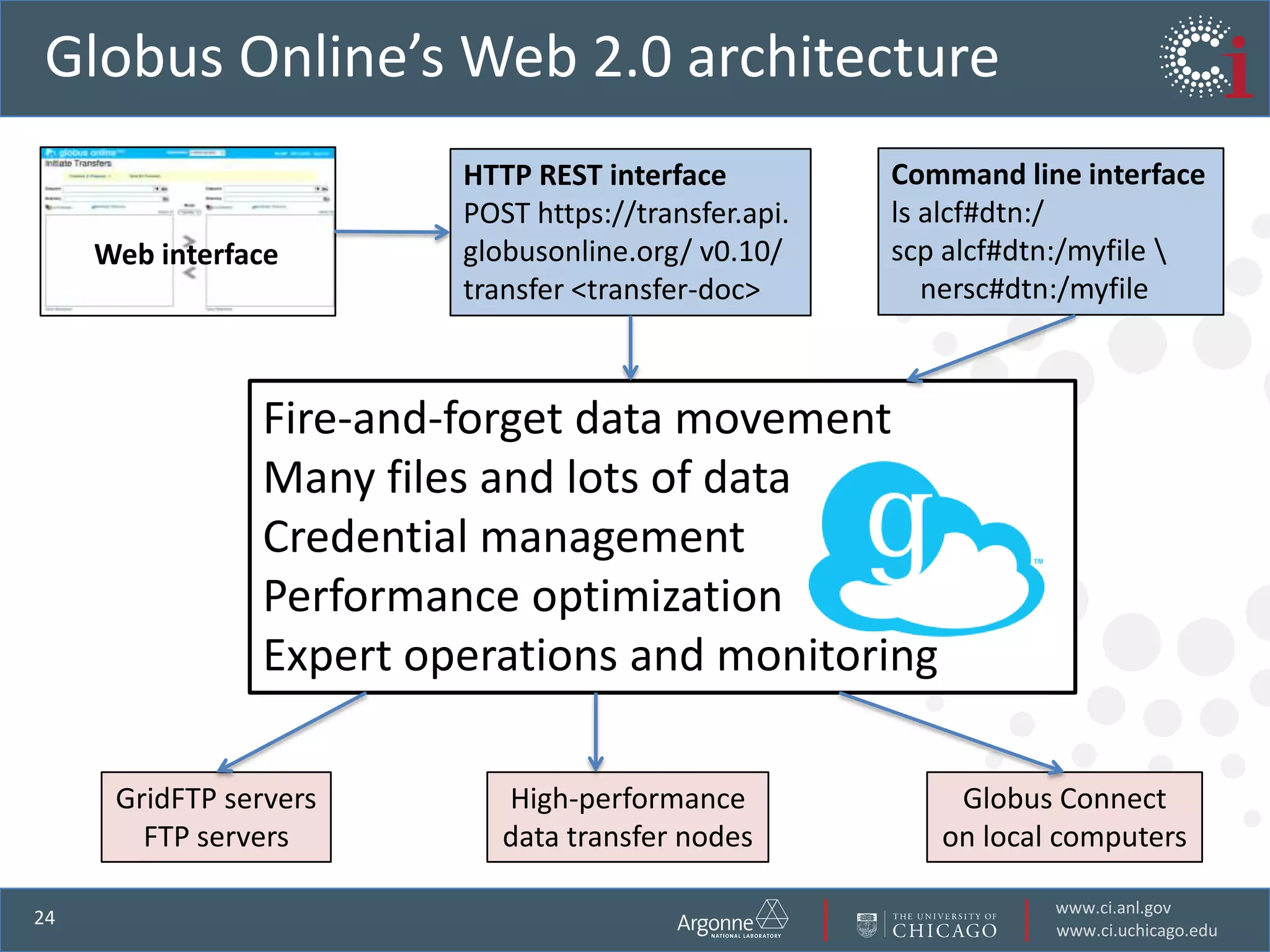
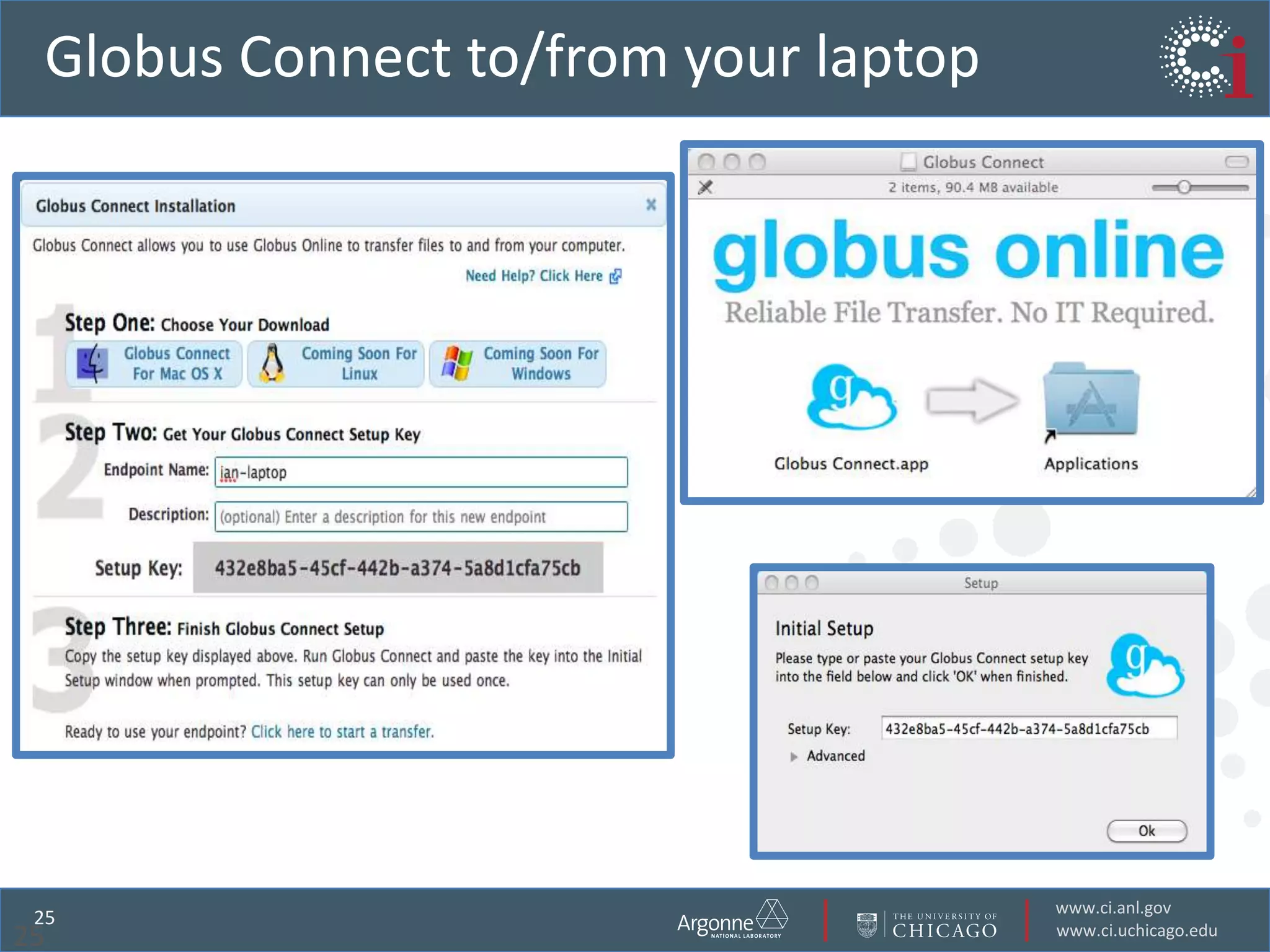
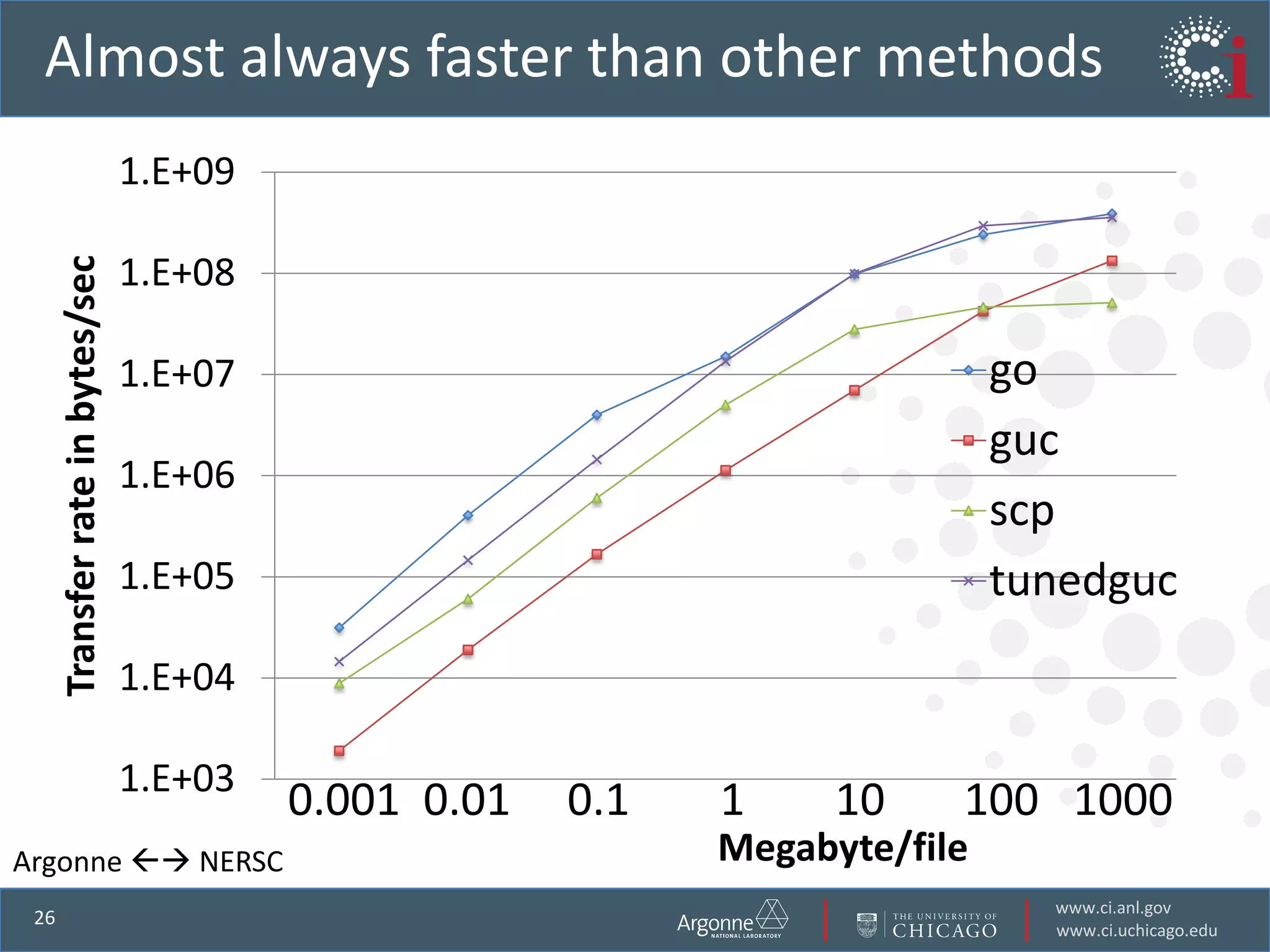
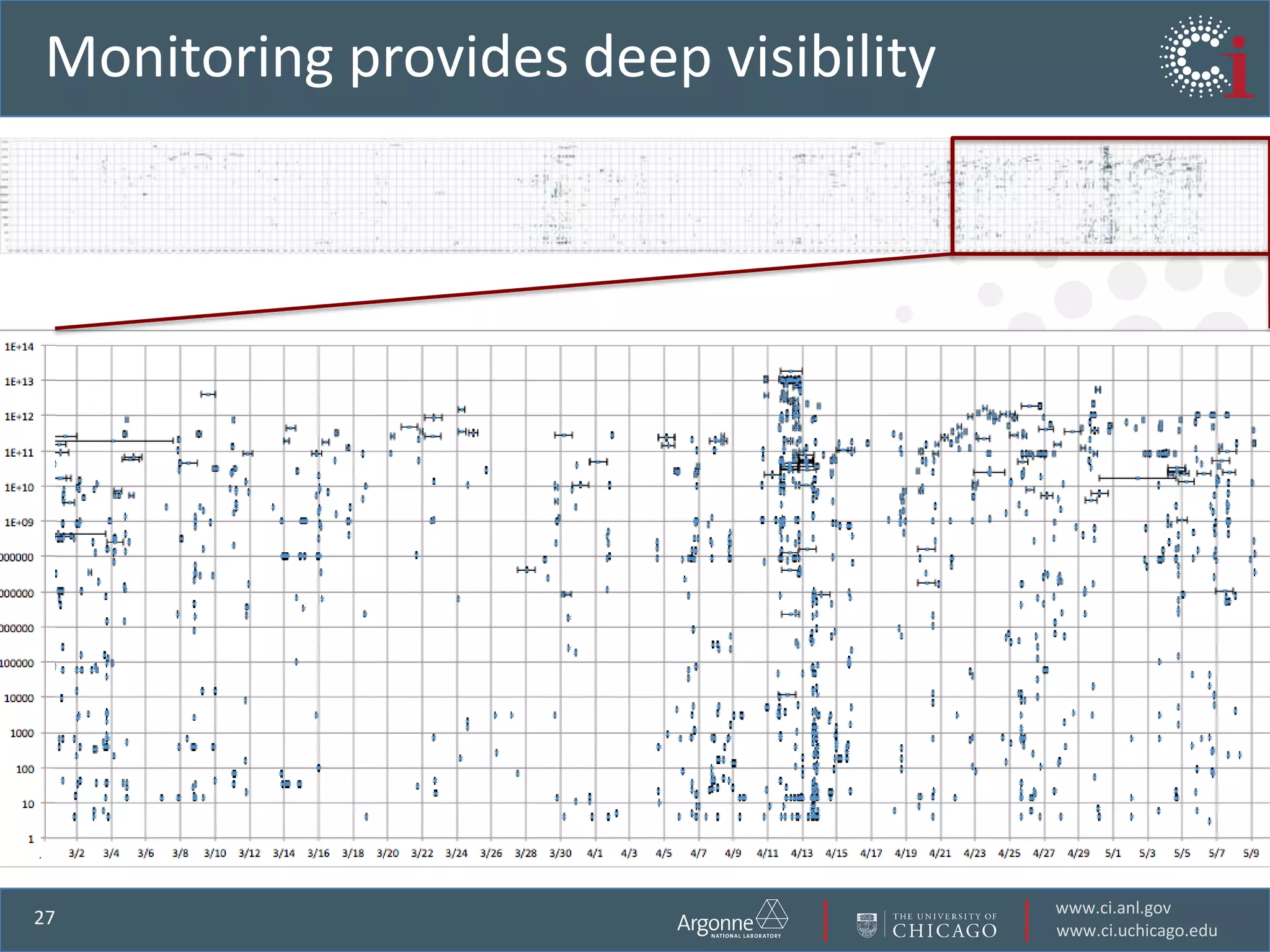

