Downloaded 34 times



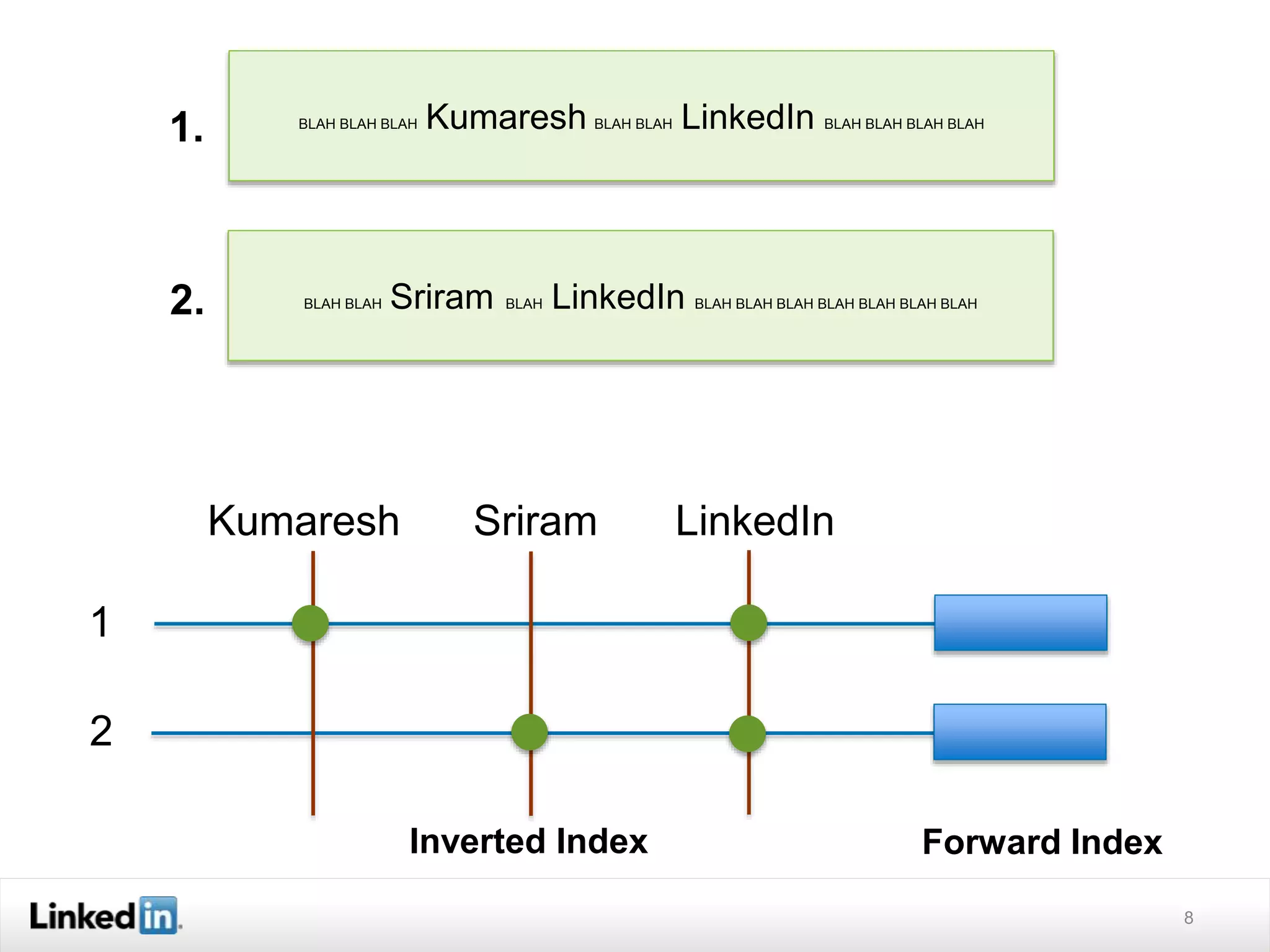
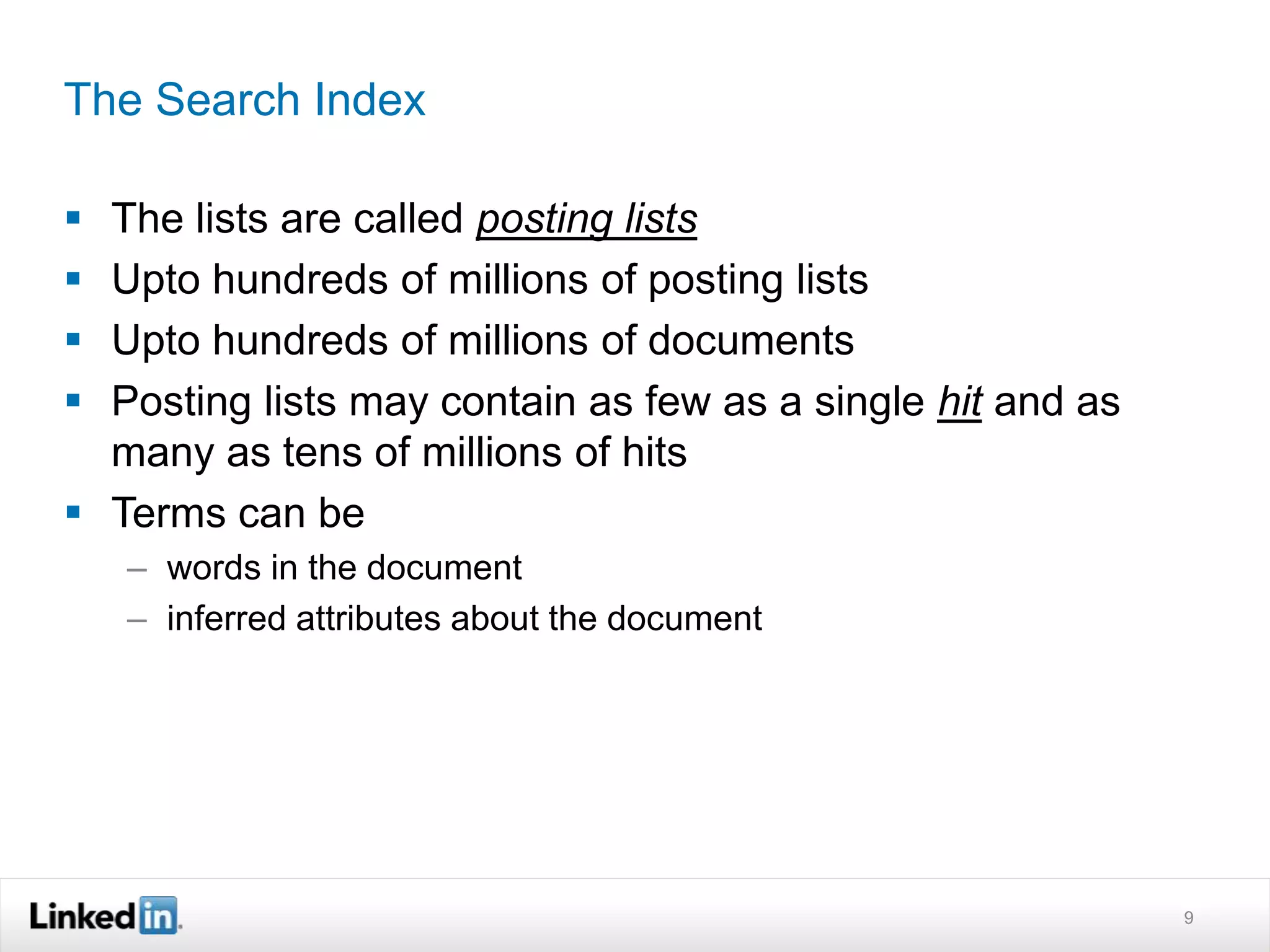
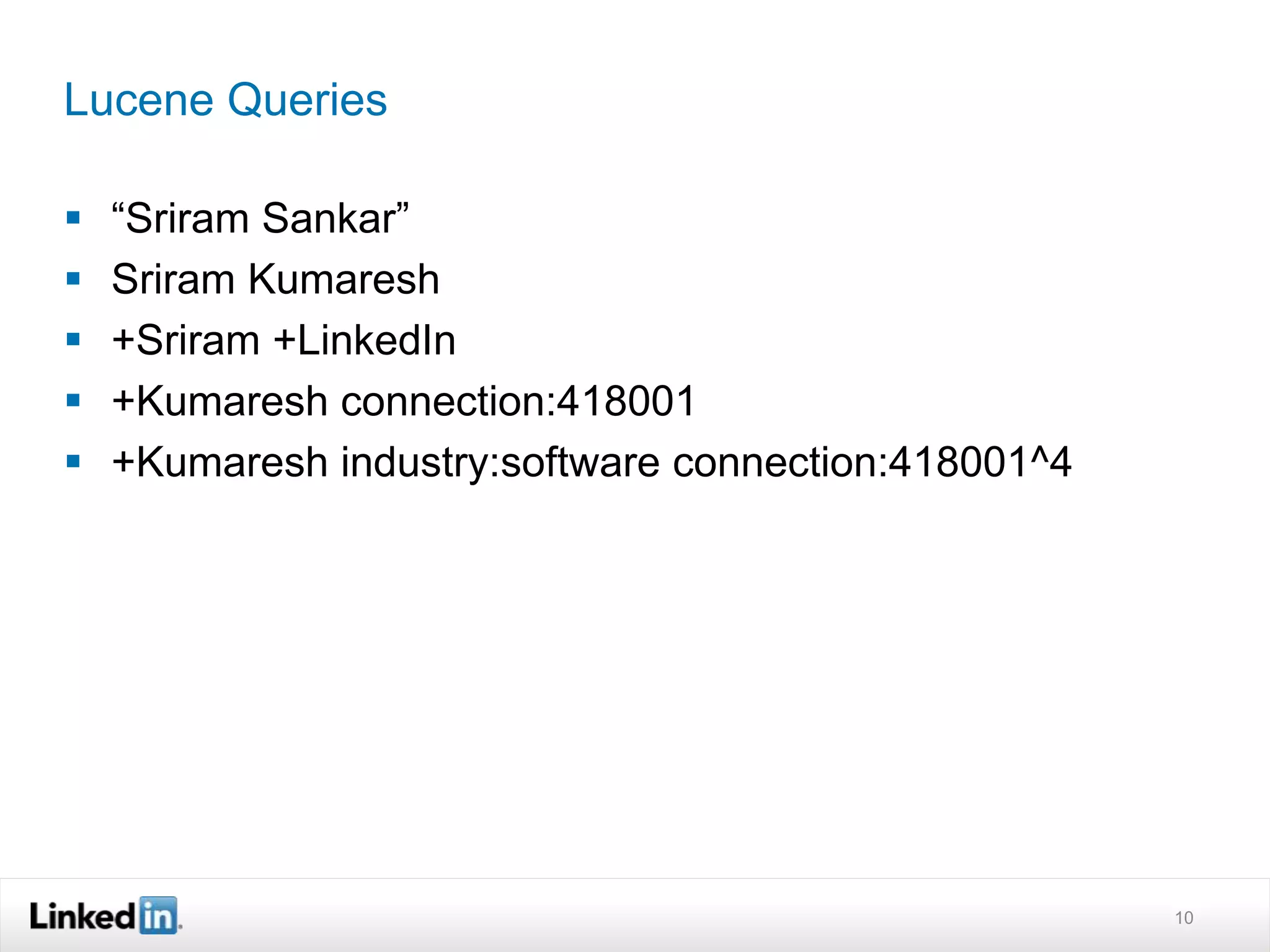
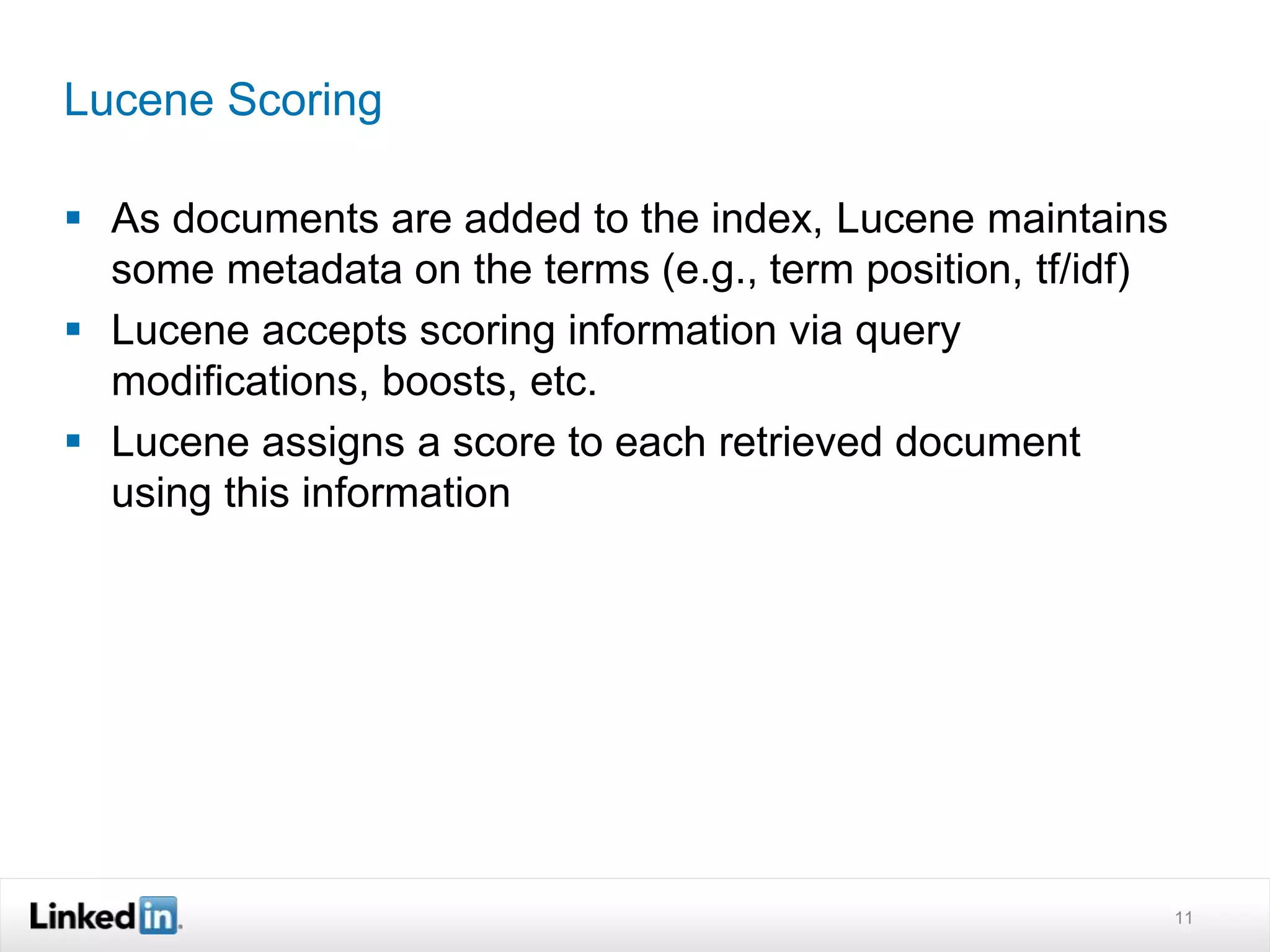
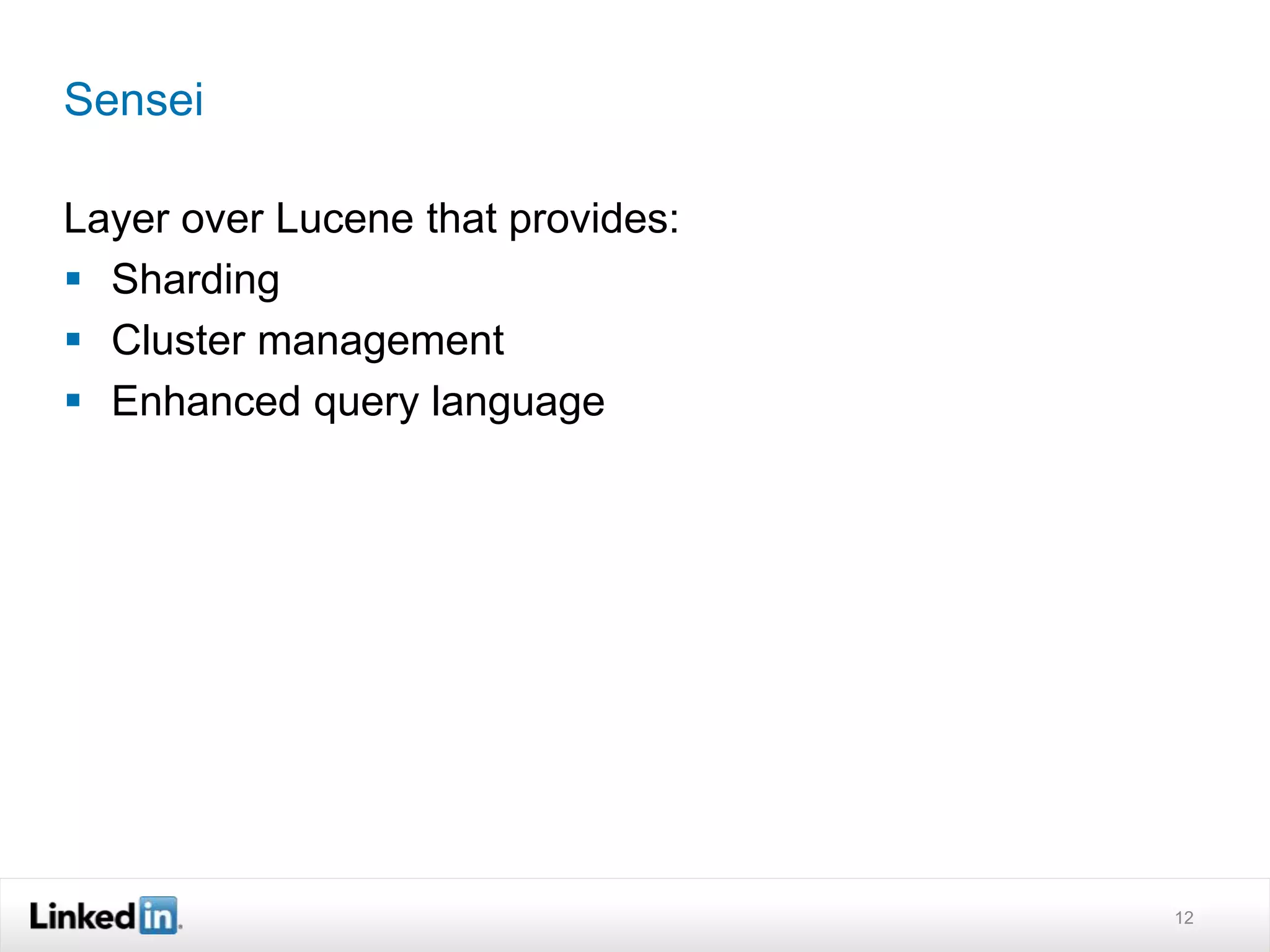
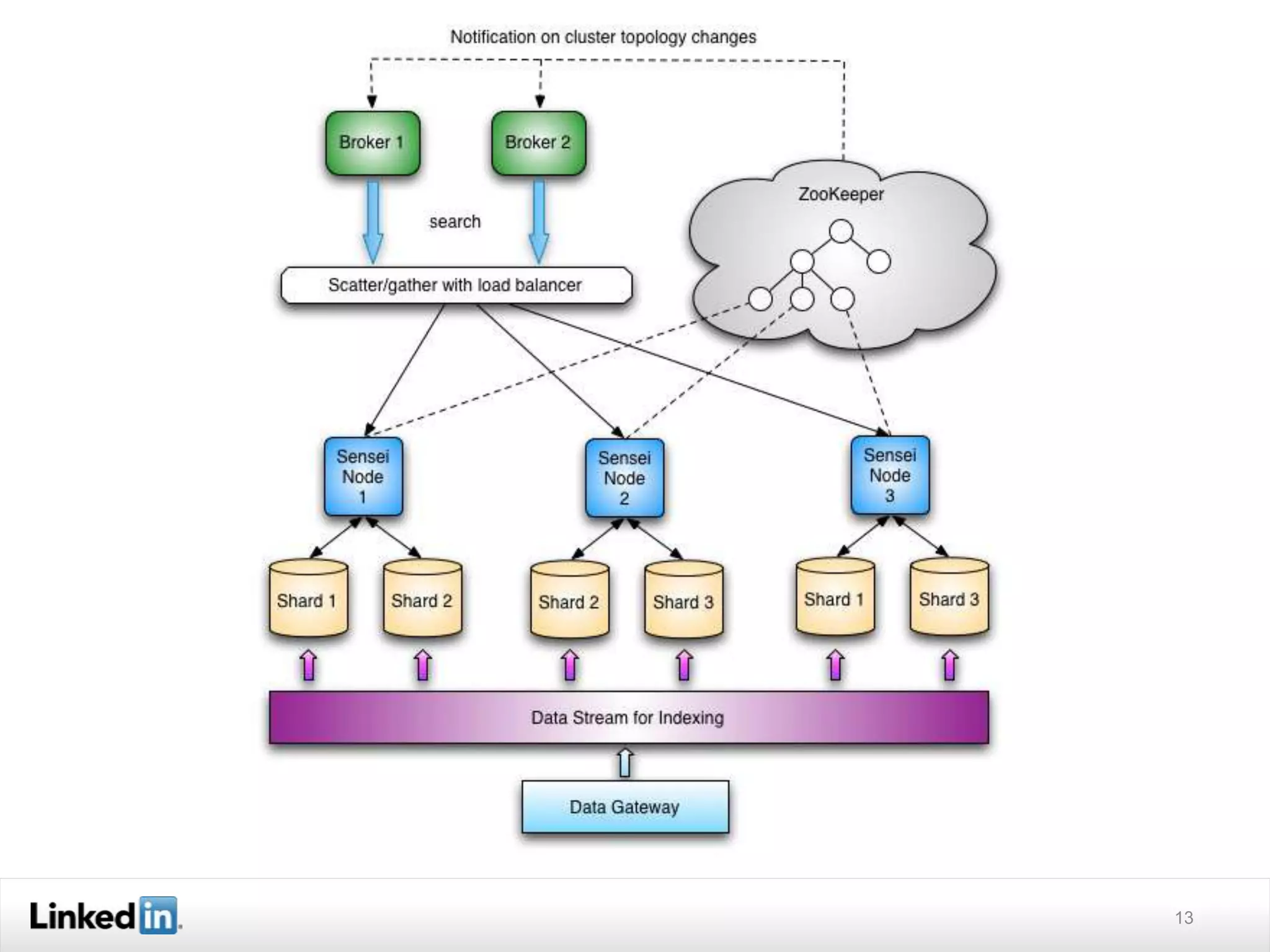

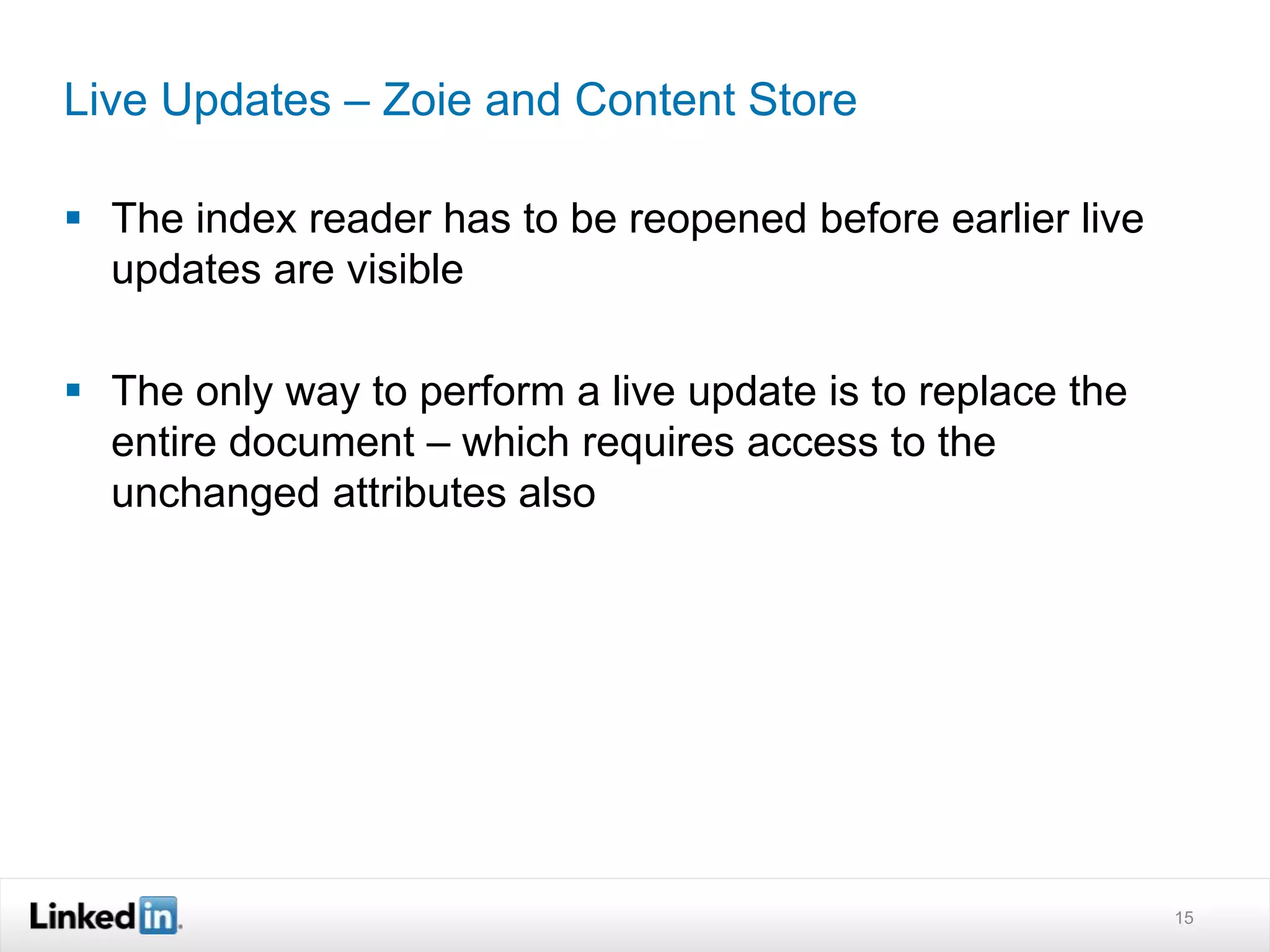
