Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
The Hive
884 views
[Japanese Content] Lance Riedel_The App Server, The Hive in Tokyo_Aug29
Read more
1
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 36
2
/ 36
3
/ 36
4
/ 36
5
/ 36
6
/ 36
7
/ 36
8
/ 36
9
/ 36
10
/ 36
11
/ 36
12
/ 36
13
/ 36
14
/ 36
15
/ 36
16
/ 36
17
/ 36
18
/ 36
19
/ 36
20
/ 36
21
/ 36
22
/ 36
23
/ 36
24
/ 36
25
/ 36
26
/ 36
27
/ 36
28
/ 36
29
/ 36
30
/ 36
31
/ 36
32
/ 36
33
/ 36
34
/ 36
35
/ 36
36
/ 36
More Related Content
PDF
Big Data Visual Analytics Realized By Hadoop and Tableau
by
DataWorks Summit
PDF
Data Engineering Meetup #1 持続可能なデータ基盤のためのデータの多様性に対する取り組み
by
cyberagent
PPTX
AWSで作る分析基盤
by
Yu Otsubo
PDF
The overview of Server-ide Bulk Loader
by
Treasure Data, Inc.
PDF
ビックデータ最適解とAWSにおける新しい武器
by
Akihiro Kuwano
PDF
Smart data integration to hybrid data analysis infrastructure
by
DataWorks Summit
PDF
Dat011 hd insight_+_spark_+_r_を活用した
by
Tech Summit 2016
PDF
re:Growth2019 Analytics Updates
by
Satoru Ishikawa
Big Data Visual Analytics Realized By Hadoop and Tableau
by
DataWorks Summit
Data Engineering Meetup #1 持続可能なデータ基盤のためのデータの多様性に対する取り組み
by
cyberagent
AWSで作る分析基盤
by
Yu Otsubo
The overview of Server-ide Bulk Loader
by
Treasure Data, Inc.
ビックデータ最適解とAWSにおける新しい武器
by
Akihiro Kuwano
Smart data integration to hybrid data analysis infrastructure
by
DataWorks Summit
Dat011 hd insight_+_spark_+_r_を活用した
by
Tech Summit 2016
re:Growth2019 Analytics Updates
by
Satoru Ishikawa
What's hot
PDF
データ基盤の従来~最新の考え方とSynapse Analyticsでの実現
by
Ryoma Nagata
PDF
[DI07] あらゆるデータに価値がある! アンチ断捨離ストのための Azure Data Lake
by
de:code 2017
PDF
データ分析を支える技術 DWH再入門
by
Satoru Ishikawa
KEY
MapReduceからの
by
Shotaro Tsubouchi
PPTX
Glueの開発環境(zeppelin)をrancherで作ってみる
by
cloudfish
PDF
Datastax Enterpriseをはじめよう
by
Yuki Morishita
PDF
Data Architecture
by
Daisuke Inoue
PDF
データ分析基盤について
by
Yuta Inamura
PPTX
Dokkuの活用と内部構造
by
修平 富田
PDF
データ分析基盤、どう作る?システム設計のポイント、教えます - Developers.IO 2019 (20191101)
by
Yosuke Katsuki
PDF
S01 t3 data_engineer
by
Takeshi Akutsu
PDF
Serverless analytics on aws
by
Amazon Web Services Japan
PDF
ARC-001_Updated: 5 年後のアプリケーション アーキテクチャを考える
by
decode2016
PDF
BigData-JAWS#16 Lake House Architecture
by
Satoru Ishikawa
PDF
Orchestrate DBaaS入門
by
Tsukasa Kawagishi
PDF
Datalake最新情報セミナー
by
mtanaka0111
PDF
クラウドを活用した自由自在なデータ分析
by
aiichiro
PPTX
Use case and Live demo : Agile data integration from Legacy system to Hadoop ...
by
DataWorks Summit/Hadoop Summit
PDF
Gtfsデータリポジトリ紹介 iodd発表資料
by
Shimpei Matsuura
データ基盤の従来~最新の考え方とSynapse Analyticsでの実現
by
Ryoma Nagata
[DI07] あらゆるデータに価値がある! アンチ断捨離ストのための Azure Data Lake
by
de:code 2017
データ分析を支える技術 DWH再入門
by
Satoru Ishikawa
MapReduceからの
by
Shotaro Tsubouchi
Glueの開発環境(zeppelin)をrancherで作ってみる
by
cloudfish
Datastax Enterpriseをはじめよう
by
Yuki Morishita
Data Architecture
by
Daisuke Inoue
データ分析基盤について
by
Yuta Inamura
Dokkuの活用と内部構造
by
修平 富田
データ分析基盤、どう作る?システム設計のポイント、教えます - Developers.IO 2019 (20191101)
by
Yosuke Katsuki
S01 t3 data_engineer
by
Takeshi Akutsu
Serverless analytics on aws
by
Amazon Web Services Japan
ARC-001_Updated: 5 年後のアプリケーション アーキテクチャを考える
by
decode2016
BigData-JAWS#16 Lake House Architecture
by
Satoru Ishikawa
Orchestrate DBaaS入門
by
Tsukasa Kawagishi
Datalake最新情報セミナー
by
mtanaka0111
クラウドを活用した自由自在なデータ分析
by
aiichiro
Use case and Live demo : Agile data integration from Legacy system to Hadoop ...
by
DataWorks Summit/Hadoop Summit
Gtfsデータリポジトリ紹介 iodd発表資料
by
Shimpei Matsuura
Viewers also liked
PPTX
1.nigam shah stanford_meetup
by
The Hive
PDF
Big Data App servor by Lance Riedel, CTO, The Hive for The Hive India event
by
The Hive
PPTX
The Hive "Data Virtualization" Introduction - Jim Green, CEO of Composite Sof...
by
The Hive
PPTX
Advanced Visual Analytics and Real-time Analytics at Platform scale by Brian ...
by
The Hive
PDF
Opportunites in Big Data by Sumant Mandal, Founder of The Hive for The Hive I...
by
The Hive
PPTX
Search at Linkedin by Sriram Sankar and Kumaresh Pattabiraman
by
The Hive
PPTX
The Hive Think Tank: Rocking the Database World with RocksDB
by
The Hive
PPTX
Leanplum_Controlled Experimentation_Panel_The Hive
by
The Hive
PDF
Startup Series: Lean Analytics, Innovation, and Tilting at Windmills
by
The Hive
PDF
Untethered health in a networked society by James Mathews
by
The Hive
PDF
Mumhsocialpdf
by
Lissah Dunston
PDF
Expt panel hive_data_rp_20130320_final-1
by
The Hive
PPTX
My magazine edited
by
sofiamorana1
PPT
Chictopia for Mobile & Social Commerce panel discussion
by
The Hive
PPTX
La musica
by
sandramucua
PPT
Redbook
by
ens007
PPS
San martin 2013 2014
by
Joserra Abarretegui
PPT
San martin 2013 2014
by
Joserra Abarretegui
PPTX
Pre production planning
by
sofiamorana1
PPS
Very beautiful
by
asmaeazed
1.nigam shah stanford_meetup
by
The Hive
Big Data App servor by Lance Riedel, CTO, The Hive for The Hive India event
by
The Hive
The Hive "Data Virtualization" Introduction - Jim Green, CEO of Composite Sof...
by
The Hive
Advanced Visual Analytics and Real-time Analytics at Platform scale by Brian ...
by
The Hive
Opportunites in Big Data by Sumant Mandal, Founder of The Hive for The Hive I...
by
The Hive
Search at Linkedin by Sriram Sankar and Kumaresh Pattabiraman
by
The Hive
The Hive Think Tank: Rocking the Database World with RocksDB
by
The Hive
Leanplum_Controlled Experimentation_Panel_The Hive
by
The Hive
Startup Series: Lean Analytics, Innovation, and Tilting at Windmills
by
The Hive
Untethered health in a networked society by James Mathews
by
The Hive
Mumhsocialpdf
by
Lissah Dunston
Expt panel hive_data_rp_20130320_final-1
by
The Hive
My magazine edited
by
sofiamorana1
Chictopia for Mobile & Social Commerce panel discussion
by
The Hive
La musica
by
sandramucua
Redbook
by
ens007
San martin 2013 2014
by
Joserra Abarretegui
San martin 2013 2014
by
Joserra Abarretegui
Pre production planning
by
sofiamorana1
Very beautiful
by
asmaeazed
Similar to [Japanese Content] Lance Riedel_The App Server, The Hive in Tokyo_Aug29
PDF
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
PPTX
ビッグデータ活用支援フォーラム
by
Recruit Technologies
PDF
避けては通れないビッグデータ周辺の重要課題
by
kurikiyo
PPTX
WebDB Forum 2012 基調講演資料
by
Recruit Technologies
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PPTX
ビッグデータ&データマネジメント展
by
Recruit Technologies
PDF
Hadoop/AI基盤における考慮点、PoCの進め方、基盤構成例
by
日本ヒューレット・パッカード株式会社
PPTX
BigData Architecture for Azure
by
Ryoma Nagata
PDF
Data platformdesign
by
Ryoma Nagata
PDF
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
PPTX
ビッグデータ処理データベースの全体像と使い分け - 2017年 Version -
by
Tetsutaro Watanabe
PPTX
ビッグデータ処理データベースの全体像と使い分け 2018年version
by
Tetsutaro Watanabe
PDF
スケーラブルなシステムのためのHBaseスキーマ設計 #hcj13w
by
Cloudera Japan
PDF
[INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop
by
Insight Technology, Inc.
PPTX
Dat009 クラウドでビック
by
Tech Summit 2016
PDF
Dat009 クラウドでビック
by
Tech Summit 2016
PDF
マイニング探検会#10
by
Yoji Kiyota
PDF
Osc2012 spring HBase Report
by
Seiichiro Ishida
PPTX
Cloudera大阪セミナー 20130219
by
Cloudera Japan
PDF
クラウドストレージの基礎知識(Cloudian white paper)
by
CLOUDIAN KK
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
ビッグデータ活用支援フォーラム
by
Recruit Technologies
避けては通れないビッグデータ周辺の重要課題
by
kurikiyo
WebDB Forum 2012 基調講演資料
by
Recruit Technologies
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
ビッグデータ&データマネジメント展
by
Recruit Technologies
Hadoop/AI基盤における考慮点、PoCの進め方、基盤構成例
by
日本ヒューレット・パッカード株式会社
BigData Architecture for Azure
by
Ryoma Nagata
Data platformdesign
by
Ryoma Nagata
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
ビッグデータ処理データベースの全体像と使い分け - 2017年 Version -
by
Tetsutaro Watanabe
ビッグデータ処理データベースの全体像と使い分け 2018年version
by
Tetsutaro Watanabe
スケーラブルなシステムのためのHBaseスキーマ設計 #hcj13w
by
Cloudera Japan
[INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop
by
Insight Technology, Inc.
