


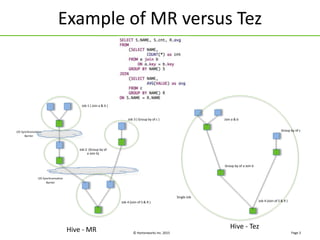
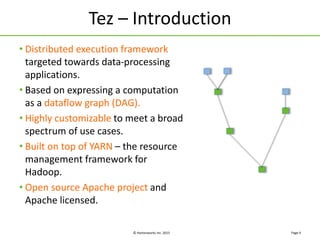
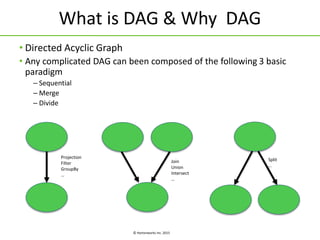

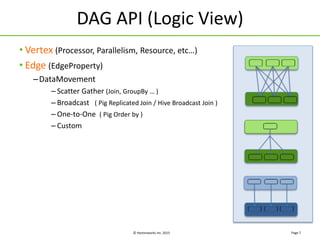
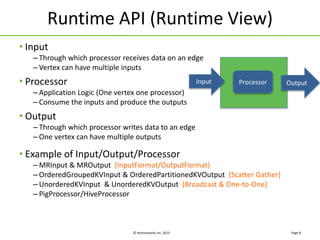




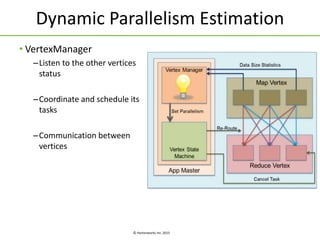

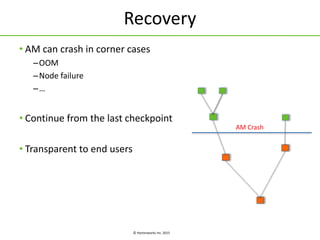
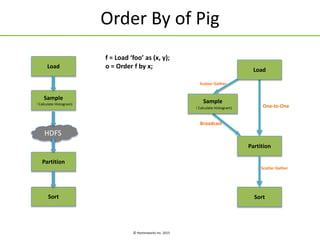



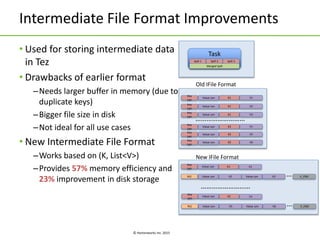



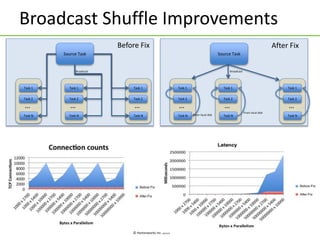
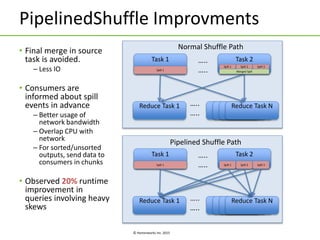
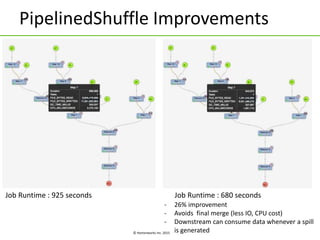

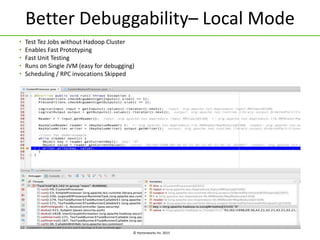

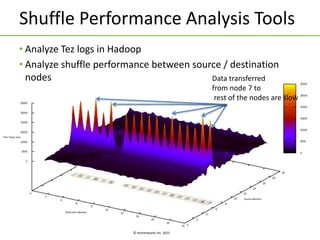
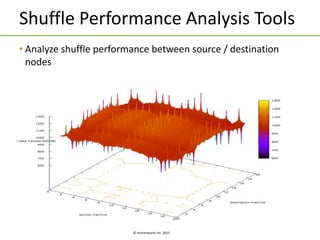





Apache Tez is a framework for building data processing applications on top of YARN. It allows expressing a computation as a directed acyclic graph (DAG) to optimize execution. Tez improves on MapReduce by avoiding intermediate data writes to HDFS and enabling optimizations across jobs. The presentation covered Tez features like container reuse, dynamic parallelism, and integration with YARN timeline service. It also discussed ongoing work to improve performance through speculation, intermediate file formats, and shuffle optimizations.




























































![[2C1] 아파치 피그를 위한 테즈 연산 엔진 개발하기 최종](https://cdn.slidesharecdn.com/ss_thumbnails/2b1-140929191628-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




















