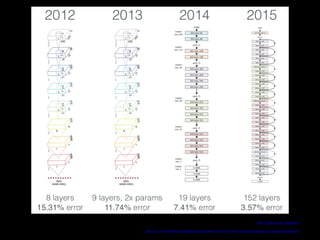
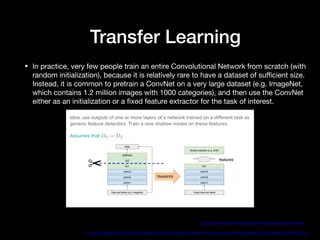
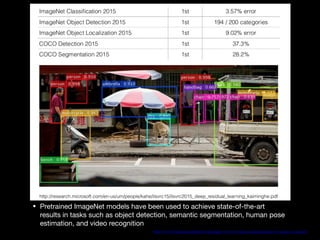
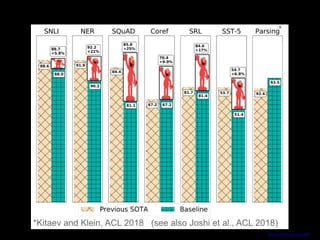
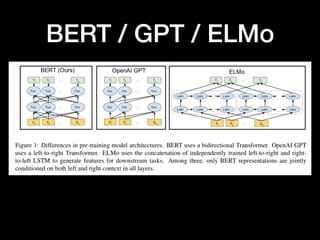
This document discusses NLP's "Imagenet Moment" with the emergence of transfer learning approaches like BERT, ELMo, and GPT. It explains that these models were pretrained on large datasets and can now be downloaded and fine-tuned for specific tasks, similar to how pretrained ImageNet models revolutionized computer vision. The document also provides an overview of BERT, including its bidirectional Transformer architecture, pretraining tasks, and performance on tasks like GLUE and SQuAD.























![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)


























