Dat009 クラウドでビック
by
Tech Summit 2016
Dat009 クラウドでビック
by
Tech Summit 2016
マイニング探検会#10
by
Yoji Kiyota
Osc2012 spring HBase Report
by
Seiichiro Ishida
Cloudera大阪セミナー 20130219
by
Cloudera Japan
クラウドストレージの基礎知識(Cloudian white paper)
by
CLOUDIAN KK
More from The Hive
PDF
The Hive Think Tank: AI in The Enterprise by Venkat Srinivasan
by
The Hive
PDF
AI in Software for Augmenting Intelligence Across the Enterprise
by
The Hive
PPTX
The Hive Think Tank: Translating IoT into Innovation at Every Level by Prith ...
by
The Hive
PPTX
The Hive Think Tank: Unpacking AI for Healthcare
by
The Hive
PDF
The Hive Think Tank: The Content Trap - Strategist's Guide to Digital Change
by
The Hive
PPTX
Social Impact & Ethics of AI by Steve Omohundro
by
The Hive
PPTX
Translating a Trillion Points of Data into Therapies, Diagnostics, and New In...
by
The Hive
PPTX
Deep Visual Understanding from Deep Learning by Prof. Jitendra Malik
by
The Hive
PDF
The Hive Think Tank - The Microsoft Big Data Stack by Raghu Ramakrishnan, CTO...
by
The Hive
PDF
Data Science in the Enterprise
by
The Hive
PDF
Digital Transformation; Digital Twins for Delivering Business Value in IIoT
by
The Hive
PPTX
The Hive Think Tank: Rendezvous Architecture Makes Machine Learning Logistics...
by
The Hive
PPTX
"The Future of Manufacturing" by Sujeet Chand, SVP&CTO, Rockwell Automation
by
The Hive
PDF
The Hive Think Tank: Heron at Twitter
by
The Hive
PDF
The Hive Think Tank: The Future Of Customer Support - AI Driven Automation
by
The Hive
PDF
Quantum Computing (IBM Q) - Hive Think Tank Event w/ Dr. Bob Sutor - 02.22.18
by
The Hive
PPTX
The Hive Think Tank: Talk by Mohandas Pai - India at 2030, How Tech Entrepren...
by
The Hive
PPTX
“ High Precision Analytics for Healthcare: Promises and Challenges” by Sriram...
by
The Hive
PDF
The Hive Think Tank: Machine Learning Applications in Genomics by Prof. Jian ...
by
The Hive
PDF
"Responsible AI", by Charlie Muirhead
by
The Hive
The Hive Think Tank: AI in The Enterprise by Venkat Srinivasan
by
The Hive
AI in Software for Augmenting Intelligence Across the Enterprise
by
The Hive
The Hive Think Tank: Translating IoT into Innovation at Every Level by Prith ...
by
The Hive
The Hive Think Tank: Unpacking AI for Healthcare
by
The Hive
The Hive Think Tank: The Content Trap - Strategist's Guide to Digital Change
by
The Hive
Social Impact & Ethics of AI by Steve Omohundro
by
The Hive
Translating a Trillion Points of Data into Therapies, Diagnostics, and New In...
by
The Hive
Deep Visual Understanding from Deep Learning by Prof. Jitendra Malik
by
The Hive
The Hive Think Tank - The Microsoft Big Data Stack by Raghu Ramakrishnan, CTO...
by
The Hive
Data Science in the Enterprise
by
The Hive
Digital Transformation; Digital Twins for Delivering Business Value in IIoT
by
The Hive
The Hive Think Tank: Rendezvous Architecture Makes Machine Learning Logistics...
by
The Hive
"The Future of Manufacturing" by Sujeet Chand, SVP&CTO, Rockwell Automation
by
The Hive
The Hive Think Tank: Heron at Twitter
by
The Hive
The Hive Think Tank: The Future Of Customer Support - AI Driven Automation
by
The Hive
Quantum Computing (IBM Q) - Hive Think Tank Event w/ Dr. Bob Sutor - 02.22.18
by
The Hive
The Hive Think Tank: Talk by Mohandas Pai - India at 2030, How Tech Entrepren...
by
The Hive
“ High Precision Analytics for Healthcare: Promises and Challenges” by Sriram...
by
The Hive
The Hive Think Tank: Machine Learning Applications in Genomics by Prof. Jian ...
by
The Hive
"Responsible AI", by Charlie Muirhead
by
The Hive
[Japanese Content] Lance Riedel_The App Server, The Hive in Tokyo_Aug29
1.
Big Data App
Server ビッグデータアプリケーションサーバー Lance Riedel
2.
Big Data App
Server ビッグデータアプリケーションサーバー 4つの「V」に向けた新しいアプリケーション フレームワーク: • 大量(Volume)の生データ (ペタバイト級) • 超高速(Velocity)で生成・取得される データ • 多様(Variety)なデータソースとスキーマ • 価値(Value)を引き出す 最新データサイエンス・分析技術を搭載
4.
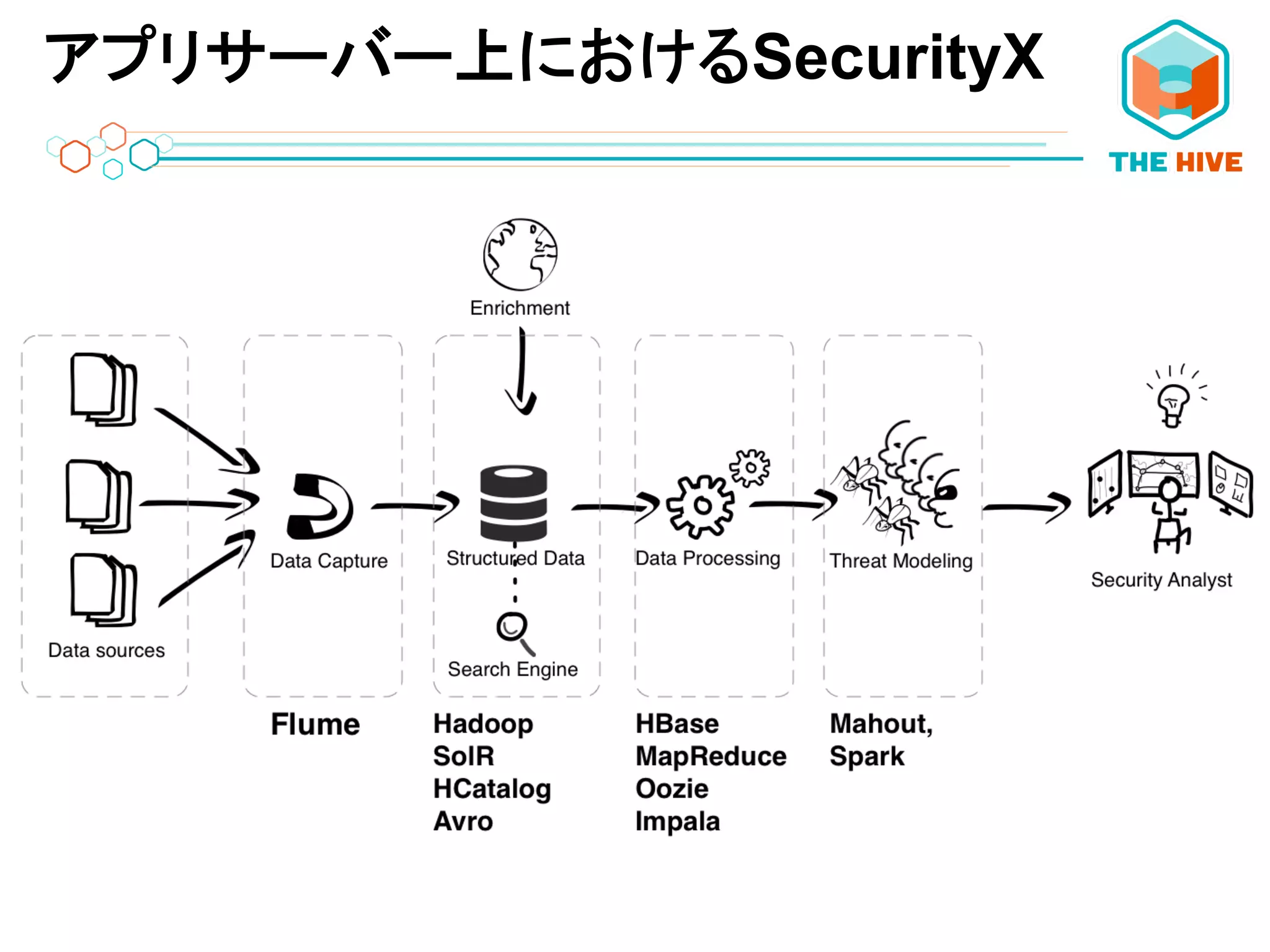
ビッグデータアプリケーションのユースケース • ログ/マシン分析 •
セキュリティ/不正検出 • センサーデータ分析 • フィナンシャル(金融)分析 • リテール(小売)分析 • 広告ターゲティング • レコメンデーション (例:Ne;lix, Amazon)
5.
