
















![{
"text": "RT @PostGradProblem: In preparation for the NFL lockout, I will be spending twice as much time analyzing my fantasy baseball
team during ...",
"truncated": true,
"in_reply_to_user_id": null,
"in_reply_to_status_id": null,
"favorited": false,
"source": "<a href="http://twitter.com/" rel="nofollow">Twitter for iPhone</a>",
"in_reply_to_screen_name": null,
"in_reply_to_status_id_str": null,
"id_str": "54691802283900928",
"entities": {
"user_mentions": [
{
"indices": [
3,
19
],
"screen_name": "PostGradProblem",
"id_str": "271572434",
"name": "PostGradProblems",
"id": 271572434
}
],
"urls": [ ],
"hashtags": [ ]
},
"contributors": null,
"retweeted": false,
"in_reply_to_user_id_str": null,
"place": null,
"retweet_count": 4,
"created_at": "Sun Apr 03 23:48:36 +0000 2011",
"retweeted_status": {
"text": "In preparation for the NFL lockout, I will be spending twice as much time analyzing my fantasy baseball team during
company time. #PGP",
"truncated": false,
"in_reply_to_user_id": null,
"in_reply_to_status_id": null,
"favorited": false,
"source": "<a href="http://www.hootsuite.com" rel="nofollow">HootSuite</a>",
"in_reply_to_screen_name": null,
