Downloaded 10 times



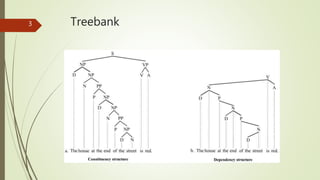




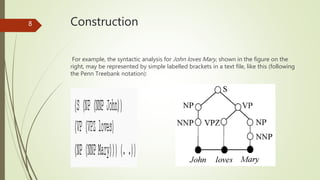








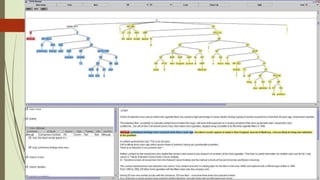
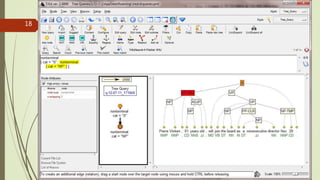

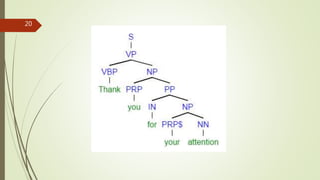

A treebank is a parsed text corpus that annotates the syntactic or semantic structure of sentences, often created from an annotated corpus with part-of-speech tags. Treebank construction can be labor-intensive and varies in detail and linguistic breadth, while different treebanks can follow specific linguistic theories or be more general. They are widely used in computational linguistics to improve natural language processing systems and in theoretical linguistics to study syntactic phenomena.



































