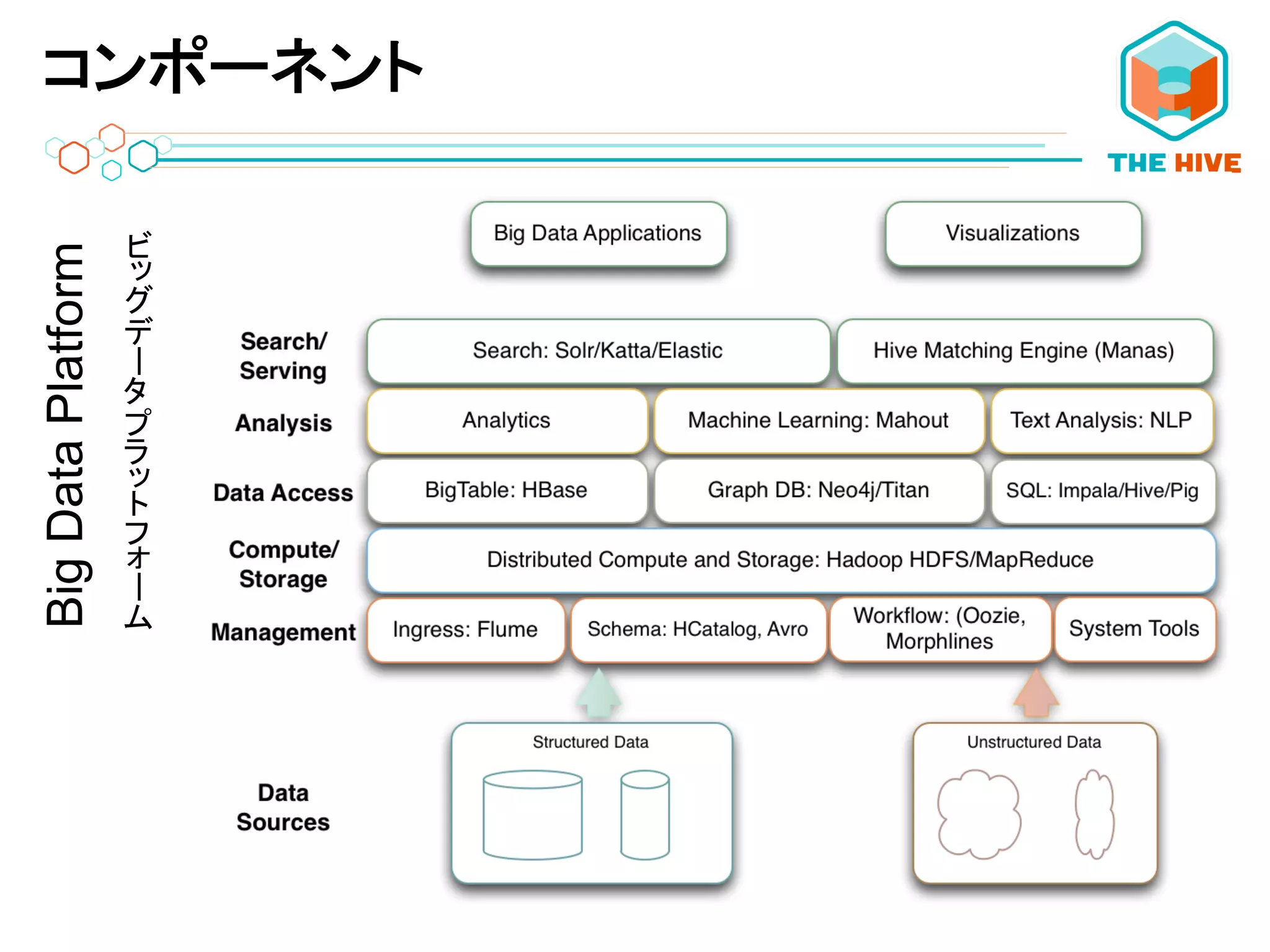
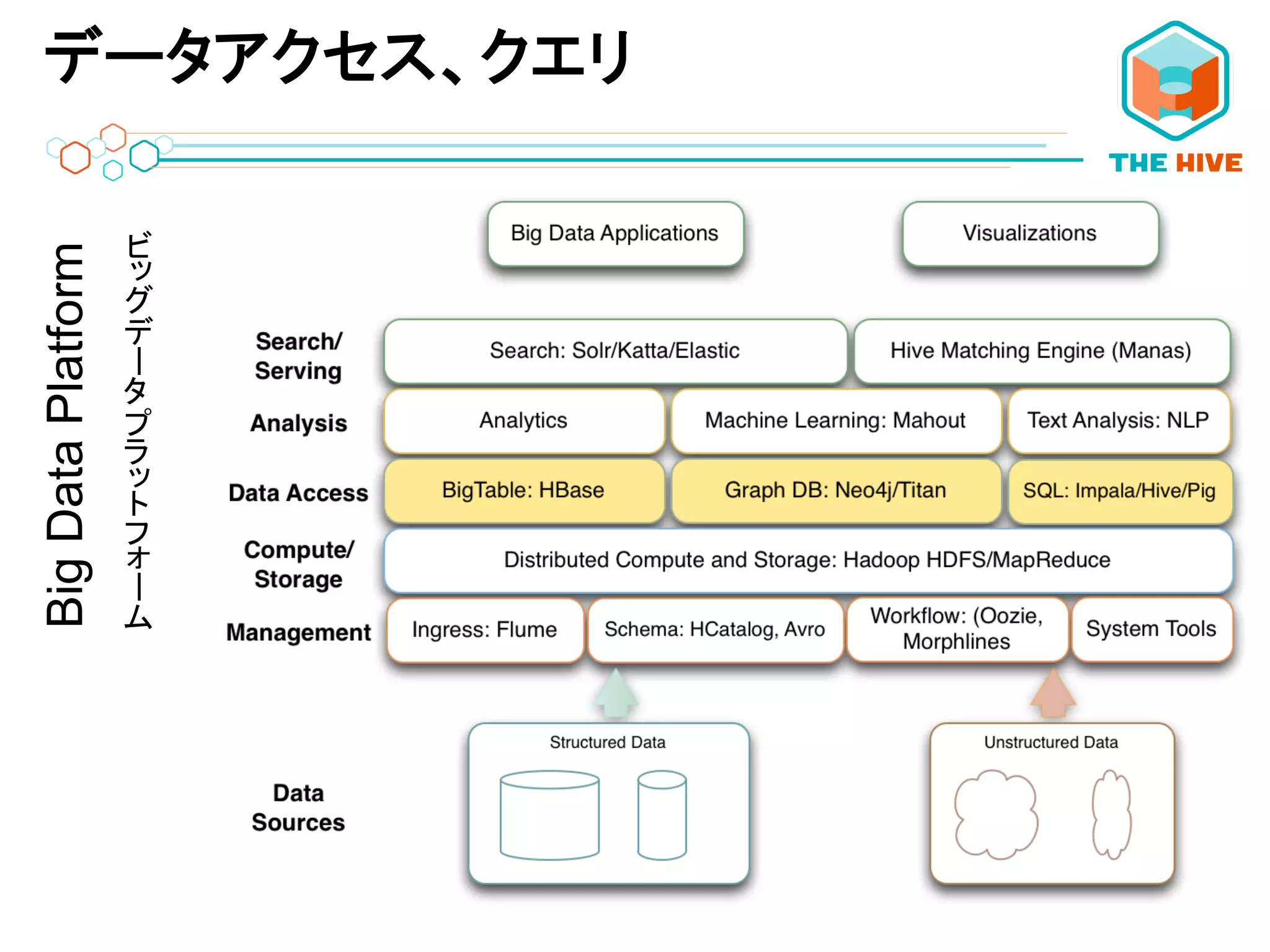
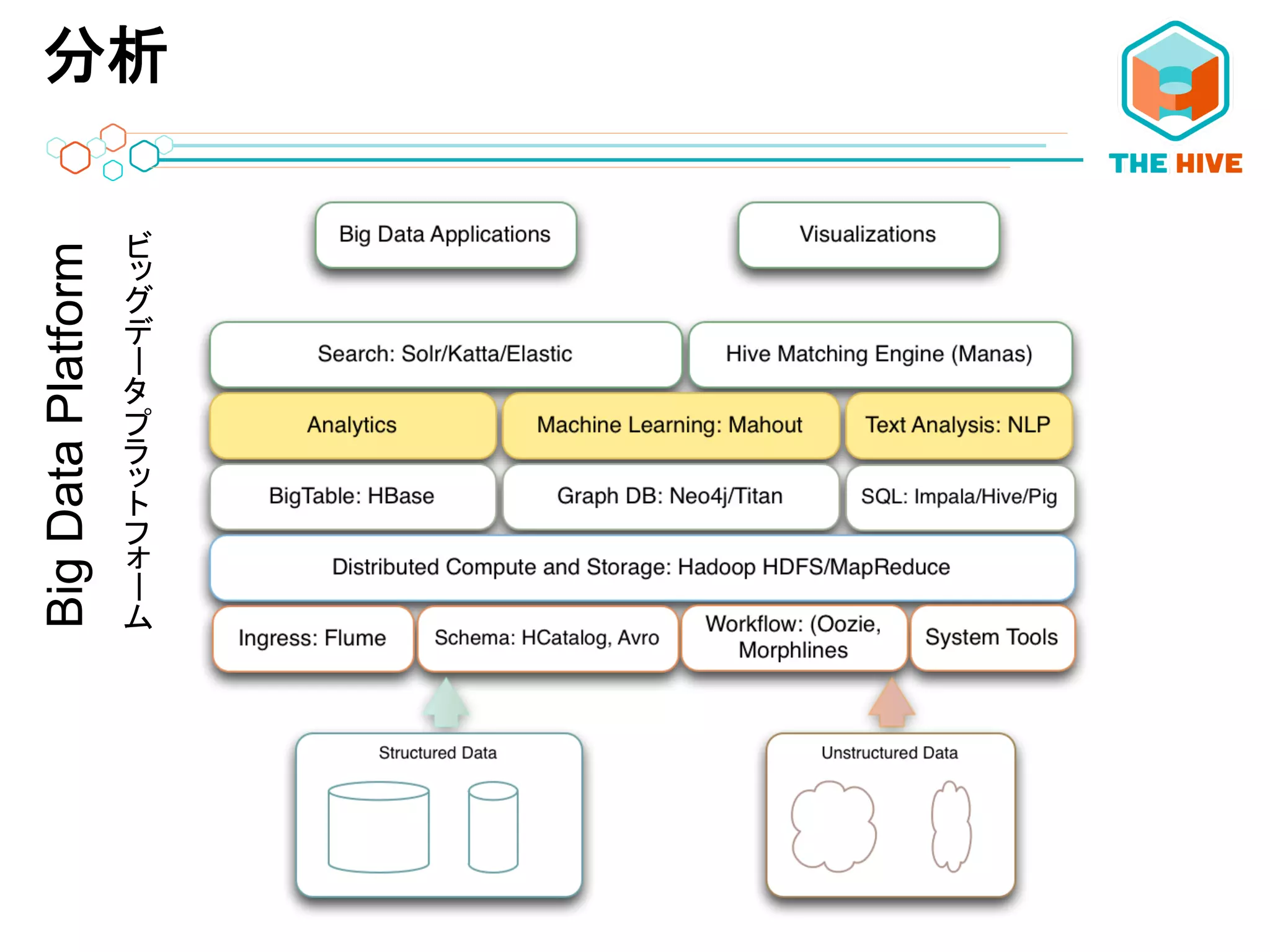
コンポーネントBigDataPlatform ーー
6.