"in_reply_to_status_id_str": null,
"id_str": "54640519019642881",
"entities": {
"user_mentions": [ ],
"urls": [ ],
"hashtags": [
Twitter JSON Payload ~6kb](https://image.slidesharecdn.com/clevelandkafka2020-11-02-201103190038/75/From-Message-to-Cluster-A-Realworld-Introduction-to-Kafka-Capacity-Planning-24-2048.jpg)





























































The document discusses Kafka capacity planning, focusing on essential factors such as average message size, estimated daily quantity, replication factors, and network and disk throughput. It emphasizes the importance of stress testing, monitoring, and understanding trade-offs in Kafka's ecosystem for effective resource management. Additionally, it provides insights into compression options and the impact of topic partitions on performance and resource usage.
Introduction to Kafka and its relevance in capacity planning with presentation details.
Introduction to Kafka and its relevance in capacity planning with presentation details.
Overview of topics to be discussed, including retention, estimated capacity, and more.
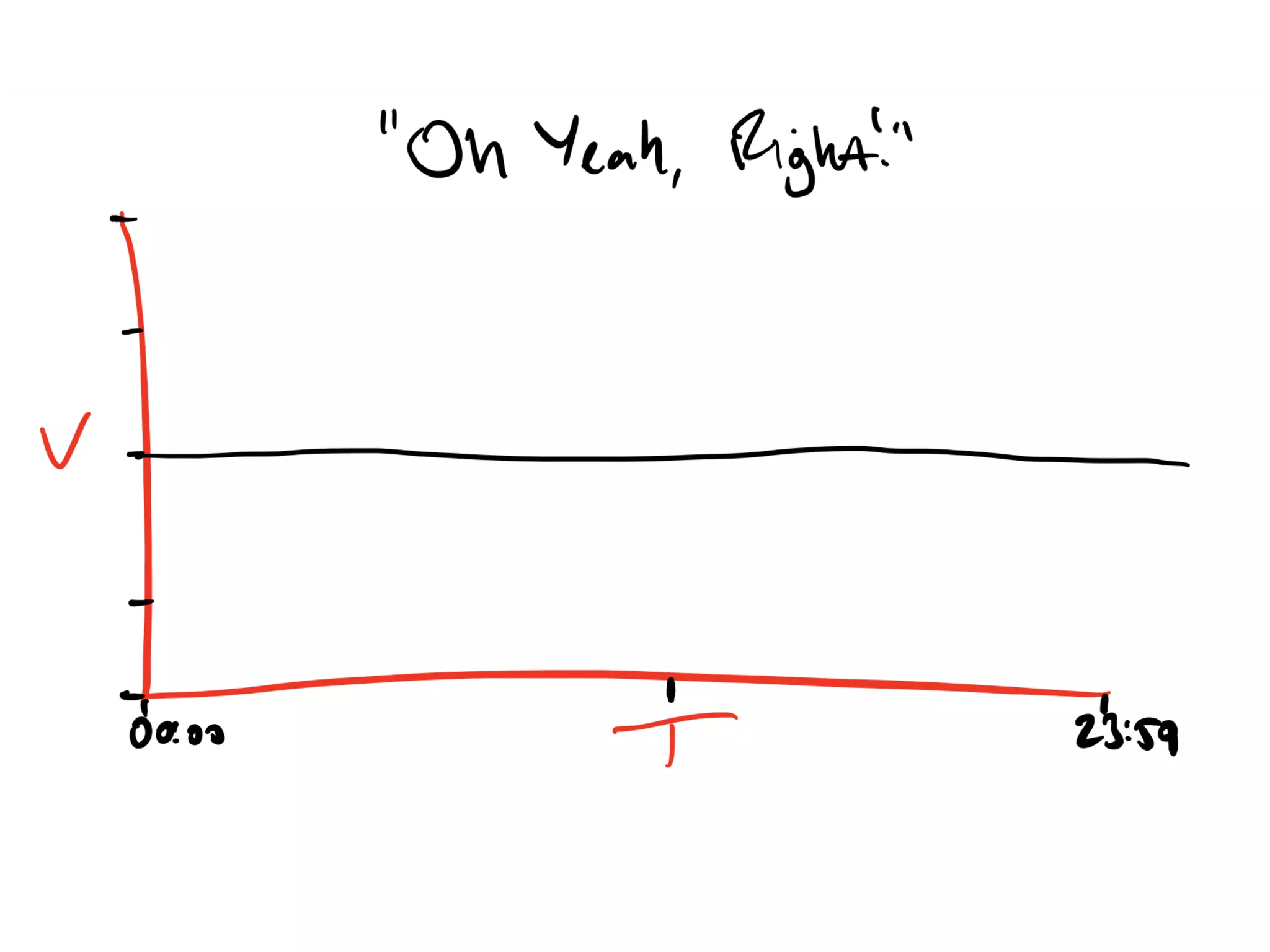
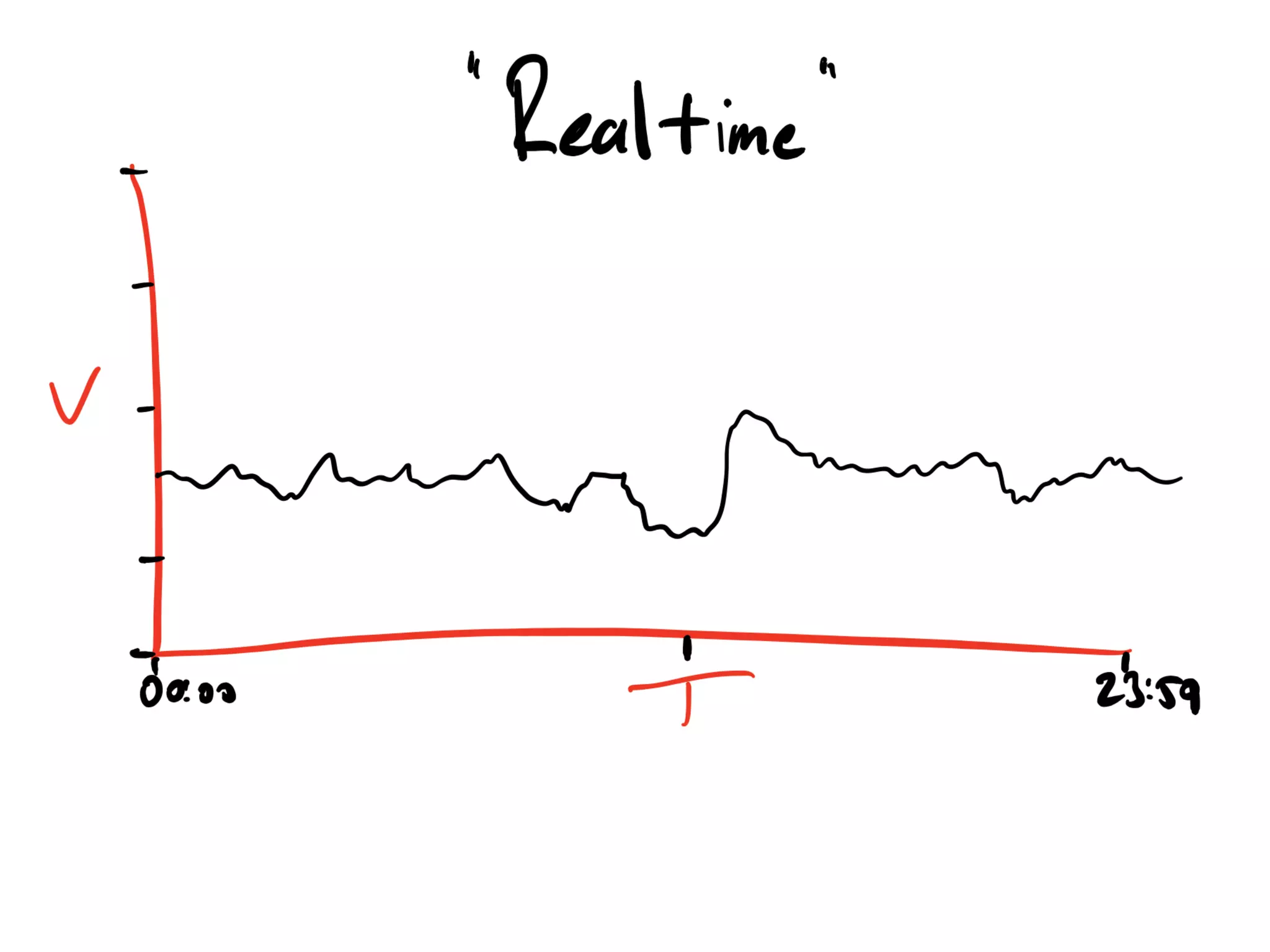
