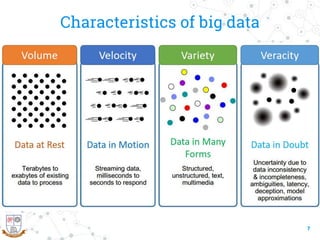
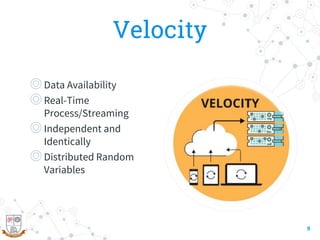
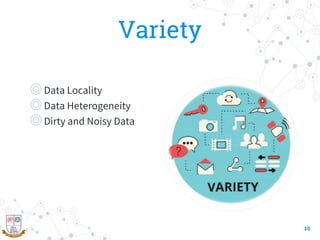
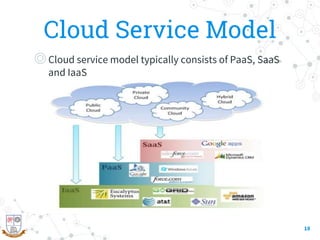
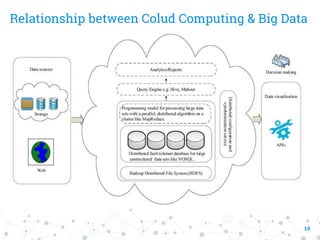
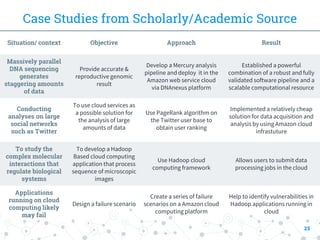
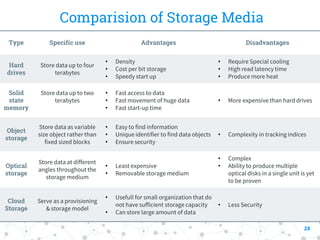
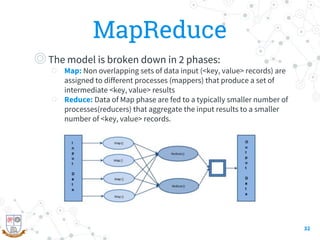
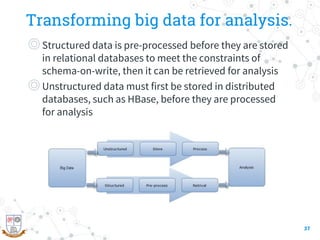
This document provides a comprehensive overview of the intersection between big data and cloud computing, defining big data by its volume, velocity, variety, and veracity. It details characteristics, storage systems, and processing frameworks like Hadoop, along with real-world case studies from various organizations. The document also highlights research challenges and open issues in managing big data within cloud environments, suggesting areas for future exploration.