Downloaded 38 times



![4
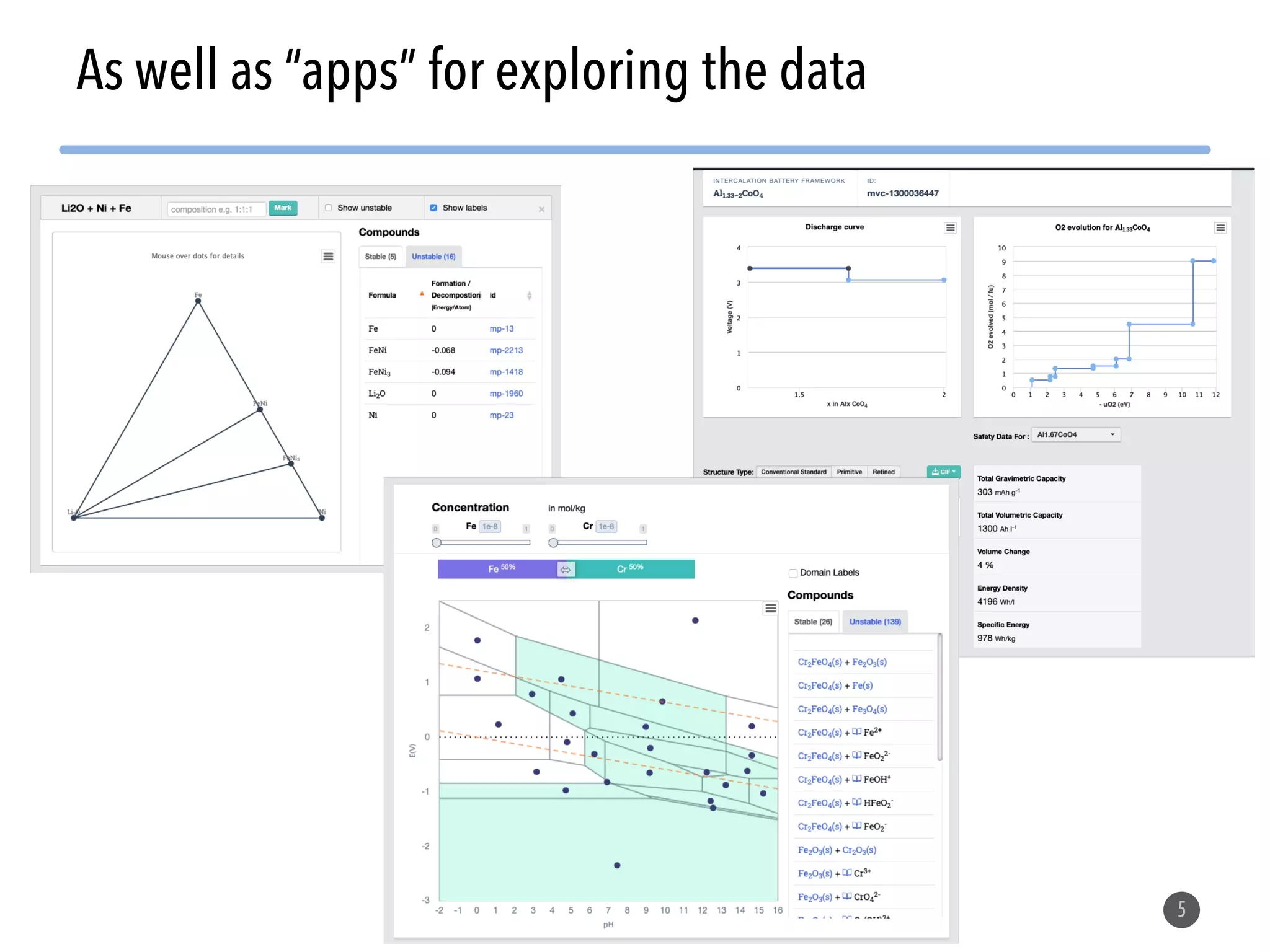
Many data sets are available!
M. De Jong et
al. Sci. Data,
2015, 2,
150009.
]
M. De Jong et
al. Sci. Data,
2015, 2,
150009.](https://image.slidesharecdn.com/20181115presentationdei-181115164217/75/Materials-Project-computation-and-database-infrastructure-4-2048.jpg)