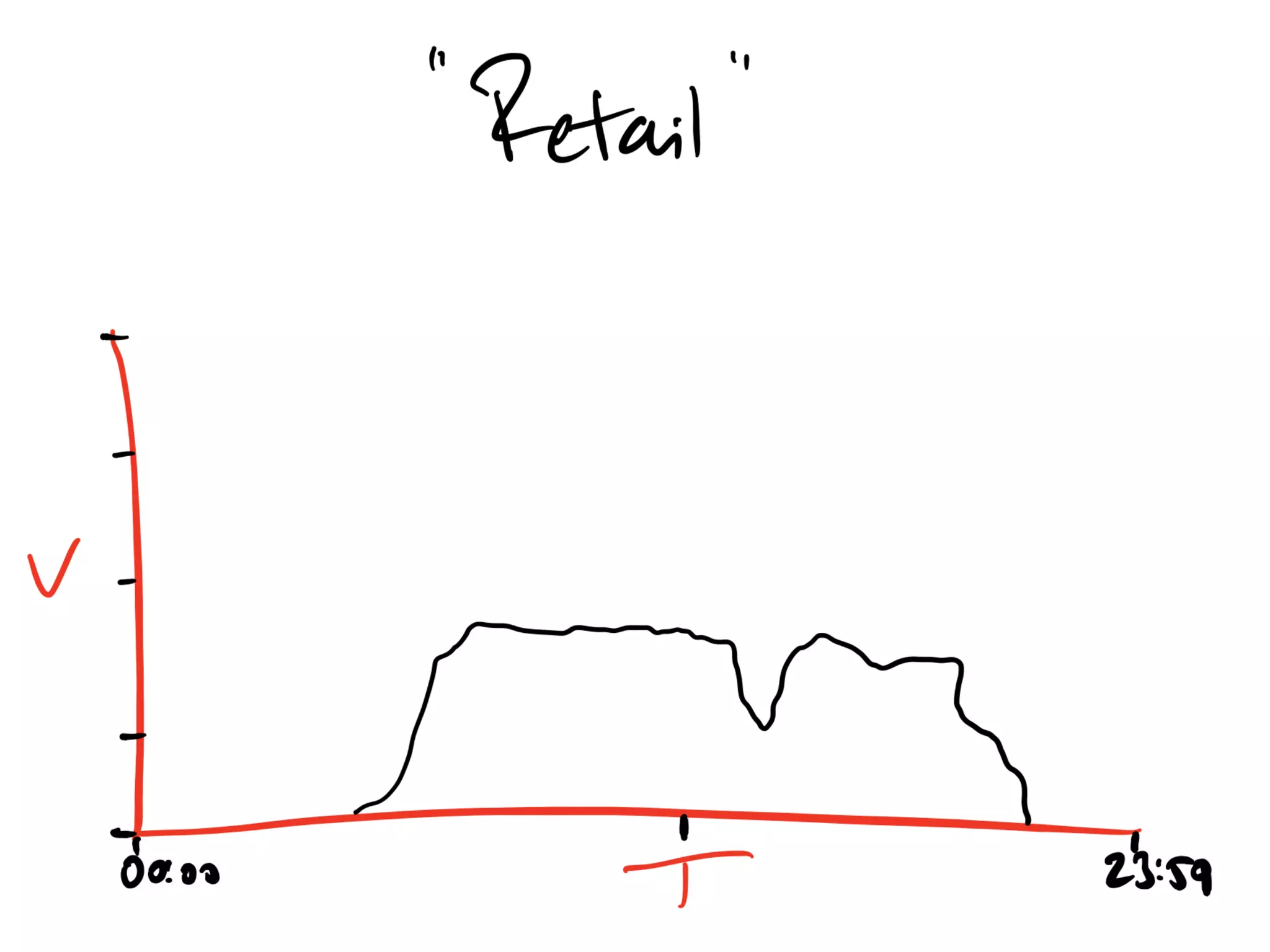
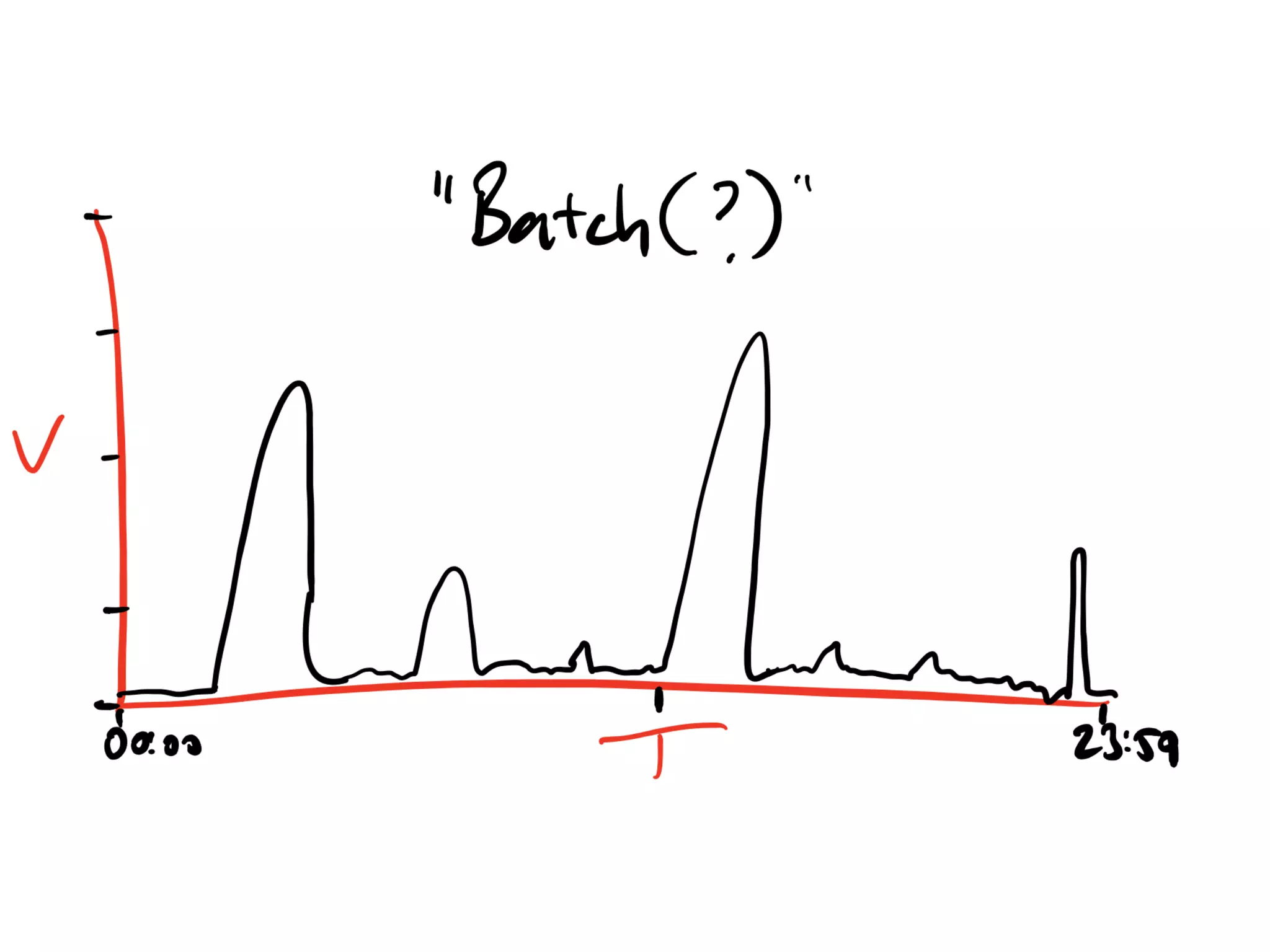
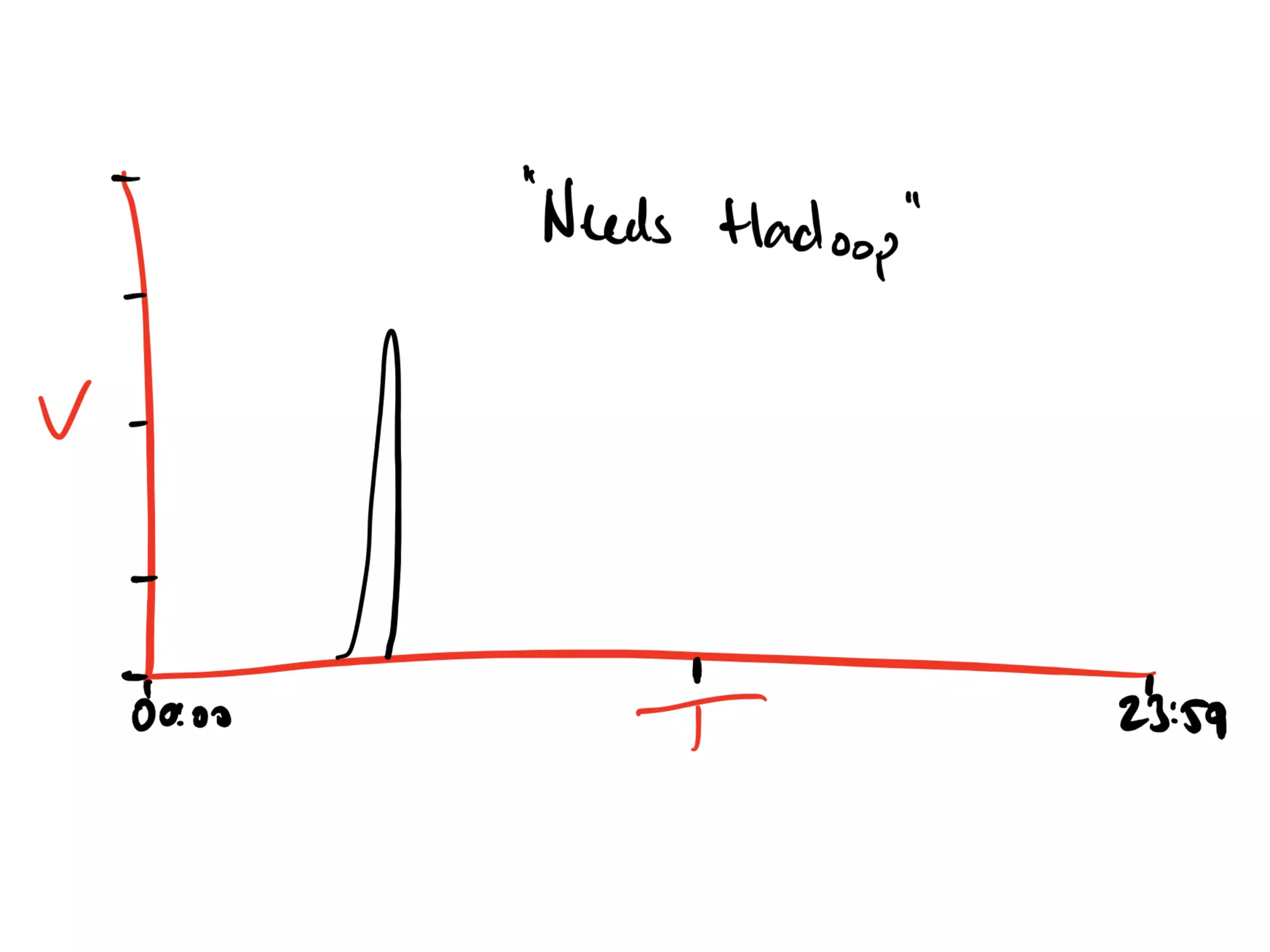
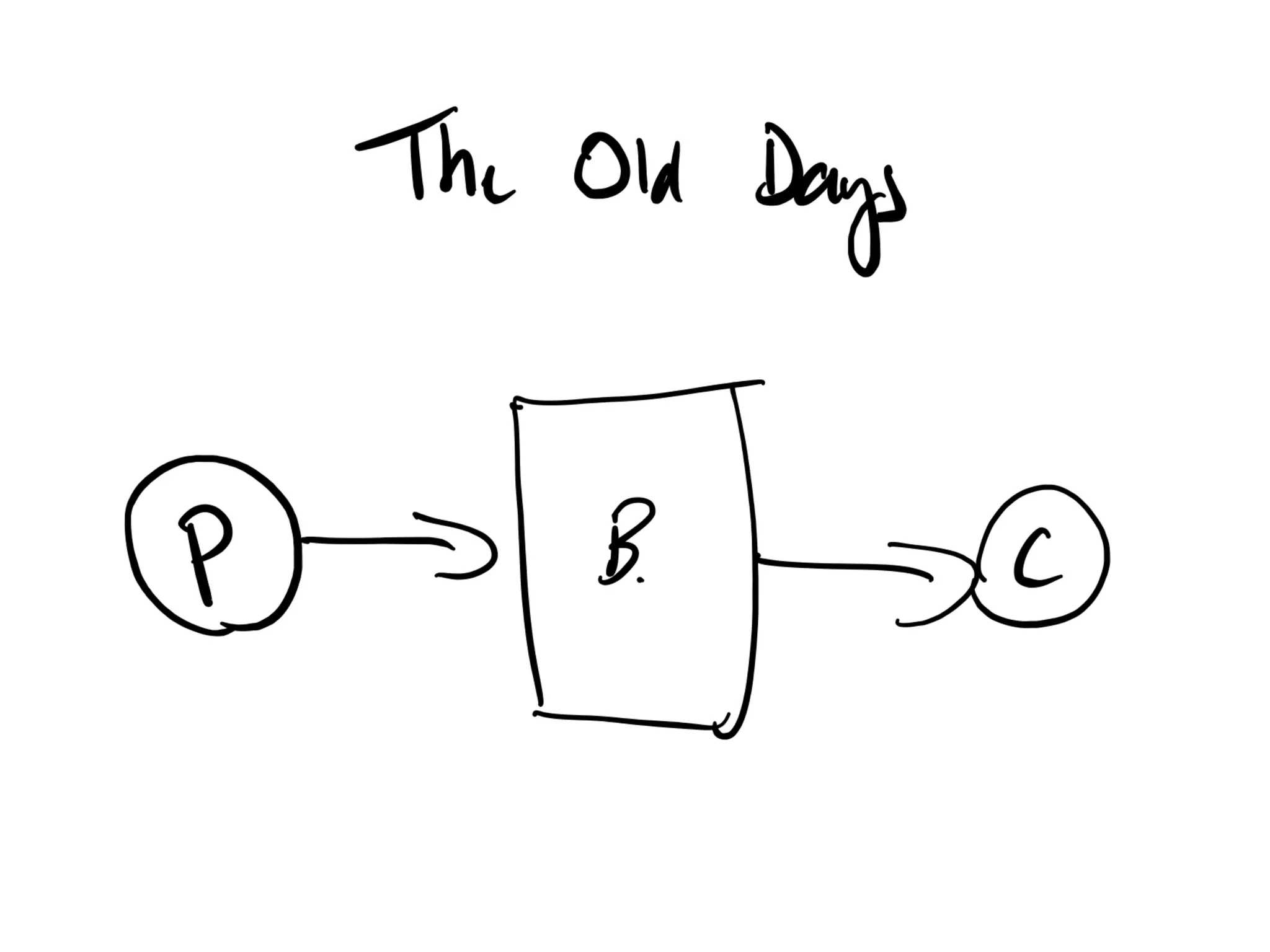
Discussion on past and present Kafka usage and common misunderstandings in cluster requirements.
Discussion on past and present Kafka usage and common misunderstandings in cluster requirements.
Discussion on past and present Kafka usage and common misunderstandings in cluster requirements.
Details about message structure and requirements, including example JSON and tweet.
