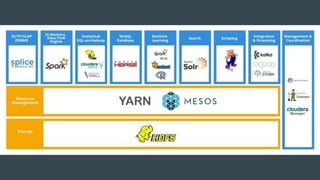
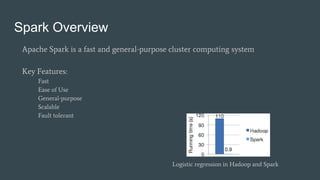
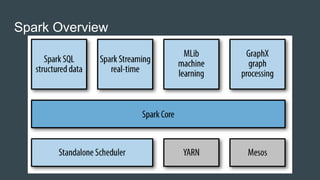
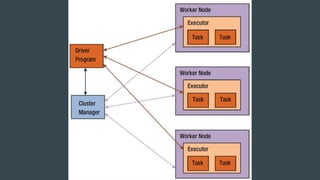
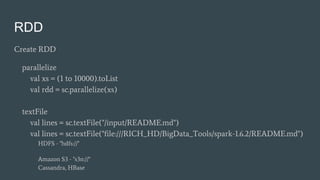
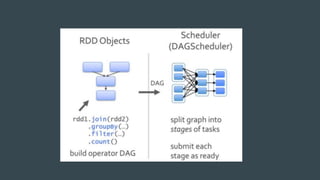
This document summarizes a Spark conference in Taiwan in 2016. It provides an overview of Spark including its key features like being fast, easy to use, general purpose, scalable and fault tolerant. It then discusses Spark core concepts like RDDs, transformations, actions, caching and provides examples. It also covers developing Spark applications using Spark shell, Zeppelin and Spark submit.