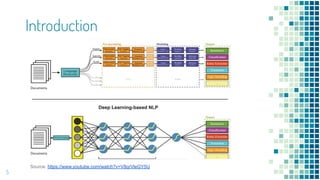


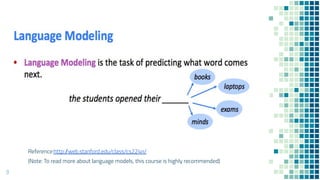

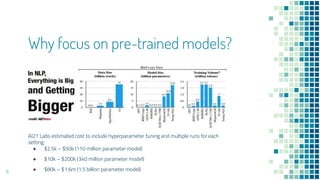

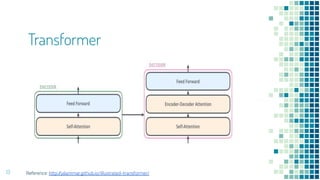


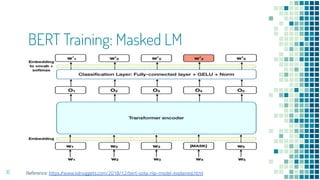



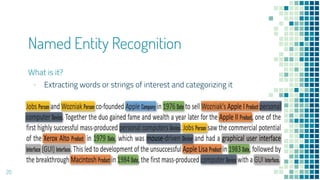
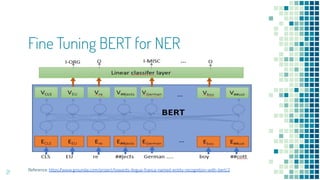

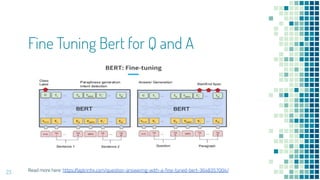

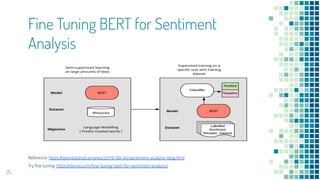

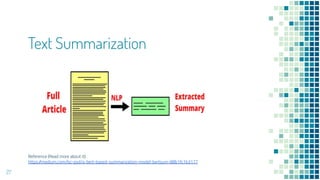
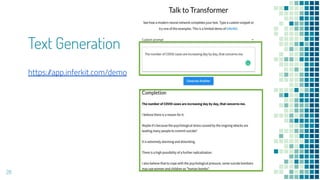
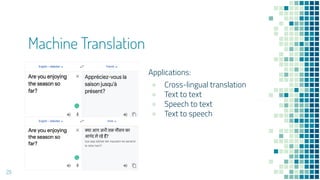

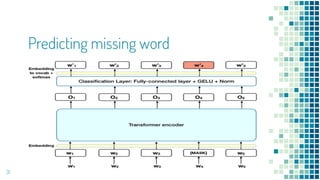
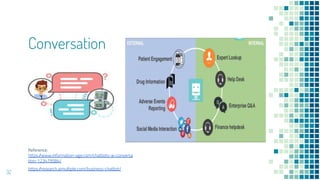

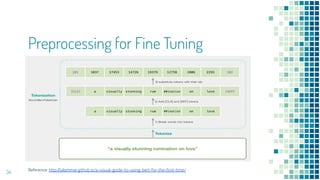


This document provides an overview of leveraging pre-trained language models for natural language understanding. It introduces BERT and how it is trained using masked language modeling and next sentence prediction. It then discusses how BERT and other pre-trained models can be fine-tuned for downstream tasks like named entity recognition, question answering, sentiment analysis, text summarization, text generation, machine translation, predicting missing words, and conversation modeling. The document concludes with an overview of preprocessing text for fine-tuning these models.