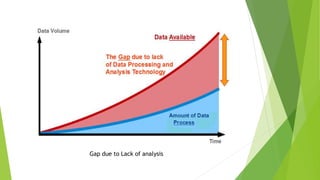
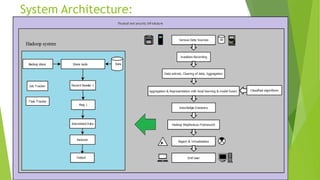
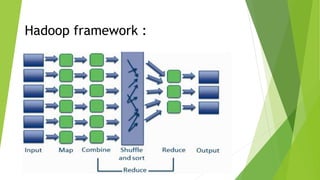
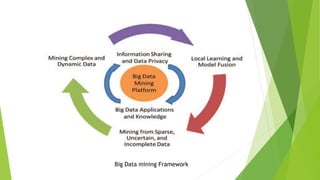
This document discusses big data and data mining. It defines big data as large volumes of structured and unstructured data that are difficult to process using traditional techniques due to their size. It outlines the 4 Vs of big data: volume, velocity, variety, and veracity. The proposed system would use distributed parallel computing with Hadoop to identify relationships in huge amounts of data from different sources and dimensions. It discusses challenges of big data like data location, volume, privacy, and gaining insights. Solutions involve parallel programming, distributed storage, and access restrictions.












































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)






![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)