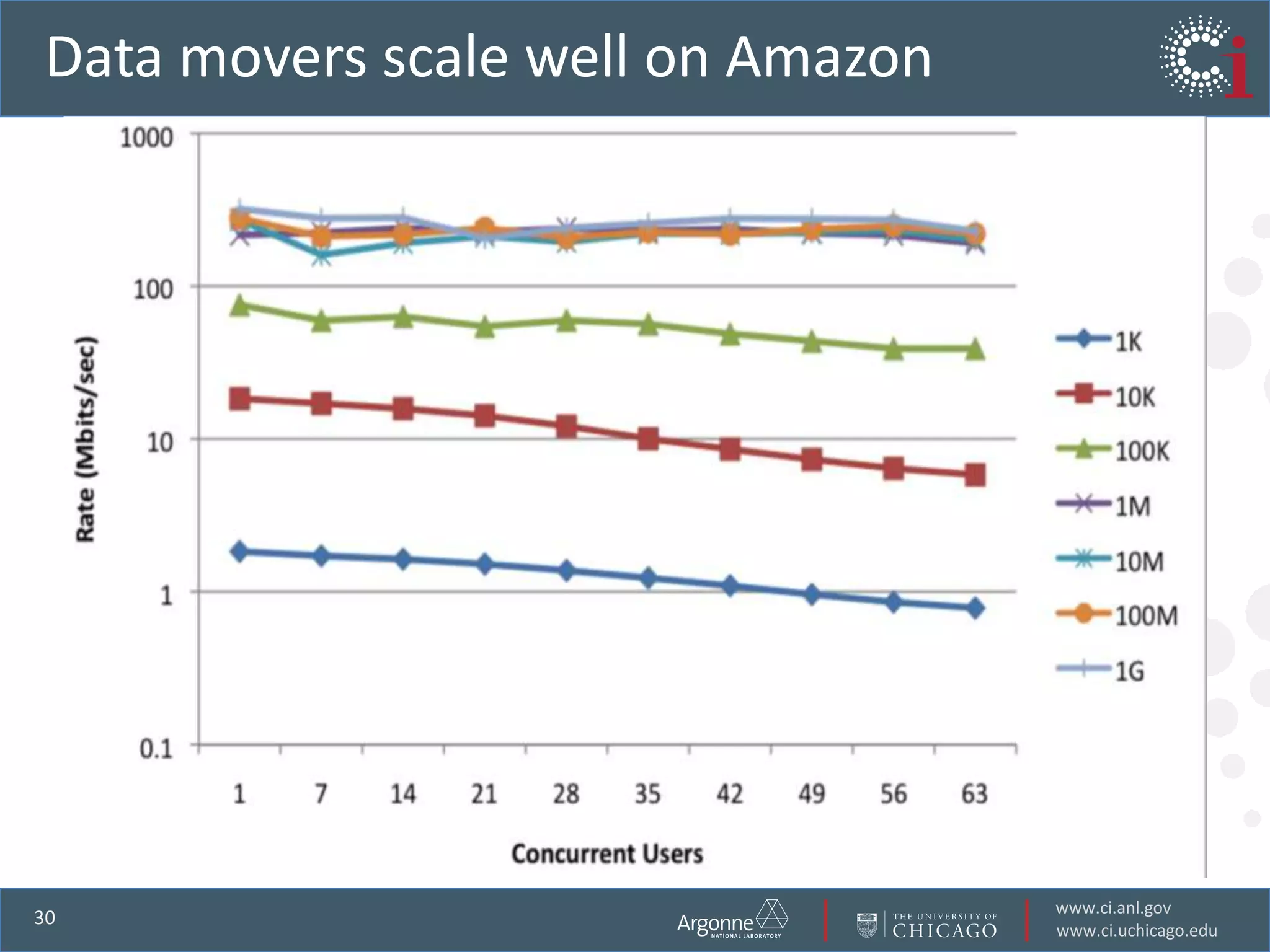
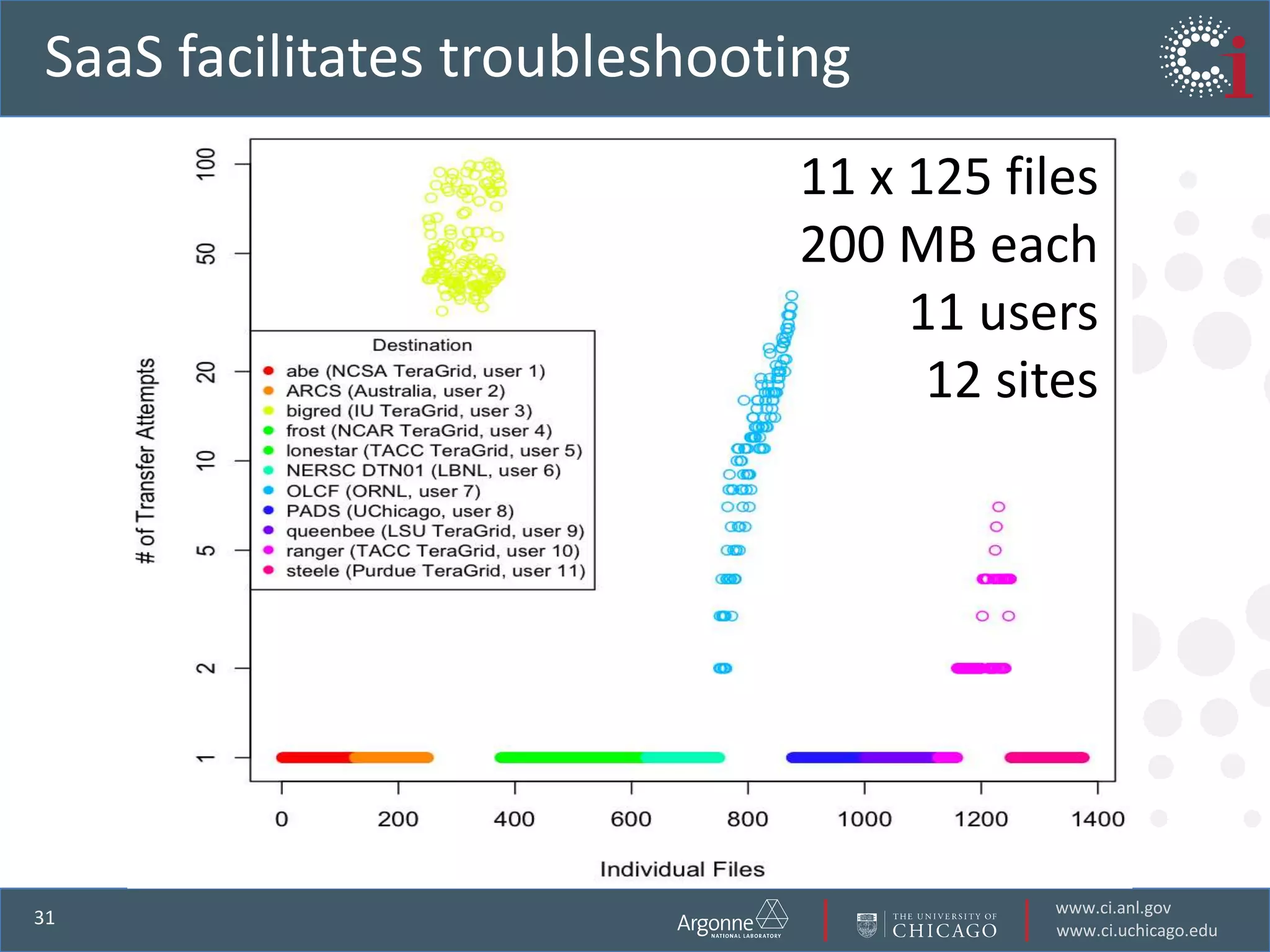
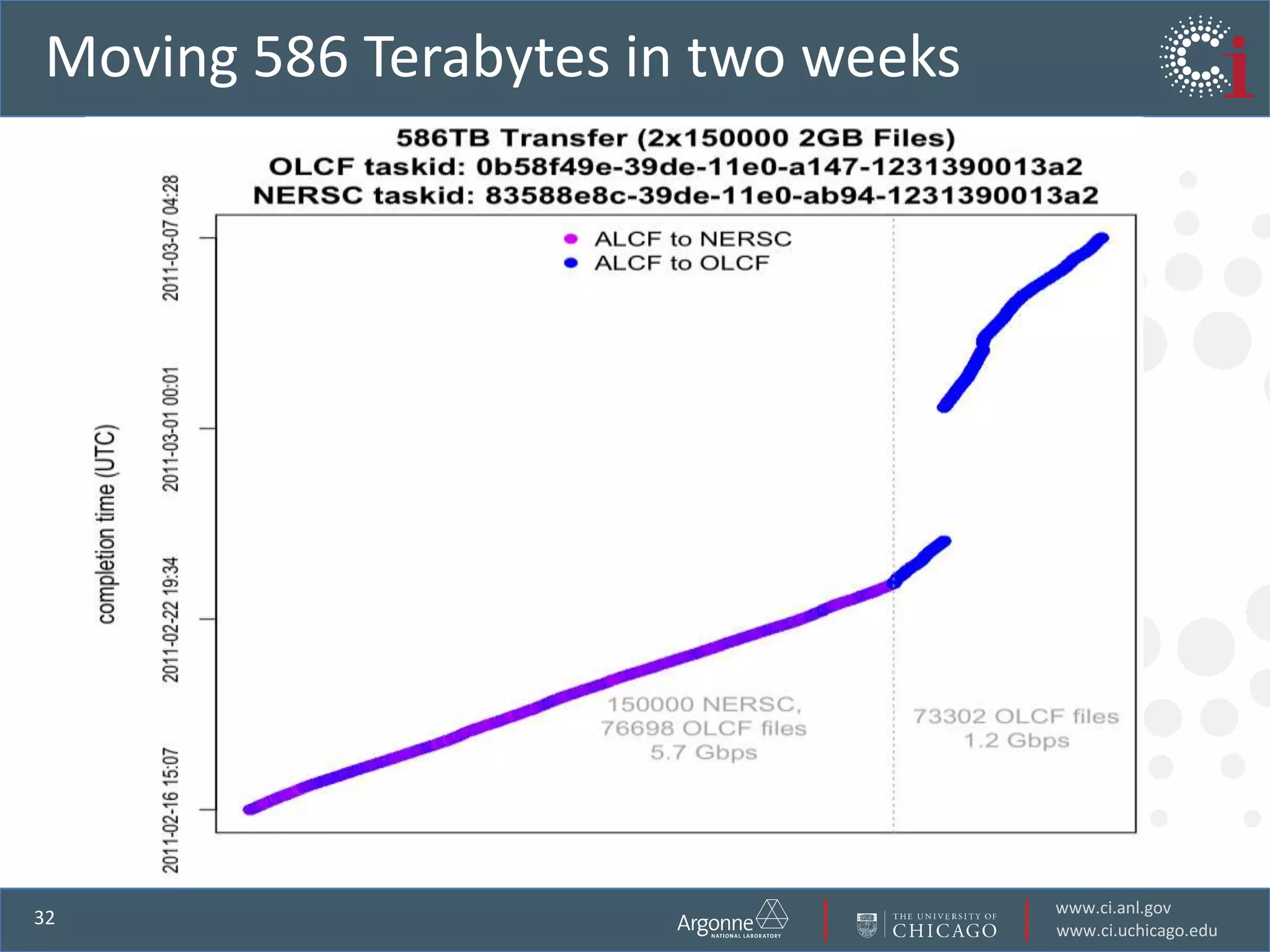
