Download as PDF, PPTX










![Use Spark in Local Mode
In your build.sbt:
• src/test/scala => “provided”
• src/main/scala => “compiled”
The Scala Build Tool is your friend!
Simply:
• Import Spark libraries
• Invoke a Context and/or Session
• Set master to local[*] or local[n]](https://image.slidesharecdn.com/012007landonrobinsonjackchapa-190510181048/75/Headaches-and-Breakthroughs-in-Building-Continuous-Applications-13-2048.jpg)




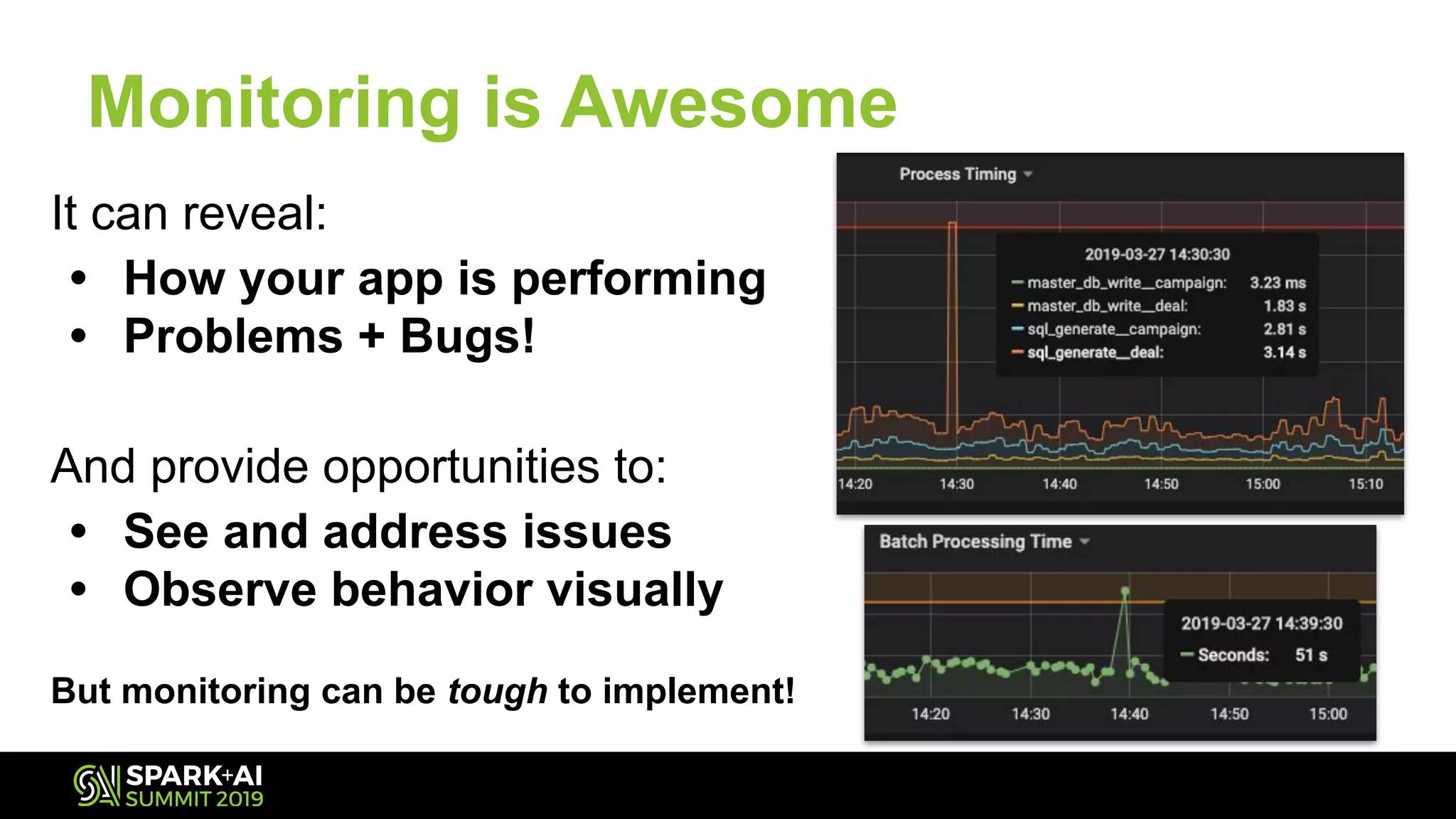