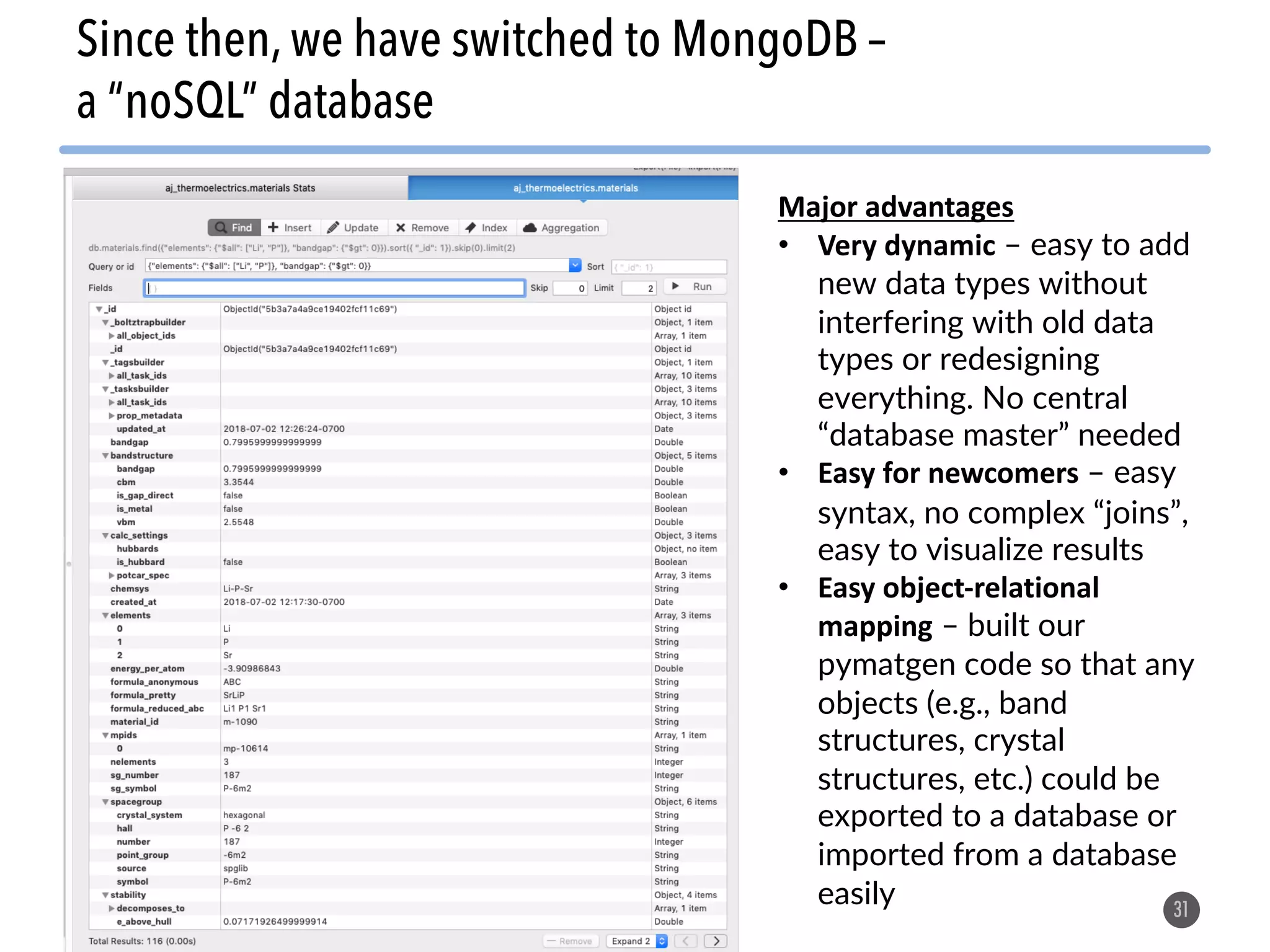
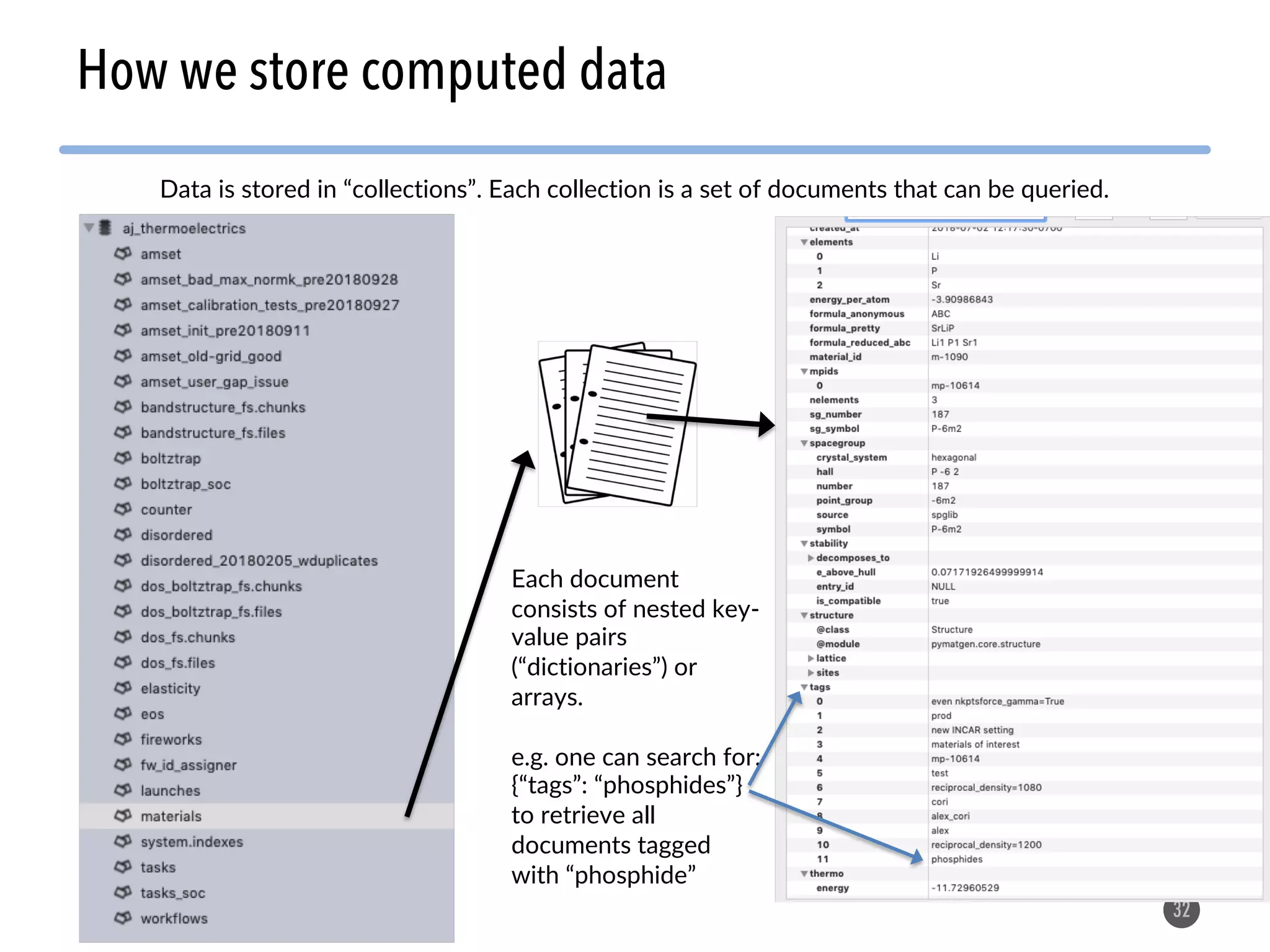

![1. As described previously: for each data type (a
“material”, “task”, “workflow”, etc.) decide on a
set of fields that describe each instance of that
data type. In MongoDB, these fields can easily