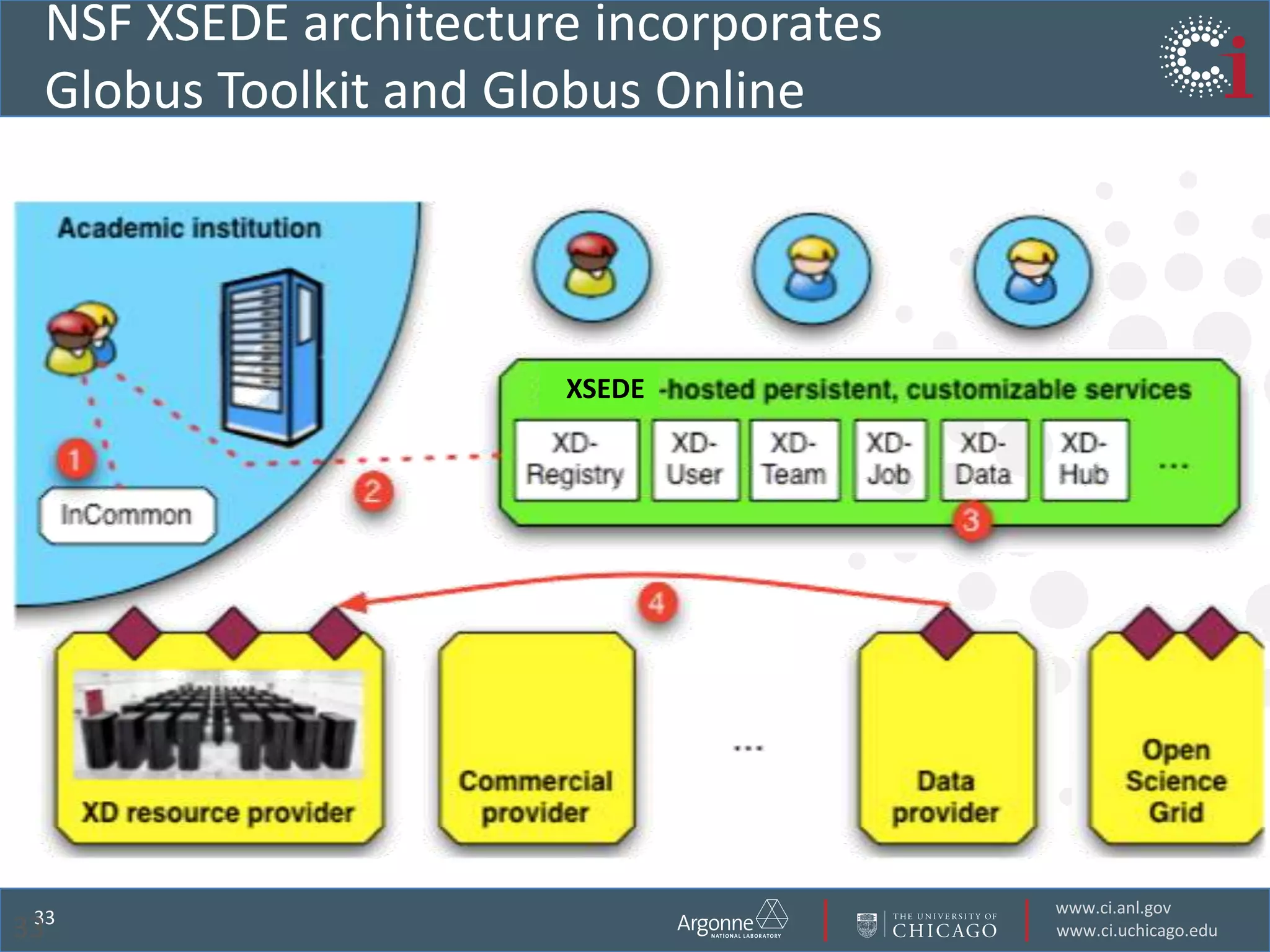
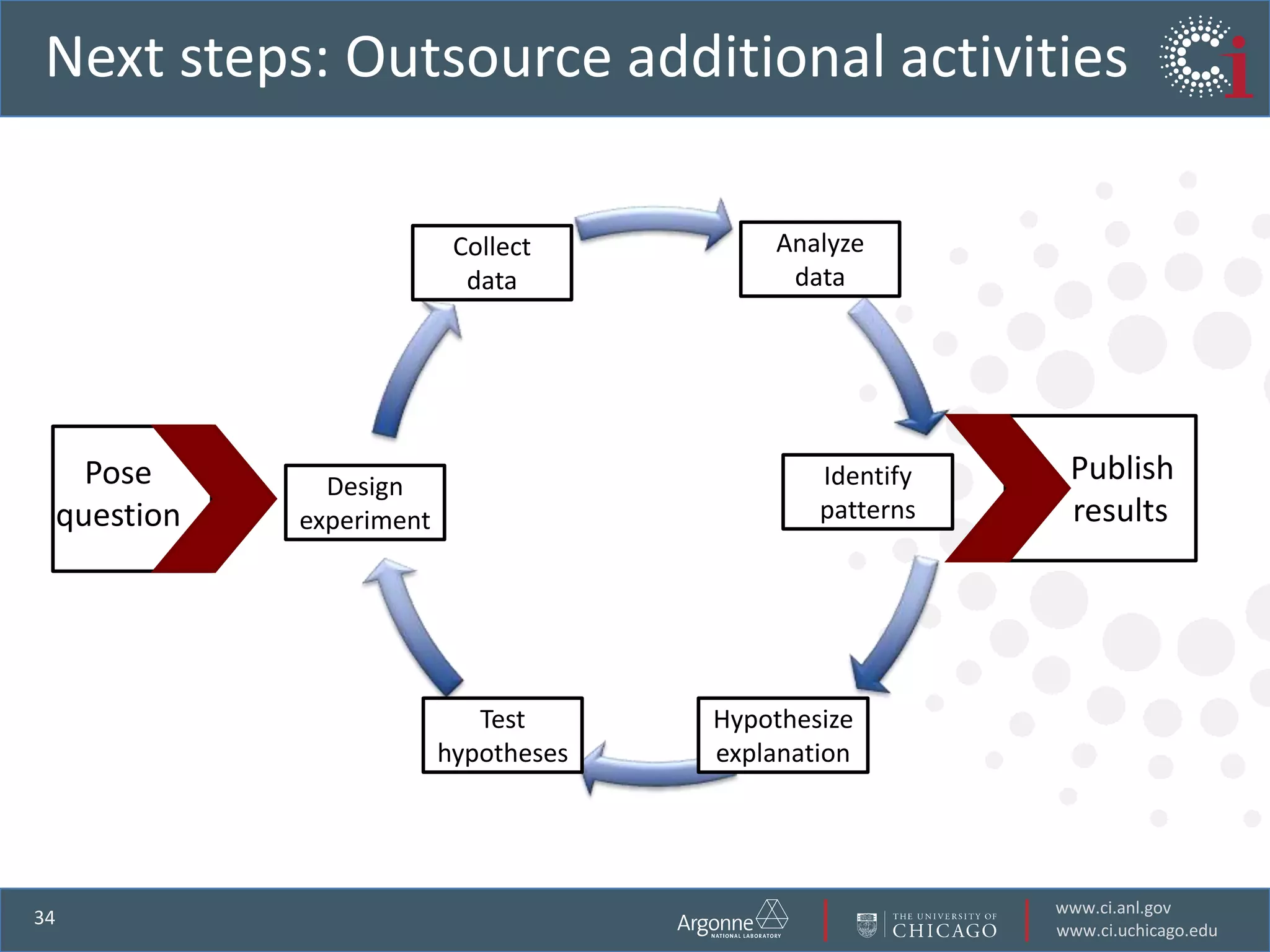







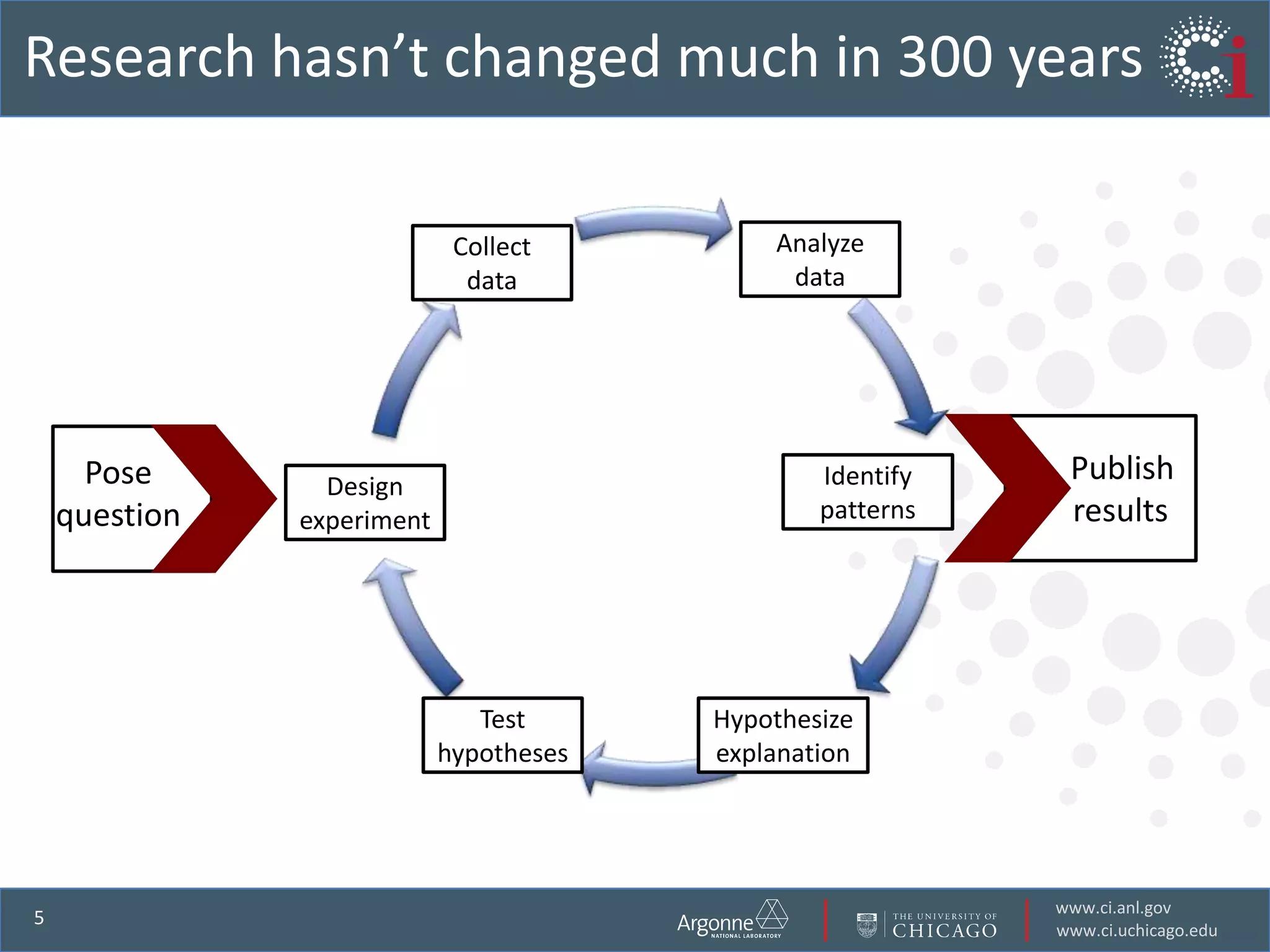
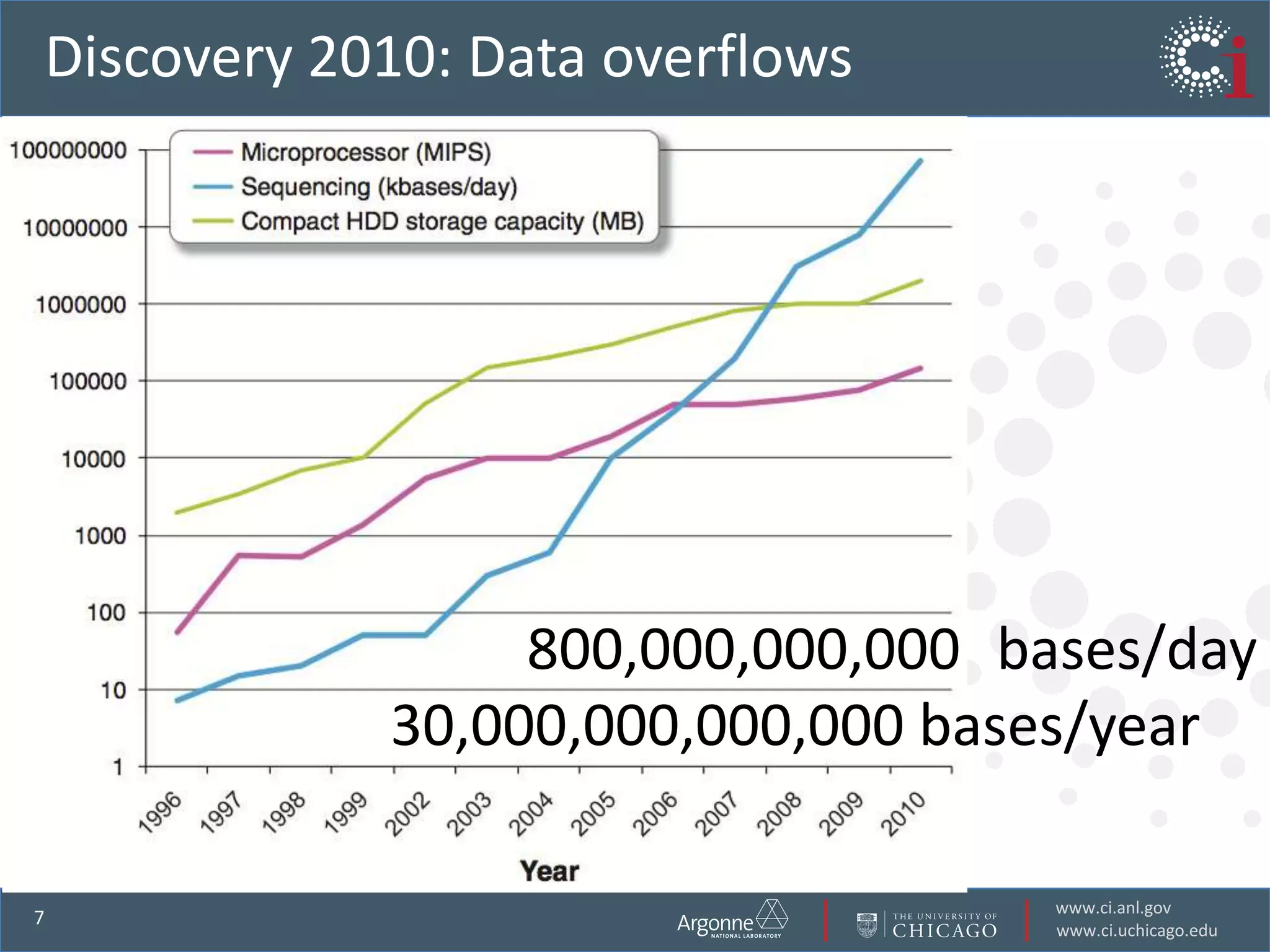
