Downloaded 15 times




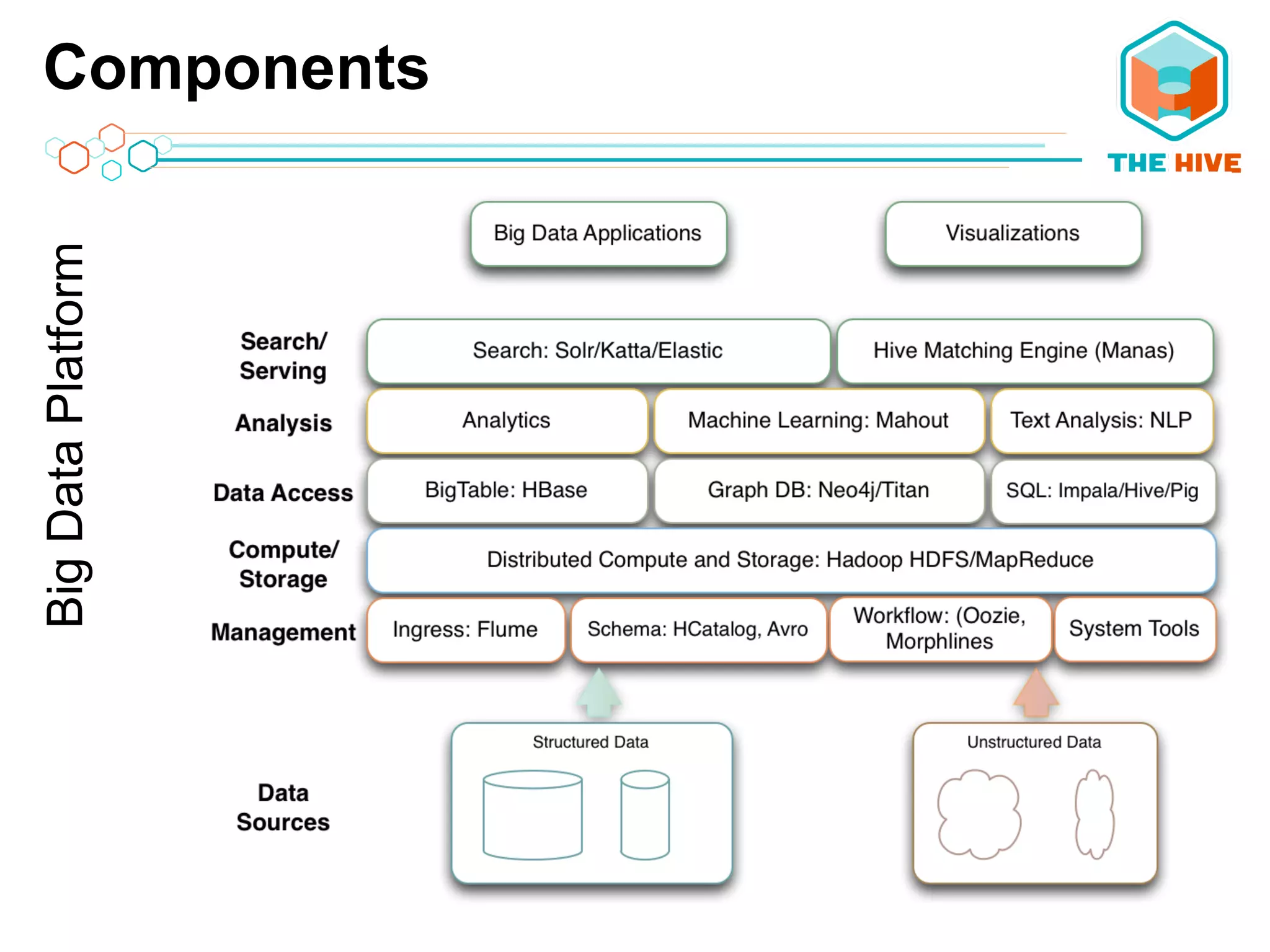

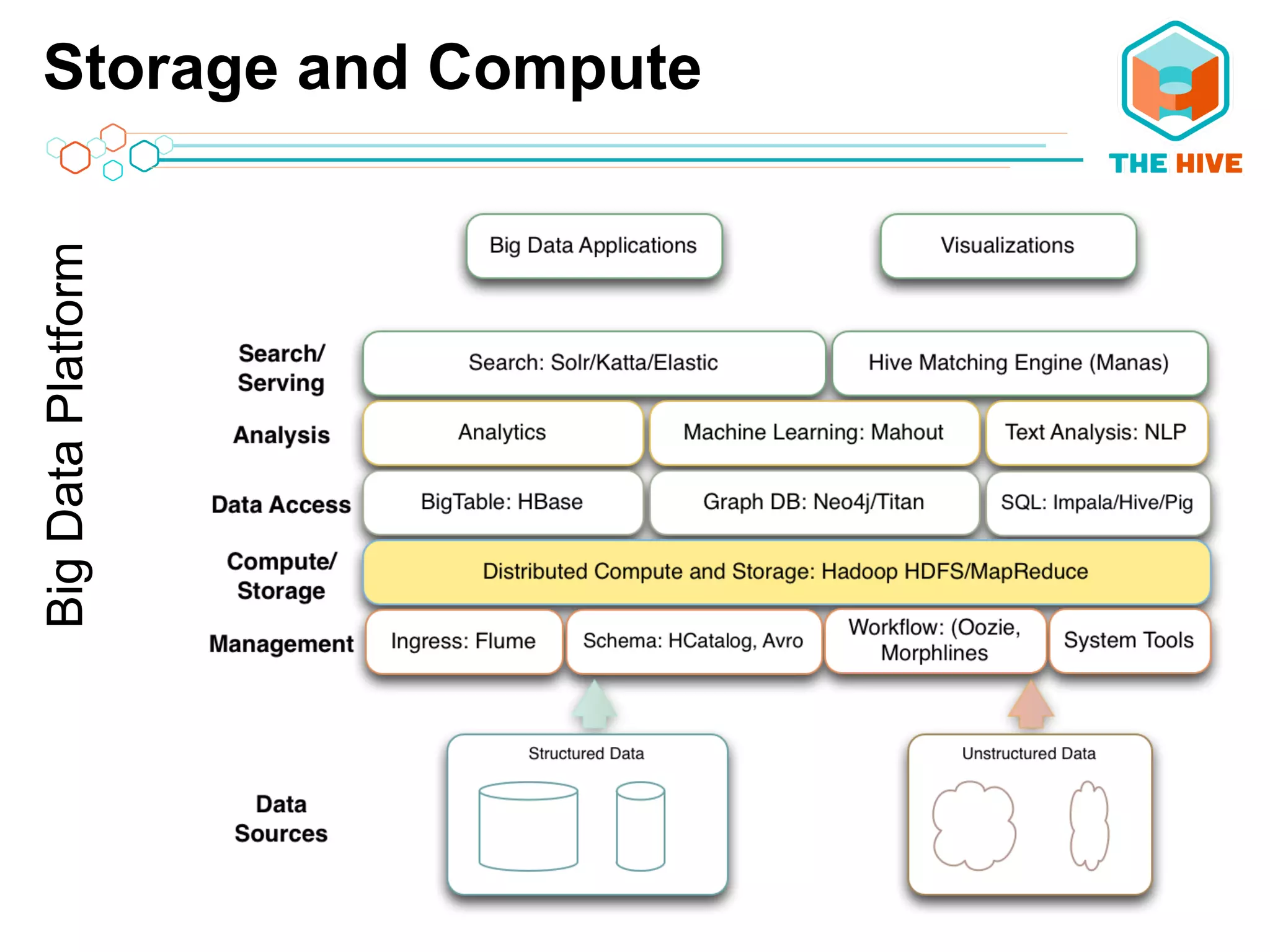

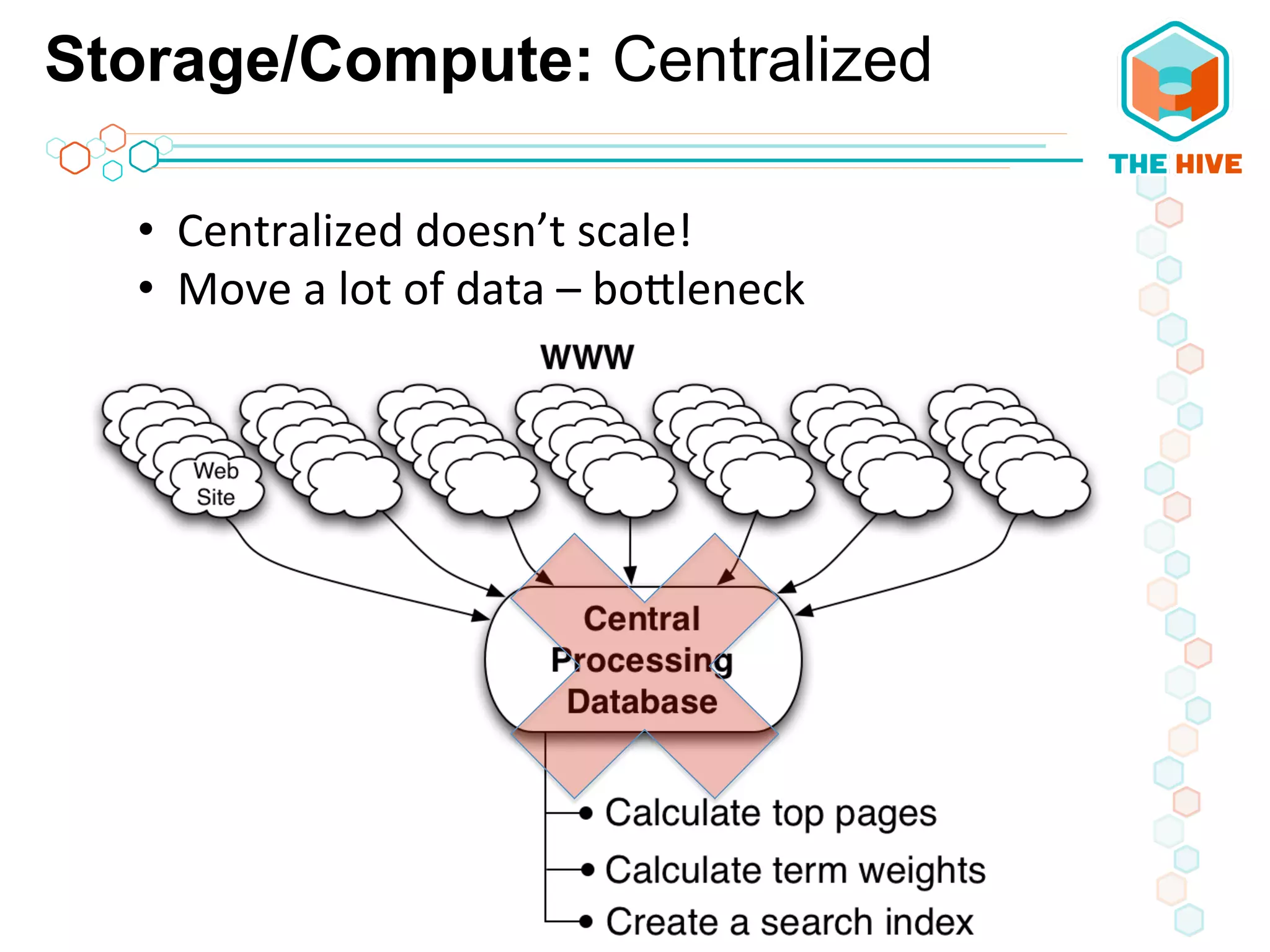
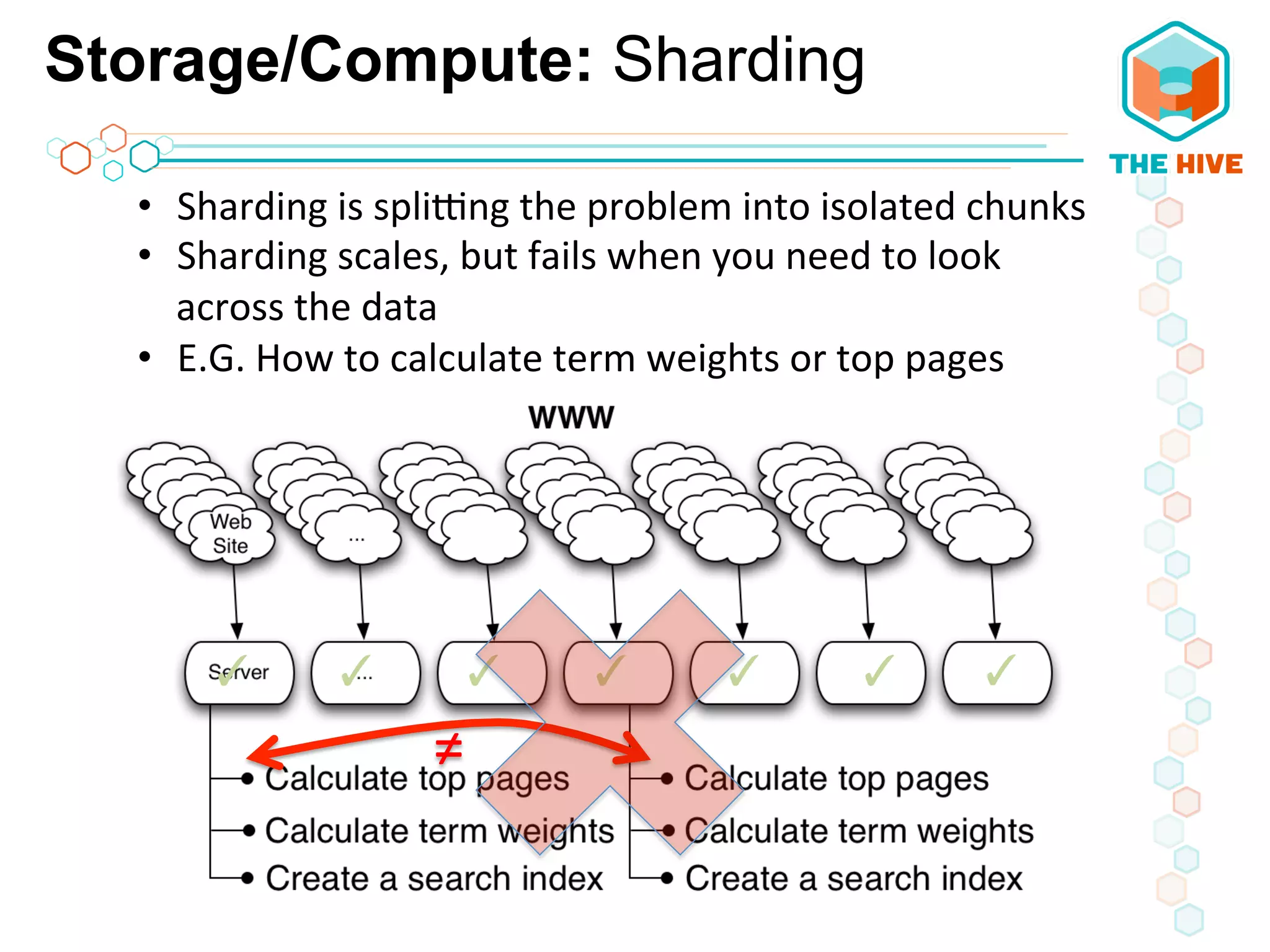

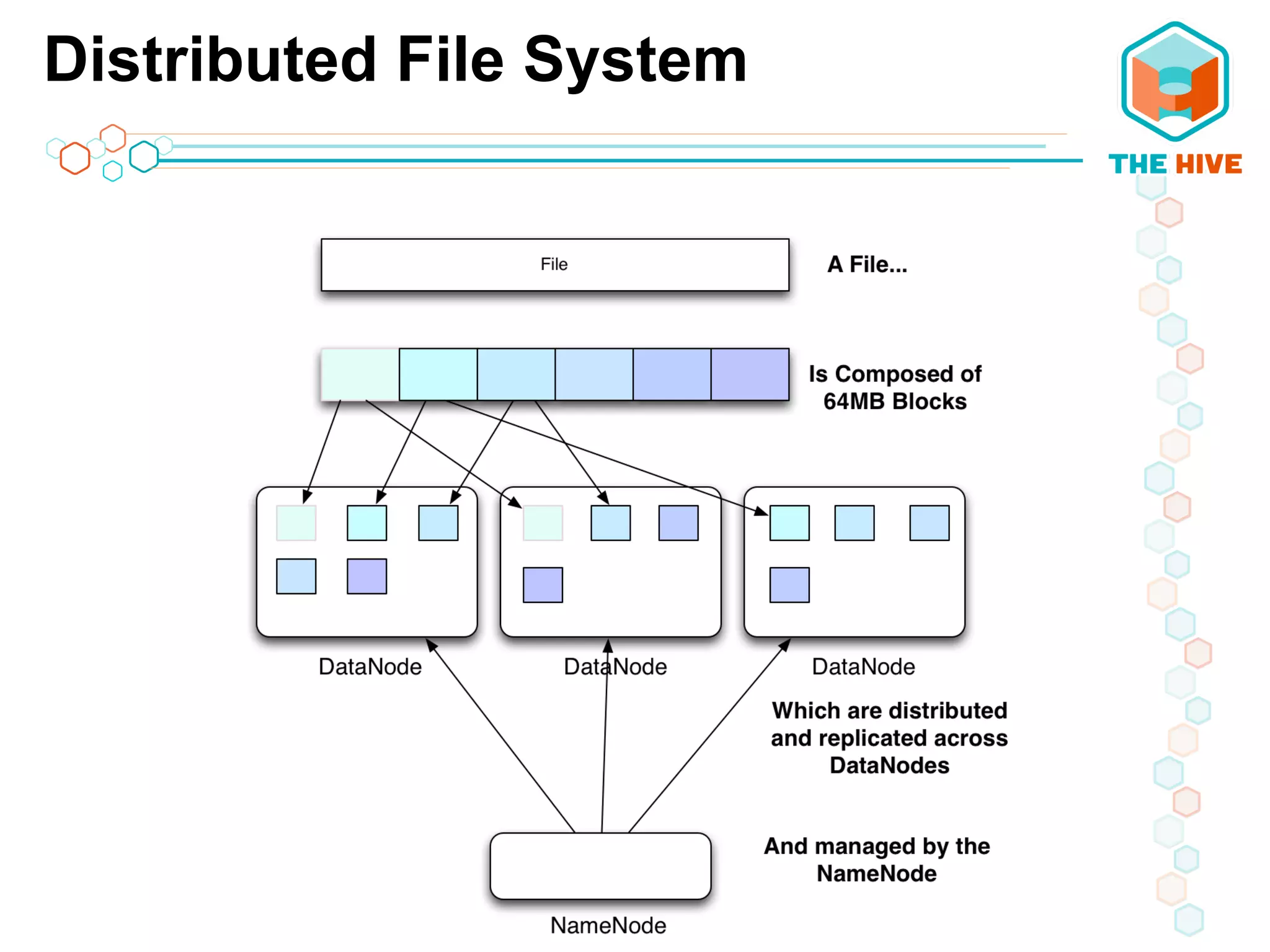
