Downloaded 80 times


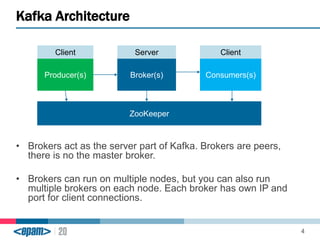
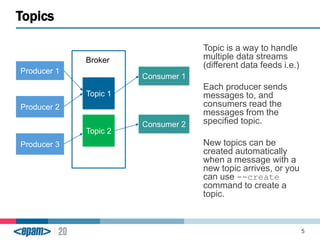

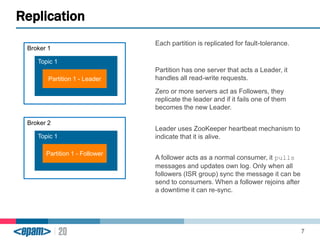
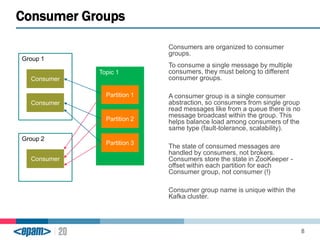

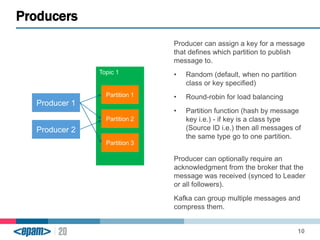
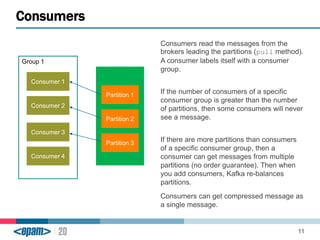


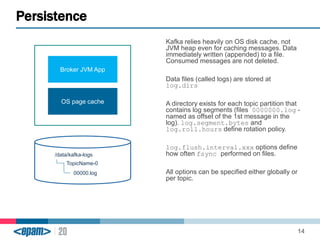
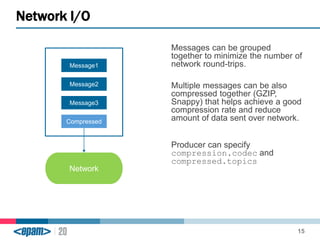
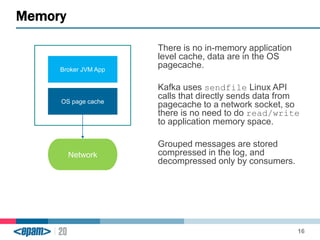



Apache Kafka is a scalable, fault-tolerant messaging system that functions as a publish-subscribe model connecting producers and consumers. It utilizes topics and partitions to manage data streams and ensures message durability and delivery through a broker system and a consumer group architecture. Additionally, Kafka supports advanced features such as message compression, log compaction, and retention policies for effective data handling.




















































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)




