



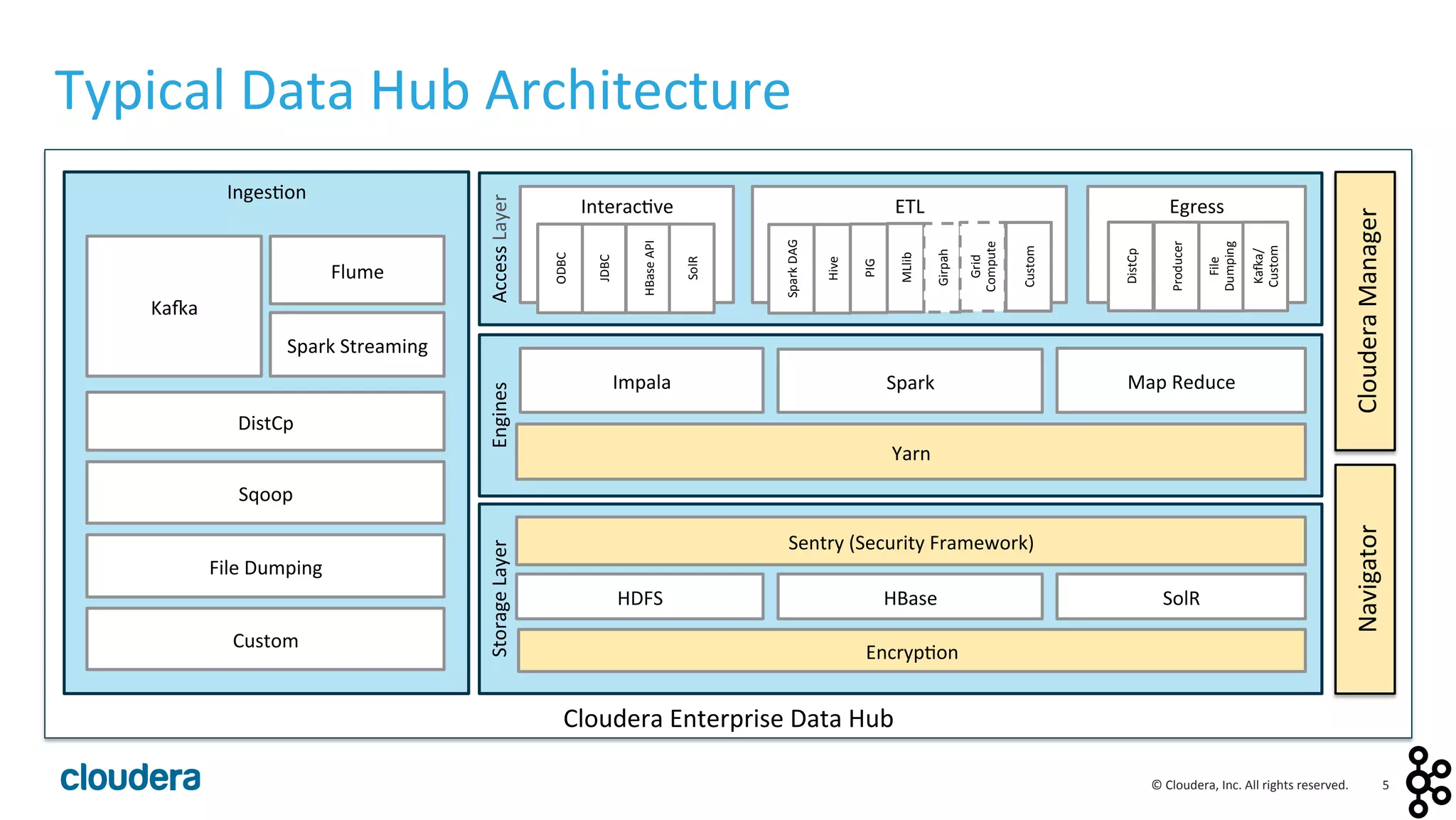