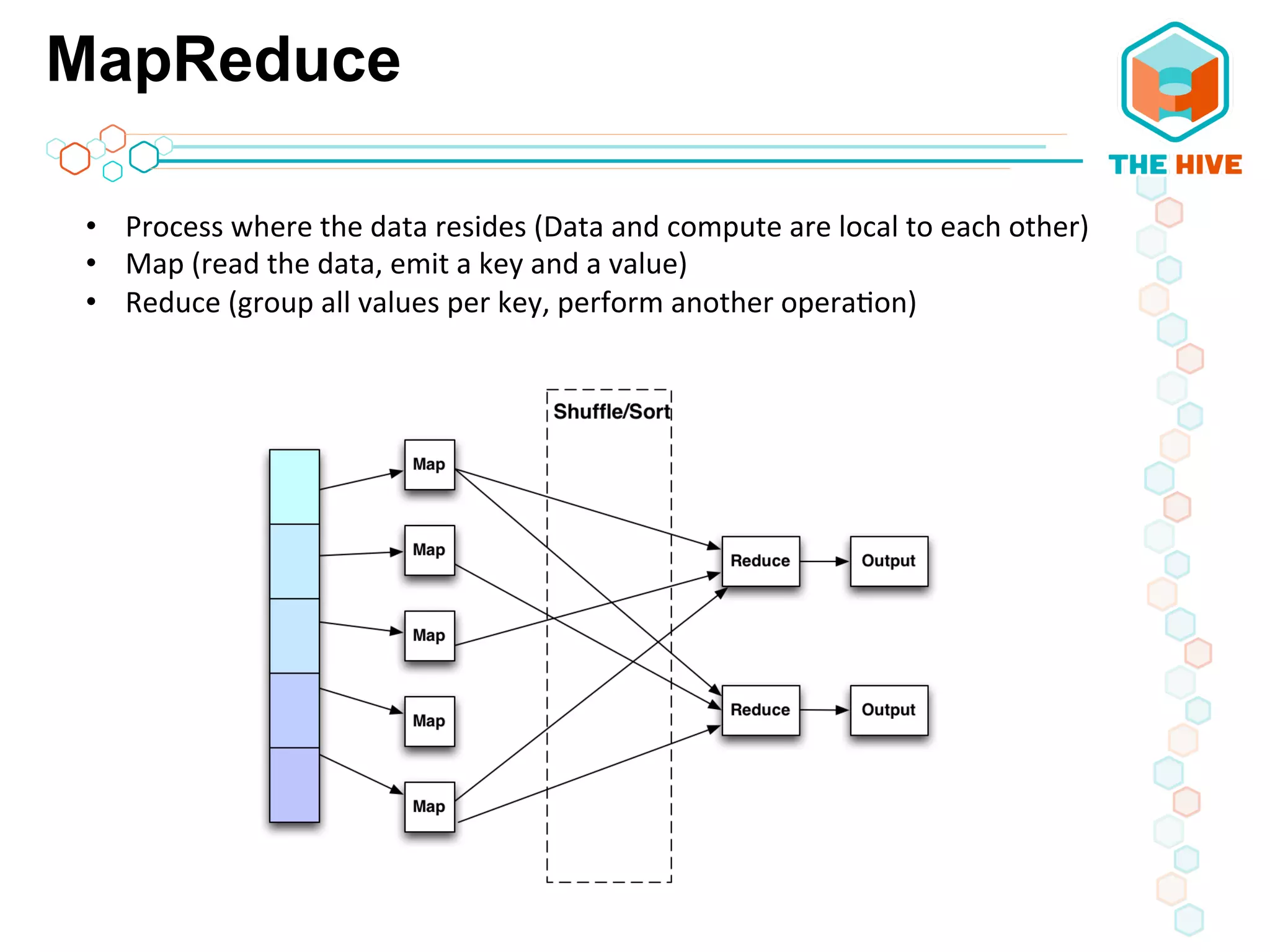

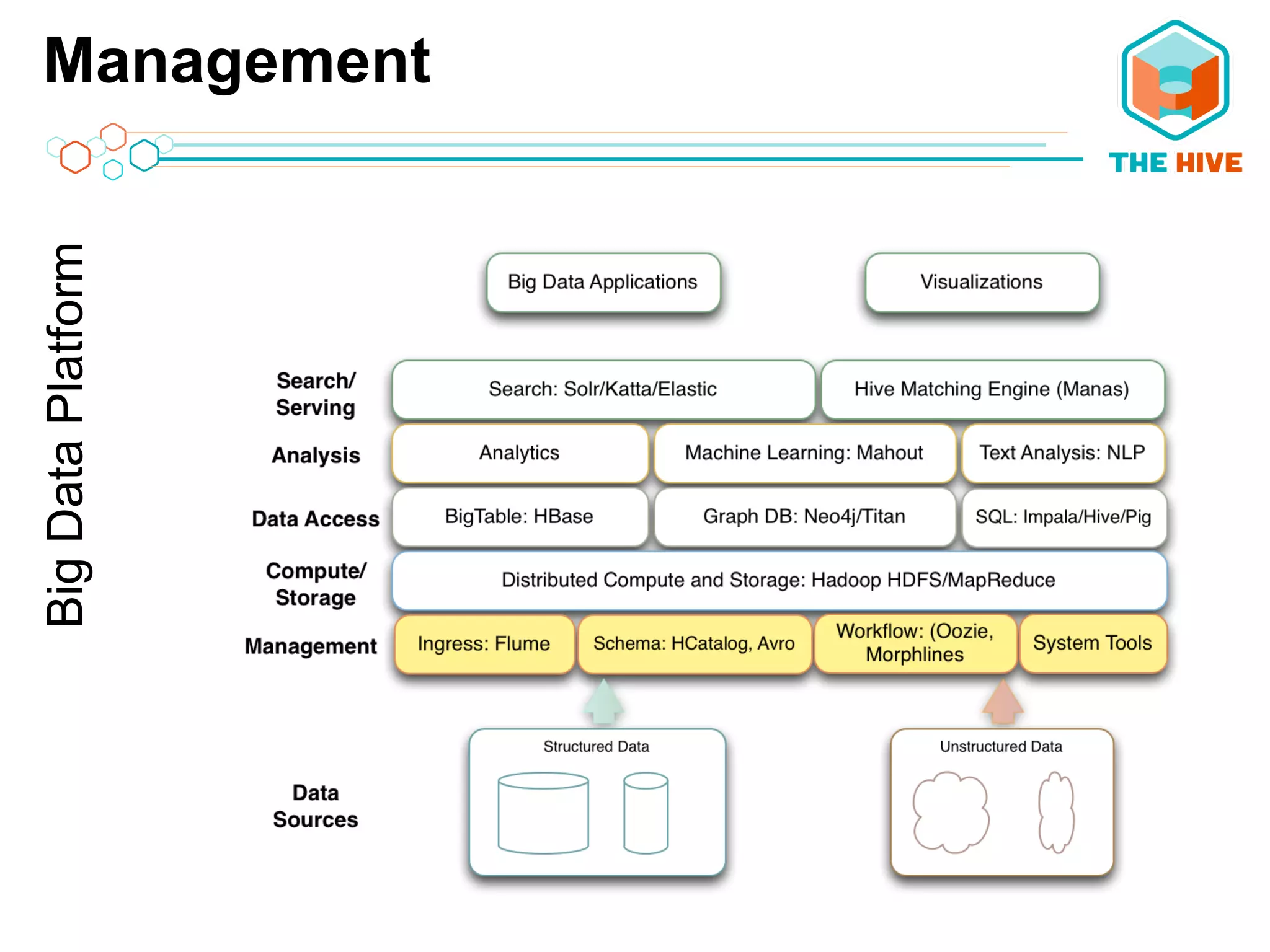
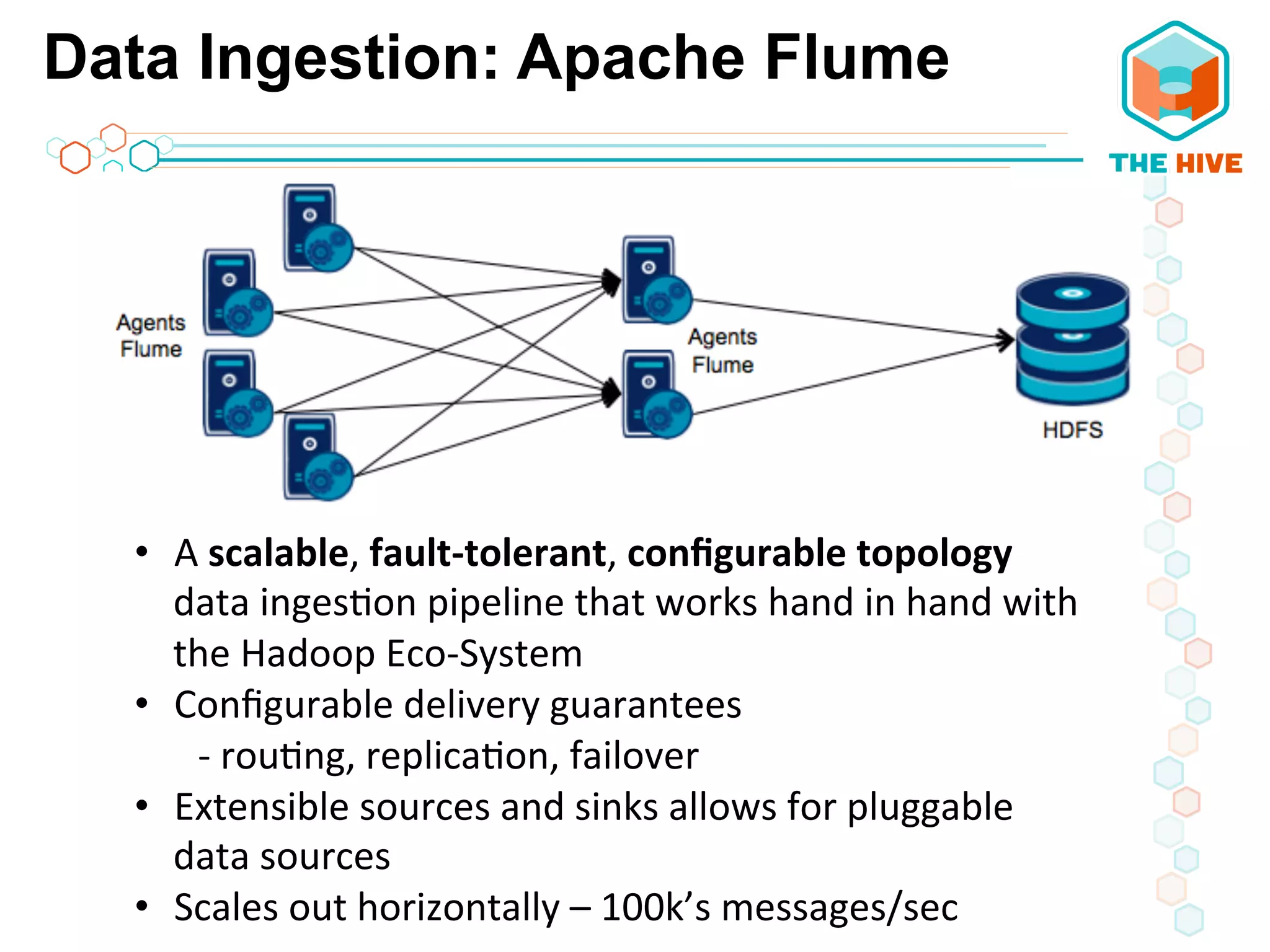
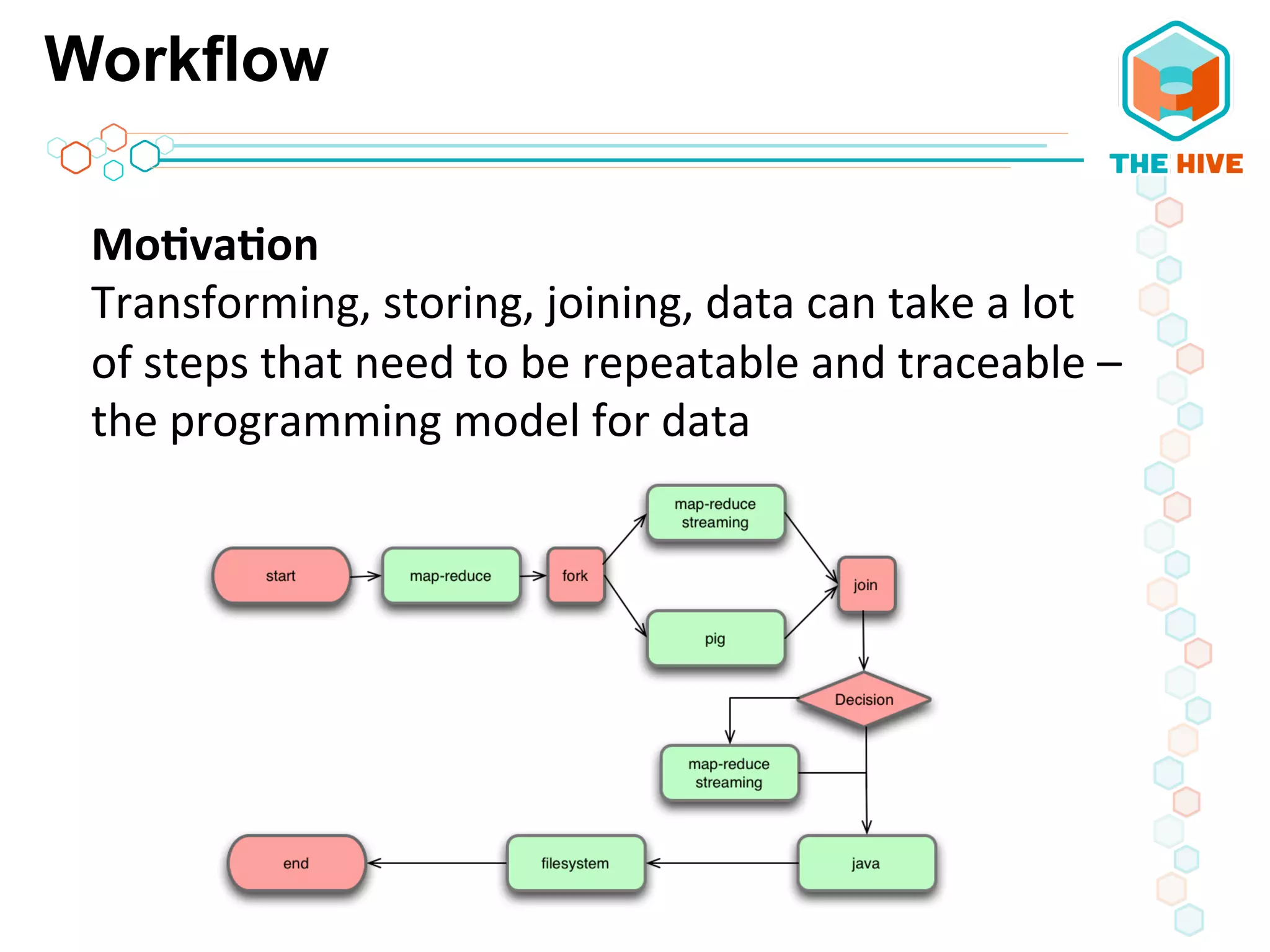

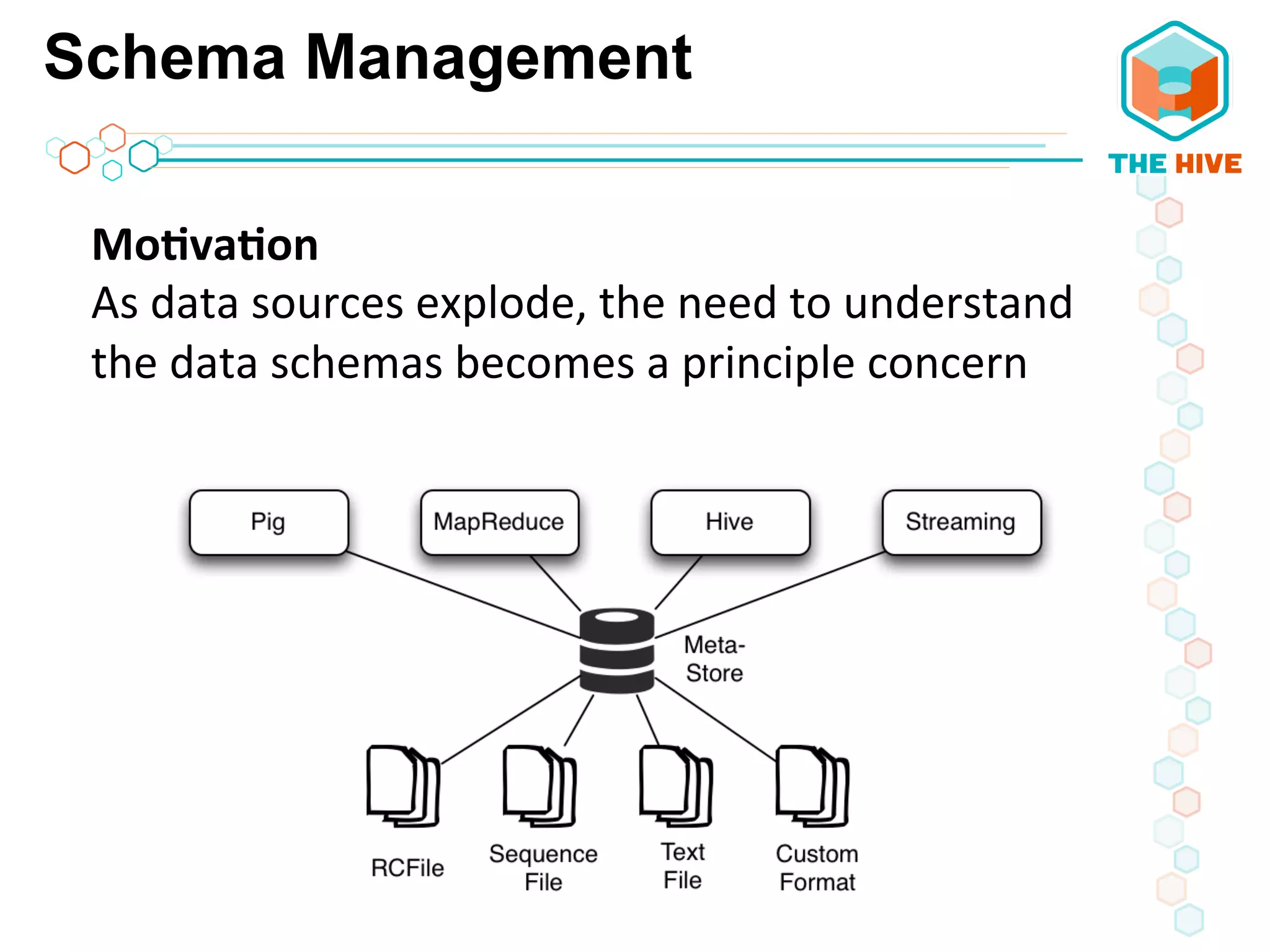


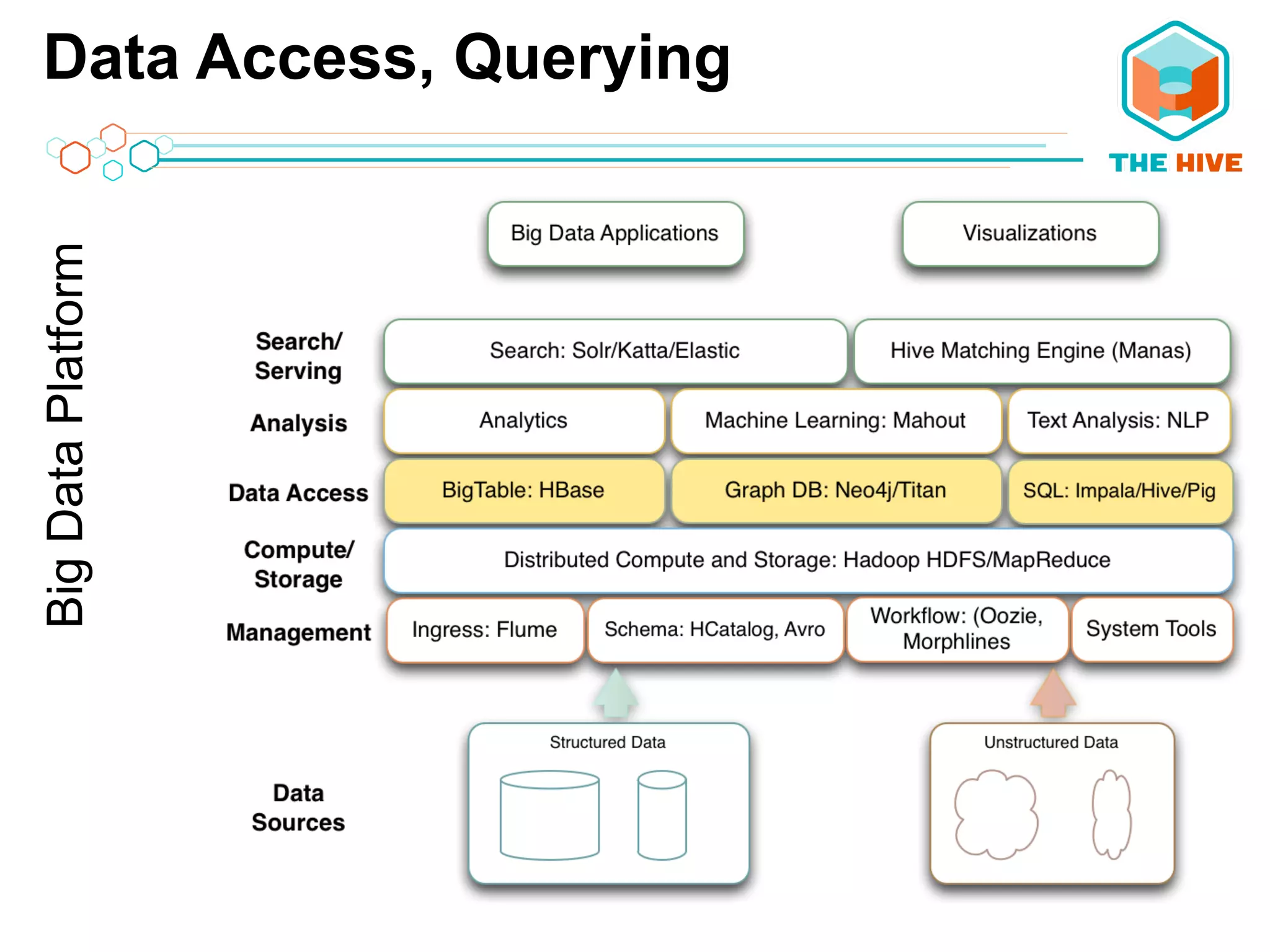



