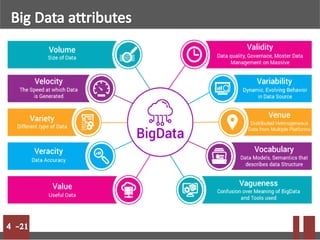
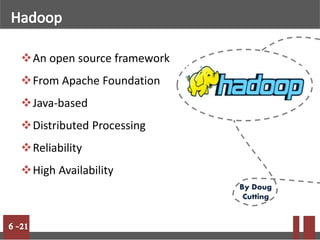
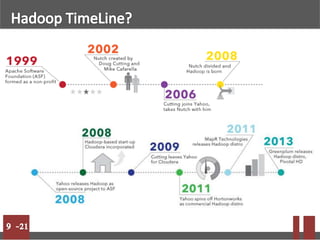
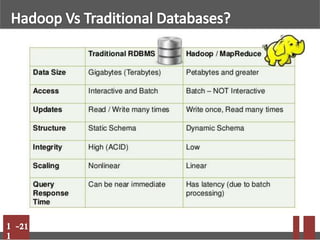
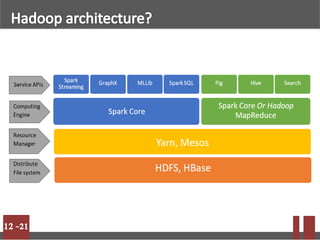
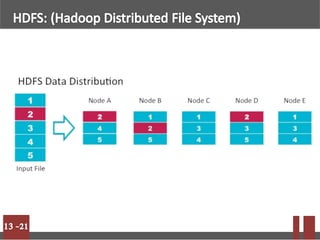
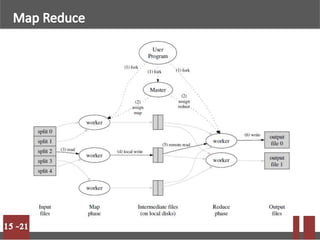
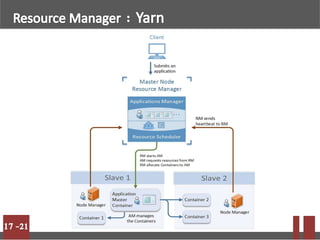
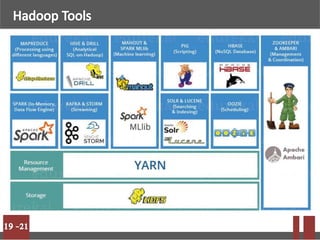
Big data refers to massive volumes of structured and unstructured data that are difficult to process using traditional databases. Hadoop is an open-source framework for distributed storage and processing of big data across clusters of commodity hardware. It uses HDFS for storage and MapReduce as a programming model. HDFS stores data in blocks across nodes for fault tolerance. MapReduce allows parallel processing of large datasets.




























































![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)

