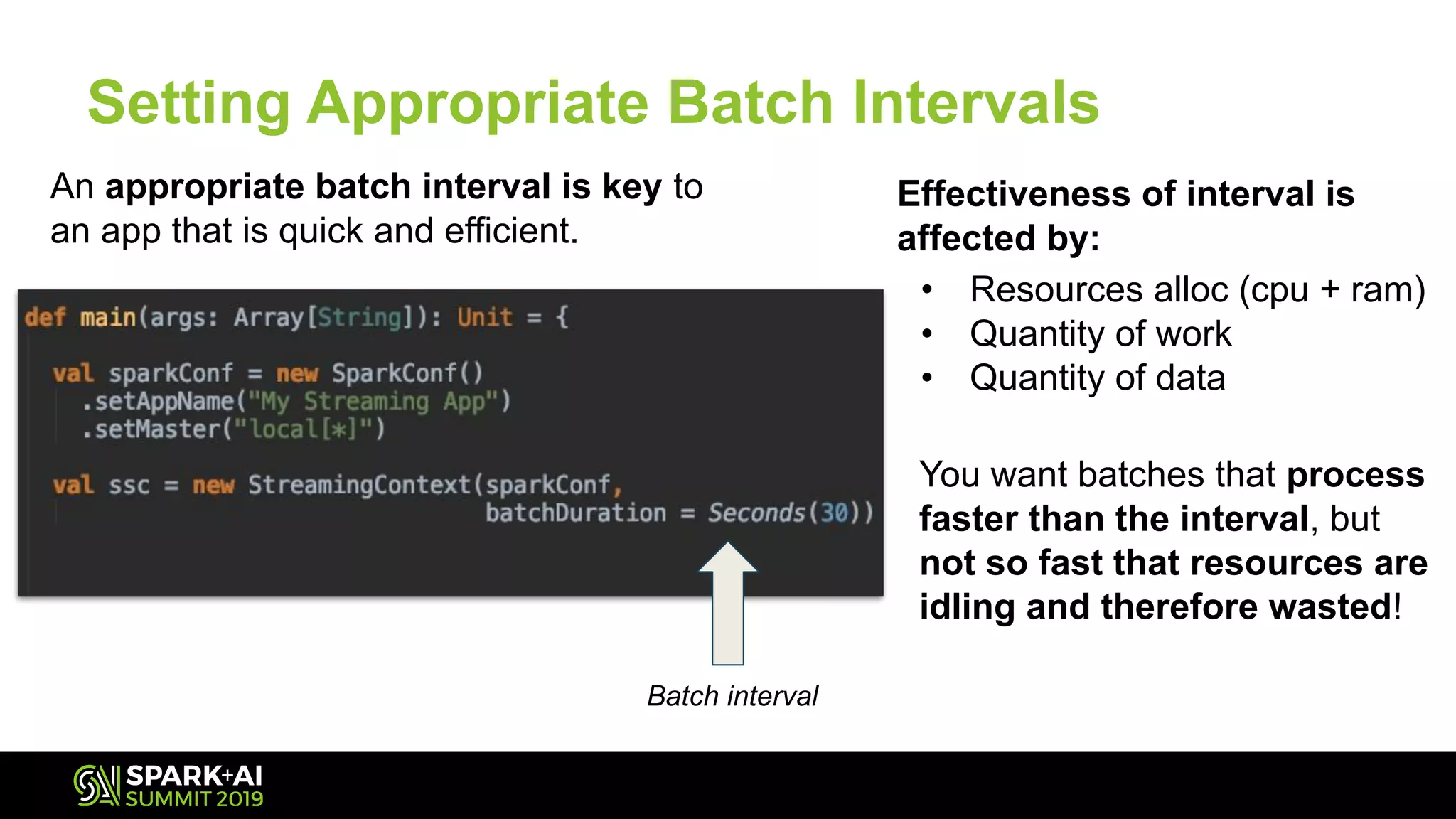
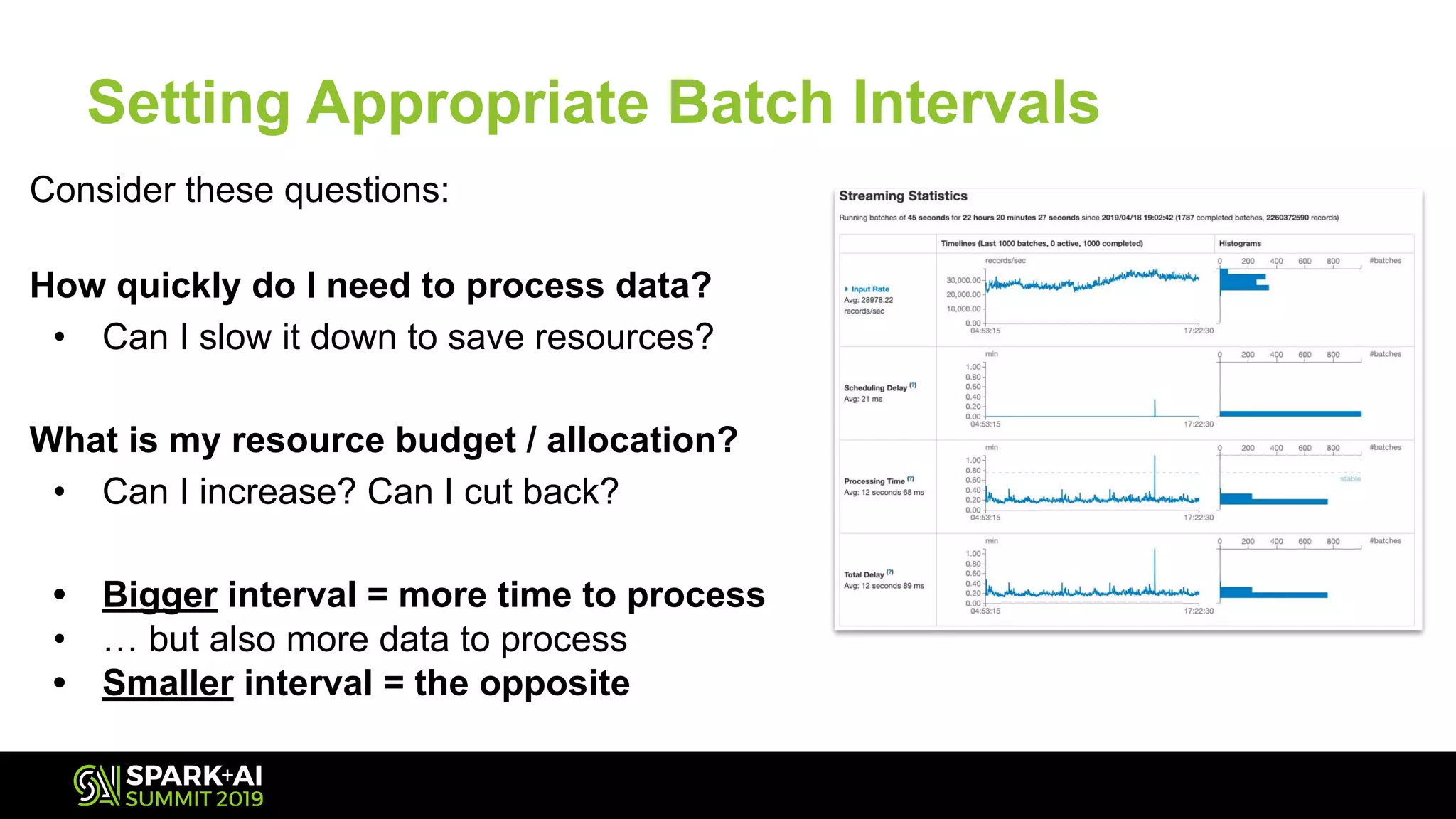













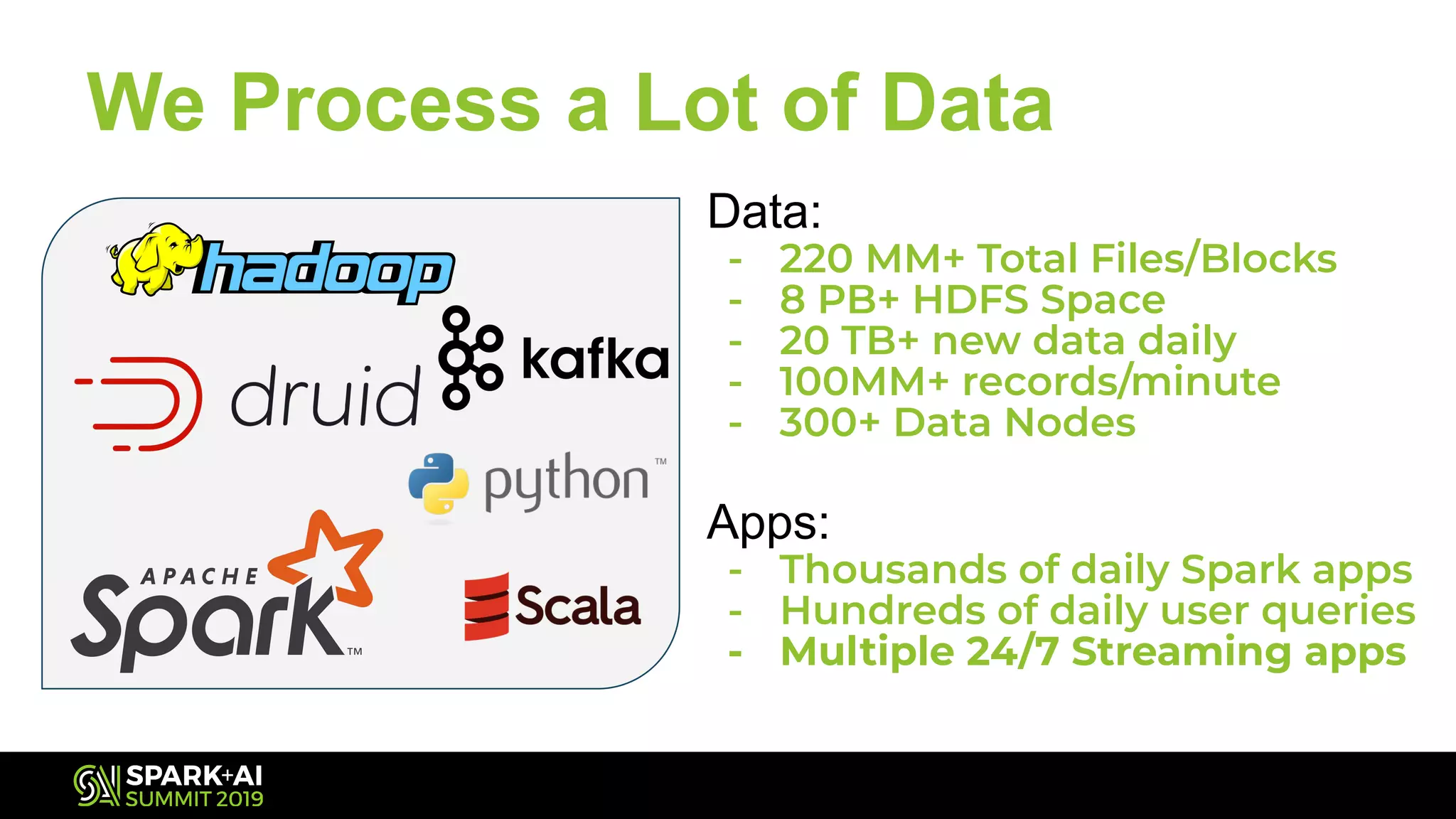
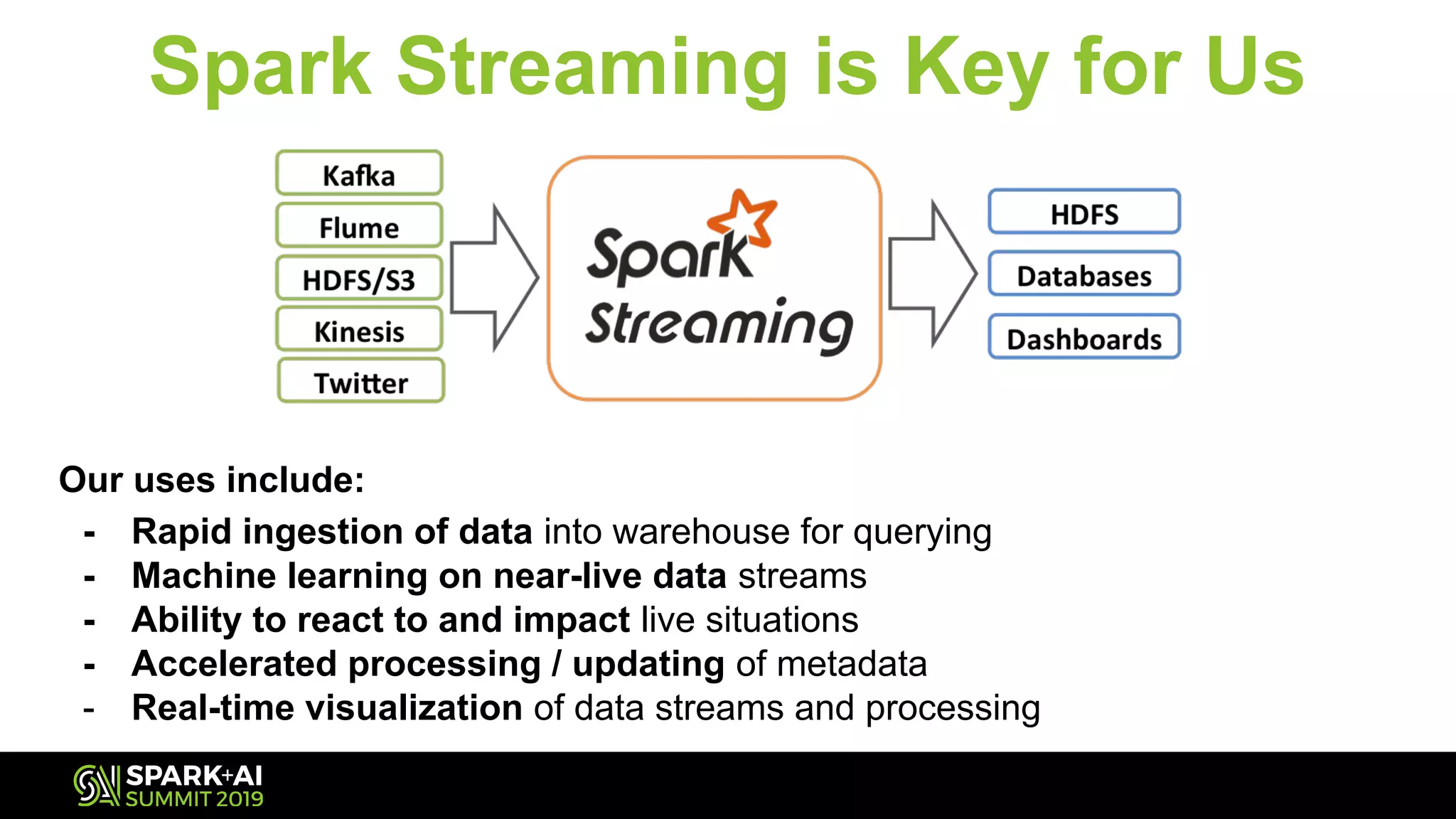
The document discusses Spark Streaming and its complexities, highlighting its powerful capabilities for processing live data streams efficiently. It covers essential topics such as testing, monitoring, batch intervals, and resource management, providing practical takeaways for optimizing Spark Streaming applications. Additionally, it emphasizes the importance of configuration settings and techniques for managing offsets and transformations in streaming applications.























































