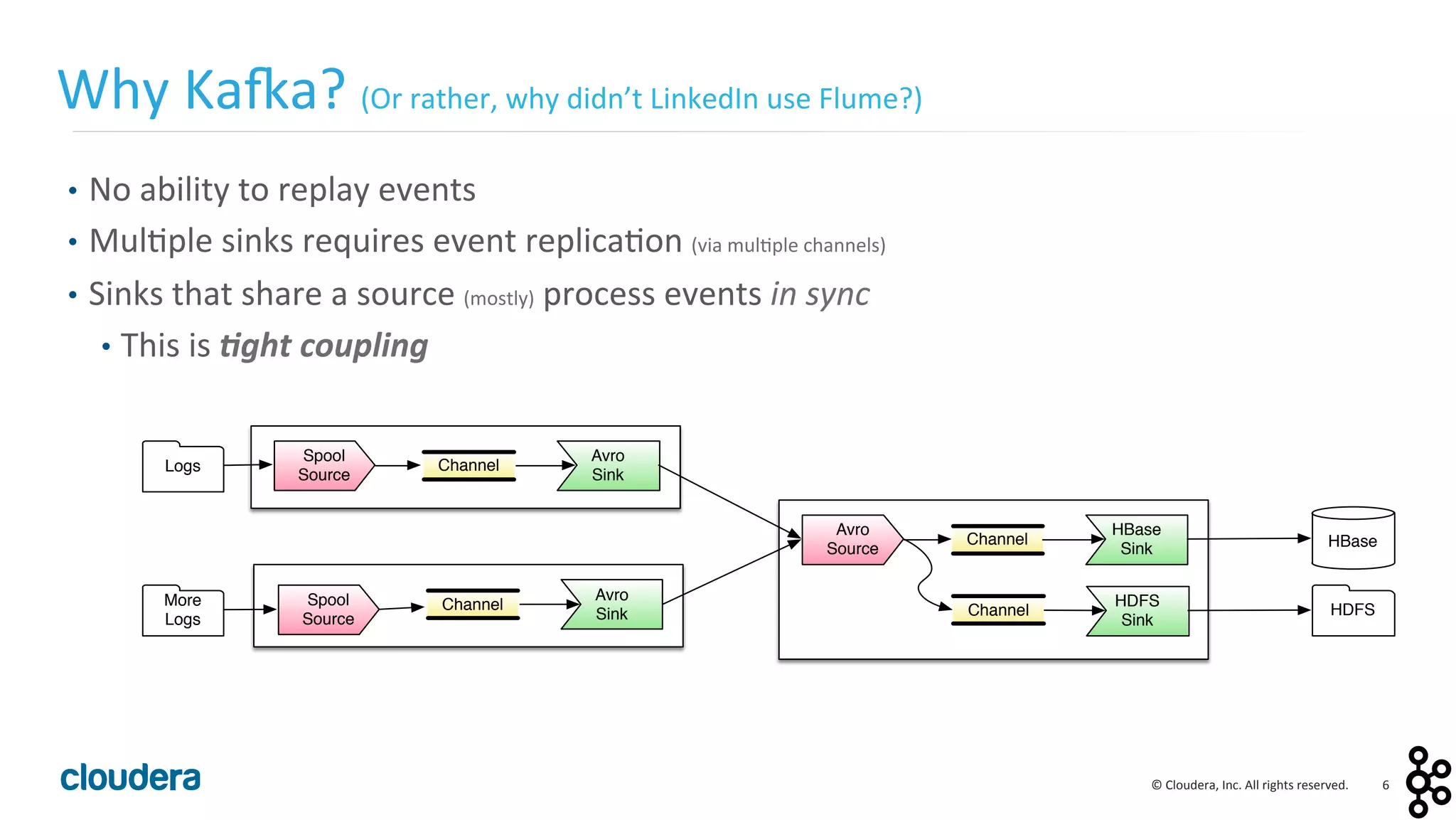