APP SERVER COMPONENTS
アプリケーションサーバー コンポーネント
7.
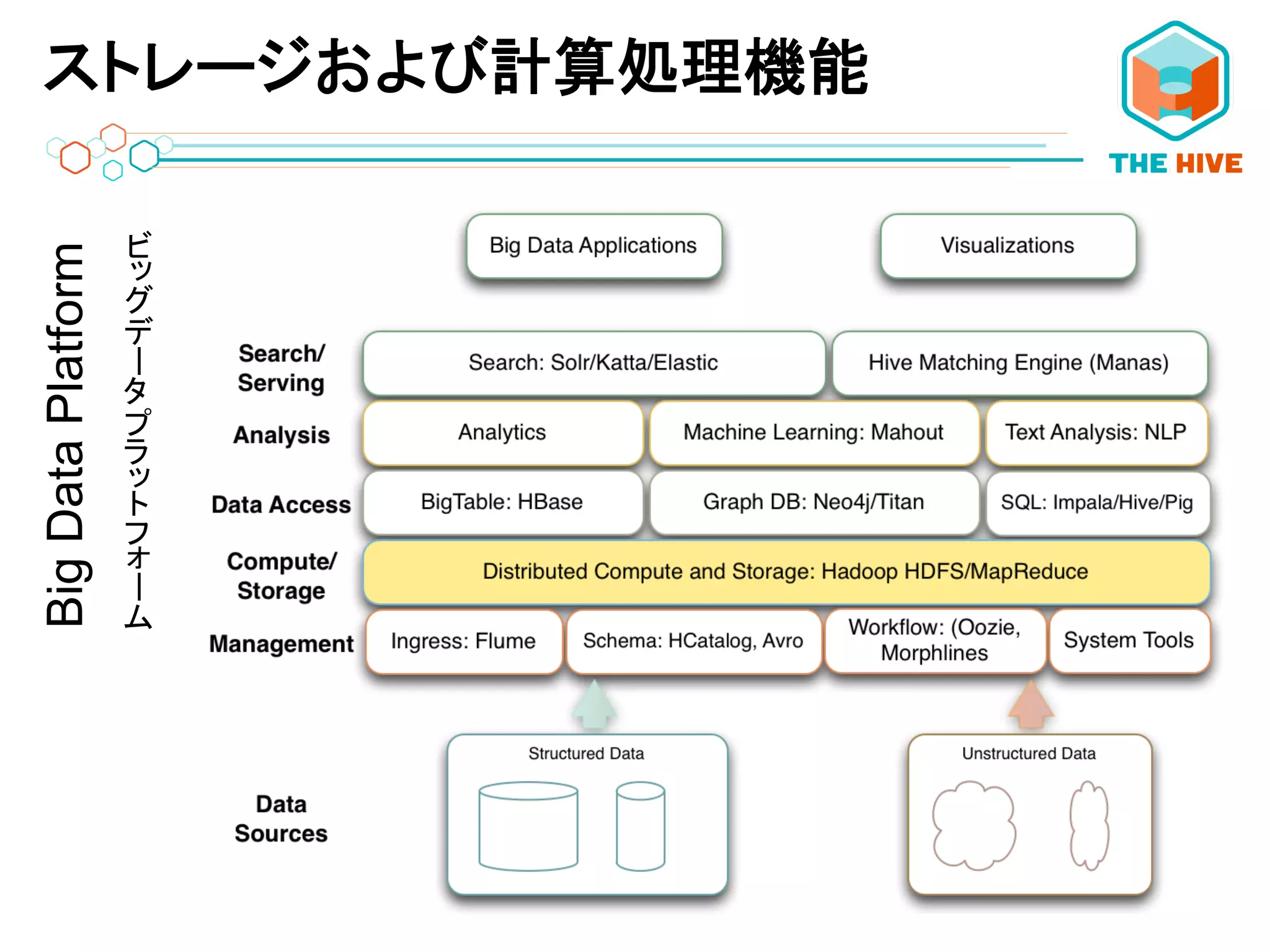
ストレージおよび計算処理機能BigDataPlatform ーー
8.
開発の動機 効率的にWebのデータを取得・処理する必要が あったGoogleの技術が開発のきっかけ
• ページ、単語、ドメインで互いに重要性を計算 • より高い費用効果– より効率的な処理、 インデックス化、重要性の把握を実現 ストレージおよび計算処理機能
9.
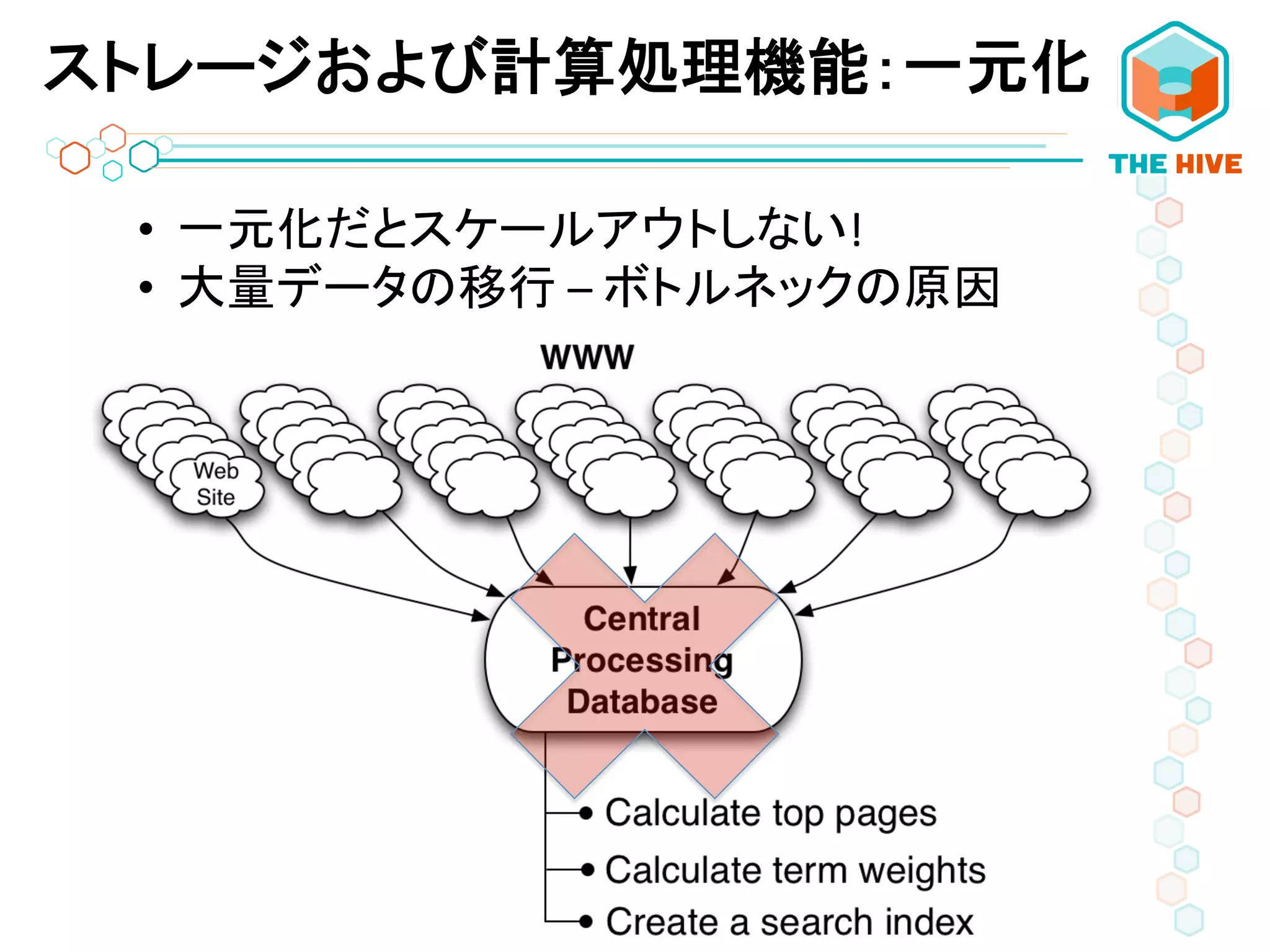
• 一元化だとスケールアウトしない!
• 大量データの移行 – ボトルネックの原因 ストレージおよび計算処理機能:一元化
10.