Details about message structure and requirements, including example JSON and tweet.
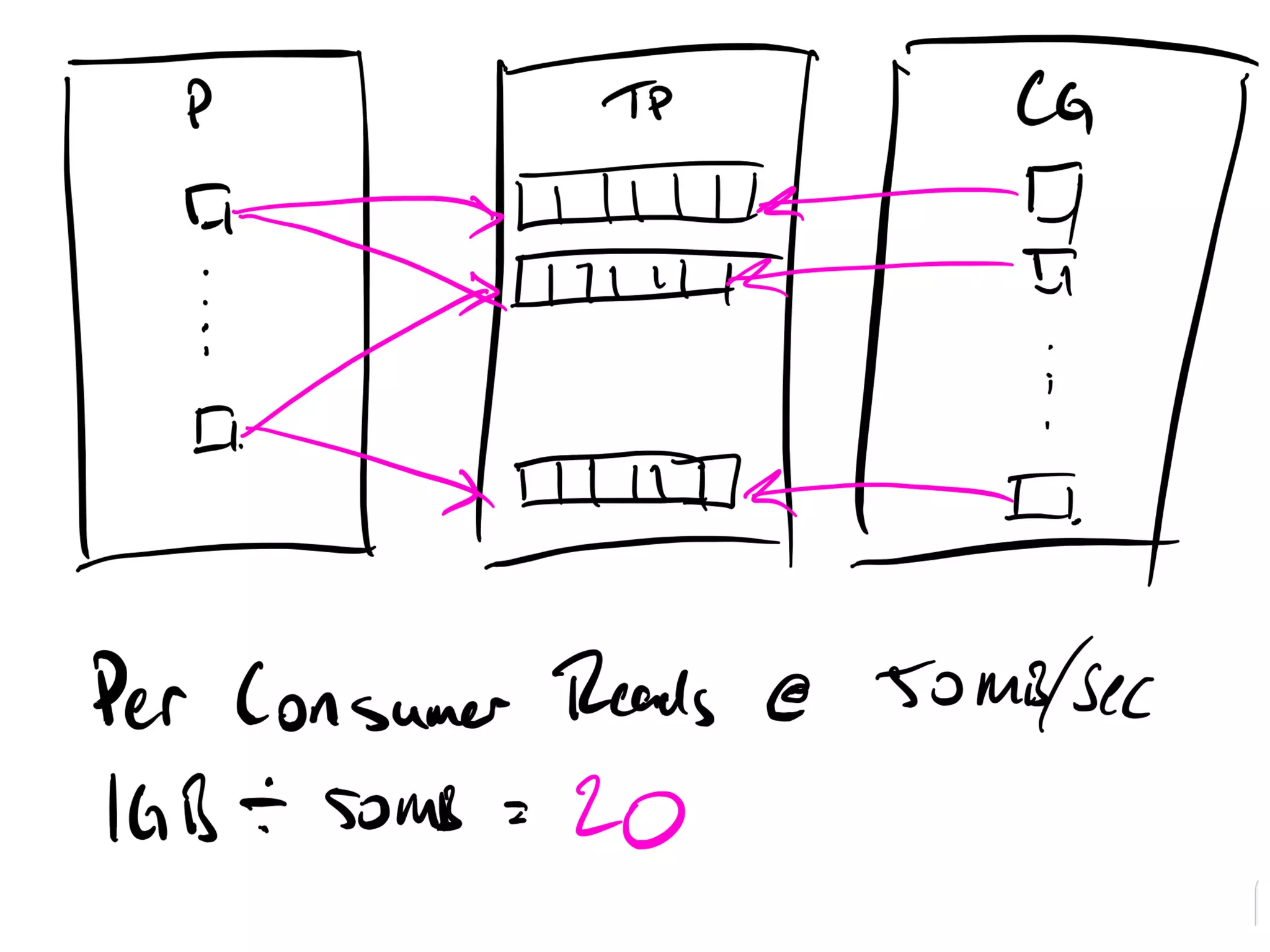
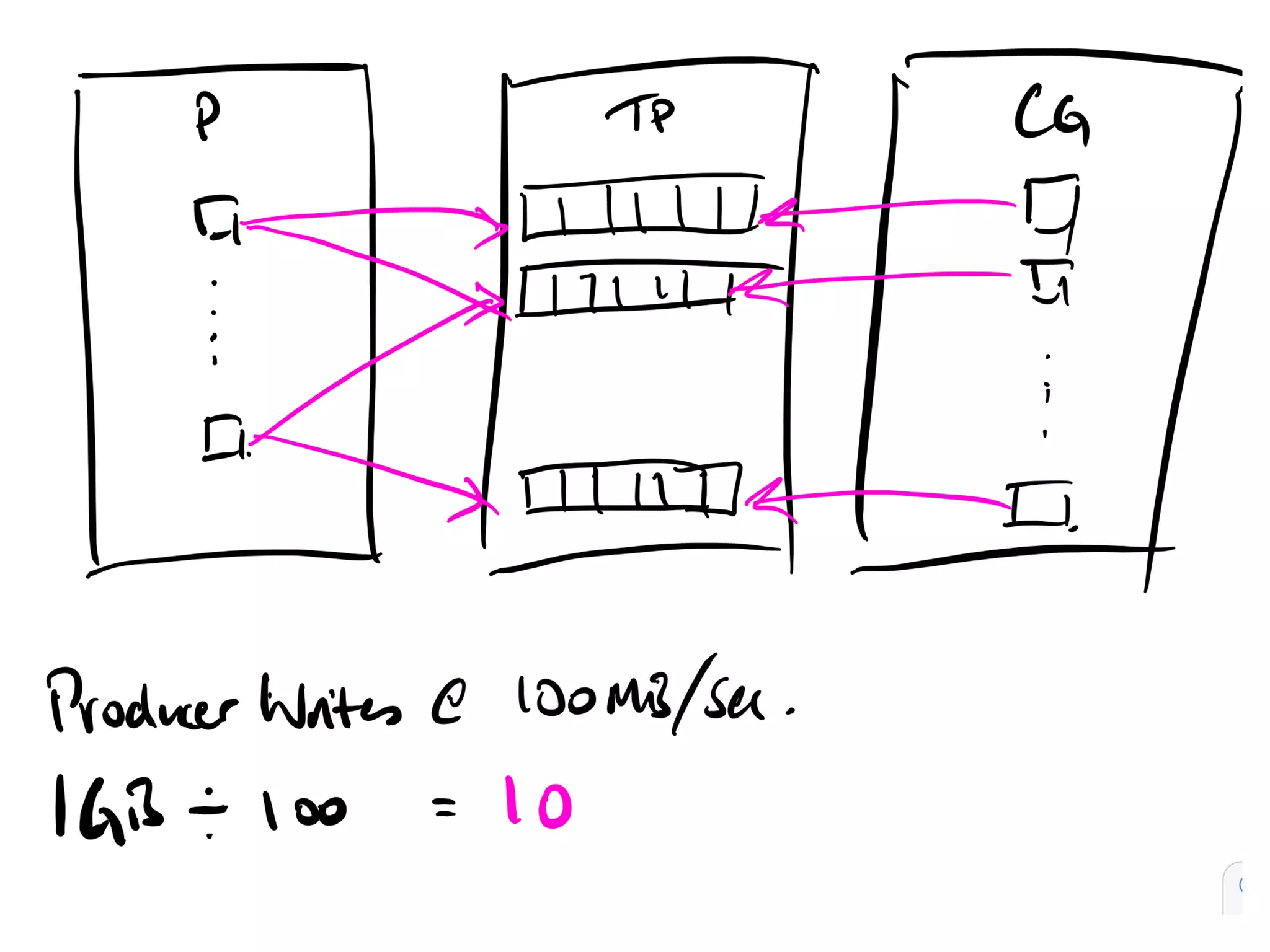
Key parameters for capacity planning: average message size, daily quantity, replication factor, etc.
Formulas and calculations for estimating capacity, including message size and retention.
Options for message compression and estimated efficiency improvements based on algorithms.
Introduction to Kafka performance tests and sample command outputs for benchmarking.
Factors affecting throughput: data writes, reads, memory caching, and network considerations.