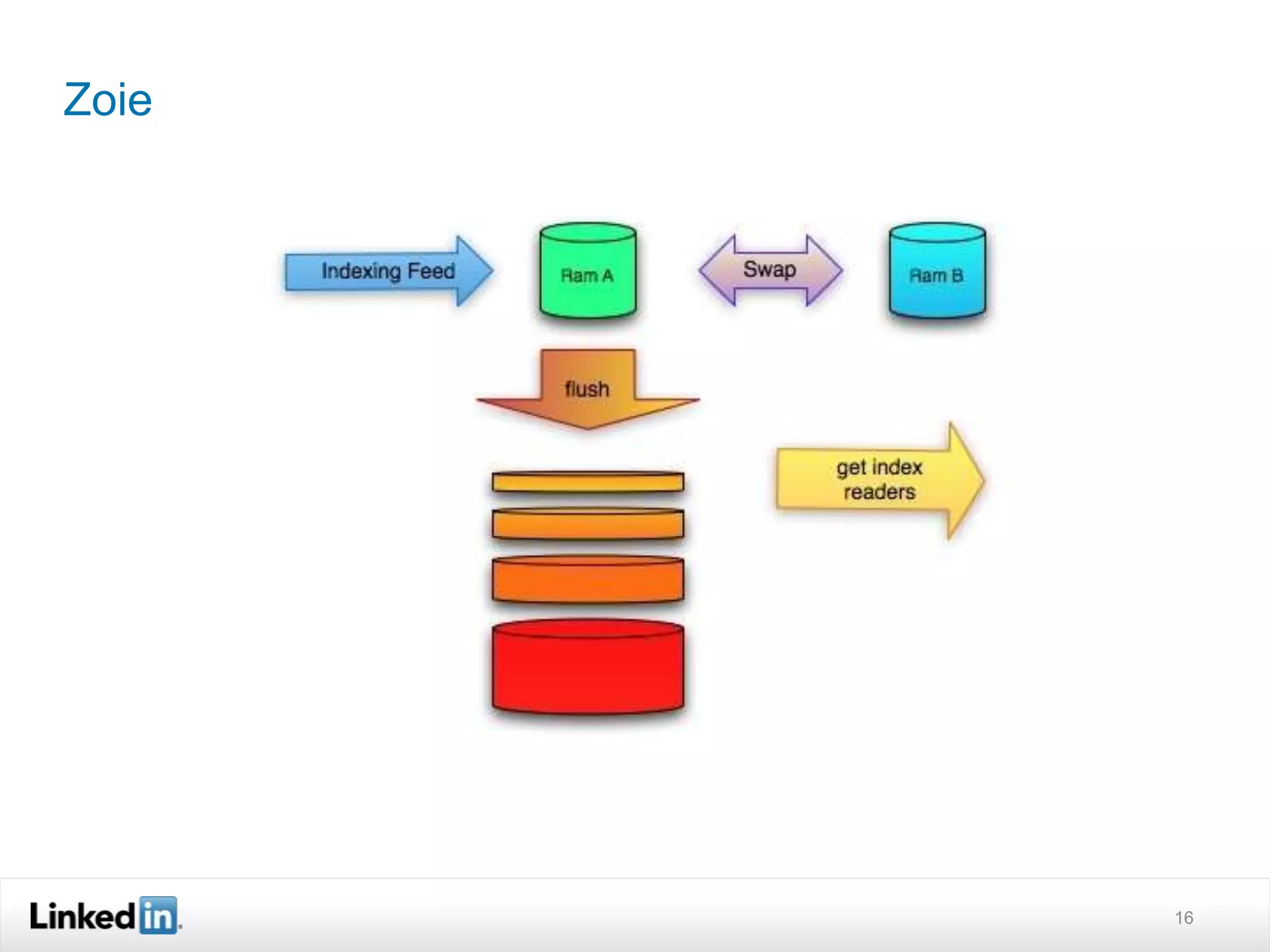
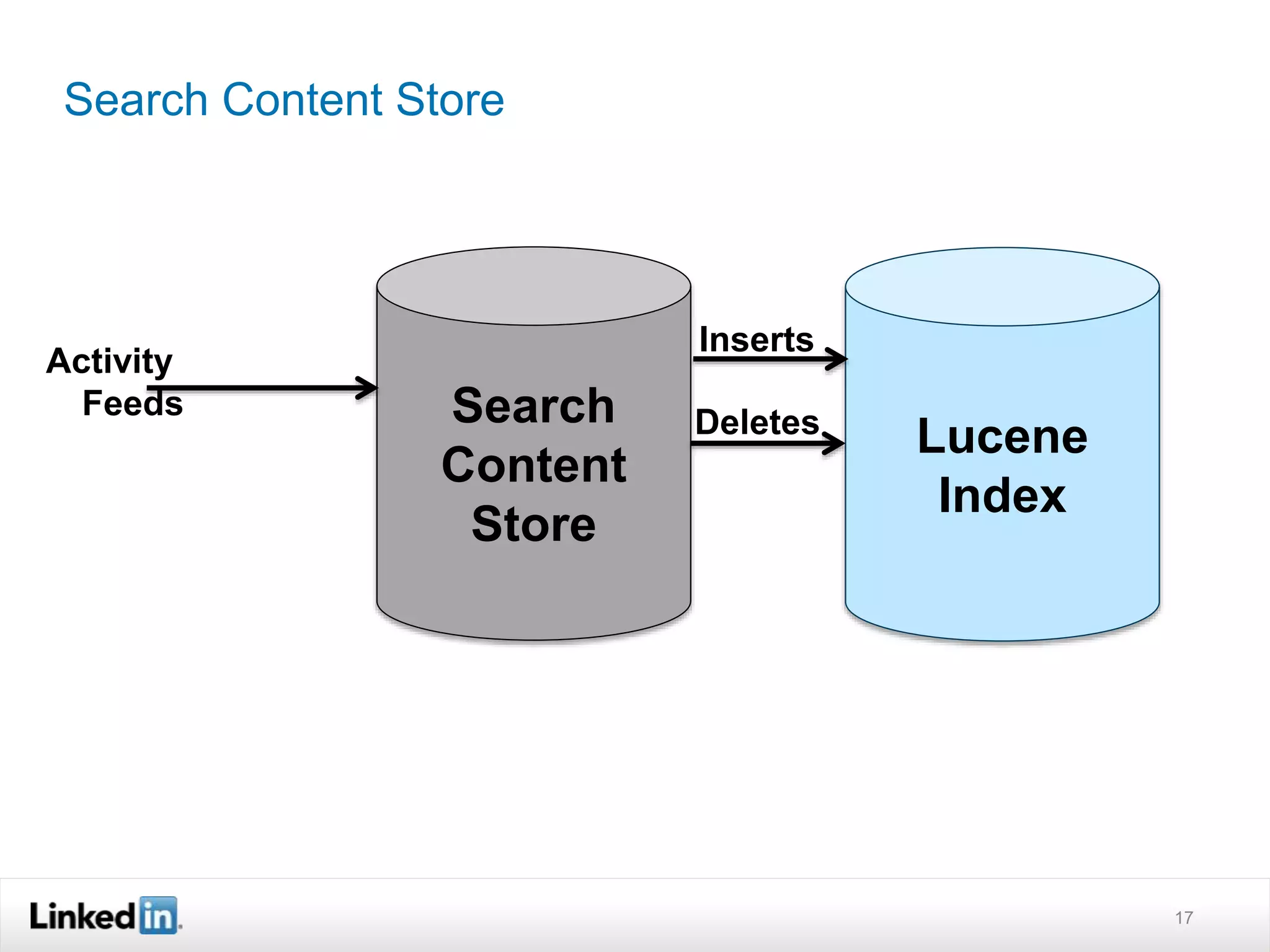
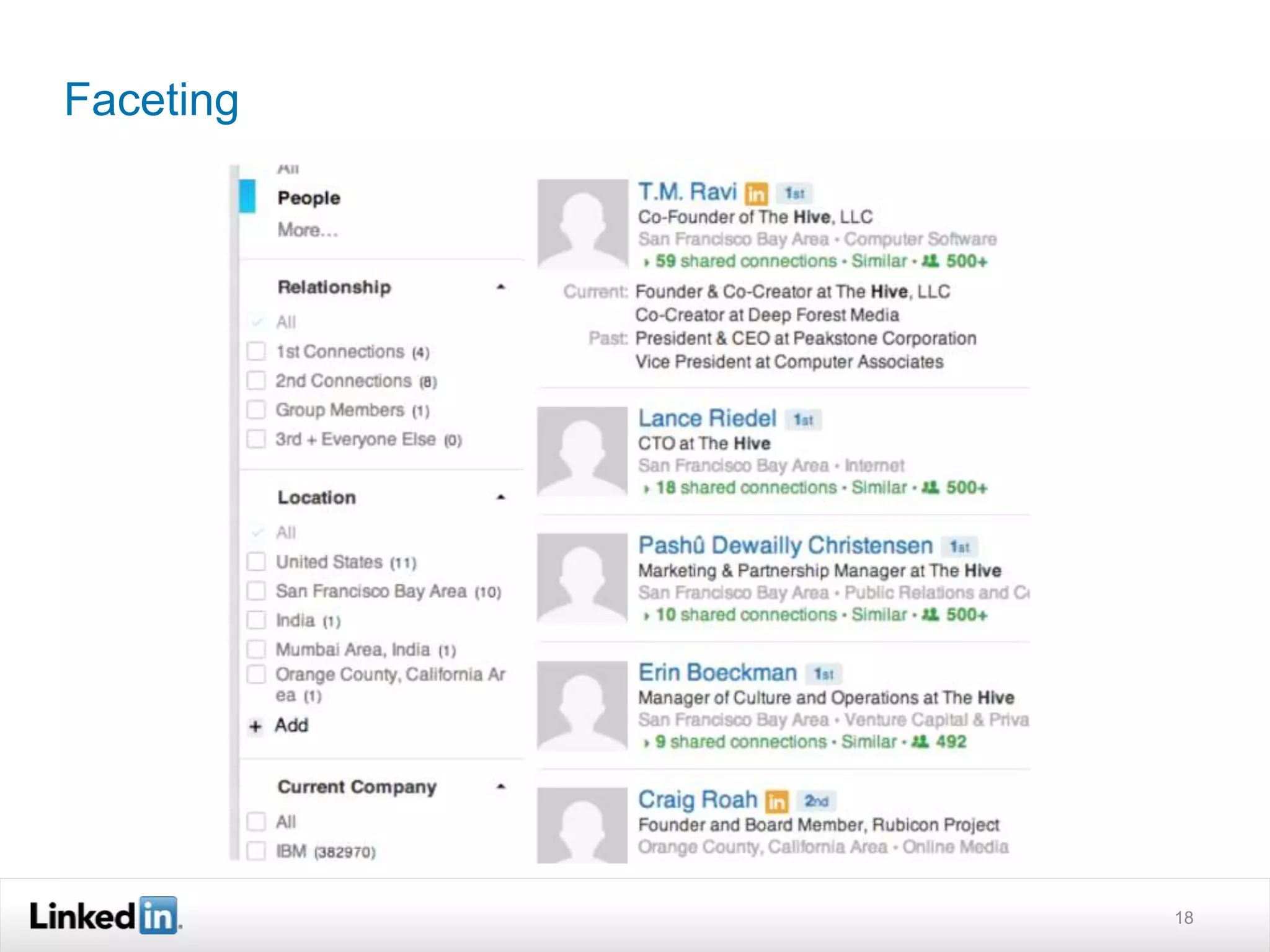
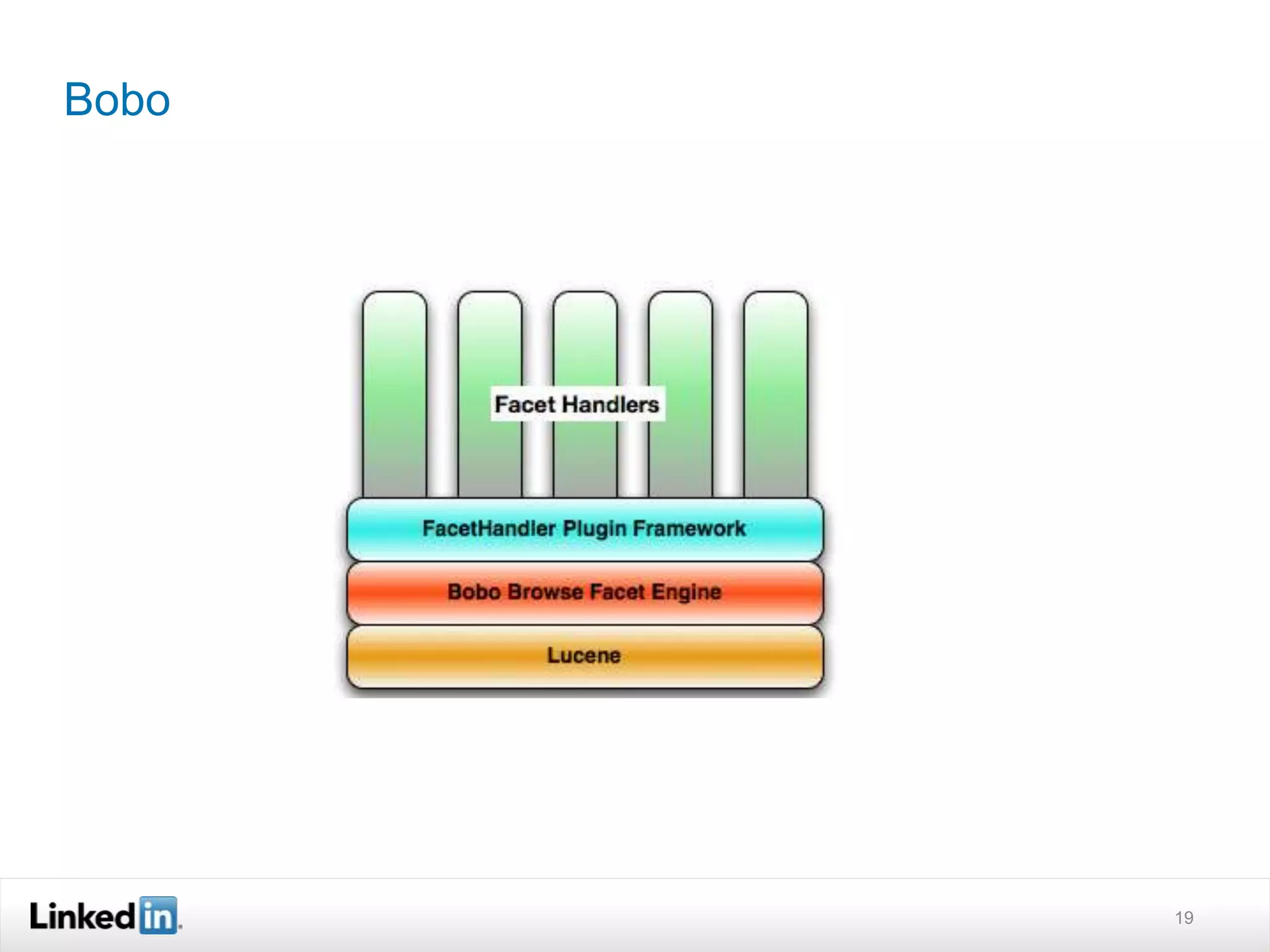




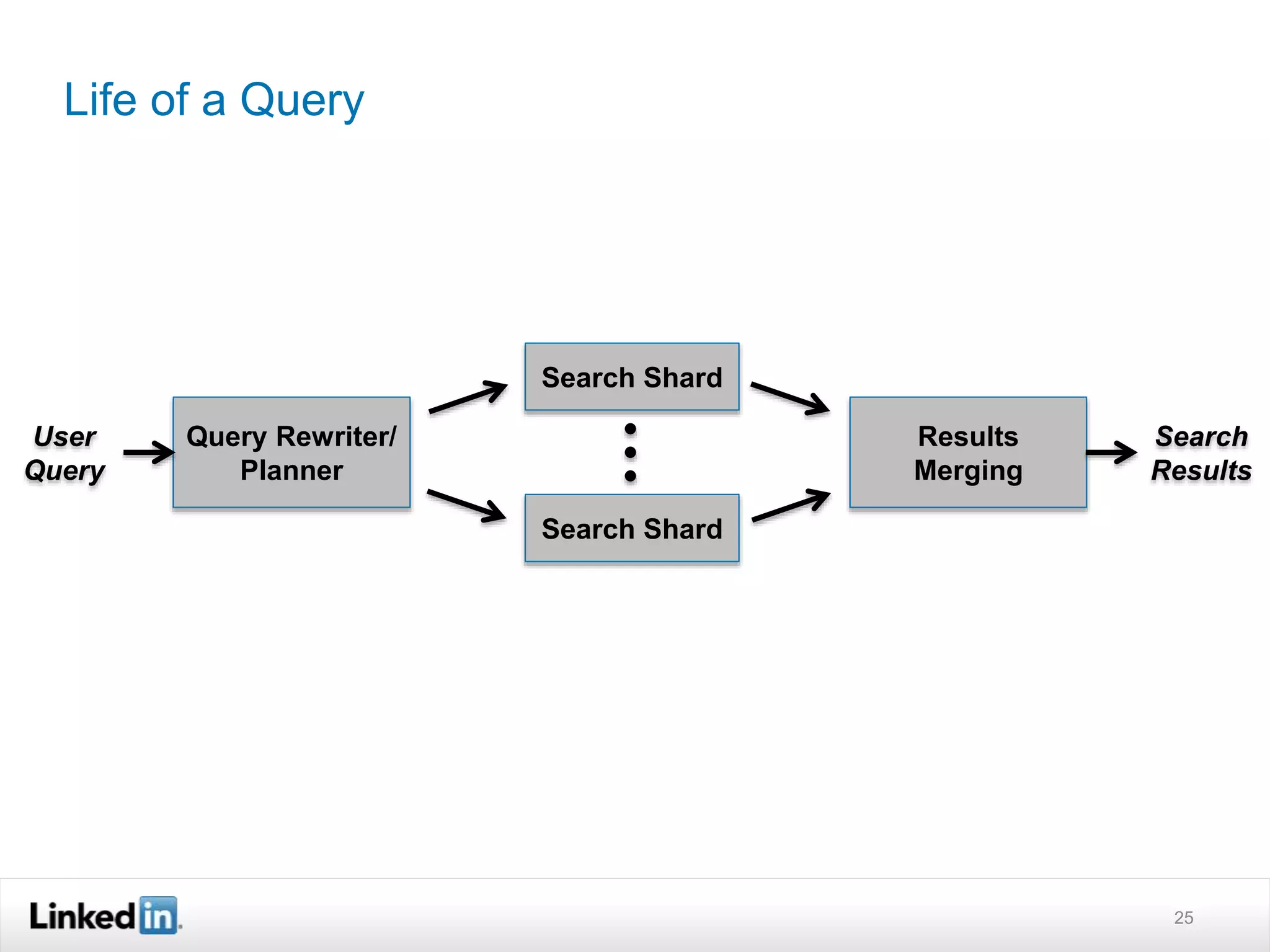
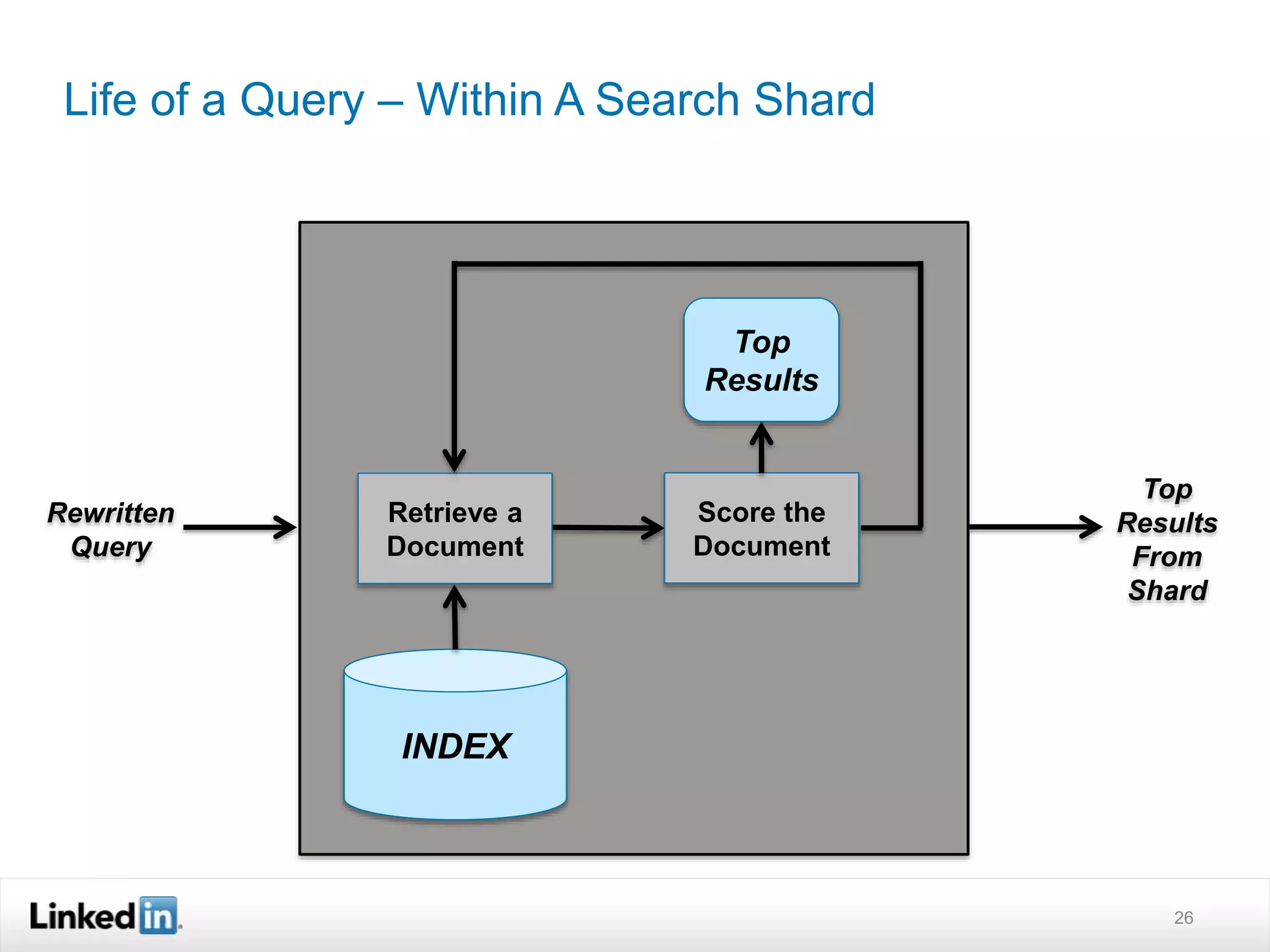
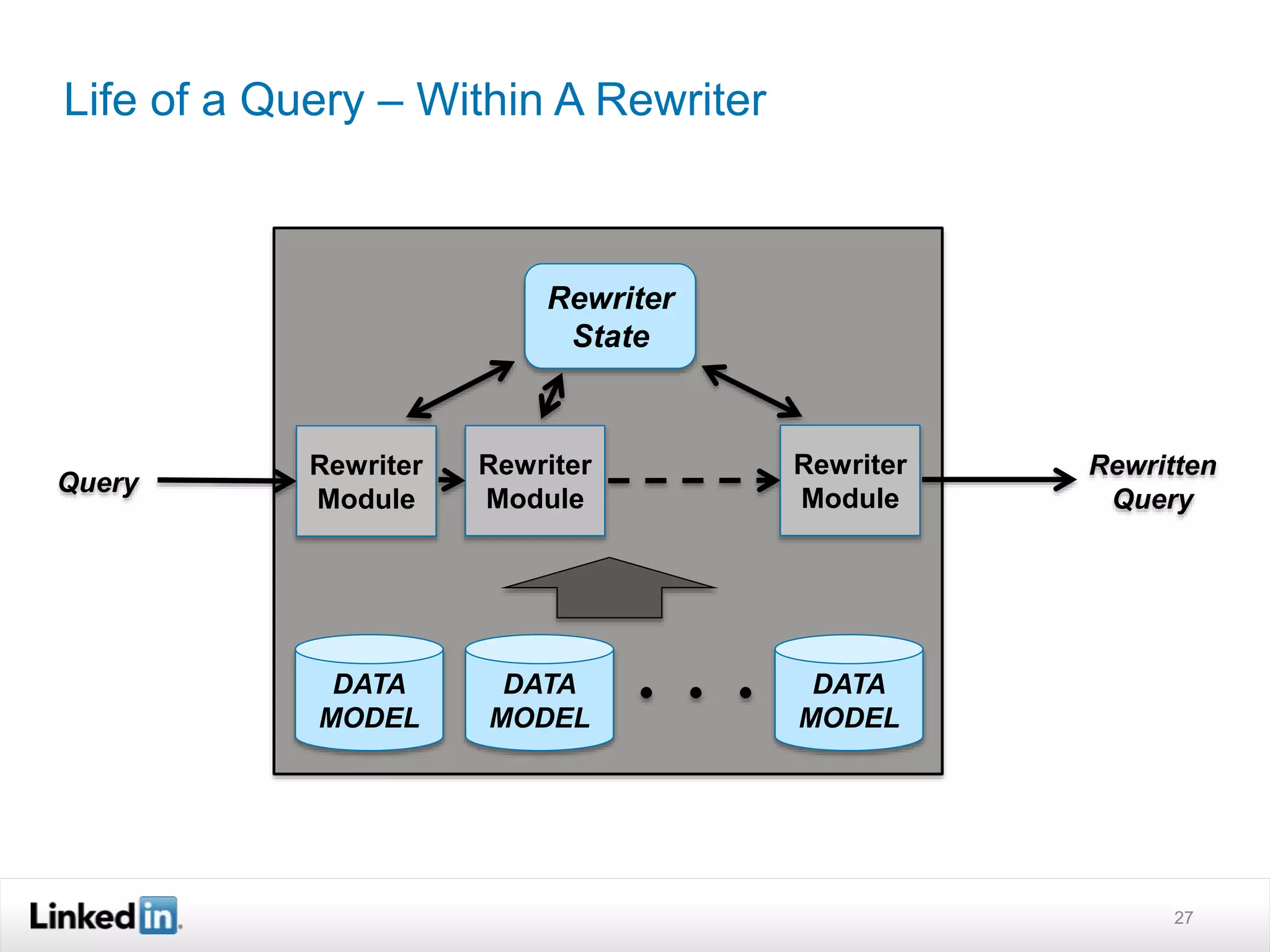
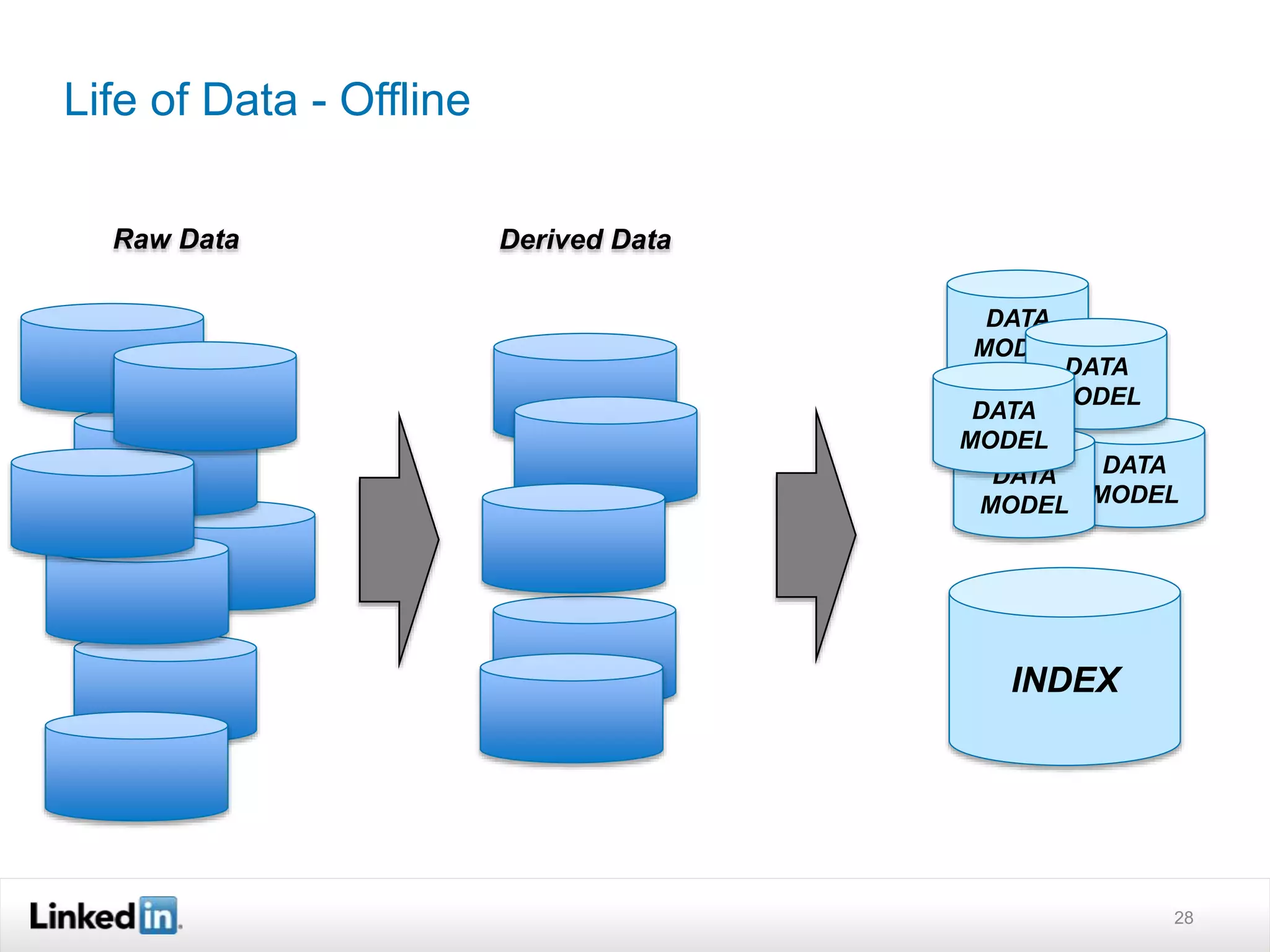