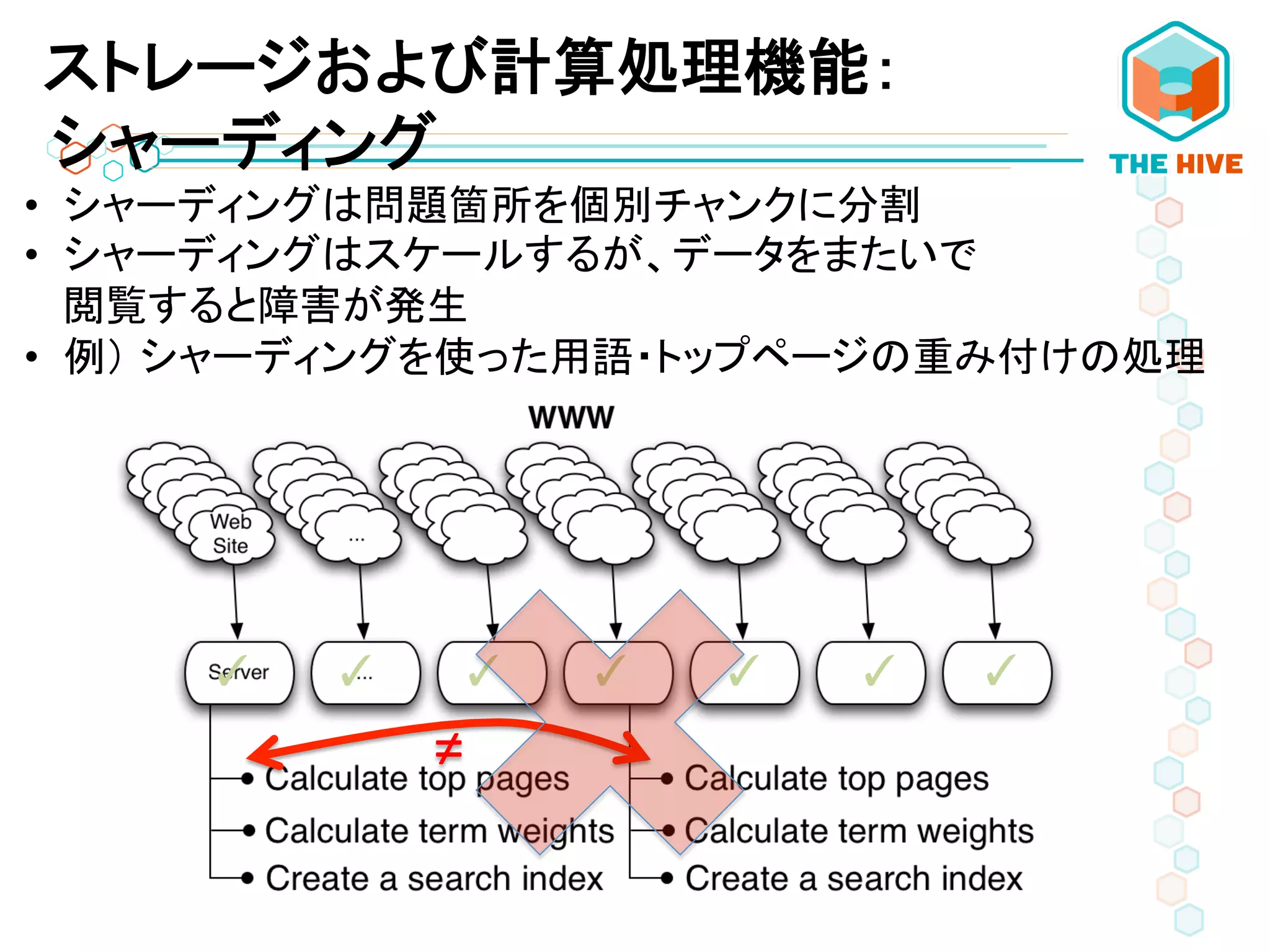
• シャーディングは問題箇所を個別チャンクに分割 •
シャーディングはスケールするが、データをまたいで 閲覧すると障害が発生 • 例) シャーディングを使った用語・トップページの重み付けの処理 ✓ ✓ ✓ ✓ ✓ ✓ ✓ ≠ ストレージおよび計算処理機能: シャーディング
11.
そこで誕生したのがDFS, MapReduce • コンピューティング機能そしてデータ分散 のための新しいプログラミングモデル (シャーディングとは異なる) •
汎用ハードウェア上で稼働 • ソフトウェア制御で障害回復 • 文書データ全体の計算処理が容易 • 2つのパートから成る完全ソリューション: • 分散ファイルシステム – DFS • MapReduce
12.
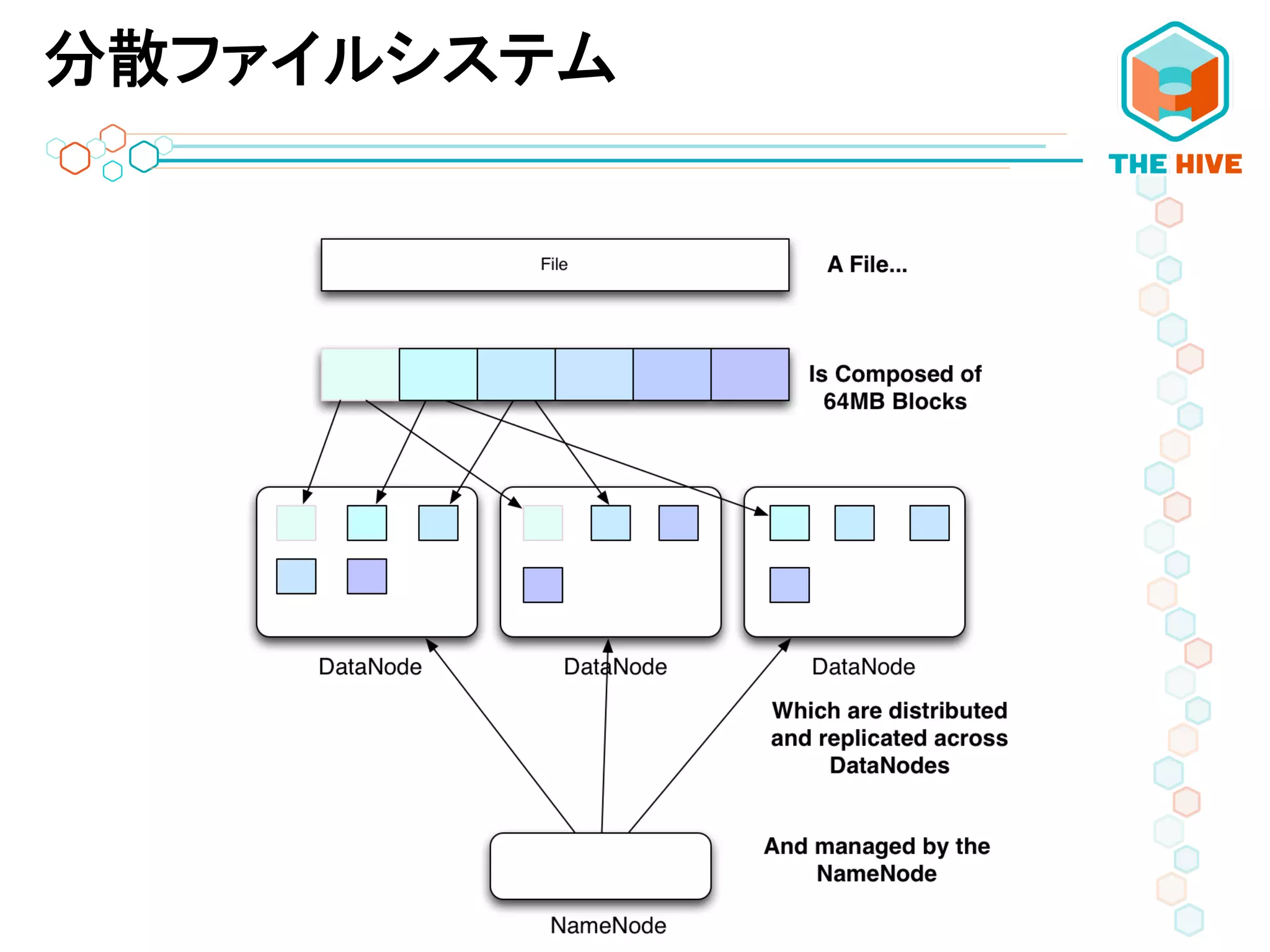
分散ファイルシステム
13.
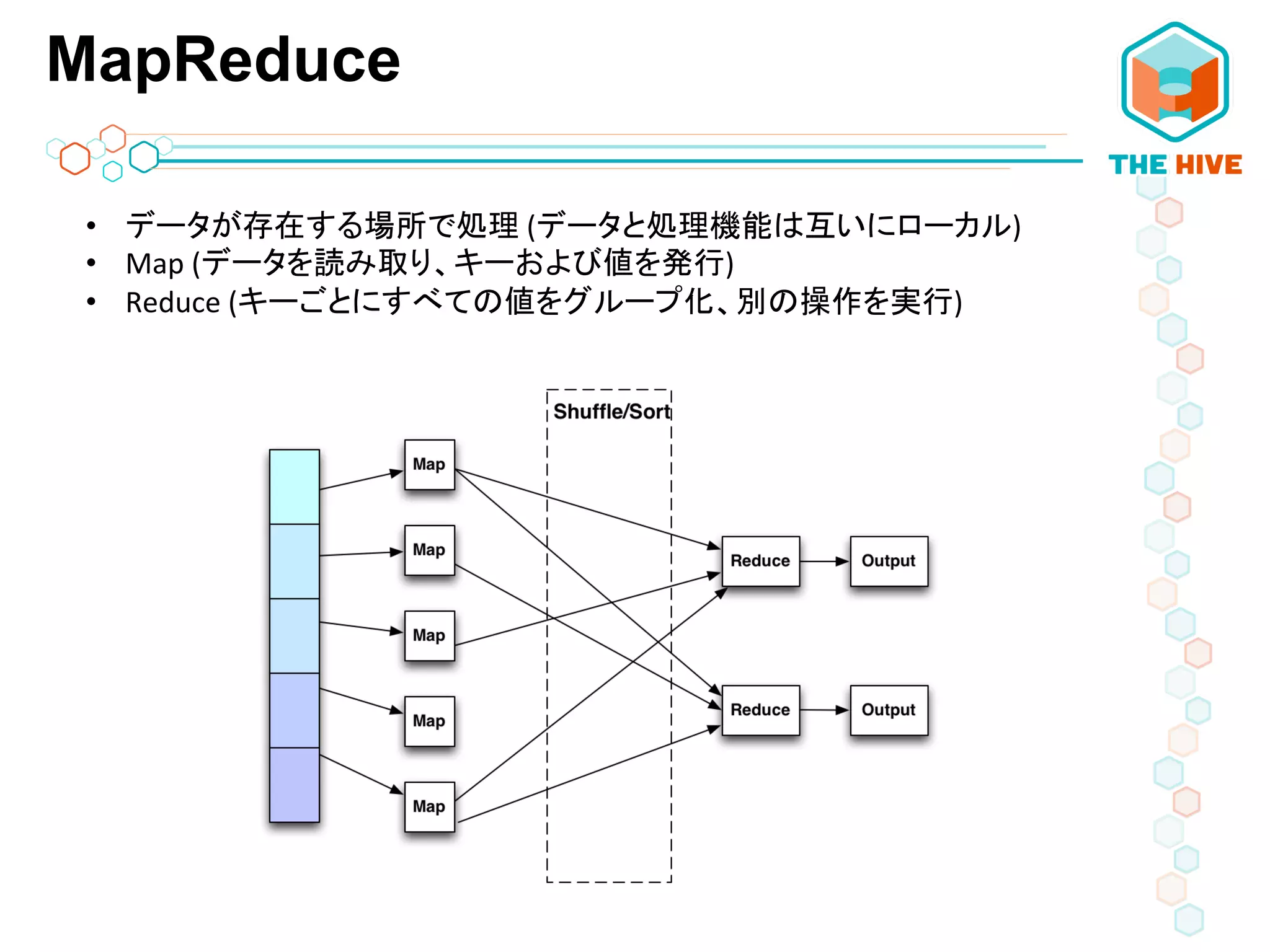
MapReduce • データが存在する場所で処理 (データと処理機能は互いにローカル)
• Map (データを読み取り、キーおよび値を発行) • Reduce (キーごとにすべての値をグループ化、別の操作を実行)
14.