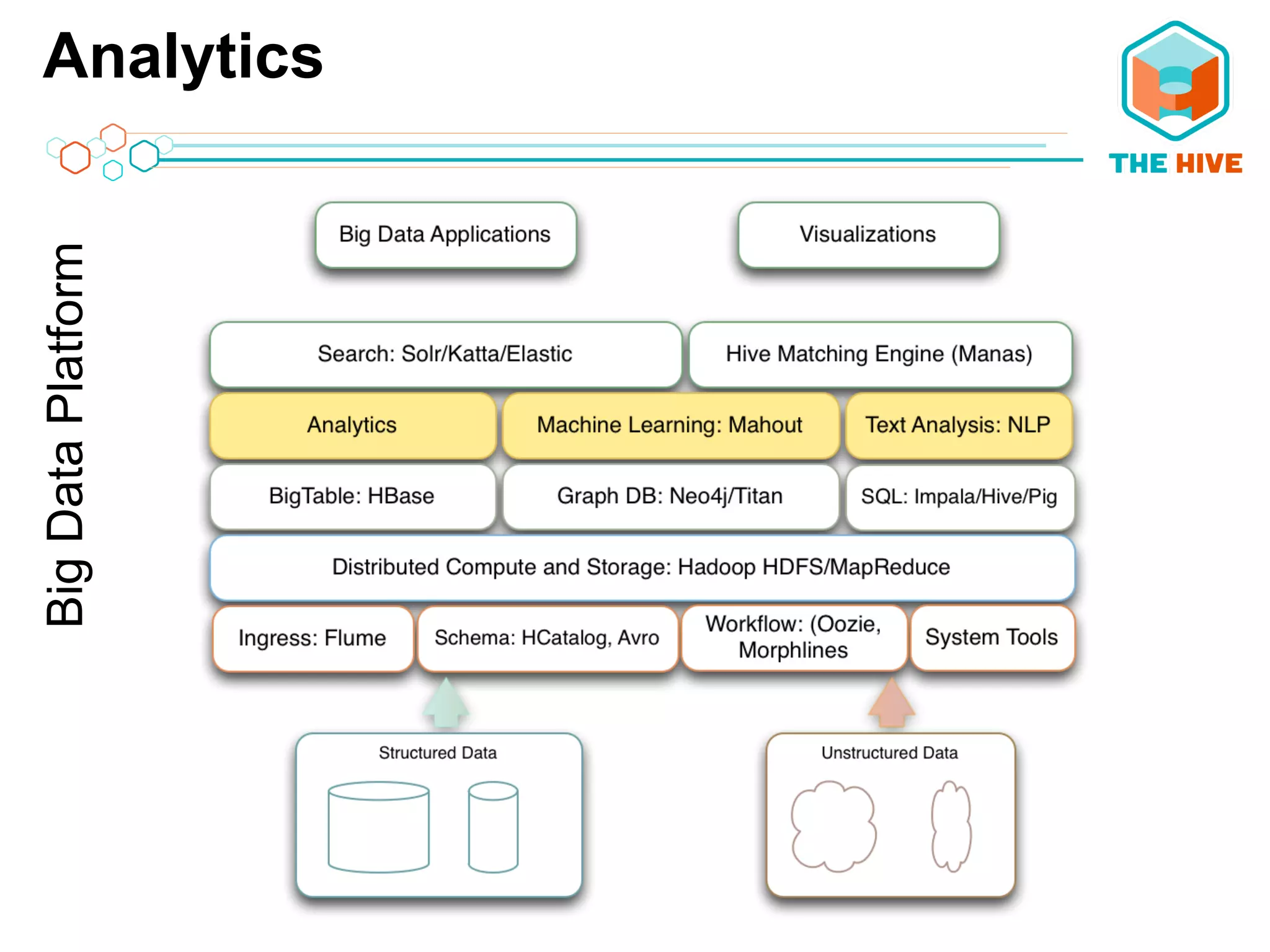


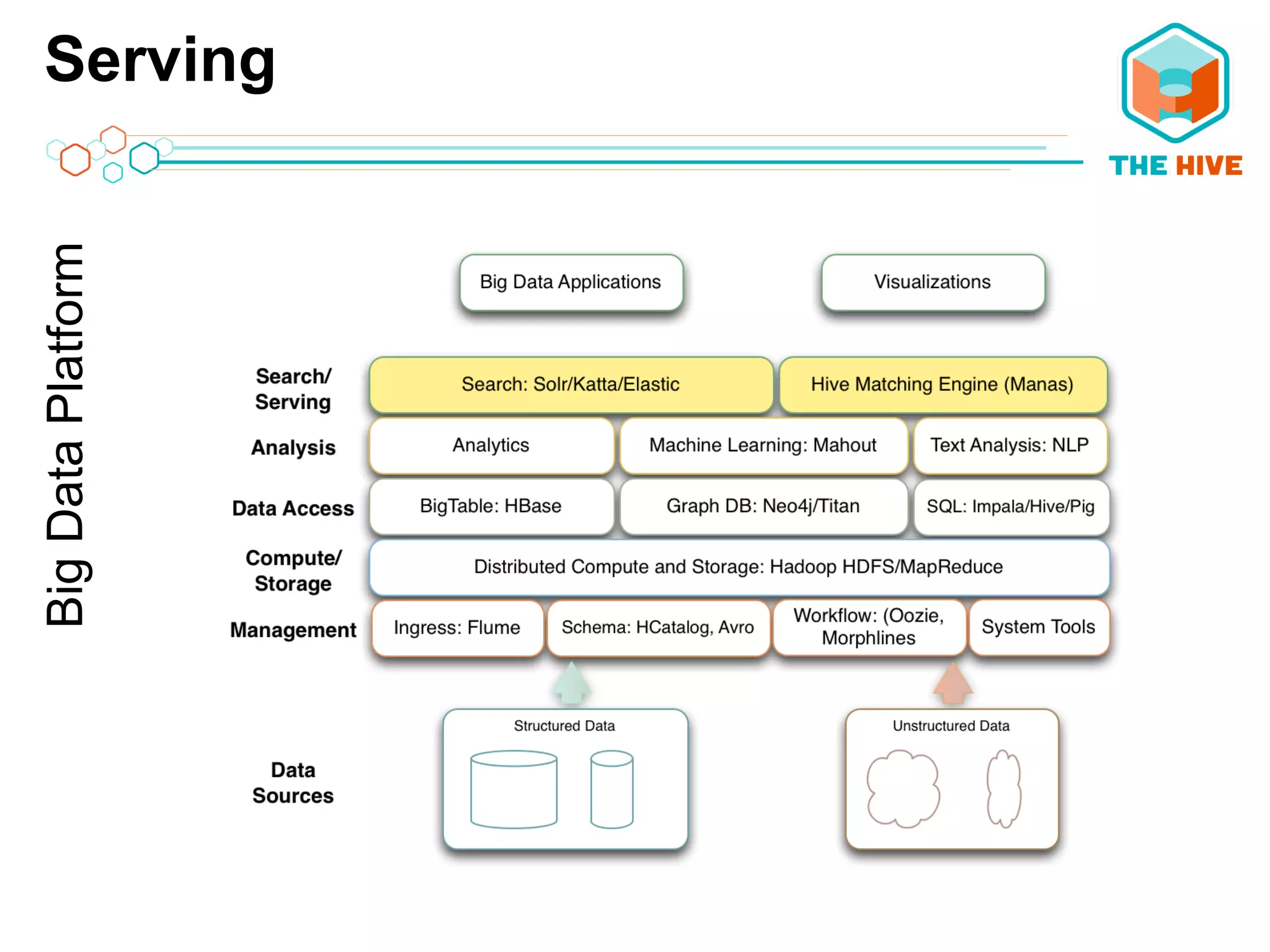



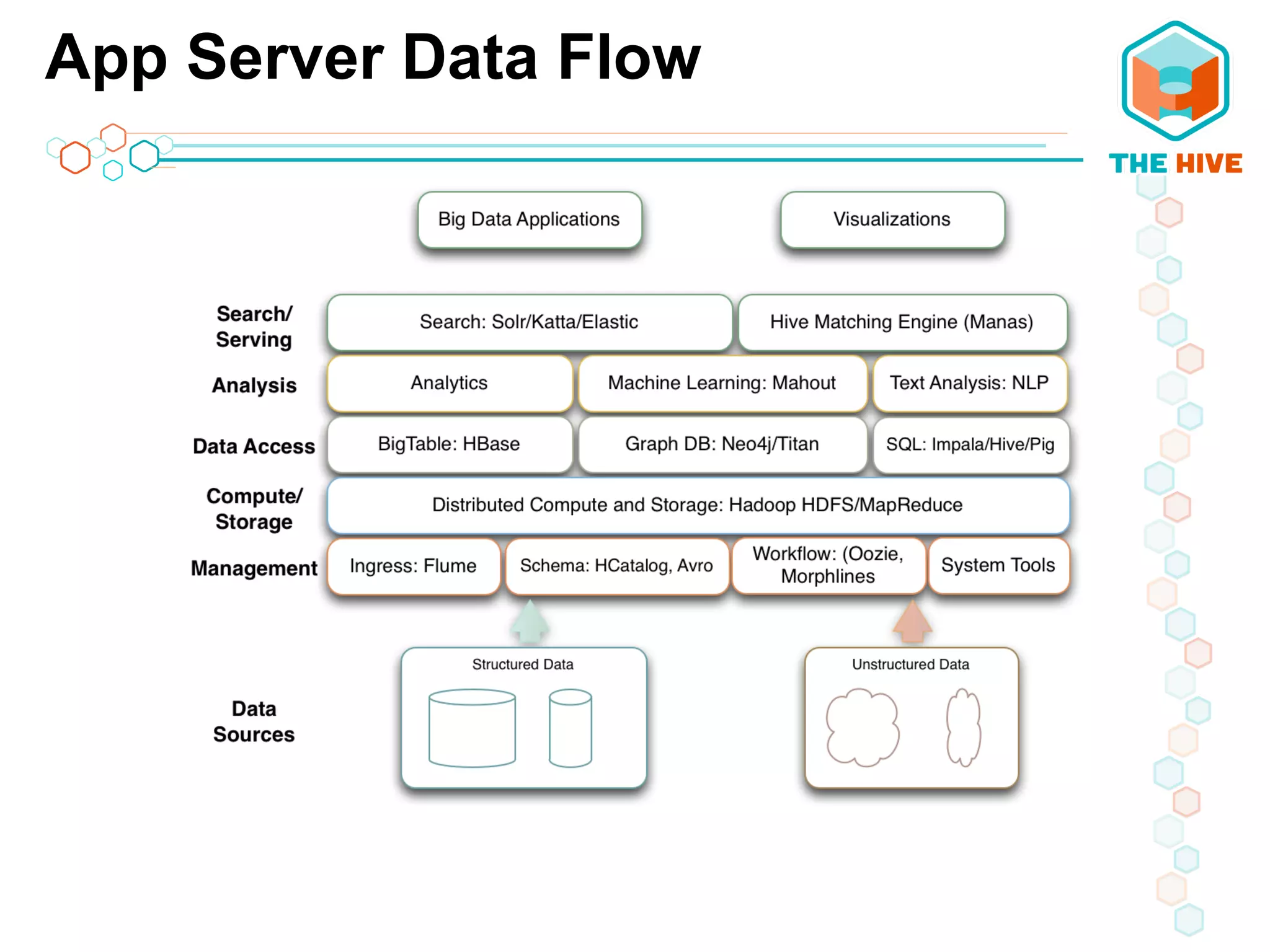
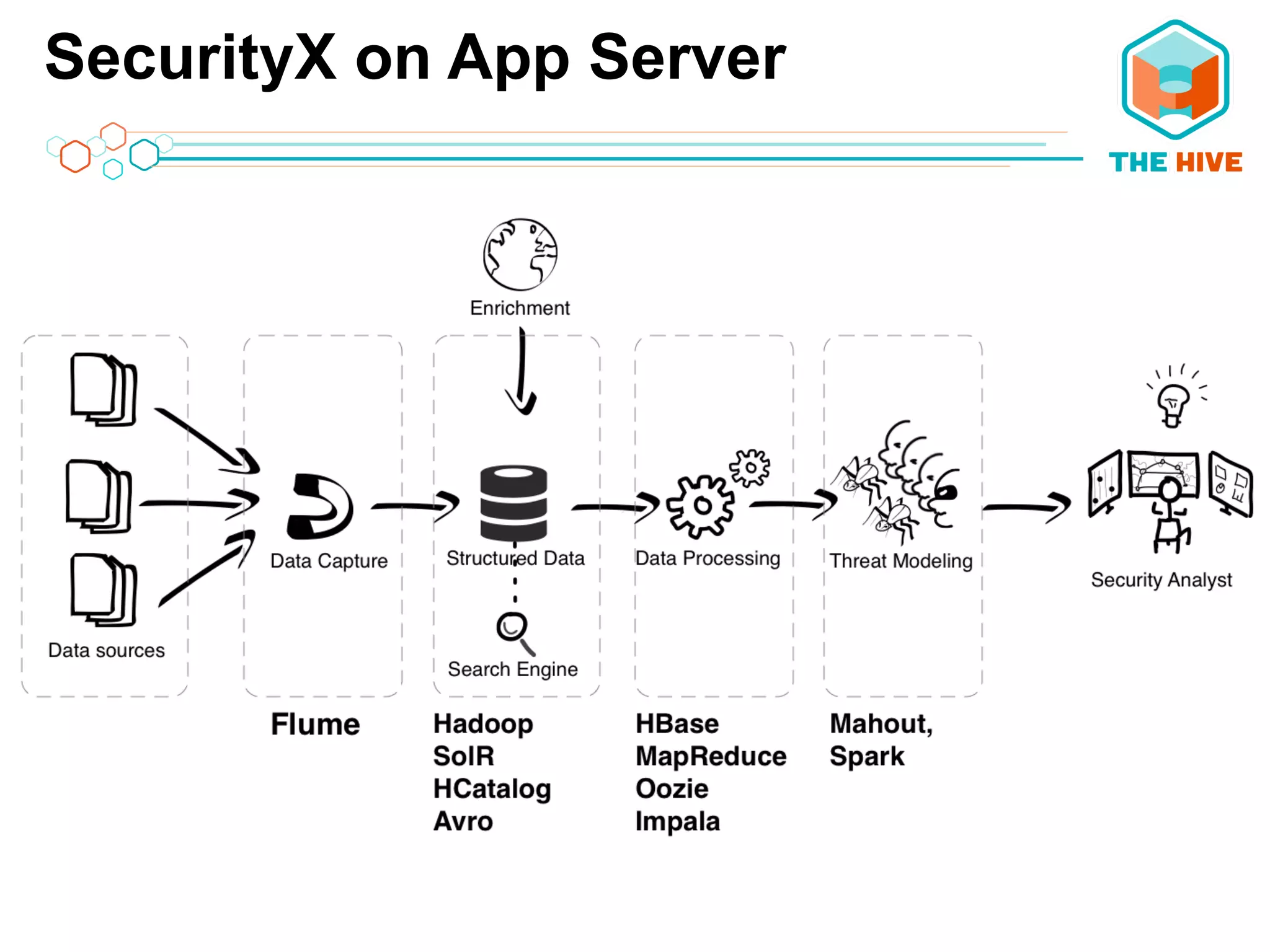

This document describes a big data application server framework for handling large volumes, velocities, and varieties of data to extract value. It discusses use cases like log analytics, security detection, sensor data analytics, and recommendation systems. The document then summarizes several key components of big data platforms, including storage and compute systems like HDFS and MapReduce, data ingestion with Apache Flume, workflow systems like Oozie, schema management with HCatalog and Avro, data access with HBase and SQL querying with Hive and Impala.





























![[Japanese Content] Lance Riedel_The App Server, The Hive in Tokyo_Aug29](https://cdn.slidesharecdn.com/ss_thumbnails/lanceriedelappserver-thehiveaug29-130920154018-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Japanese Content] Sumant Mandal_Opportunites in Big Data, The Hive in Japan,...](https://cdn.slidesharecdn.com/ss_thumbnails/sumantmadalopportunitesinbigdataoct29-130920153150-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Japanese Content] TM Ravi_ Tokyo Presentation_TheHive_Sept 2013](https://cdn.slidesharecdn.com/ss_thumbnails/ravitokyopresentationthehiveoct29-130920153653-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