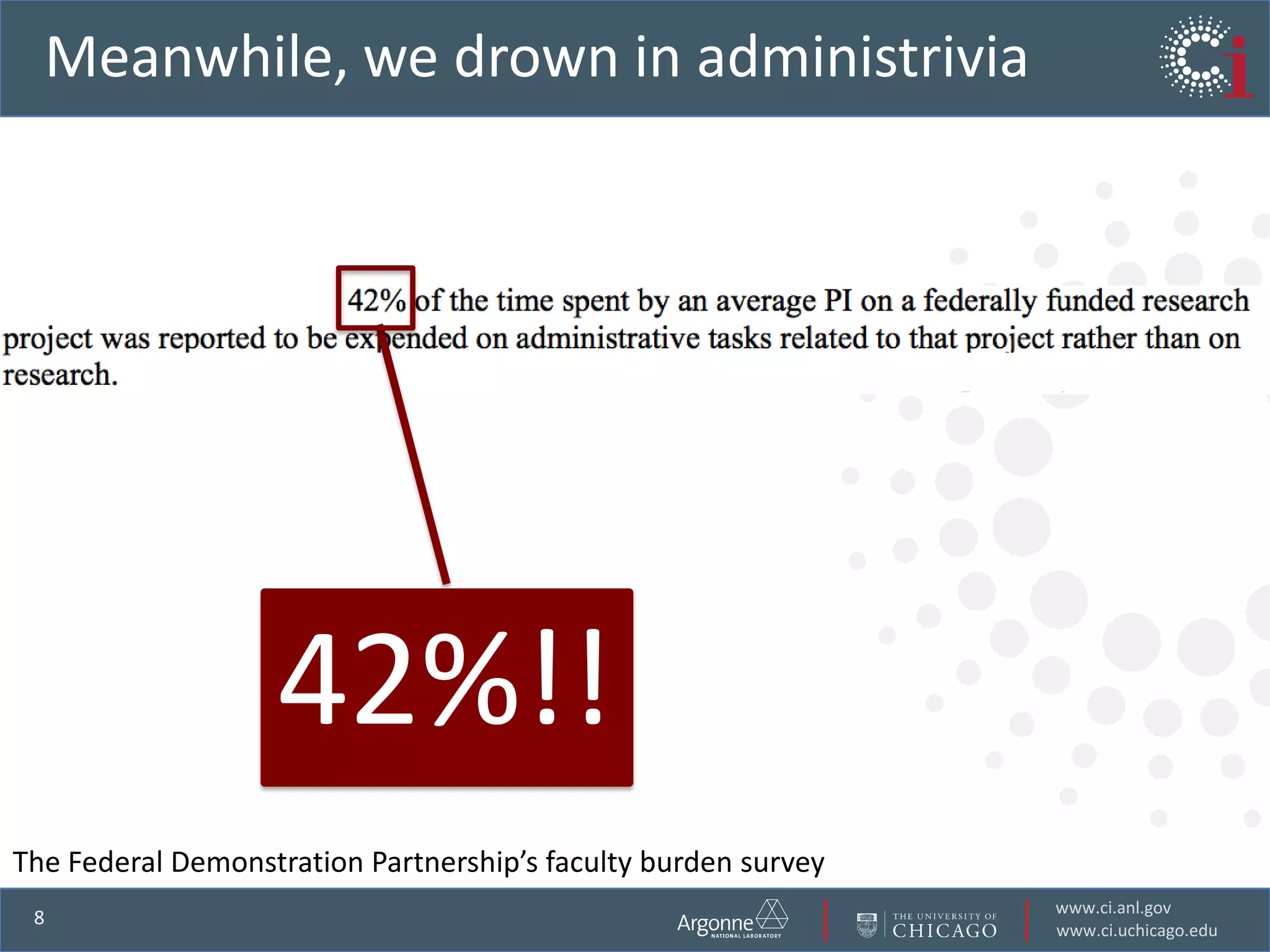
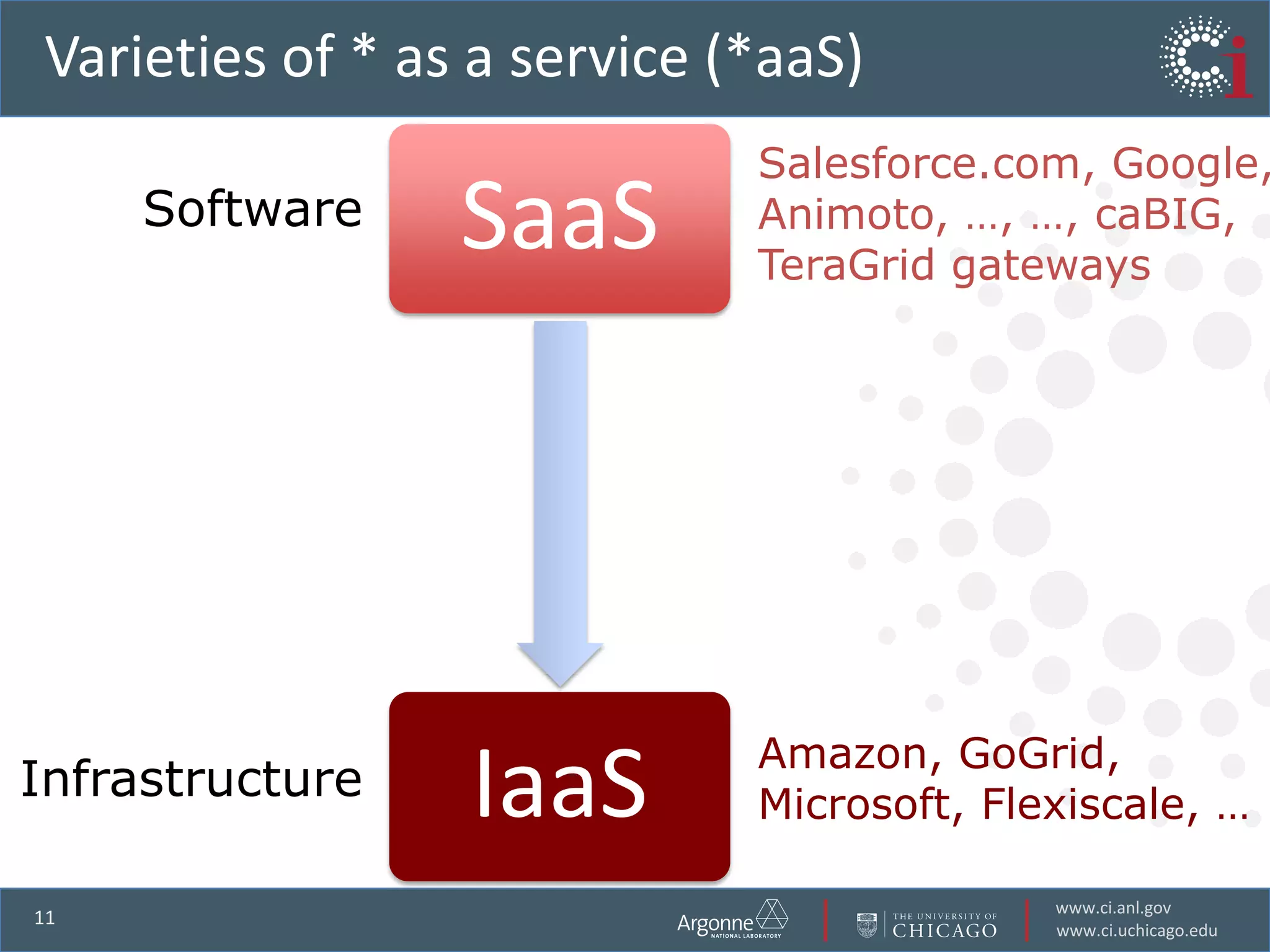
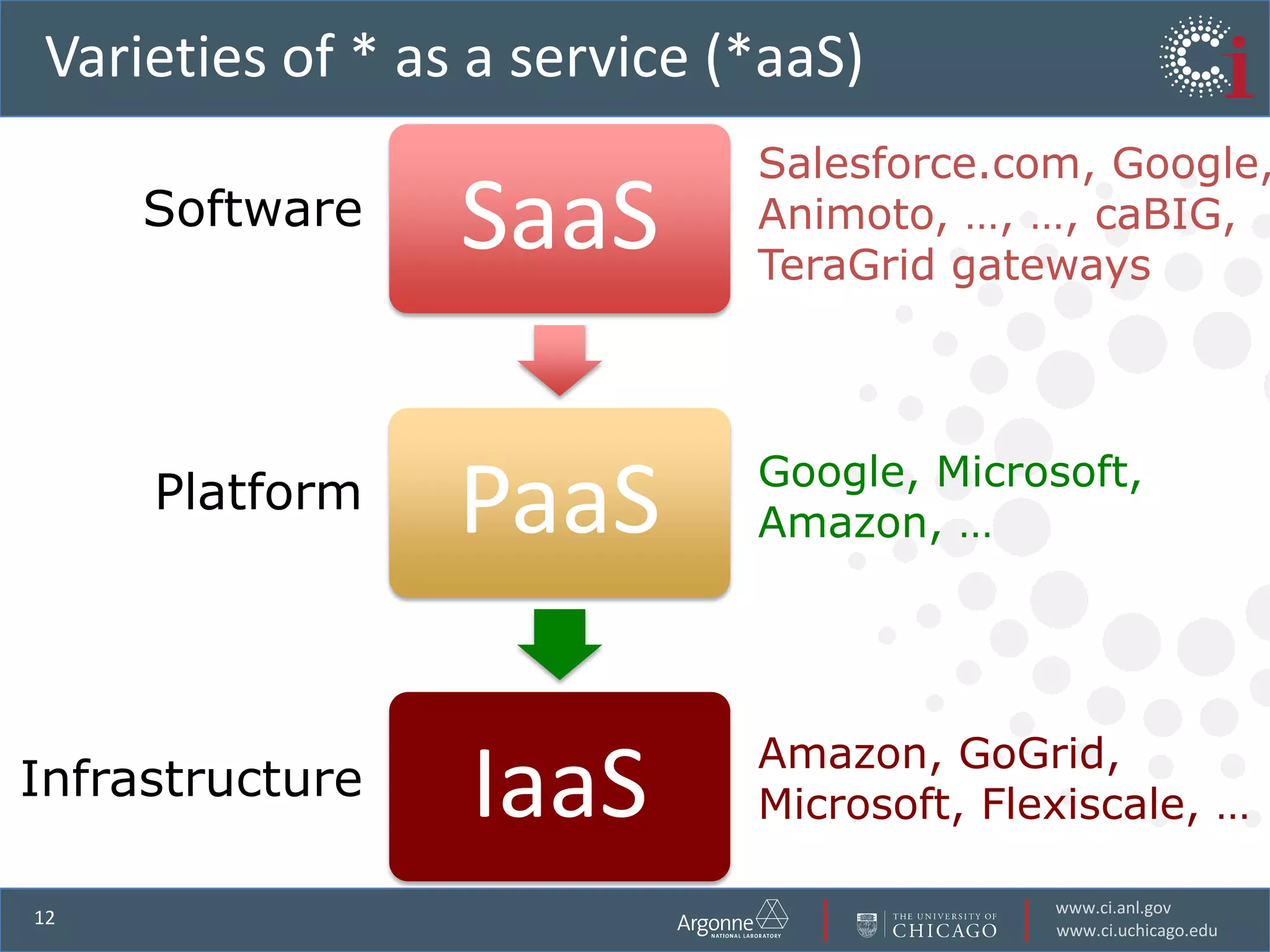
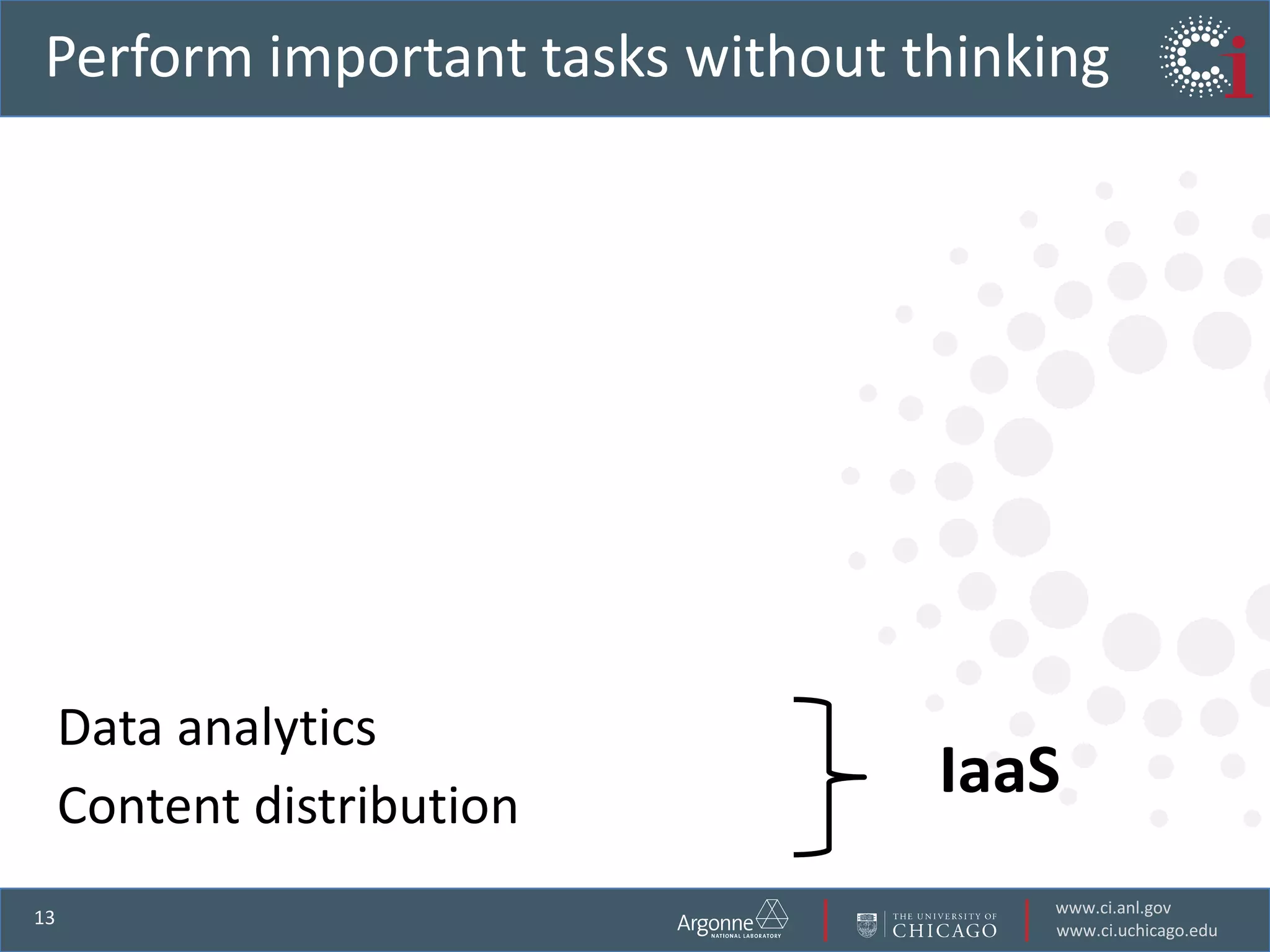