Hadoop • GoogleのDFSおよびMapReduce ホワイトペーパーを基に開発された オープンソース
• 大規模エコシステム • 導入企業: Yahoo, Facebook, TwiPer, LinkedIn, Sears, Apple, The New York Times, Telefonica, 他1000社以上!
15.
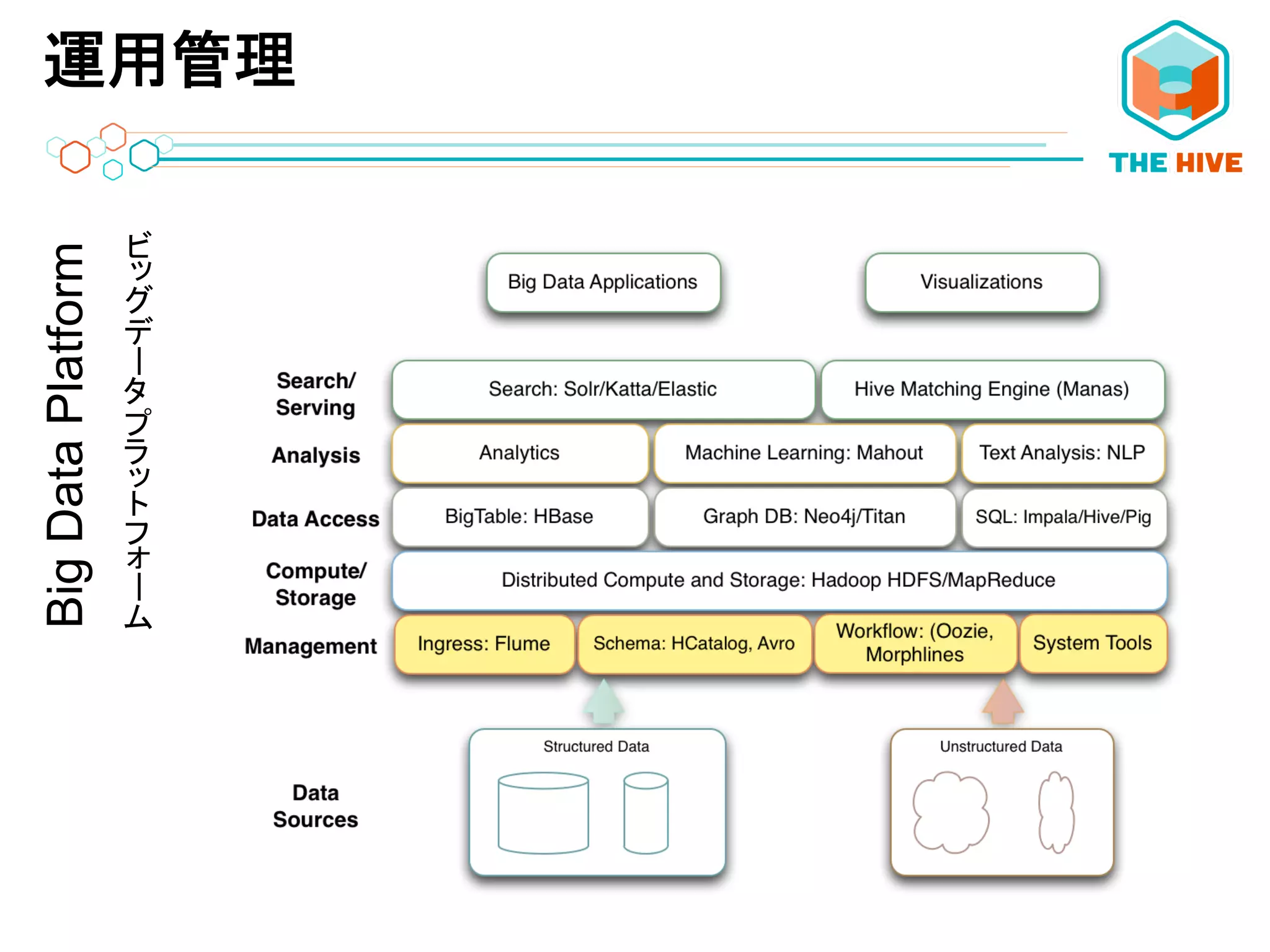
運用管理BigDataPlatform ーー
16.
データ取得 開発のきっかけ • 多様なデータソース
からのデータを取得 する必要がある • 中にはいくつか貴重な データがある: • Time-‐to-‐live (TTL) • デリバリーの保証
17.
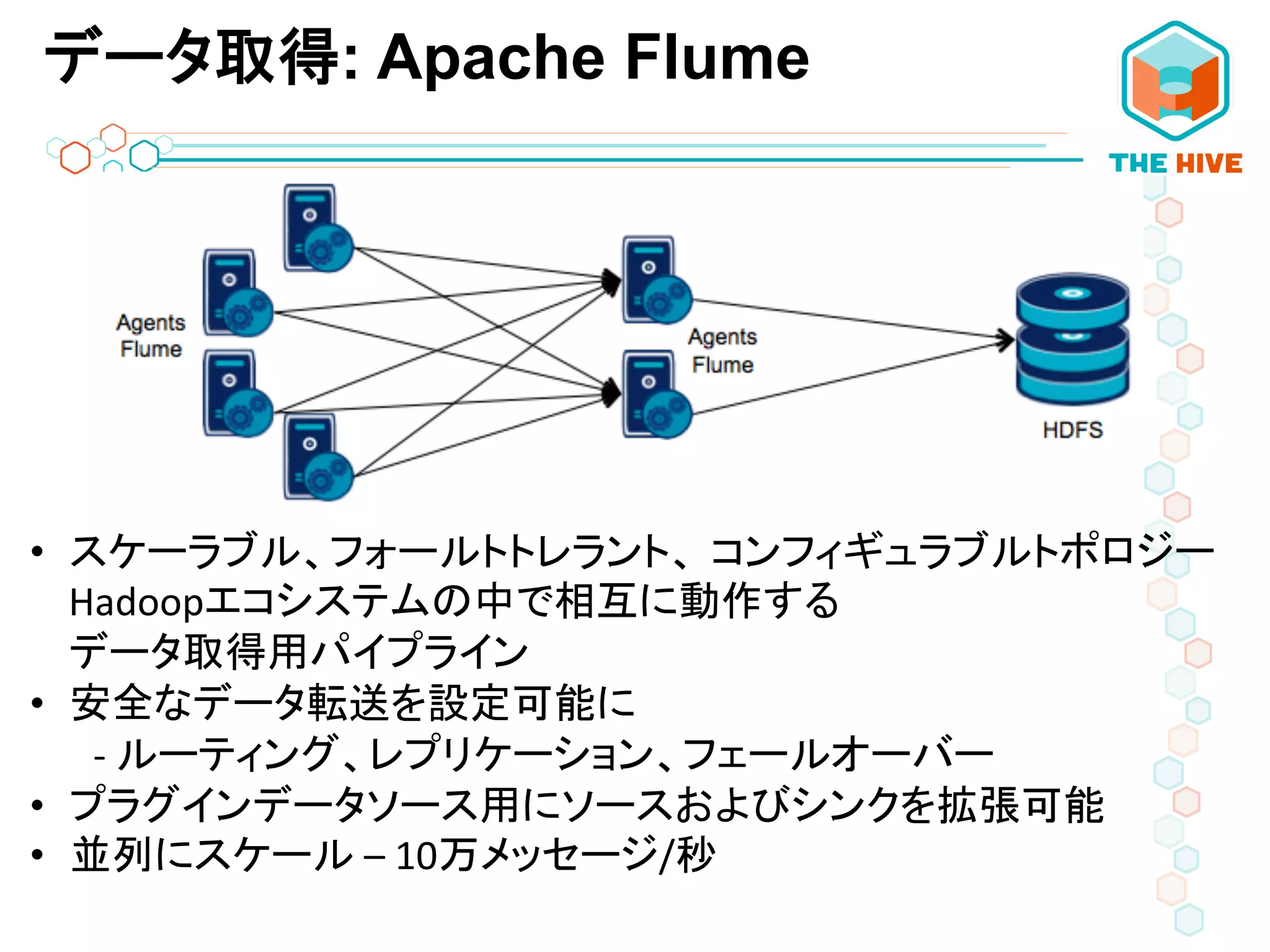
データ取得: Apache Flume •
スケーラブル、フォールトトレラント、 コンフィギュラブルトポロジー Hadoopエコシステムの中で相互に動作する データ取得用パイプライン • 安全なデータ転送を設定可能に -‐ ルーティング、レプリケーション、フェールオーバー • プラグインデータソース用にソースおよびシンクを拡張可能 • 並列にスケール – 10万メッセージ/秒
18.