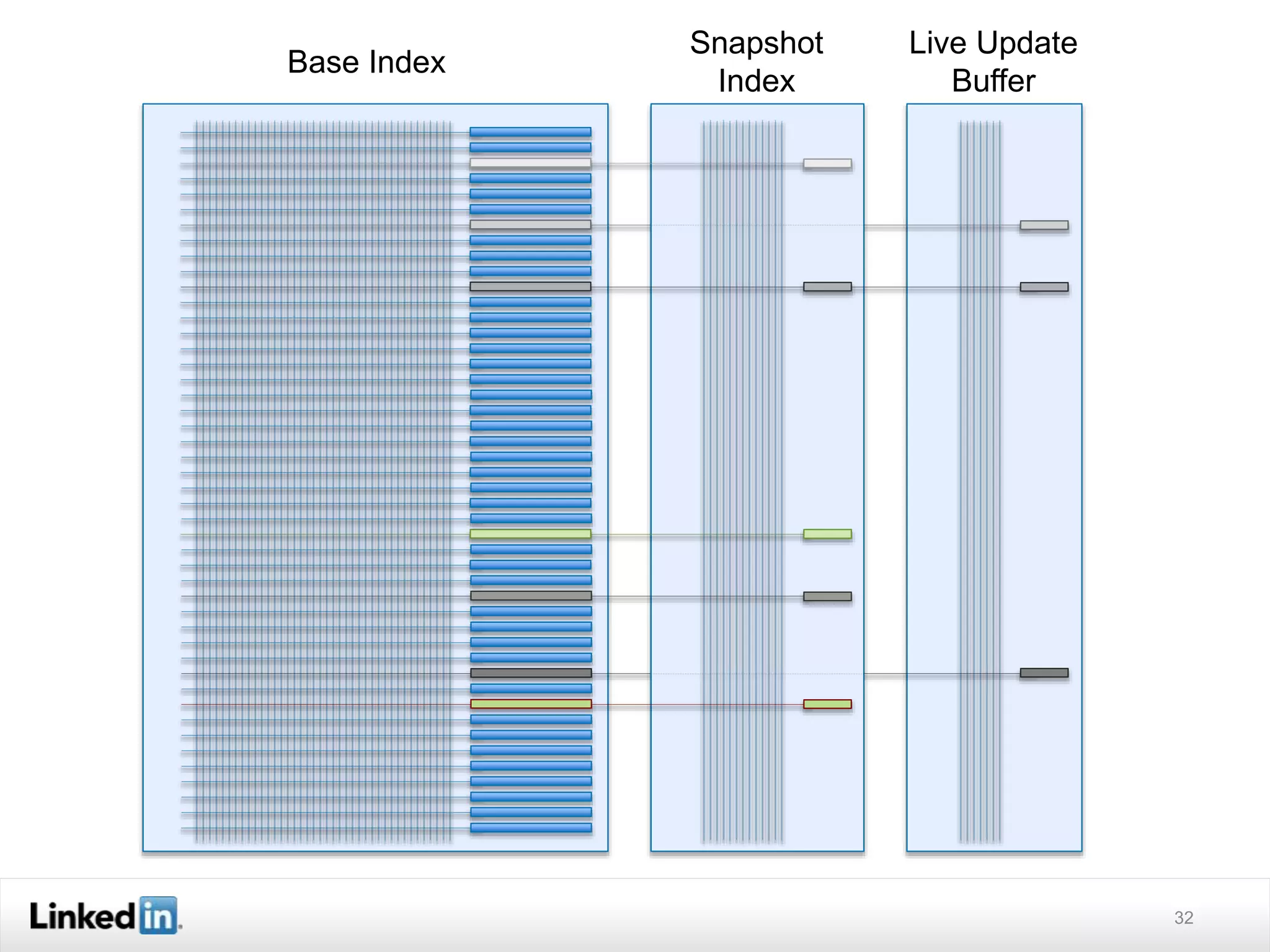



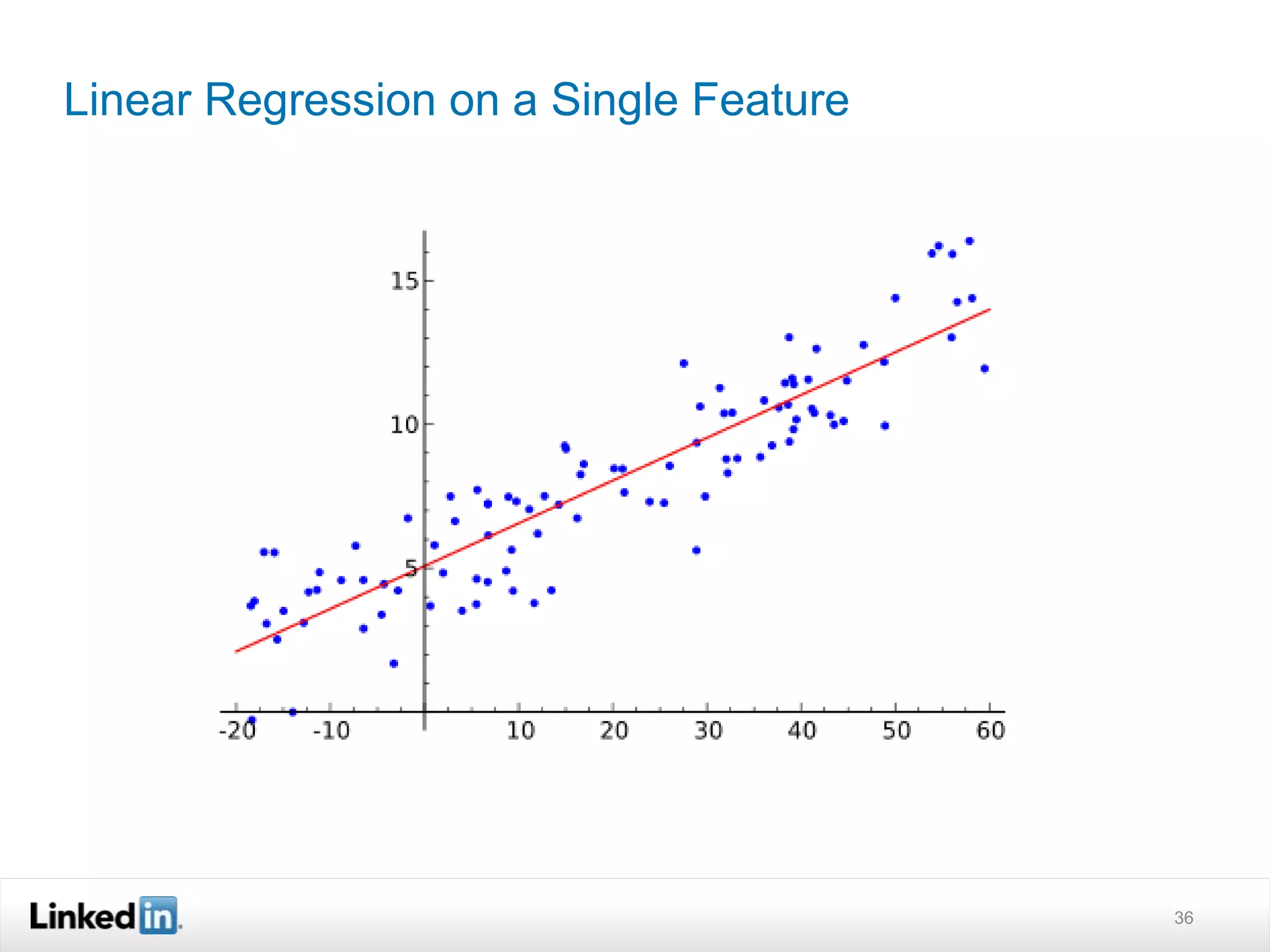
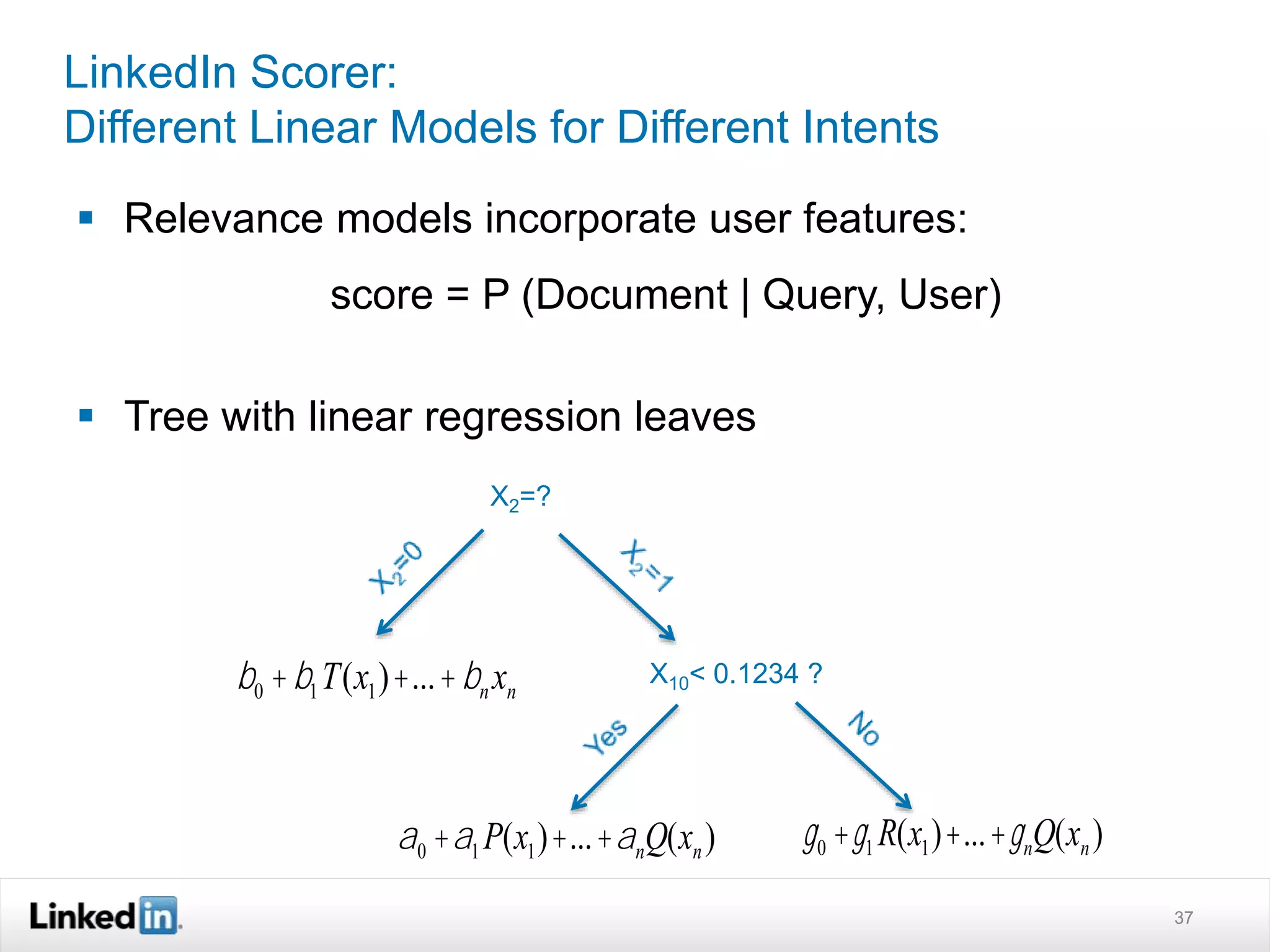

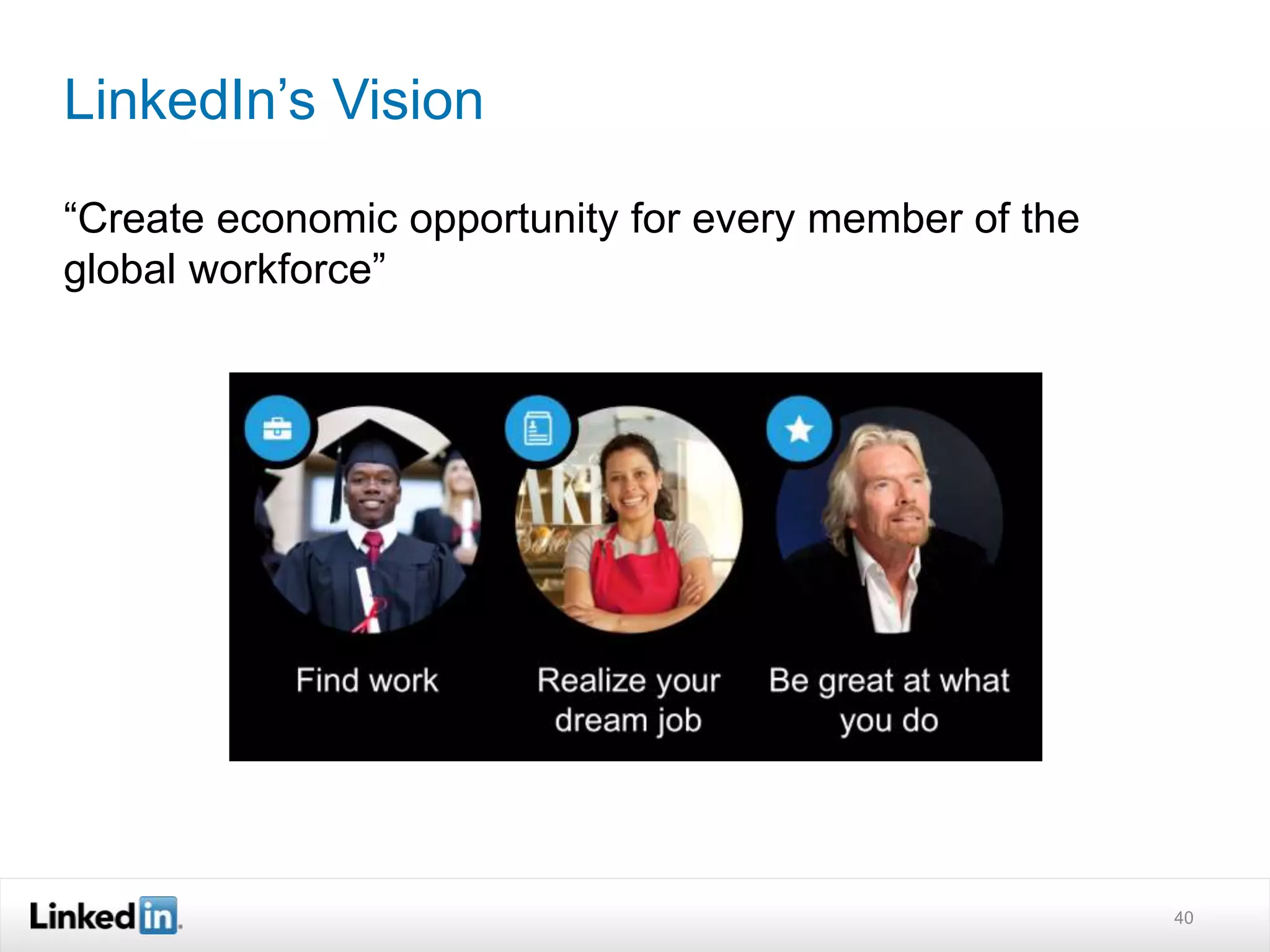
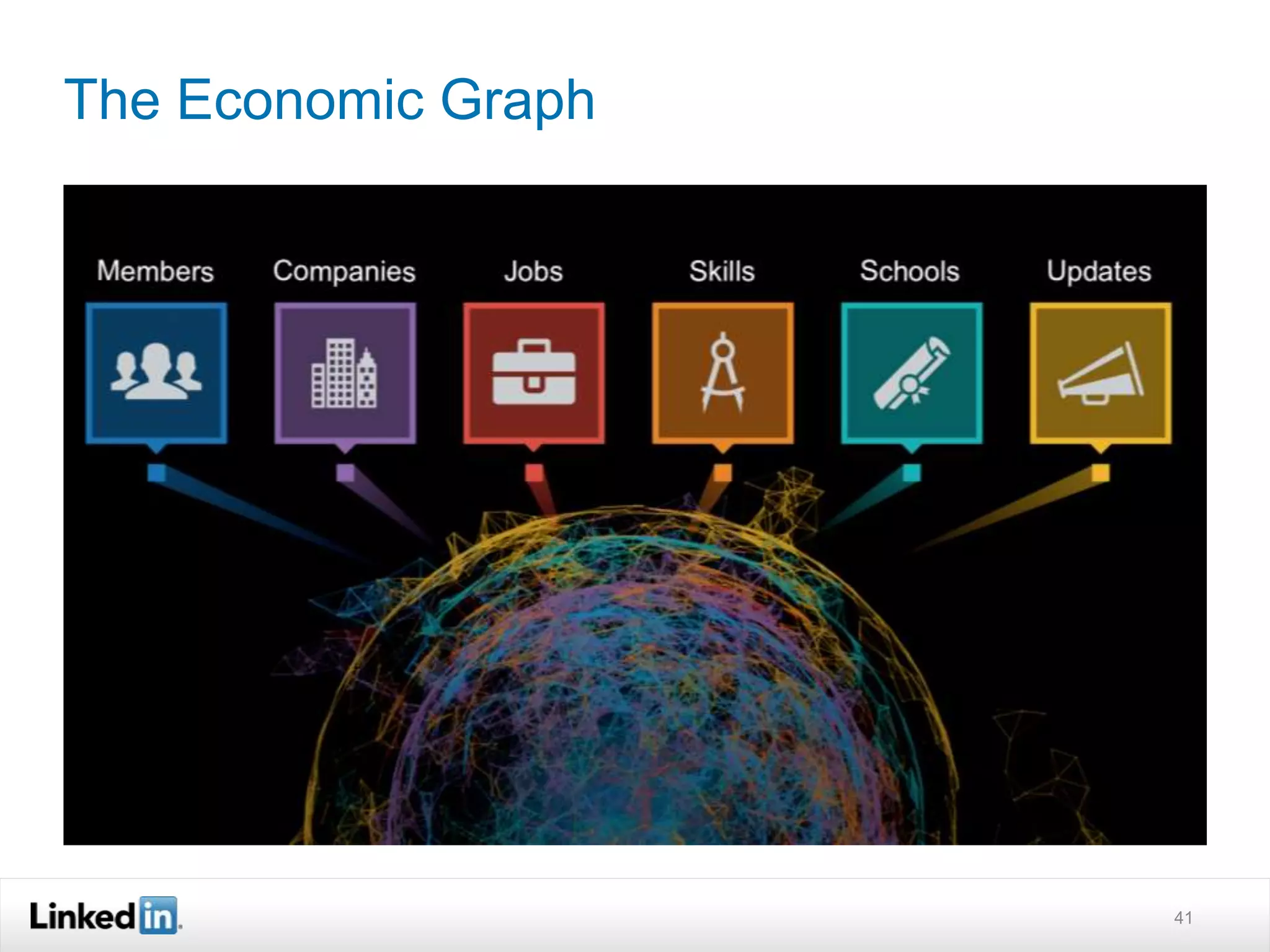
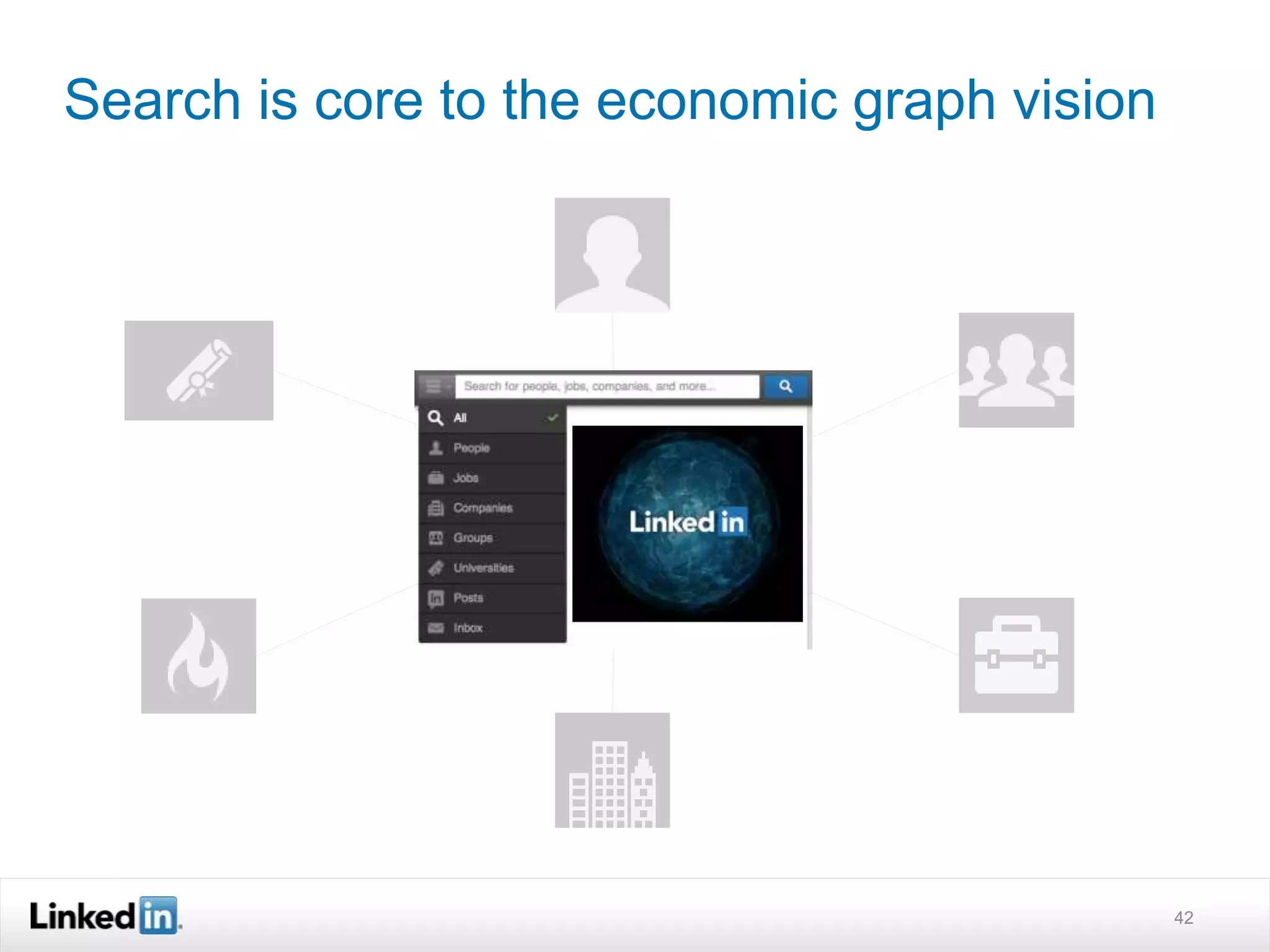
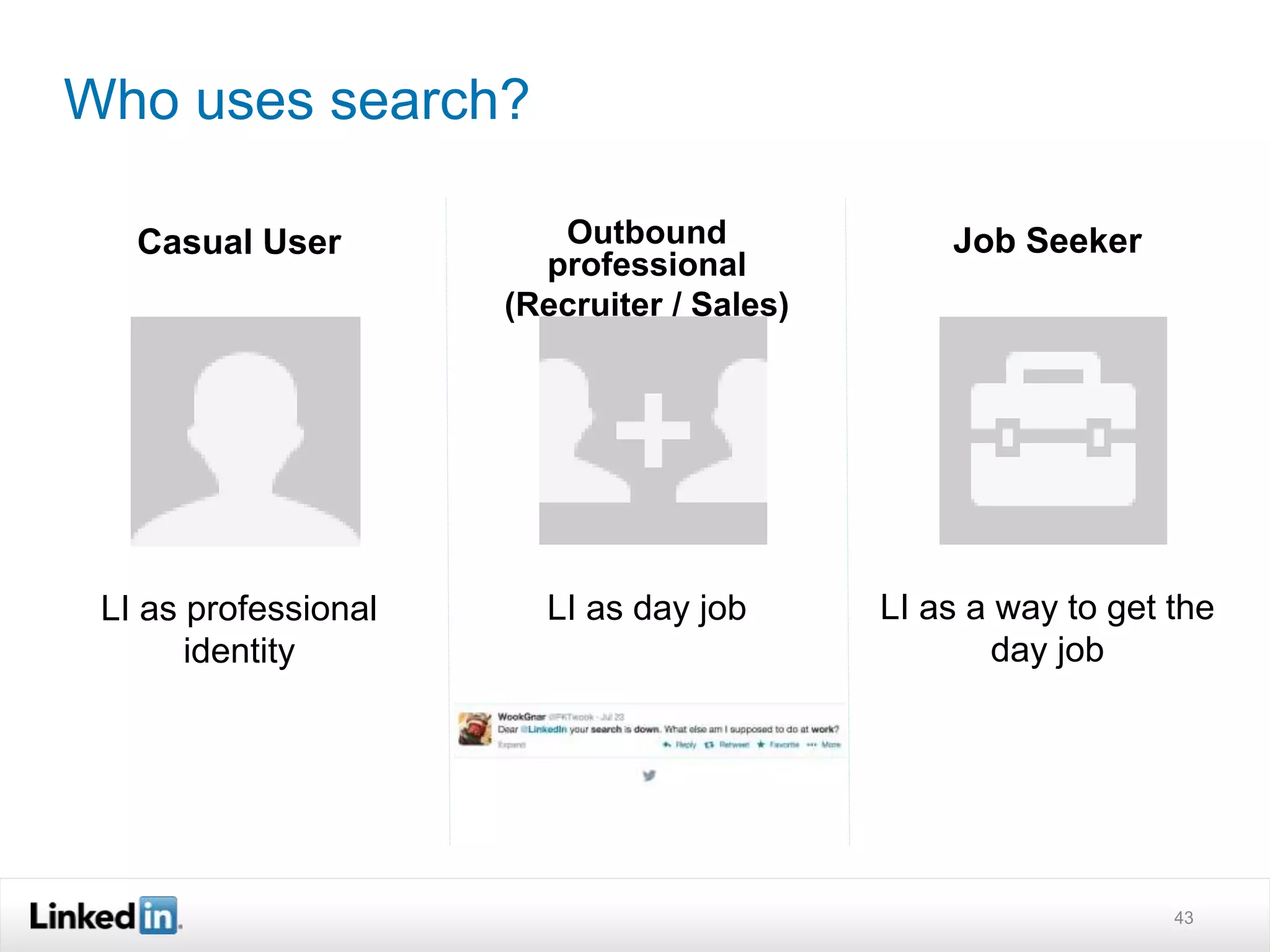
