Download as PDF, PPTX



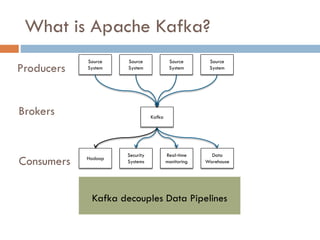

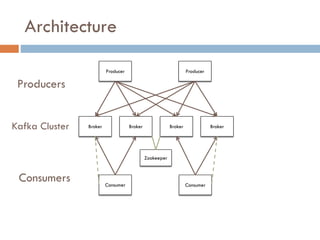
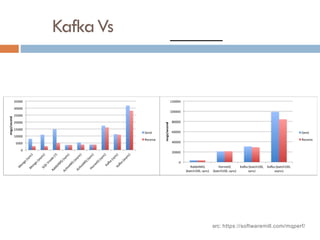

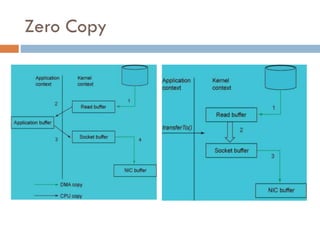


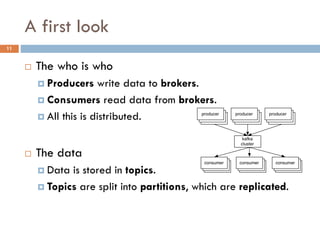
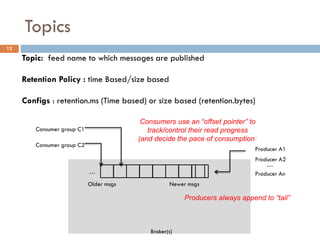

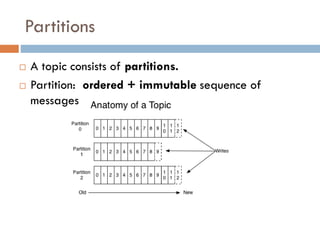
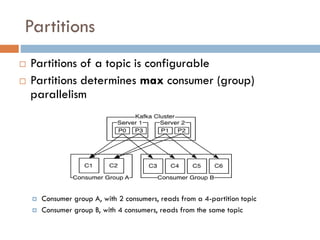


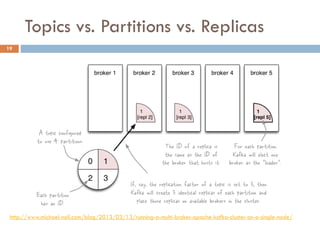
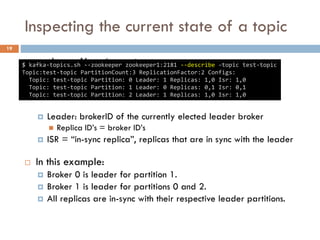




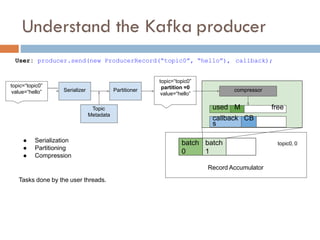
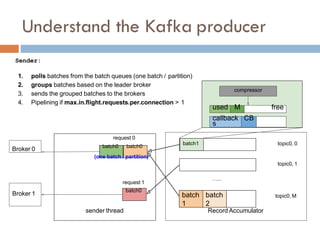

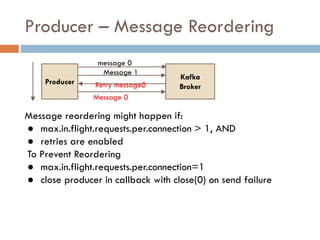


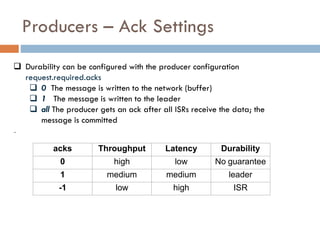
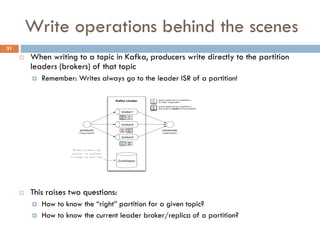


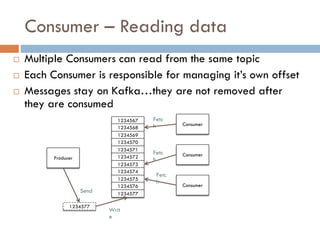
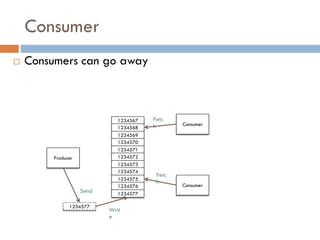
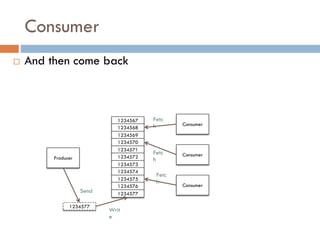

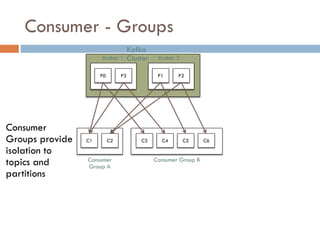
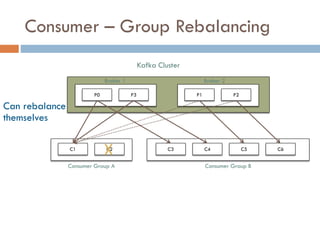
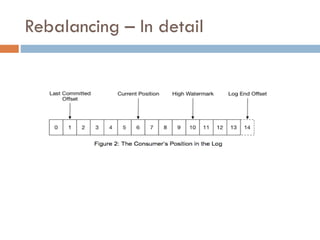







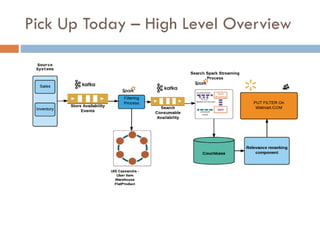

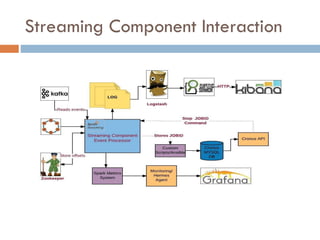


Apache Kafka is a distributed streaming platform used at WalmartLabs for various search use cases. It decouples data pipelines and allows real-time data processing. The key concepts include topics to categorize messages, producers that publish messages, brokers that handle distribution, and consumers that process message streams. WalmartLabs leverages features like partitioning for parallelism, replication for fault tolerance, and low-latency streaming.



































