be changed or added to later if needed.
2. Try to create a single collection and document
format that can handle any kind of materials
data!
– example 1: “PIF” file format from Citrine[1]
– example 2: MPContribs from Materials Project[2]
34
Two approaches to store data in MongoDB
[1] J. O’Mara, B. Meredig, K. Michel, Materials Data
Infrastructure : A Case Study of the Citrination Platform to
Examine Data Import , Storage , and Access, Jom. (2016).
[2] P. Huck, D. Gunter, S. Cholia, D. Winston, A.T. N’Diaye, K. Persson, User
applications driven by the community contribution framework MPContribs
in the Materials Project, Concurr. Comput. Pract. Exp. 22 (2015)](https://image.slidesharecdn.com/20181115presentationdei-181115164217/75/Materials-Project-computation-and-database-infrastructure-34-2048.jpg)

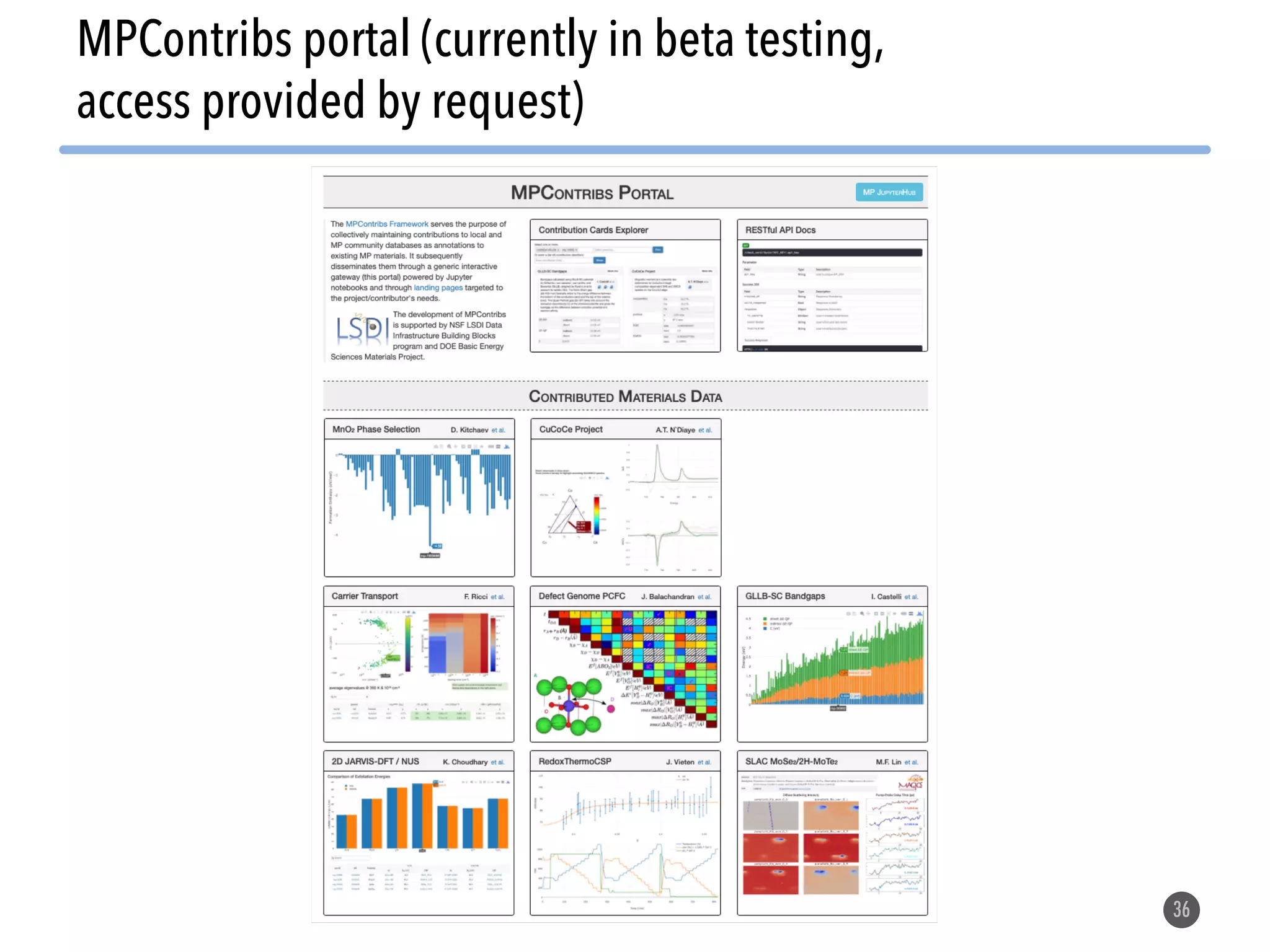


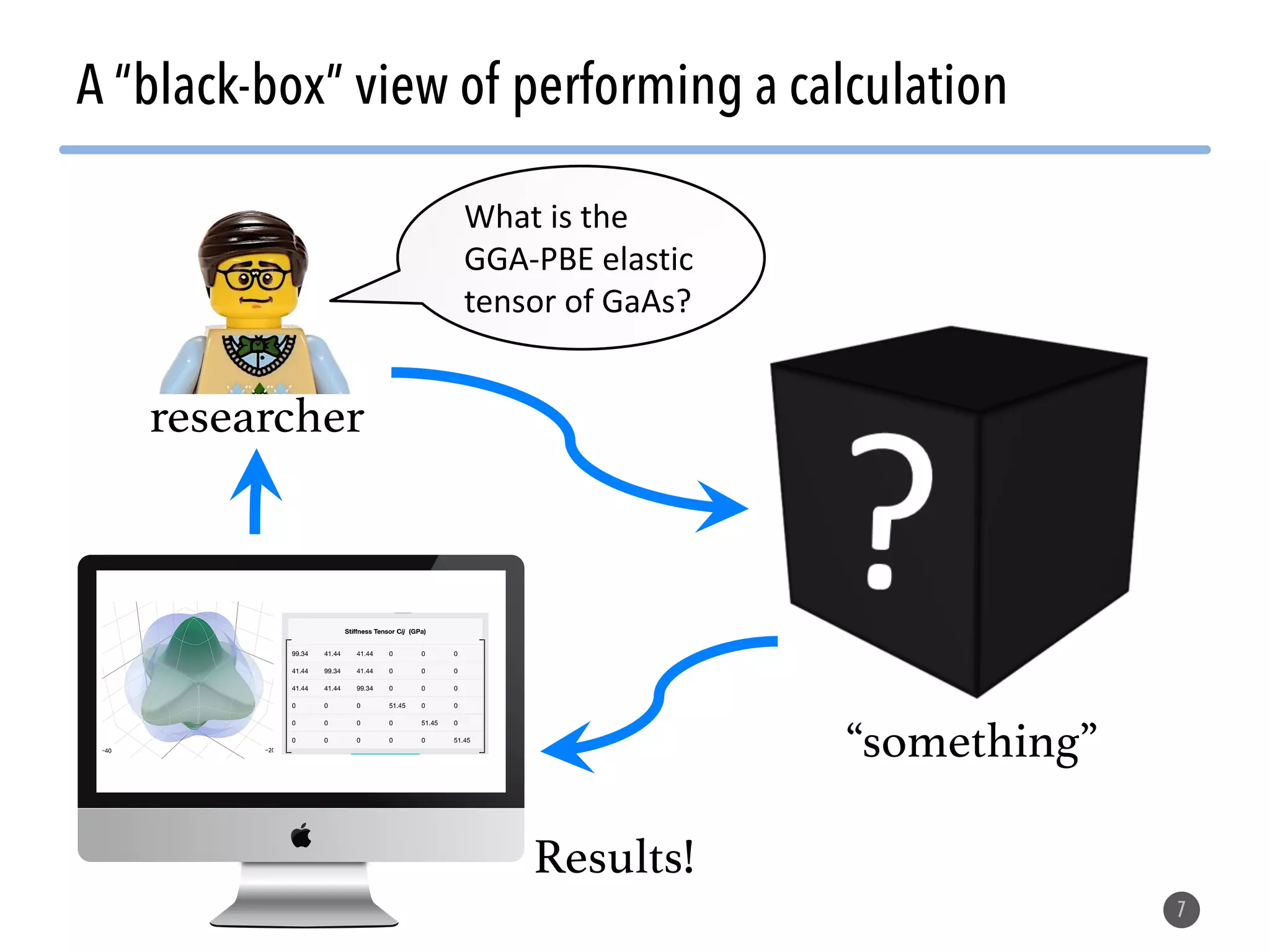
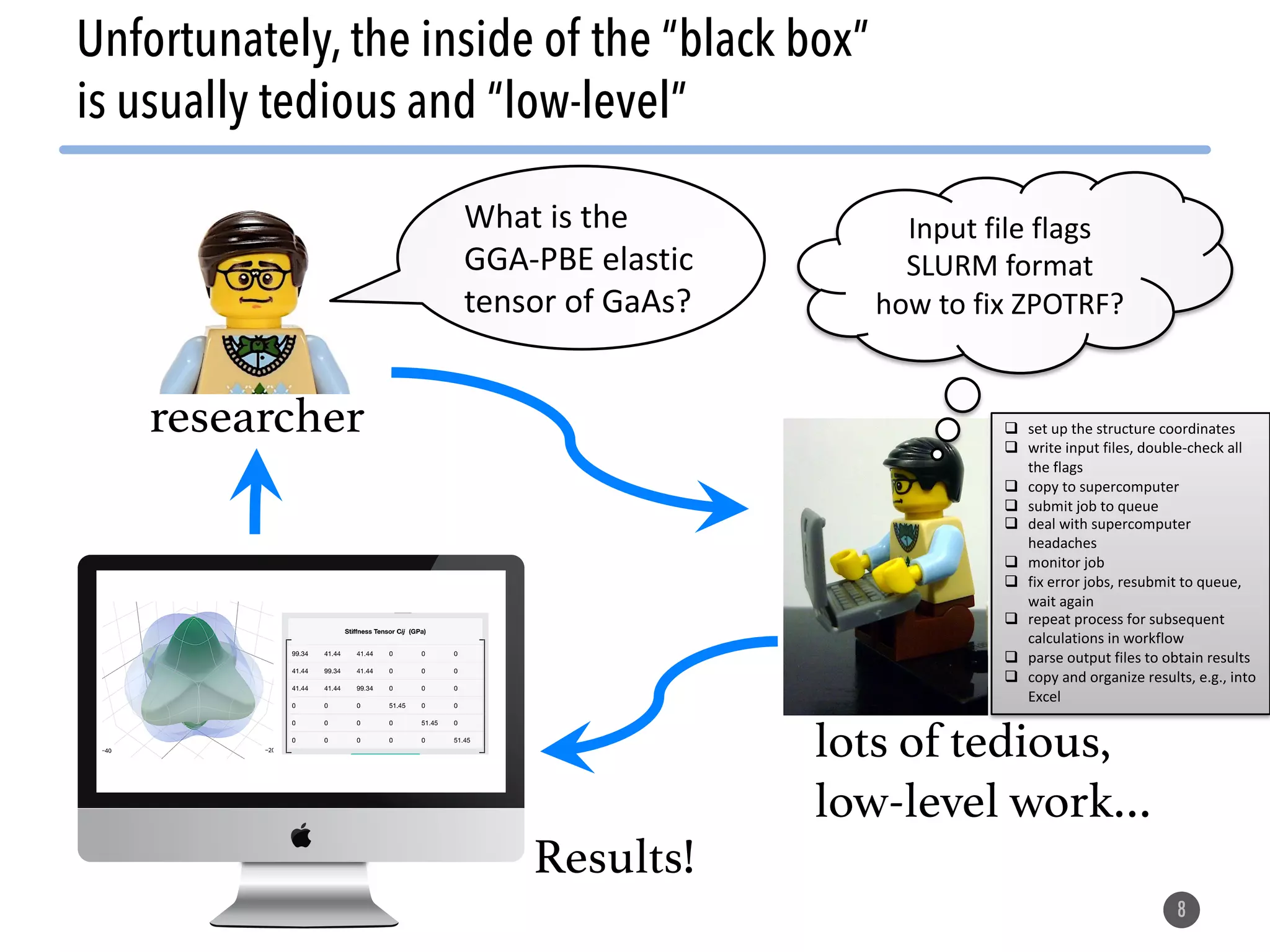
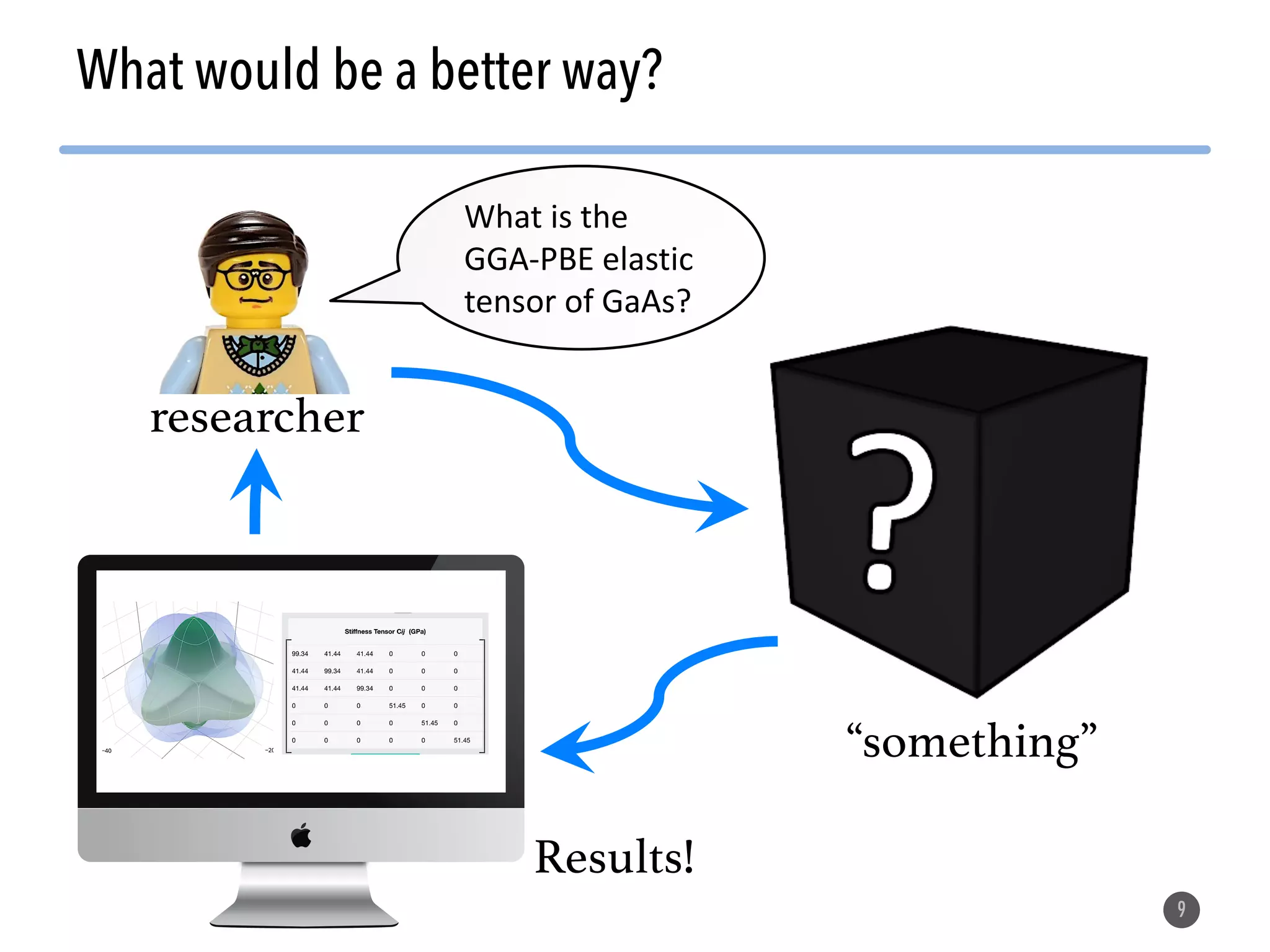