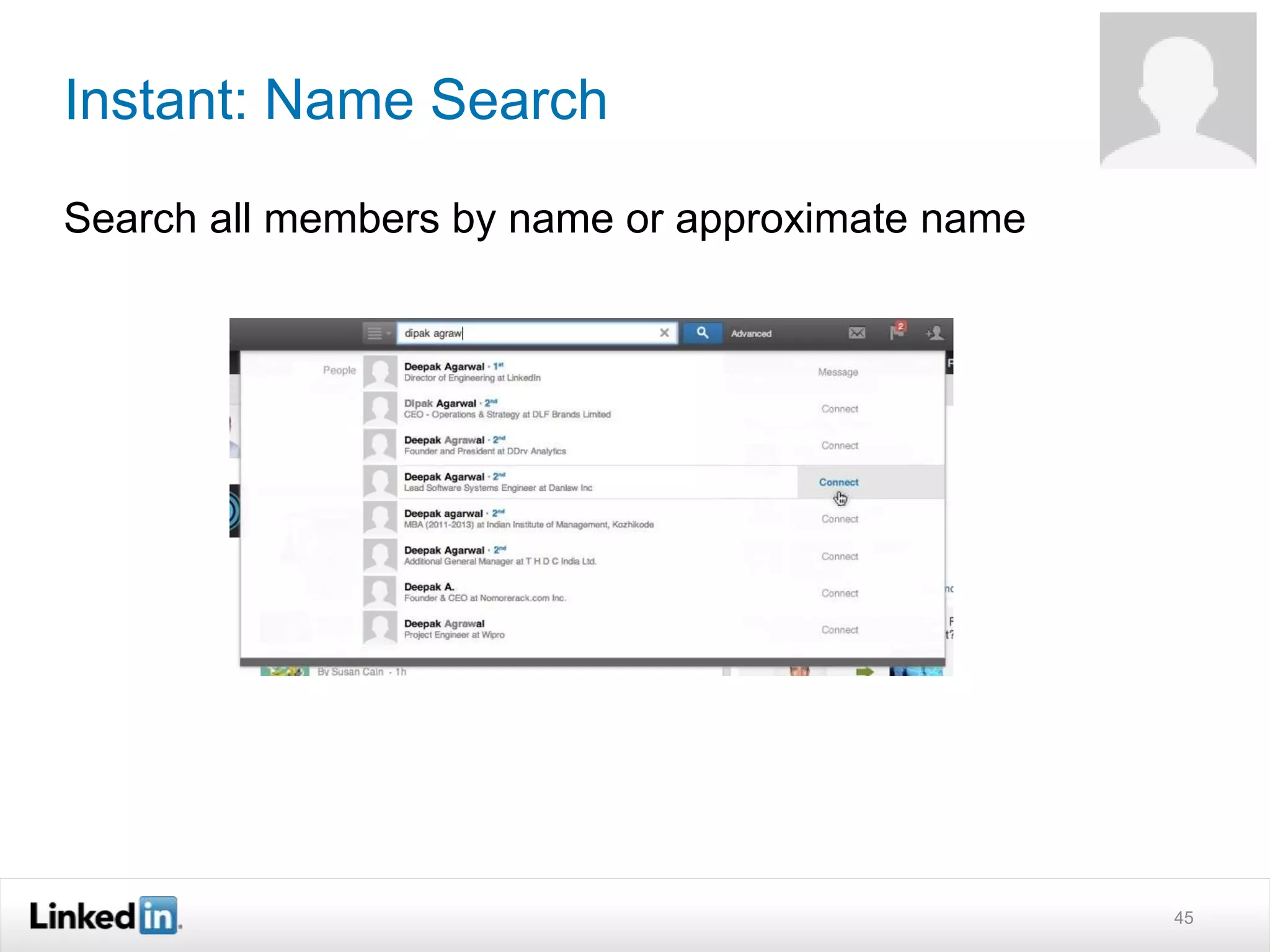
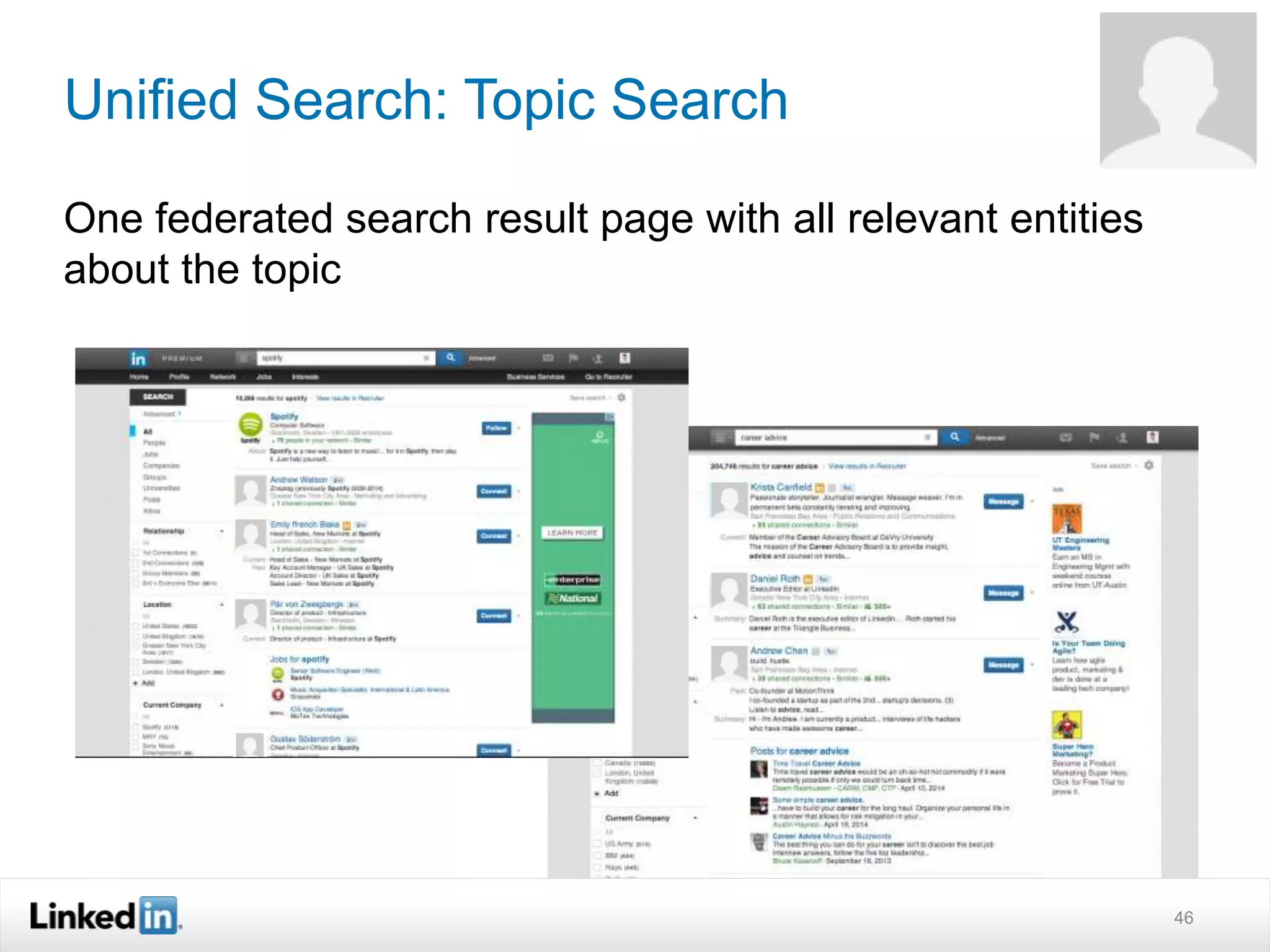
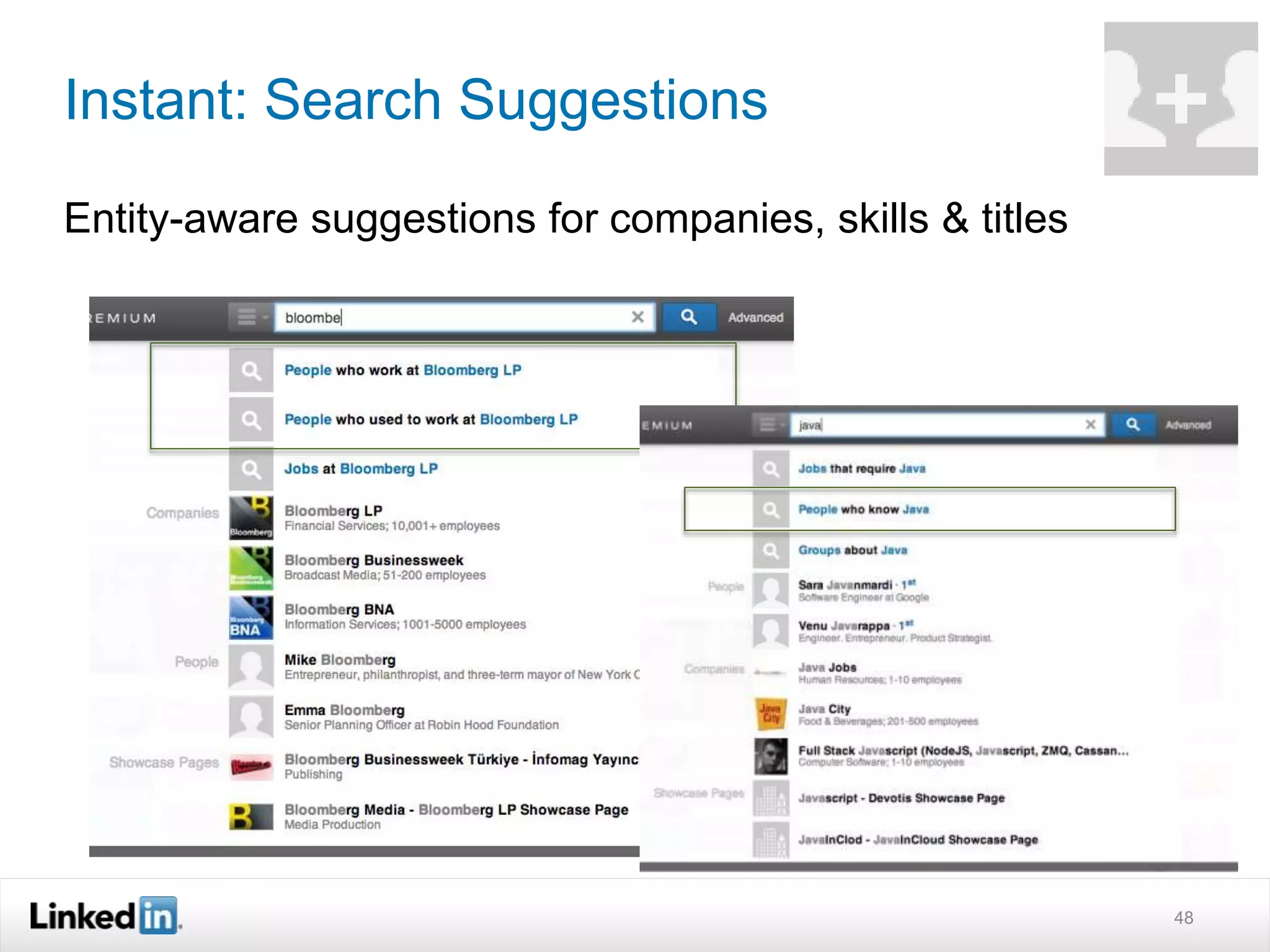
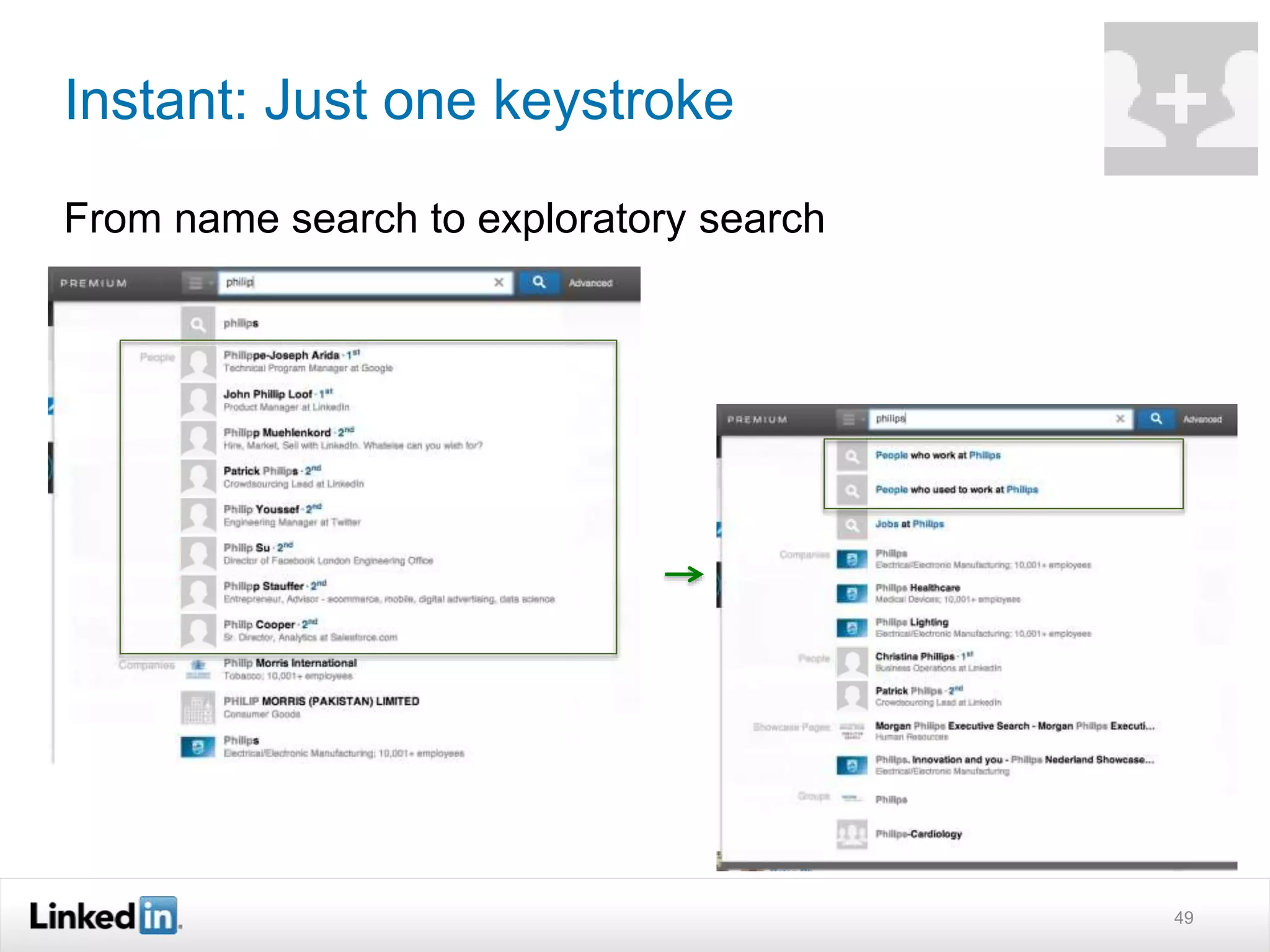
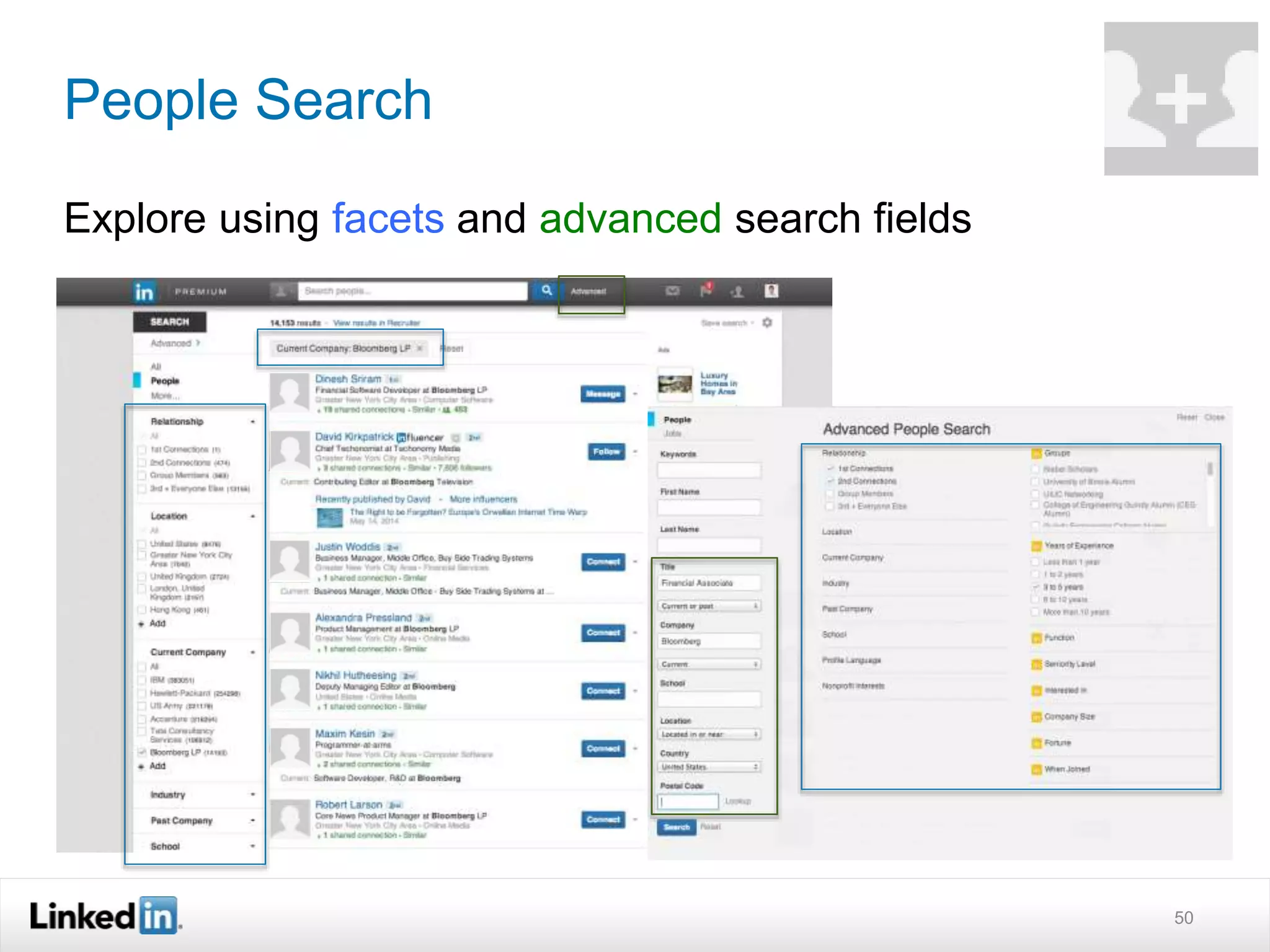
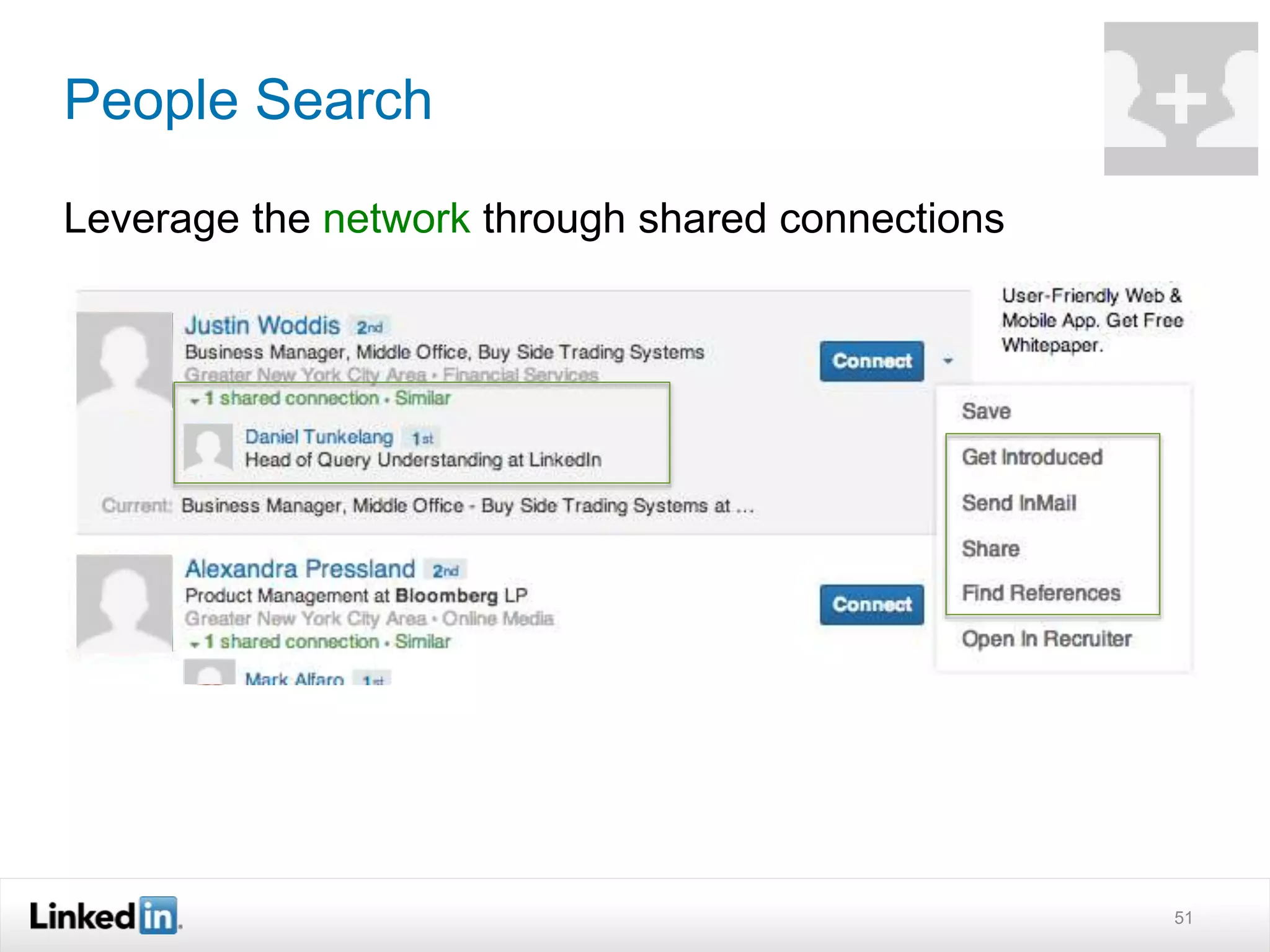
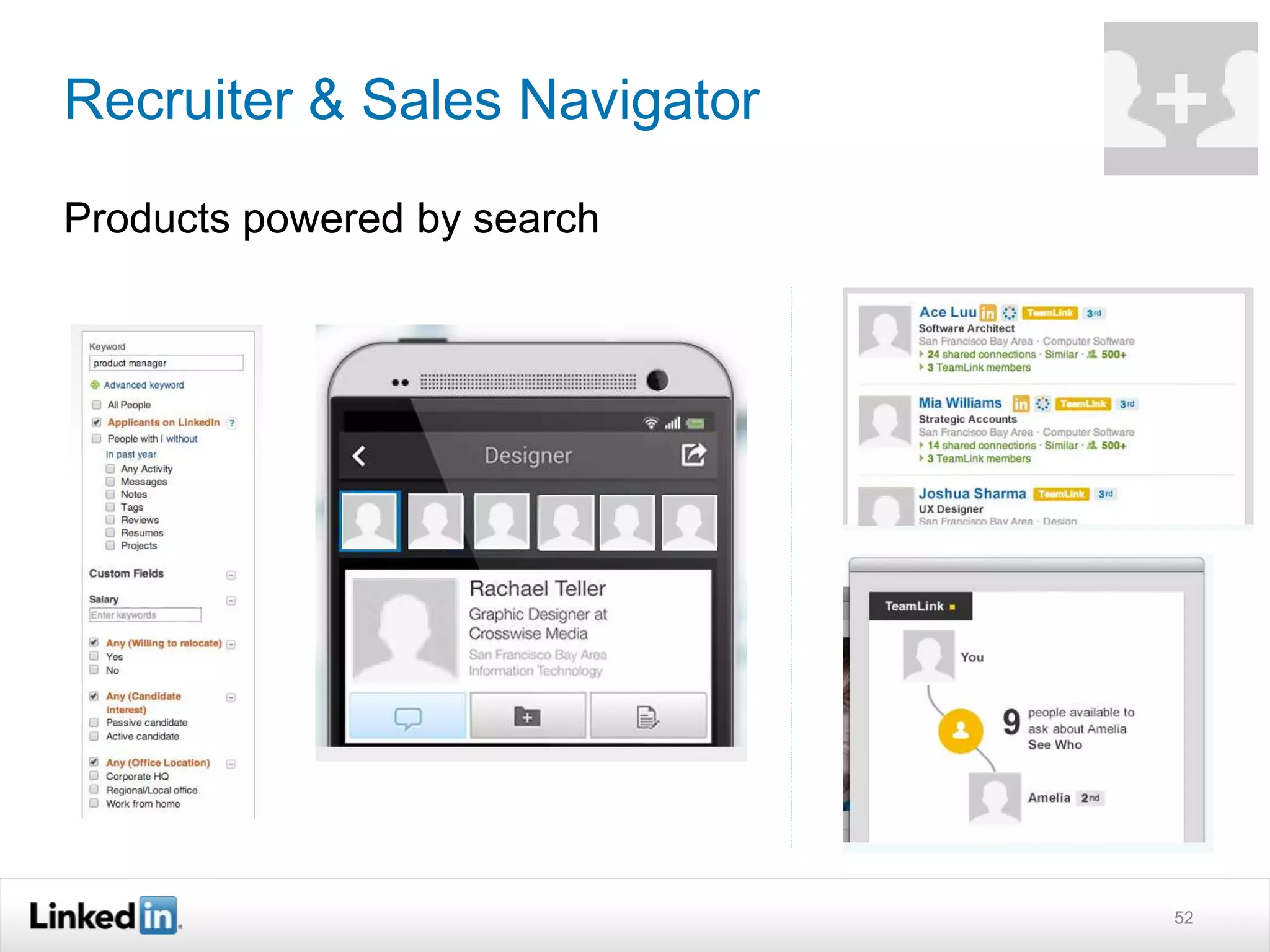
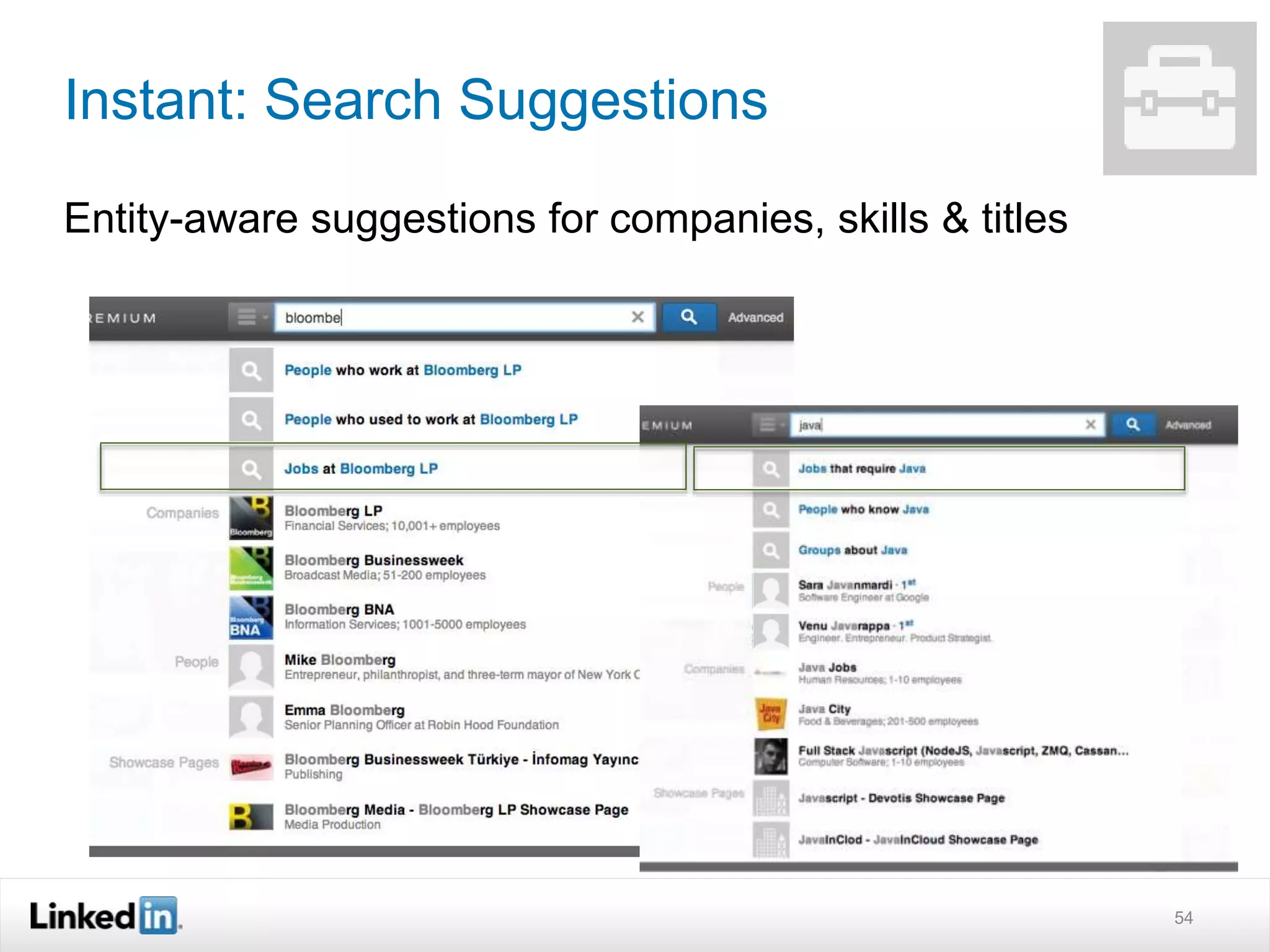
