Downloaded 27 times






![8 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
00
00
00
01
01
s01 s02
s03 s04
hash("/work/pending/part-01")
["s02", "s03", "s04"]
01
01
01
01
hash("/work/pending/part-00")
["s01", "s02", "s04"]
hash(name)->blob](https://image.slidesharecdn.com/2016-12-07-161213180658/85/S3Guard-What-s-in-your-consistency-model-8-320.jpg)

![10 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
00
00
00
01
01
s01 s02
s03 s04
hash("/work/pending/part-01")
["s02", "s03", "s04"]
copy("/work/pending/part-01",
"/work/complete/part01")
01
01
01
01
delete("/work/pending/part-01")
hash("/work/pending/part-00")
["s01", "s02", "s04"]
rename(): A Series of Operations on The Client](https://image.slidesharecdn.com/2016-12-07-161213180658/85/S3Guard-What-s-in-your-consistency-model-10-320.jpg)

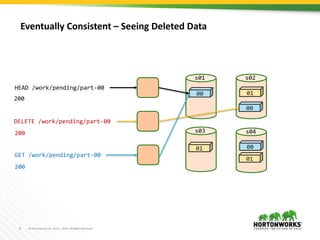


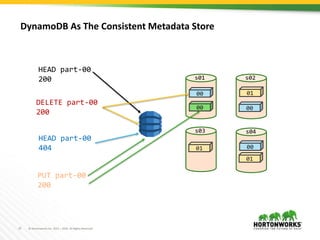



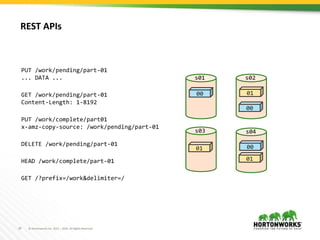

S3Guard provides a consistent metadata store for S3 using DynamoDB. It allows file system operations on S3, like listing and getting file status, to be consistent by checking results from S3 against metadata stored in DynamoDB. Mutating operations write to both S3 and DynamoDB, while read operations first check S3 results against DynamoDB to handle eventual consistency in S3. The goal is to improve performance of real workloads by providing consistent metadata operations on S3 objects written with S3Guard enabled.























































































