Download as PDF, PPTX


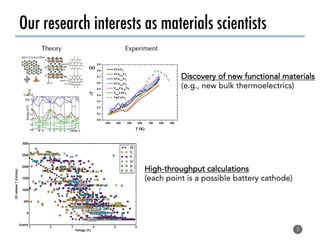





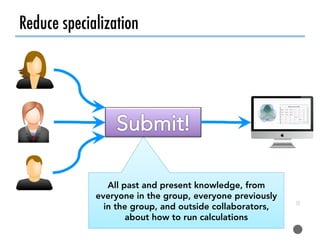

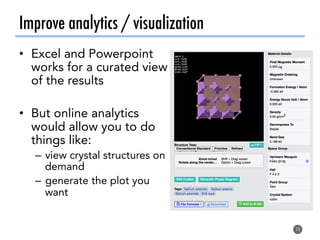

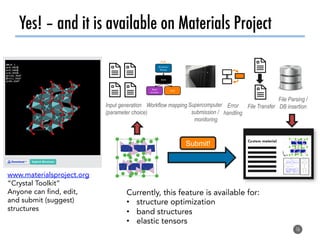
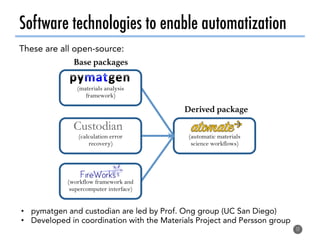
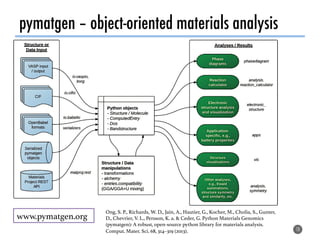
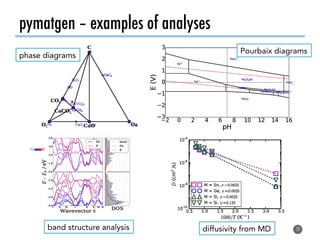
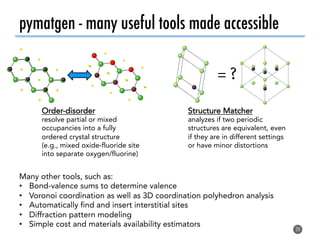
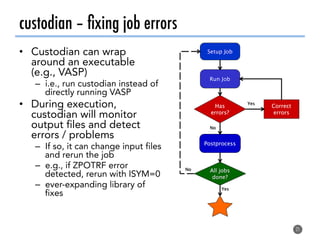


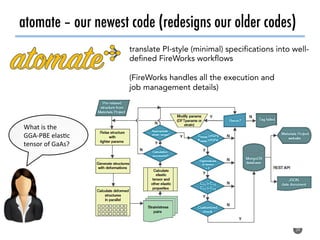







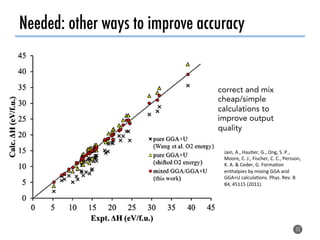
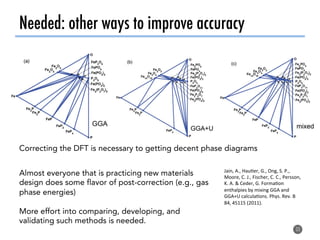






The document discusses software tools to facilitate materials science research, noting that the author's group works to standardize and automate computational methods for high-throughput calculations and discovery of new functional materials. It advocates for developing automated workflows and analysis frameworks to reduce errors, improve efficiency, and enable non-experts to easily conduct complex simulations and analyses through intuitive online interfaces. The goal is to make advanced computational materials science accessible to a wider audience.











































































