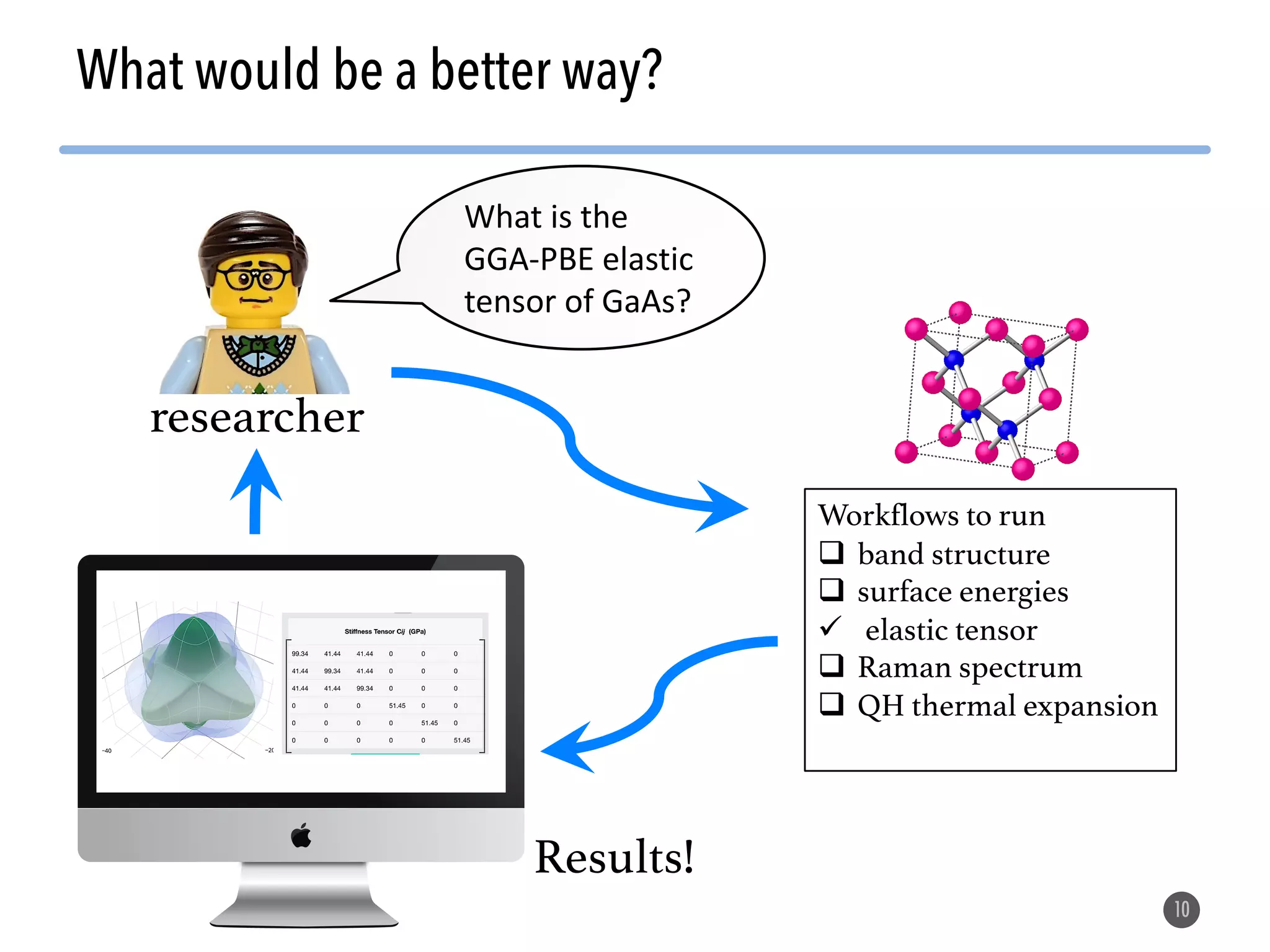
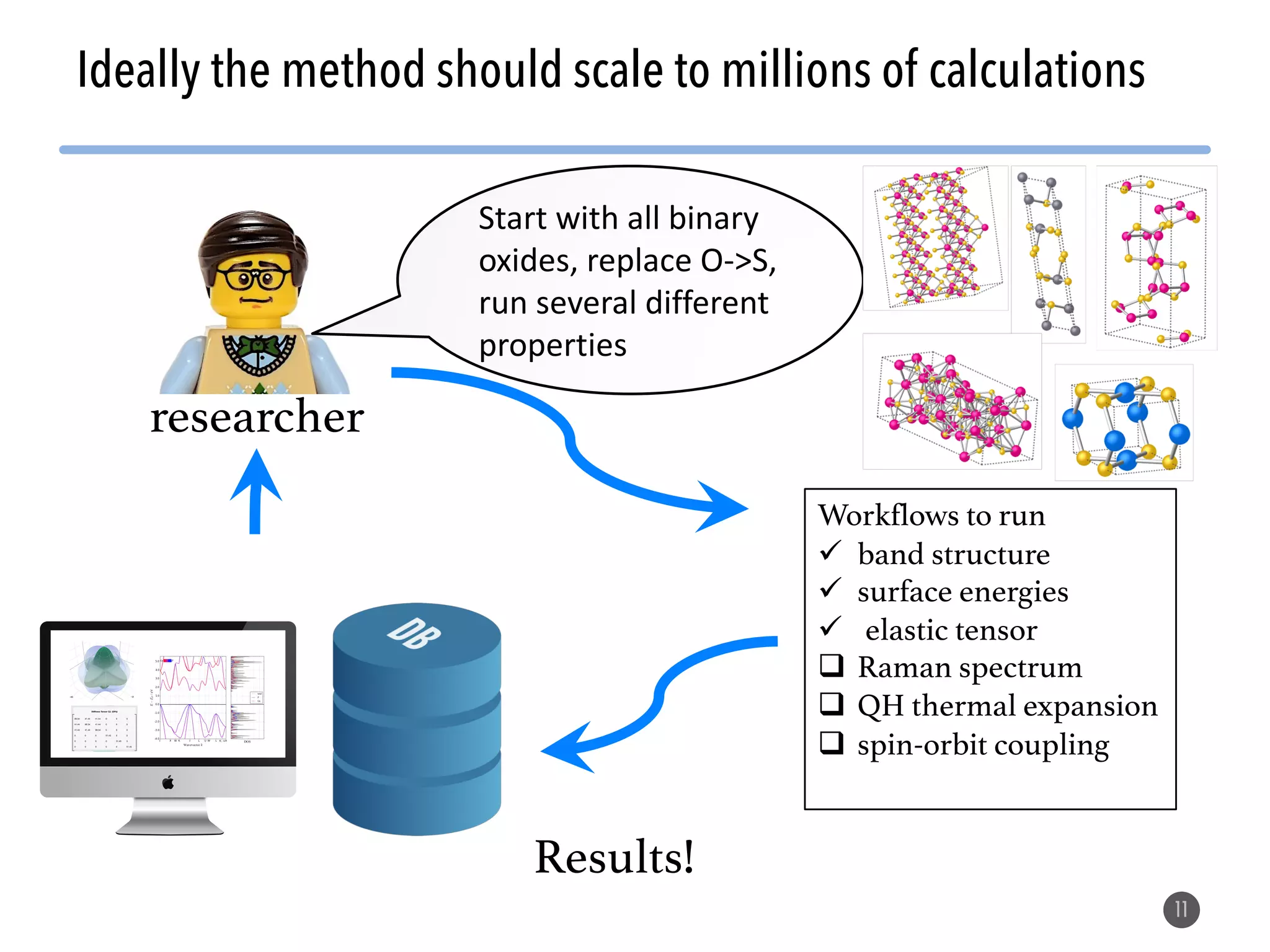
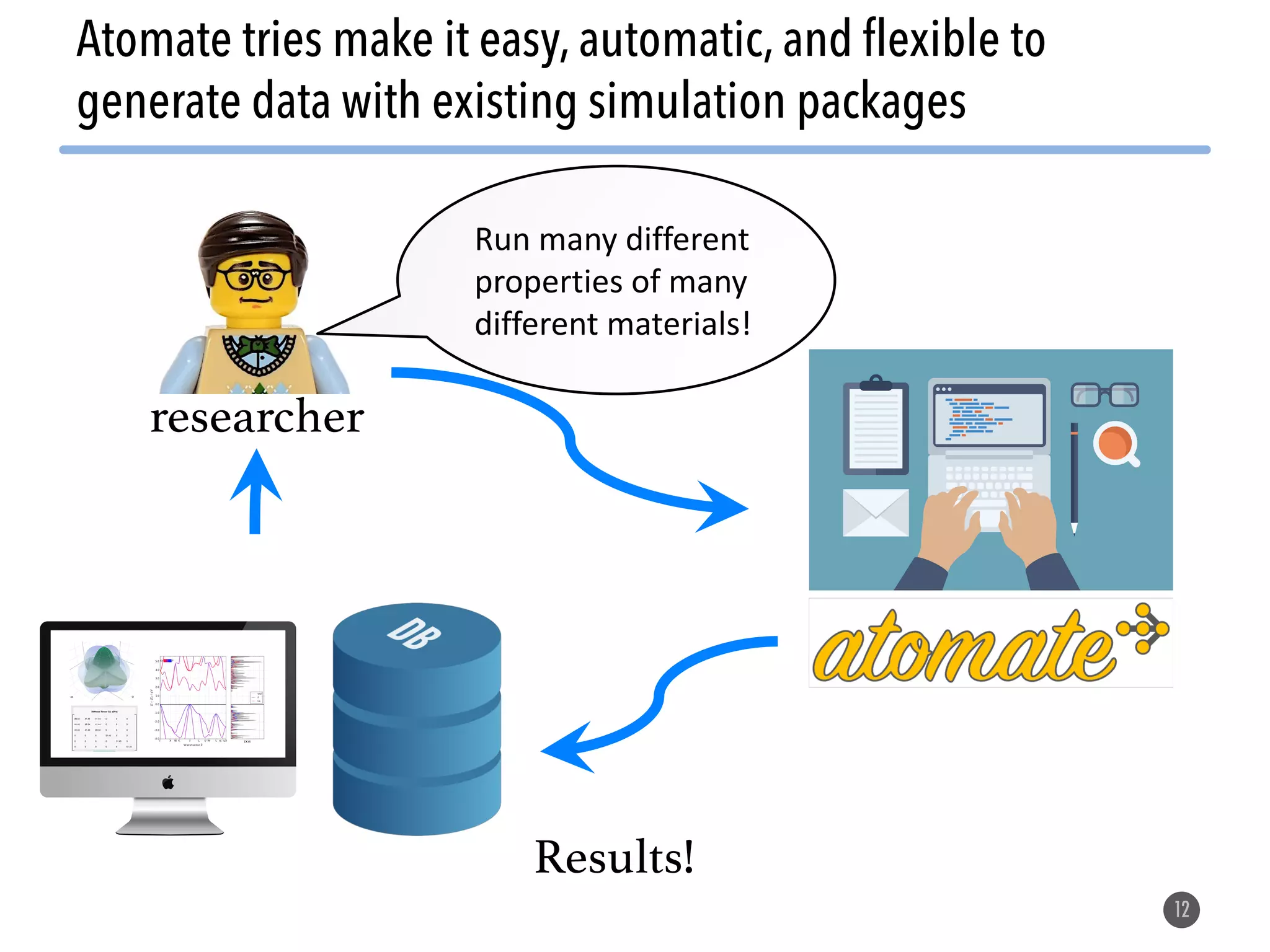
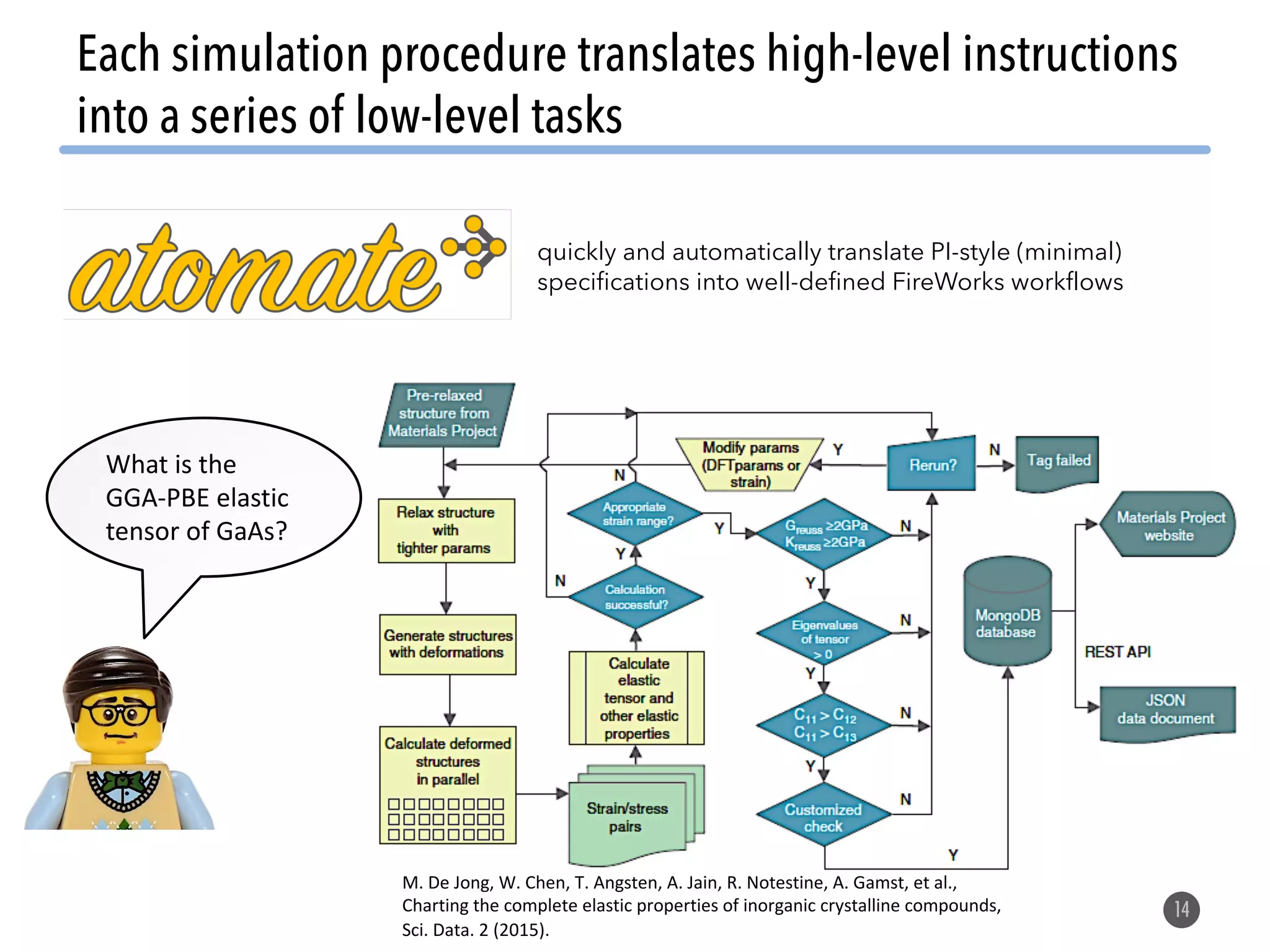
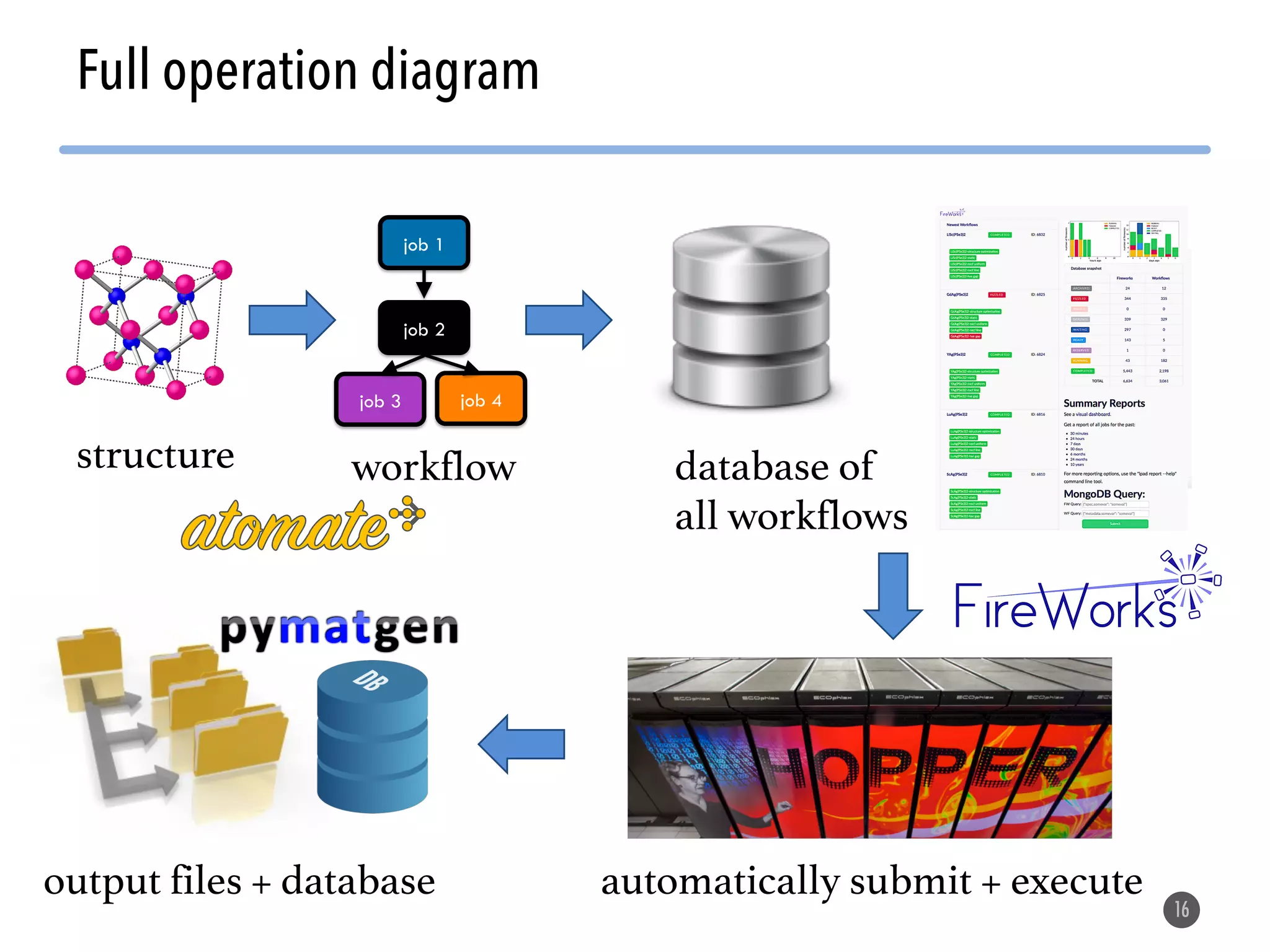
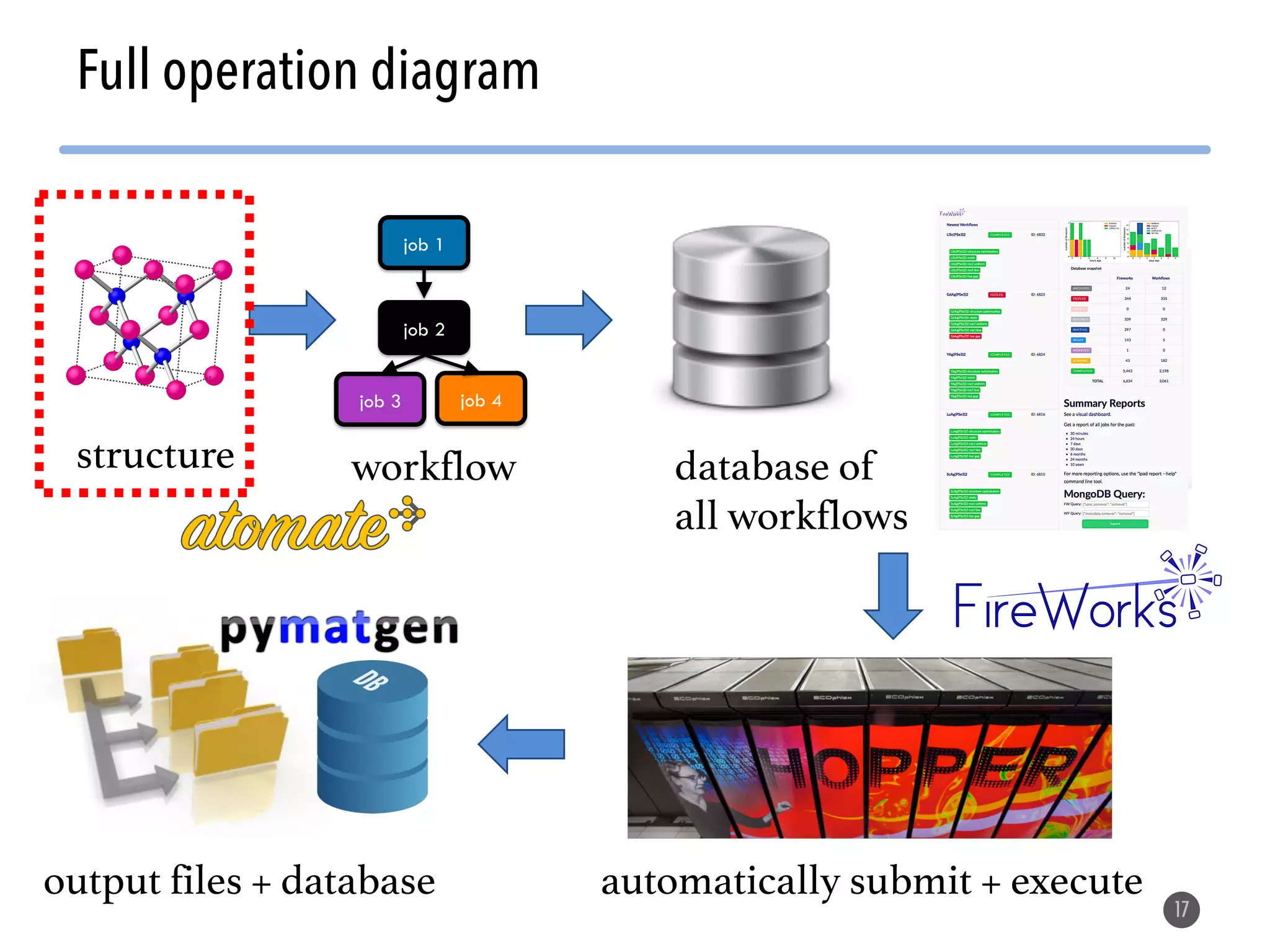
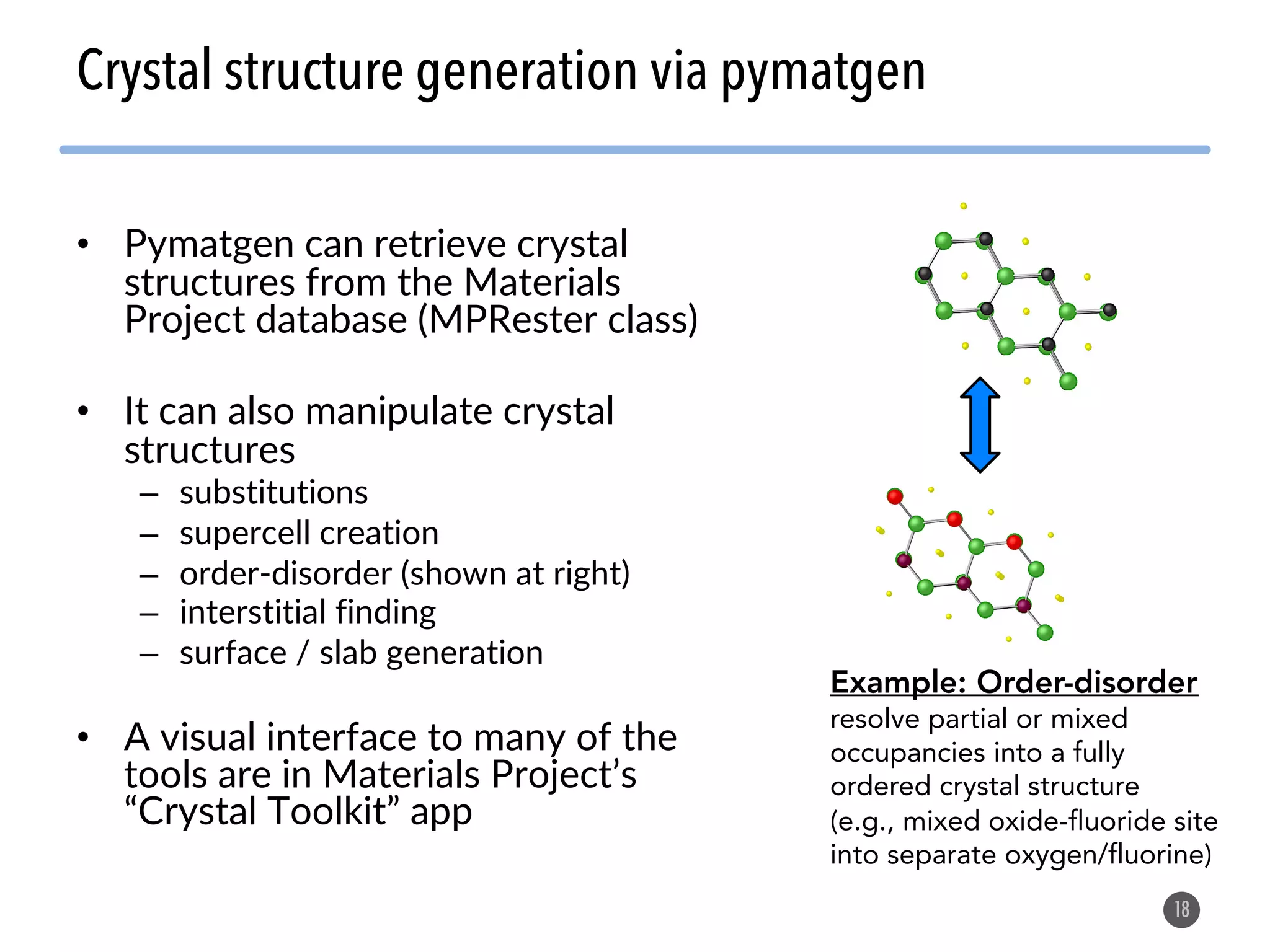
