Download to read offline













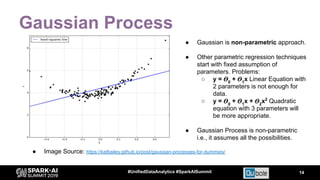

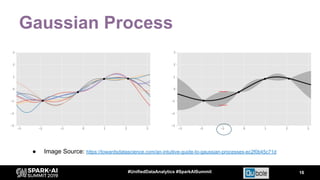










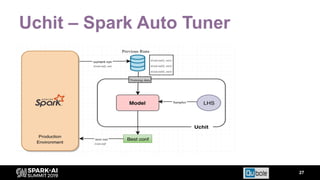

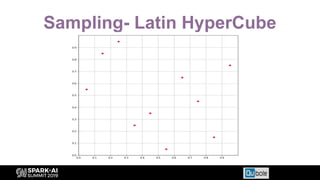
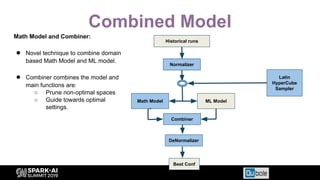


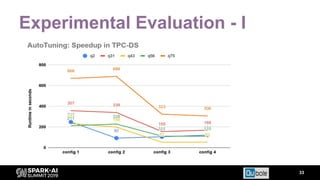



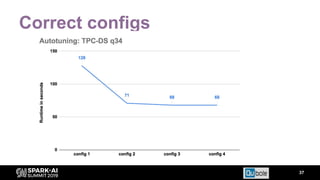

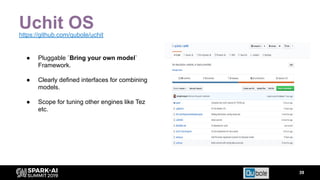



The document discusses an automated tuning system for Apache Spark applications using machine learning and domain-based models, aiming to optimize performance and resource efficiency. It covers motivation, the approach including Gaussian processes for iterative configuration prediction, and insights from previous research on performance tuning. A demo of the auto-tuning system, 'Uchit', is presented, illustrating significant reductions in configuration space and runtime evaluation time.







































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)