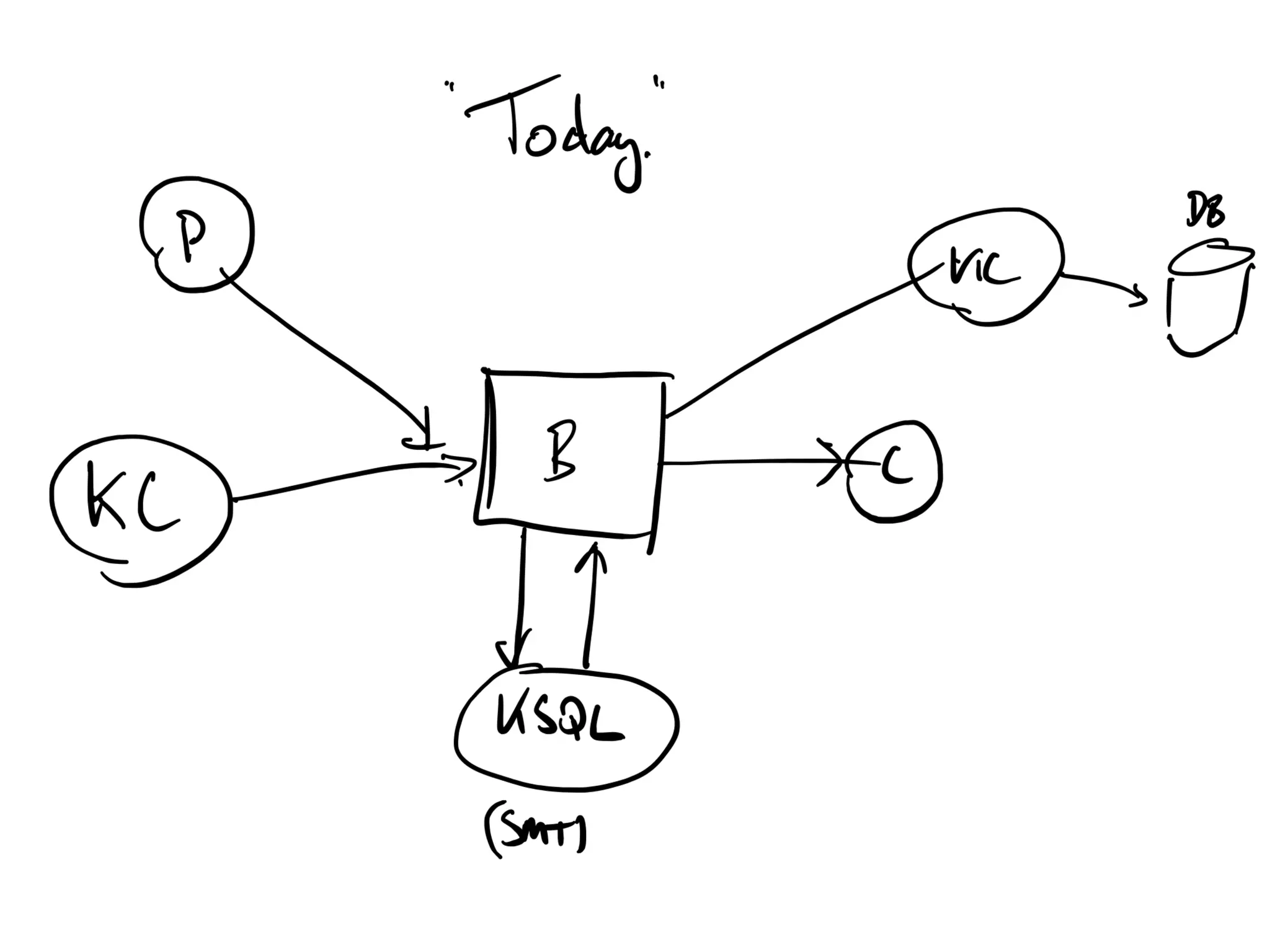
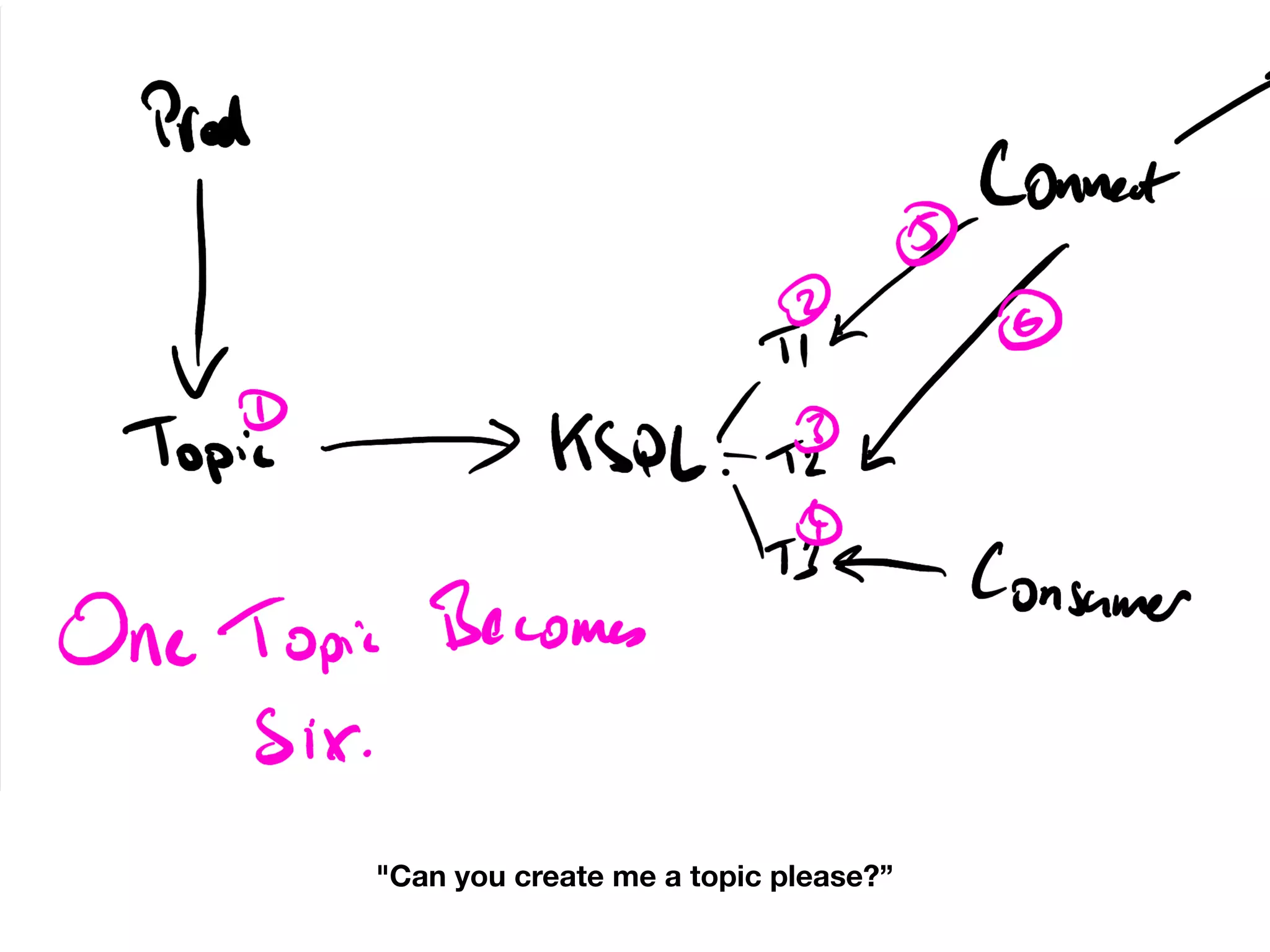
Guidance on partition management and effects on performance and Zookeeper.Overview of Kafka Connect implementations and consequences of failures.