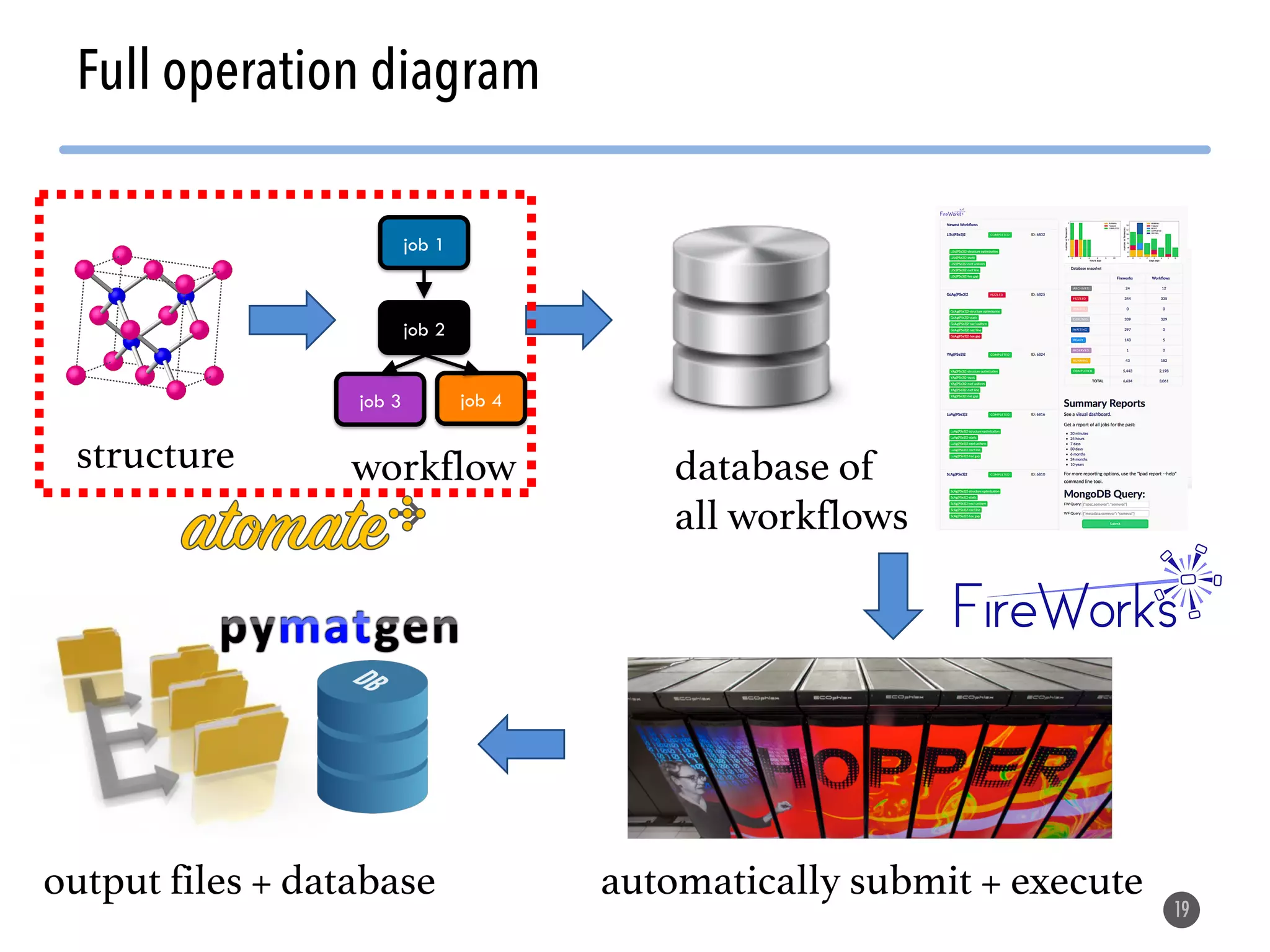
The document describes the Materials Project computation infrastructure, which uses the Atomate framework to automatically run density functional theory simulations on over 85,000 materials in a high-throughput manner, with the results stored in a MongoDB database for users to explore and analyze in order to accelerate materials innovation. The Materials Project infrastructure aims to make it easy for researchers to generate large amounts of computational data on materials properties through standardized and scalable workflows.



































