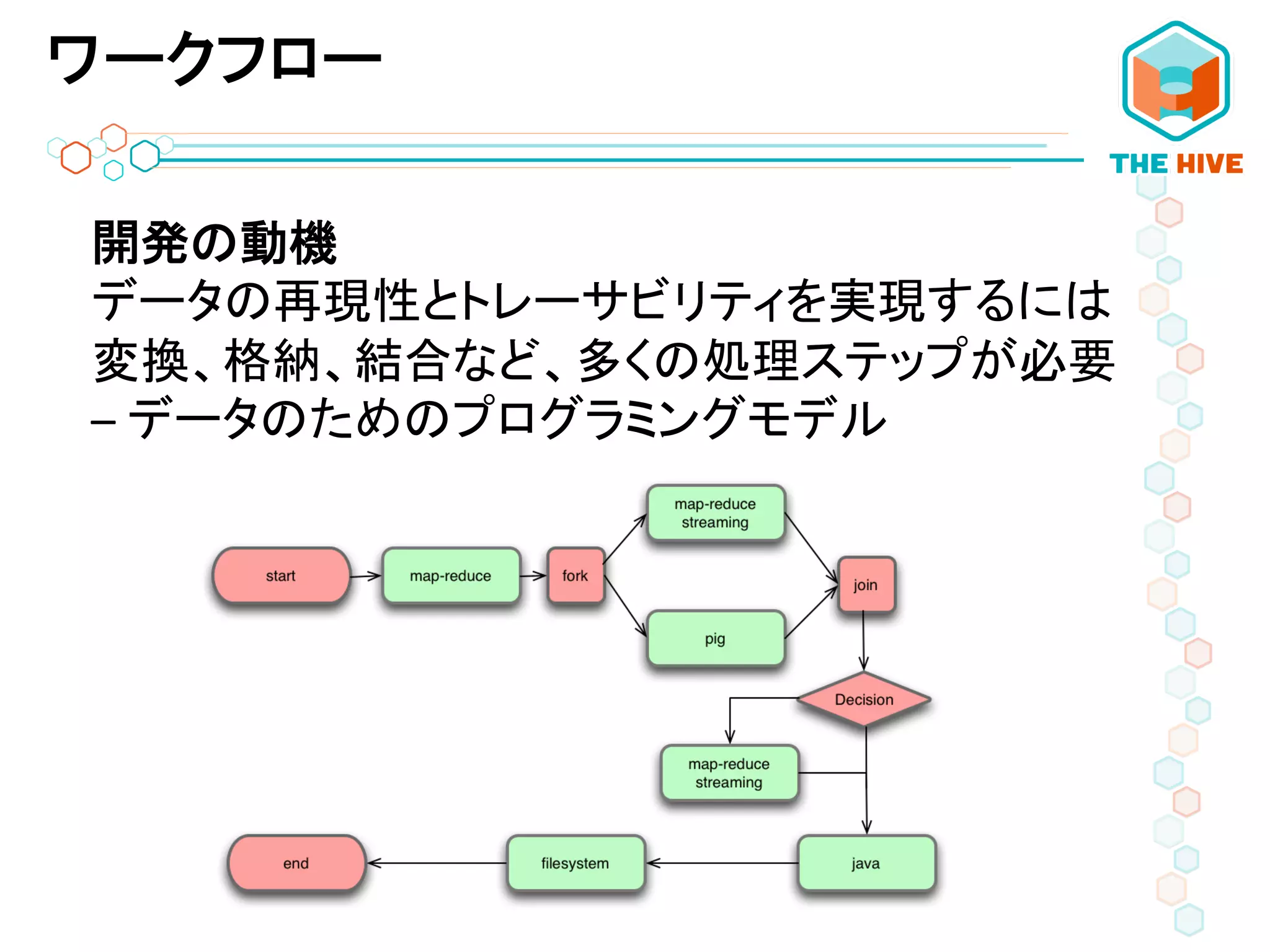
ワークフロー 開発の動機 データの再現性とトレーサビリティを実現するには 変換、格納、結合など、多くの処理ステップが必要 –
データのためのプログラミングモデル
19.
ワークフロー: Oozie 処理プログラムの独立性を把握し、それに基づいて スケジューリングと再実行を行い、各ステップのレ ポートを発行するワークフローエンジン
• 時間またはデータ可用性によってジョブをトリガー • ほかのHadoop資産と統合可能 • スケーラブルで信頼性・拡張性が高いシステム
20.
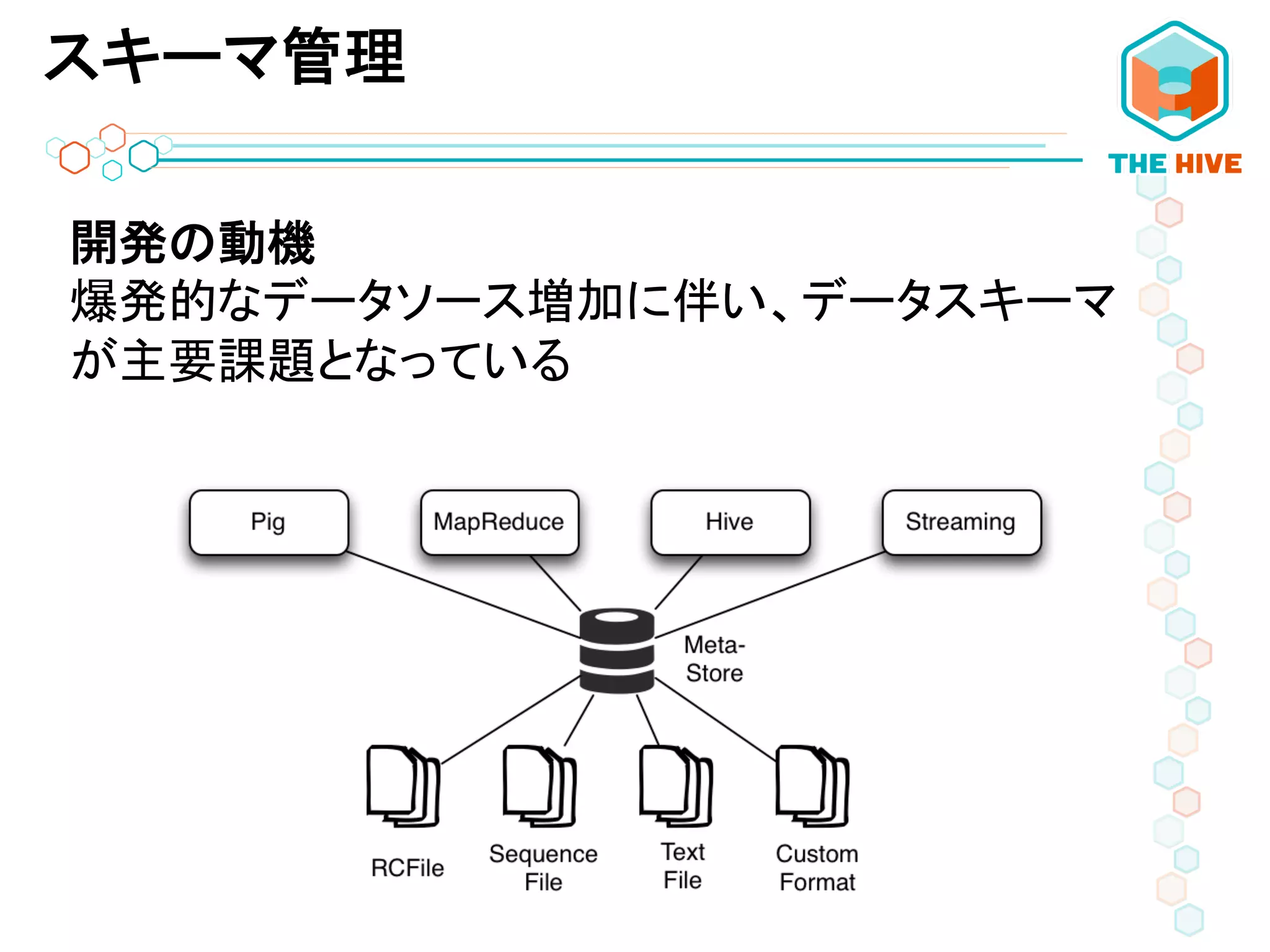
スキーマ管理 開発の動機 爆発的なデータソース増加に伴い、データスキーマ が主要課題となっている
21.
スキーマ: HCatalog • Hadoop用テーブルおよびストレージマネ ジメントレイヤー
• 異なるデータ処理ツールの利用を実現 – Pig、MapReduce、Hive – グリッド上での データ読み込み・書き出しをより容易に
22.
スキーマ: Avro •
データシリアライゼーションシステム • Avroはデータとスキーマを一緒に格納 • 同じ名前のフィールド、ミッシングフィール ド、エキストラフィールド等々の一致は簡 単に解決 • Hadoop資産のほとんどの技術はAvroに 対応 – 相互運用性/データパス
23.
データアクセス、クエリBigDataPlatform ーー
24.
データアクセス 開発の動機 多様なデータアクセスパターンに、単なるDFSファ イルでは対応できないため、それ以上の性能を持 つデータストアが必要。たとえばデータへのランダ ムアクセスを行う場合、キーバリューストアが必要。
ソリューション ユースケースに基づきさまざまなソリューションが ある • GoogleのBigTableホワイトペーパー • HadoopはSQLに対応済み
25.
データアクセス: HBase • Hadoopデータベース
– スケーラブルな分 散型ビッグデータストア(ソートマップ) – GoogleのBigTableがベース、Hadoop DFS がサポート • モジュラーを追加するとリニアにスケール • テーブルのシャーディングの自動設定が 可能 • フェールオーバーの自動化 • Apache HBaseテーブルとMapReduceジョ ブをバックアップする便利なベースクラス
26.
データアクセス: SQL –
Hive, Impala • 分散ファイルシステム上の生データに対す るSQLクエリ • Impala –HDFSのファイルに対し、SELECT(選 択)、JOIN(結合)、機能のアグリゲートと いったクエリを実行 – リアルタイムに • Hive –容易なデータサマライズの実現、アド ホッククエリの実行、Hadoopと互換性ある ファイルシステムに格納された大規模デー タセットを分析
27.
分析BigDataPlatform ーー
28.
データ分析 開発の動機 • データが持つ潜在的な価値の発掘。ビッグ データの裏にある最も重要なニーズ!