Basic requirements for running ksqlDB and challenges related to query processing.
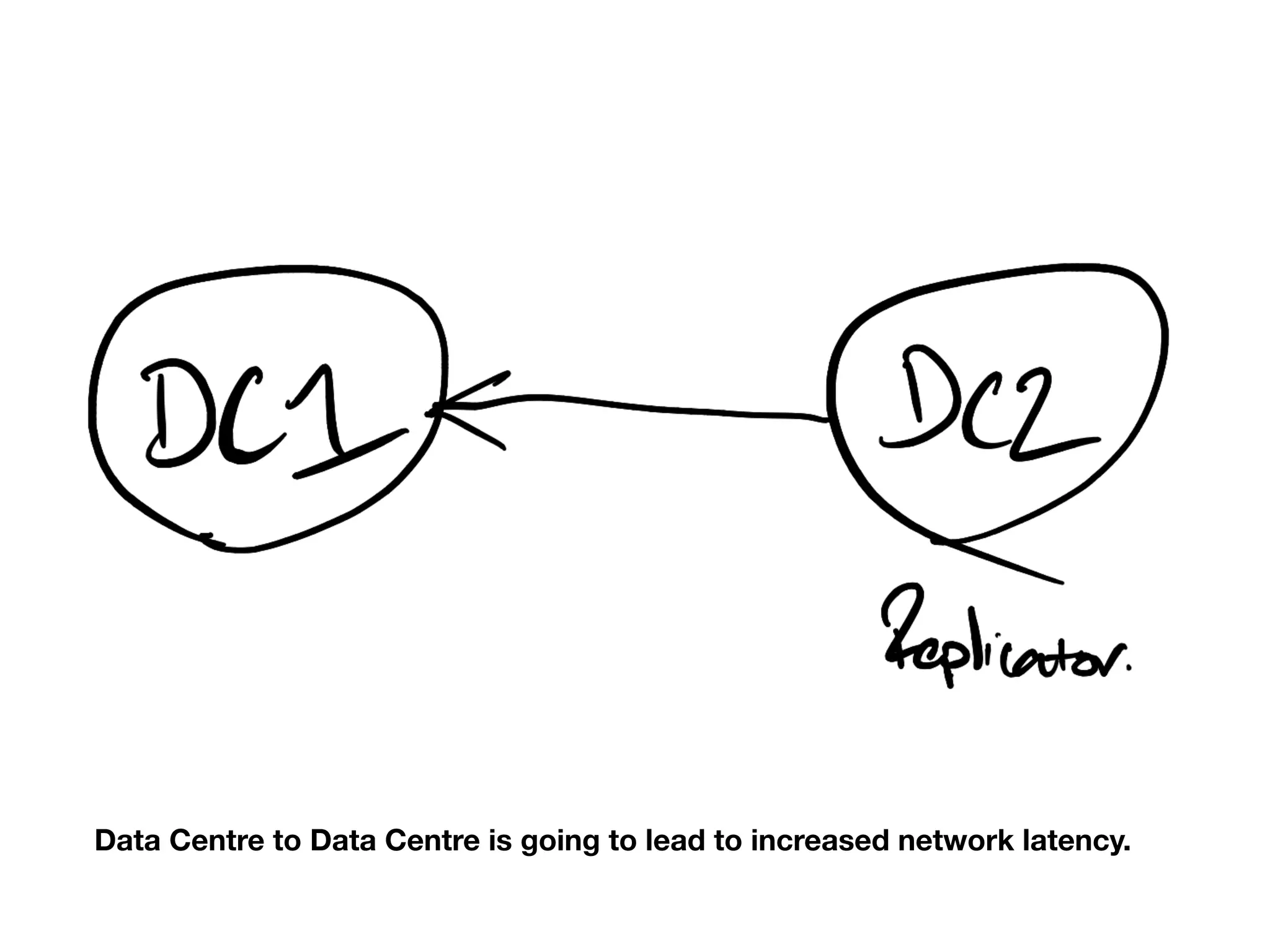
Challenges of data replication across data centers and performance tuning parameters.
Emphasizes importance of lag reports, trade-offs in planning, security considerations, and evolving ecosystem.
Thanking attendees and organizers for participation and support.
Thanking attendees and organizers for participation and support.







































































![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)