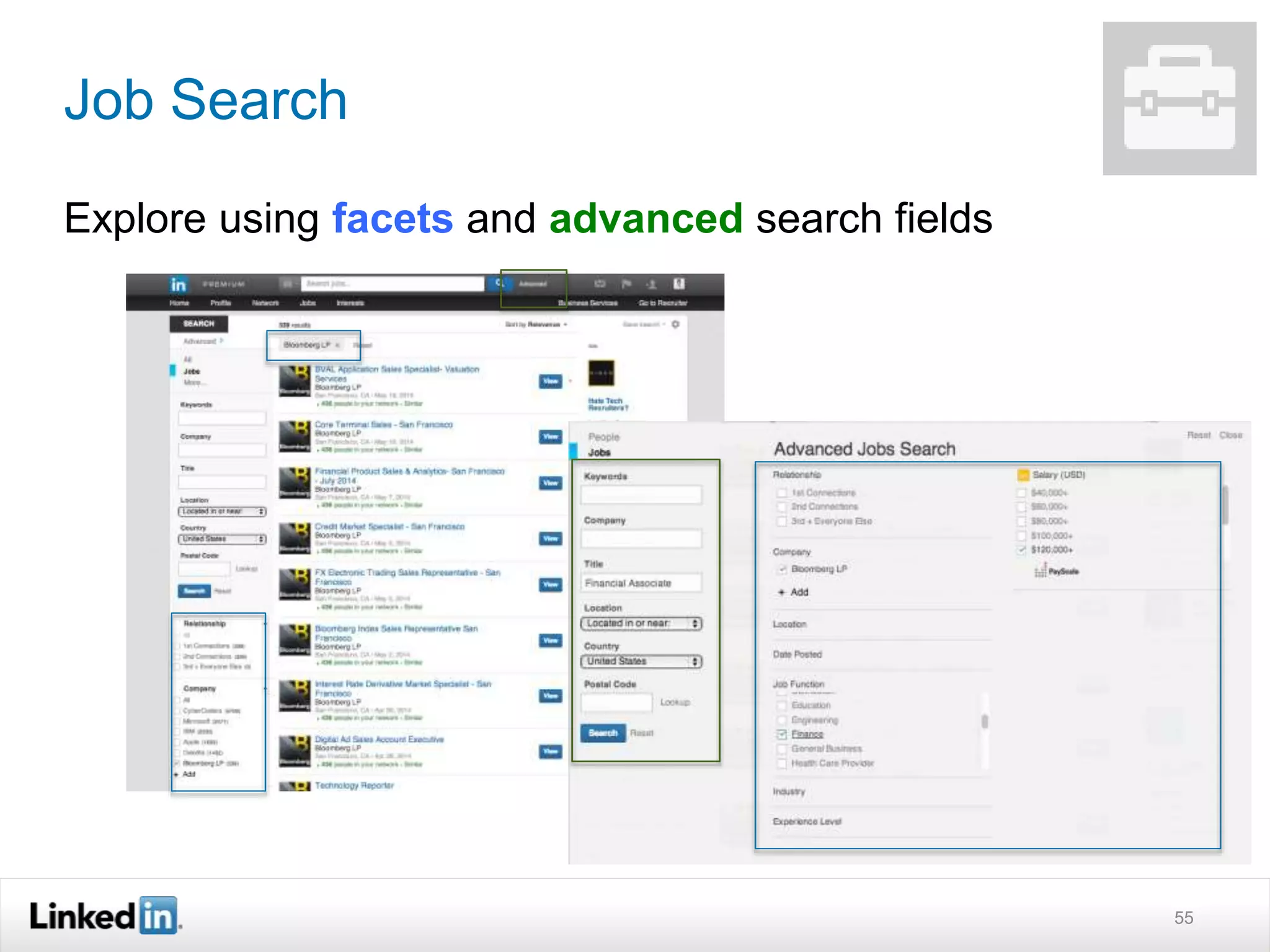
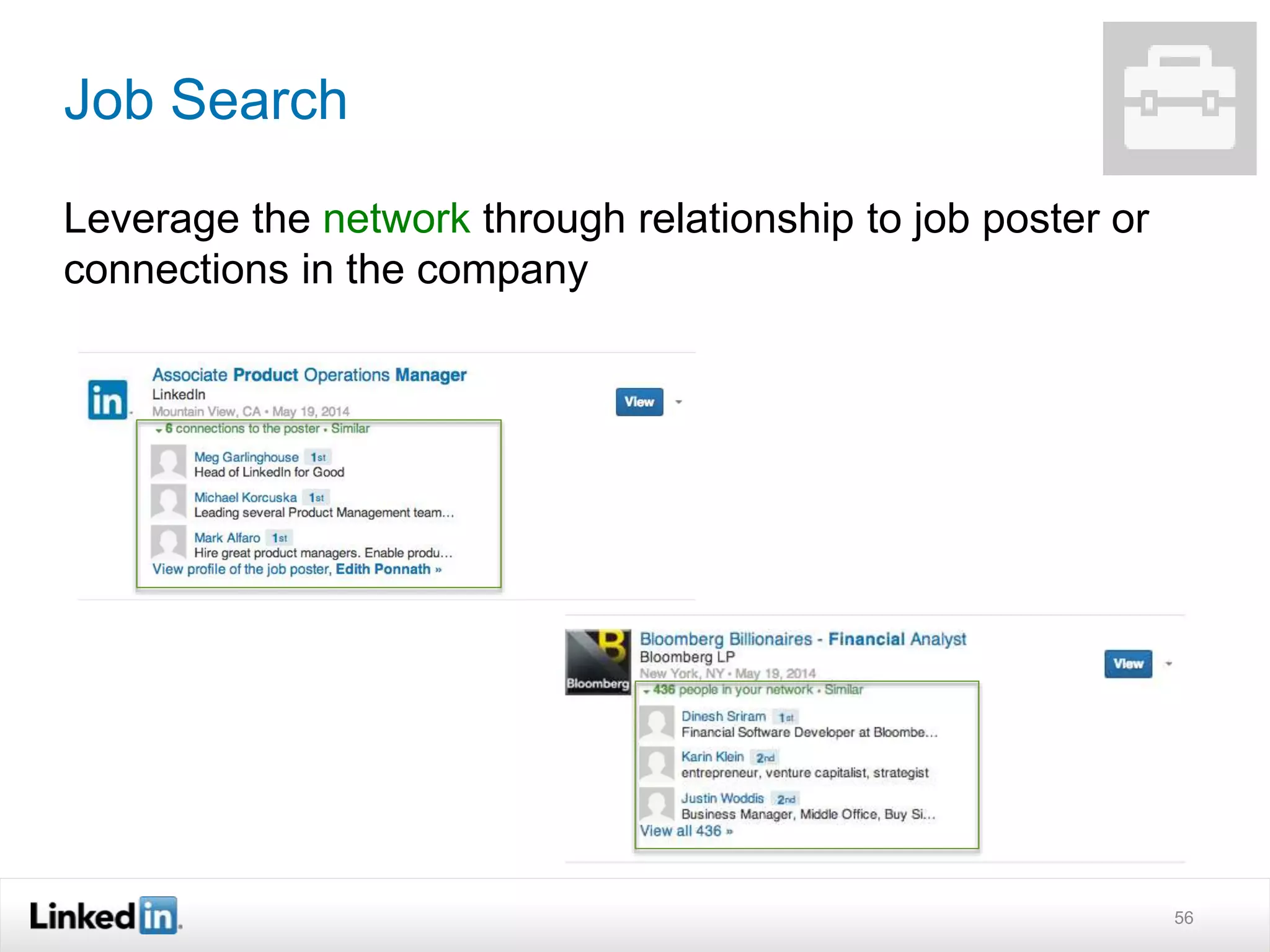




The document discusses LinkedIn's search capabilities and infrastructure. It describes LinkedIn's transition from using open source search components like Lucene to developing their own proprietary search stack. The new stack allows for more flexible indexing, live updates, and relevance capabilities powered by machine learning. Search is a core part of LinkedIn's vision of creating economic opportunity by connecting professionals to jobs, talent, and information through their economic graph.

![[Japanese Content] Sumant Mandal_Opportunites in Big Data, The Hive in Japan,...](https://cdn.slidesharecdn.com/ss_thumbnails/sumantmadalopportunitesinbigdataoct29-130920153150-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Japanese Content] TM Ravi_ Tokyo Presentation_TheHive_Sept 2013](https://cdn.slidesharecdn.com/ss_thumbnails/ravitokyopresentationthehiveoct29-130920153653-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Japanese Content] Lance Riedel_The App Server, The Hive in Tokyo_Aug29](https://cdn.slidesharecdn.com/ss_thumbnails/lanceriedelappserver-thehiveaug29-130920154018-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)