• クラスタリング、機械学習、相関性、モデリング – データサイエンスの中心分野 – 一般に、ユー スケースは非常に多様 ソリューション ユースケースに応じた最適なツールに適合できる ように、スキーマを共有できるプラグイン可能な アーキテクチャ
29.
データ分析: フレームワーク例 • Mahout
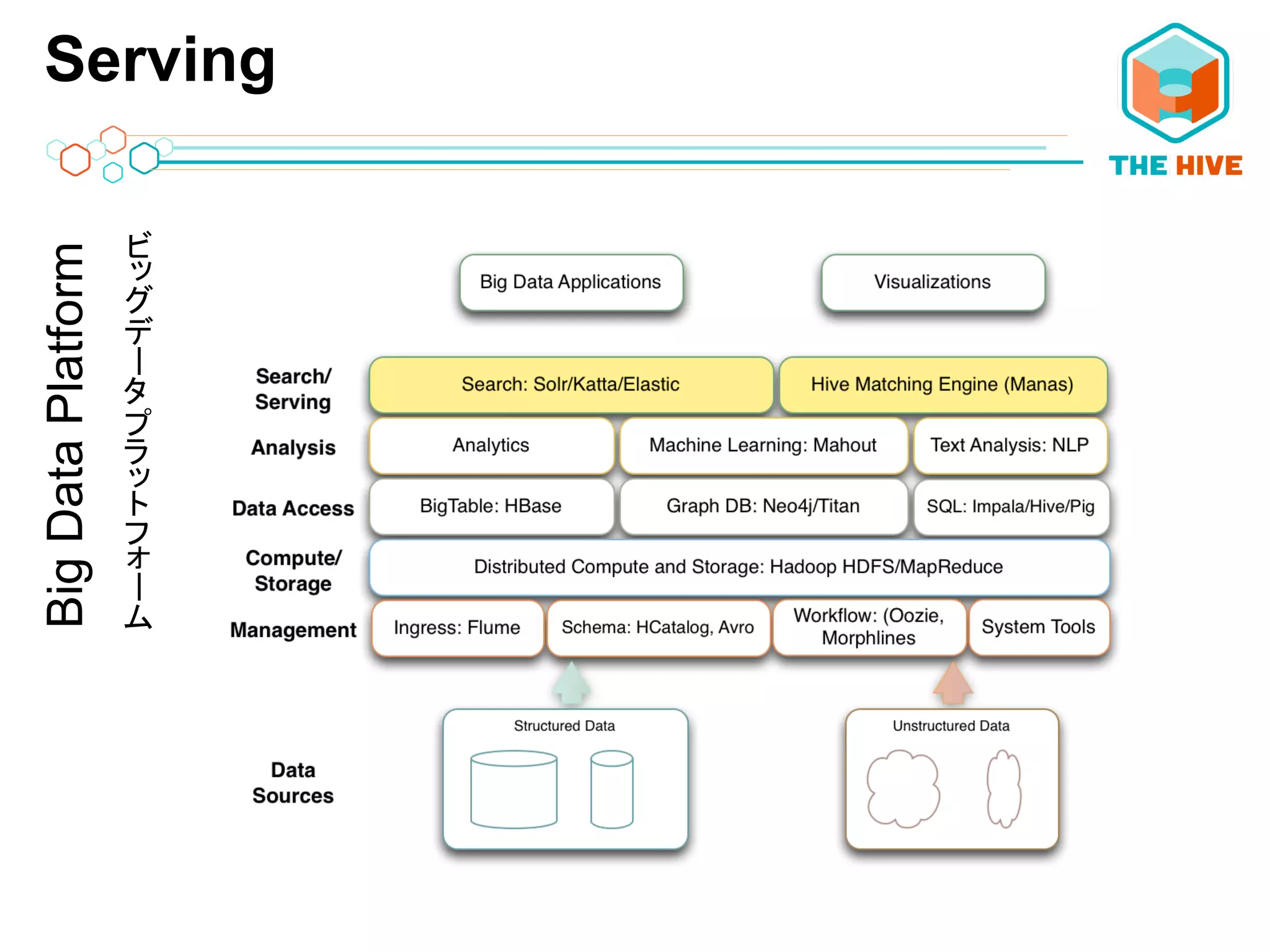
• 機械学習、クラスタリング • PaPern – カスケーディングからHadoop用の機械学習 DSL • 0xData • ビッグデータ用数学および予測エンジンのオープン ソース • サンプルアルゴリズム • Random Forest(ランダムフォレスト)アルゴリズム • K平均法 • 階層クラスタリング • 線形回帰 • ロジスティック回帰 • サポートベクターマシン • 人口ニューラルネットワーク • アソシエーションルール学習
30.
ServingBigDataPlatform ーー
31.
サービス 開発の動機 • エンドユーザー用の強力なアプリケーション
• リアルタイムなデータアクセスを実現する 検索/ブラウジングおよびレコメンデーションエンジン
32.
サービス: 検索 –
Solr Cloud • Hadoop最上部にインデックスを構築 • 並列にスケーラブル、フォールトトレラント機能 • インデックスオプションにおける圧倒的な柔軟性 • トークン化 • フィールドタイプ • データストレージ • 同様の柔軟性を持つ検索オプション • AND,OR,NOT, ワイルドカード • ファセット検索(オントロジー(概念体系)の利用) • 拡張アルゴリズムと重み付けプラグ機能
33.
サービス: Manas –
機械学習 • The Hiveの超スケーラブルなマッチング エンジン • 100〜1000の機能を照合しながら10 億〜数十億ものドキュメントを効率的に ハンドリング • 現在、こうした機能を担当しているオー プンソースコミュニティ上には存在しな いエンジン
34.
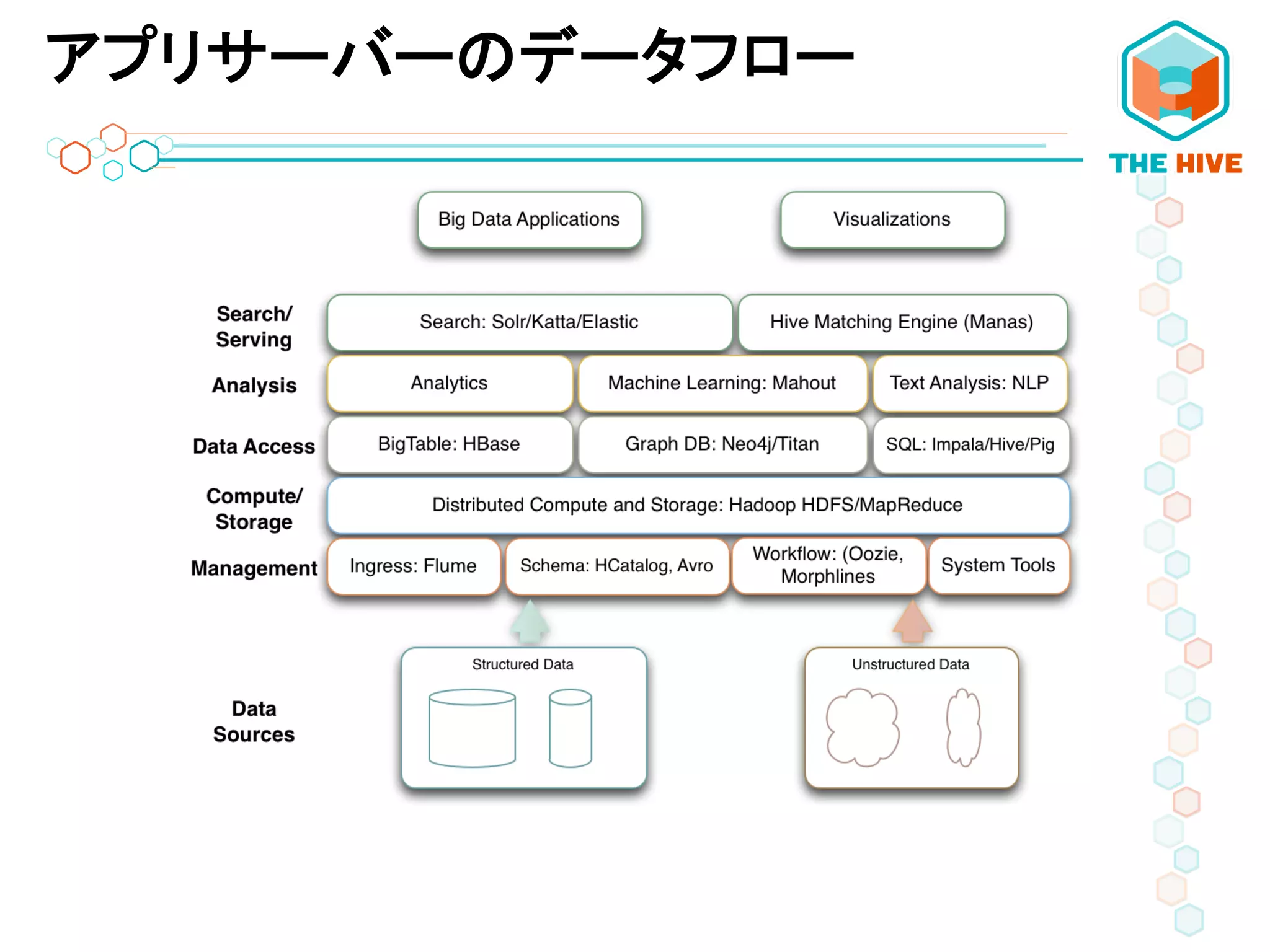
EXAMPLE APP USE-‐CASE
アプリケーションサーバーのユースケース例
35.
アプリサーバーのデータフロー
36.
アプリサーバー上におけるSecurityX
Download





























![[DI07] あらゆるデータに価値がある! アンチ断捨離ストのための Azure Data Lake](https://cdn.slidesharecdn.com/ss_thumbnails/di07-170605024557-thumbnail.jpg?width=640&height=640&fit=bounds)


















































![[INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop](https://cdn.slidesharecdn.com/ss_thumbnails/insightout2011b21part2nosqlhadoop-111114020909-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

