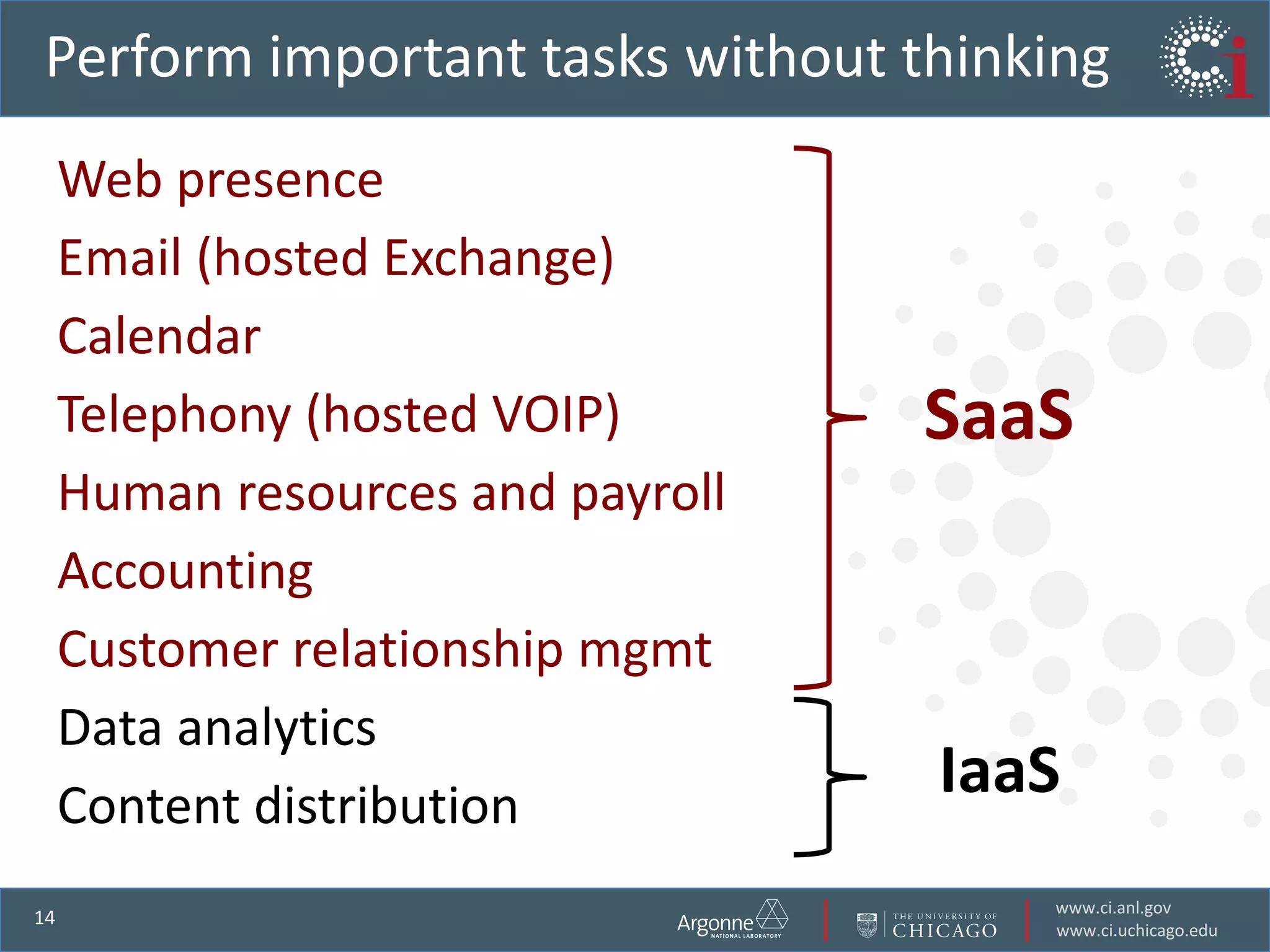
The document discusses the challenges in data-intensive science and the potential of outsourcing mundane research tasks through Software-as-a-Service (SaaS) solutions. It highlights how automation can accelerate discovery by reducing the time researchers spend on administrative tasks and data handling. The Globus Online platform is presented as an example of leveraging cloud services to streamline data movement and enhance research efficiency.











































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