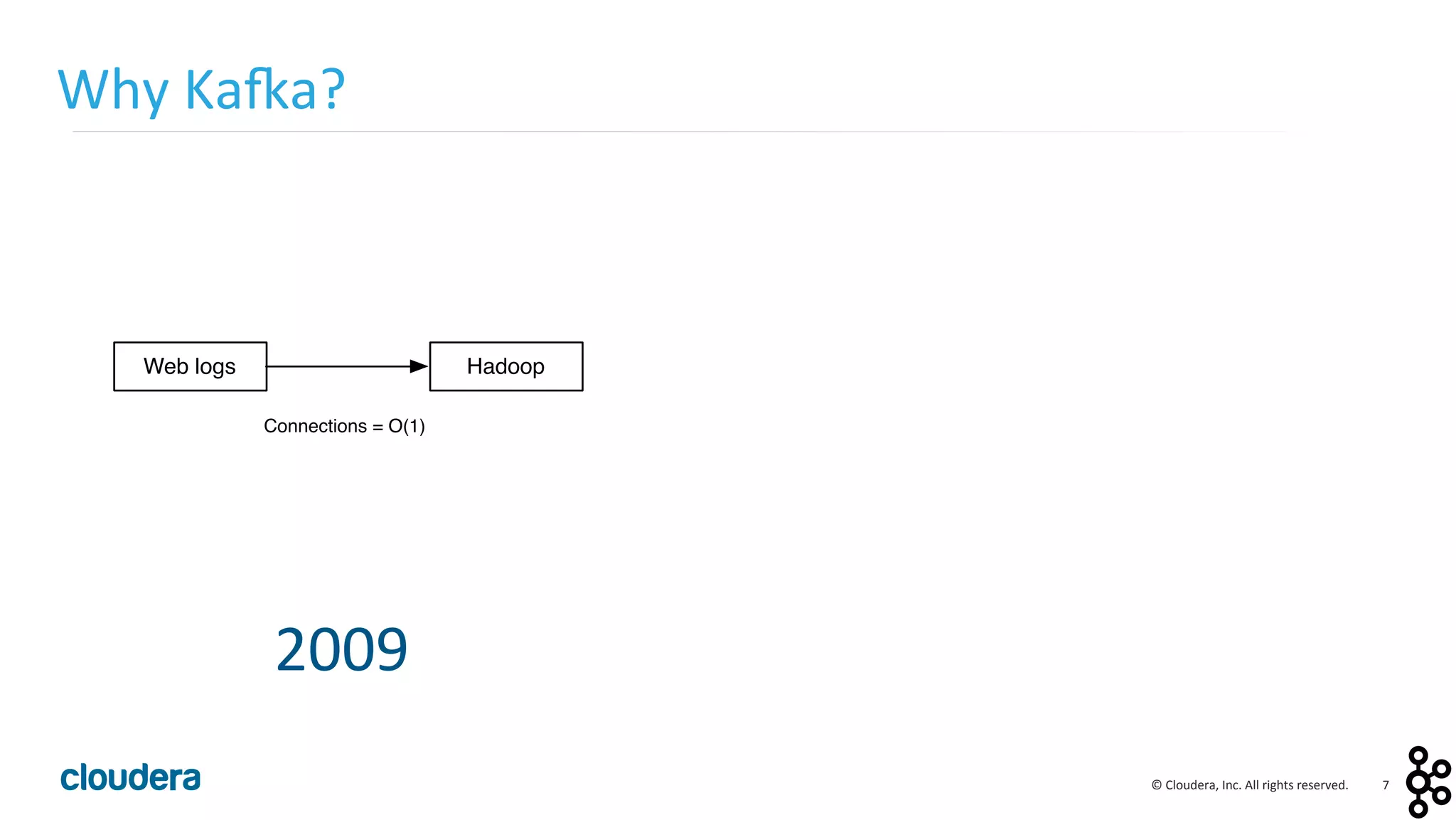
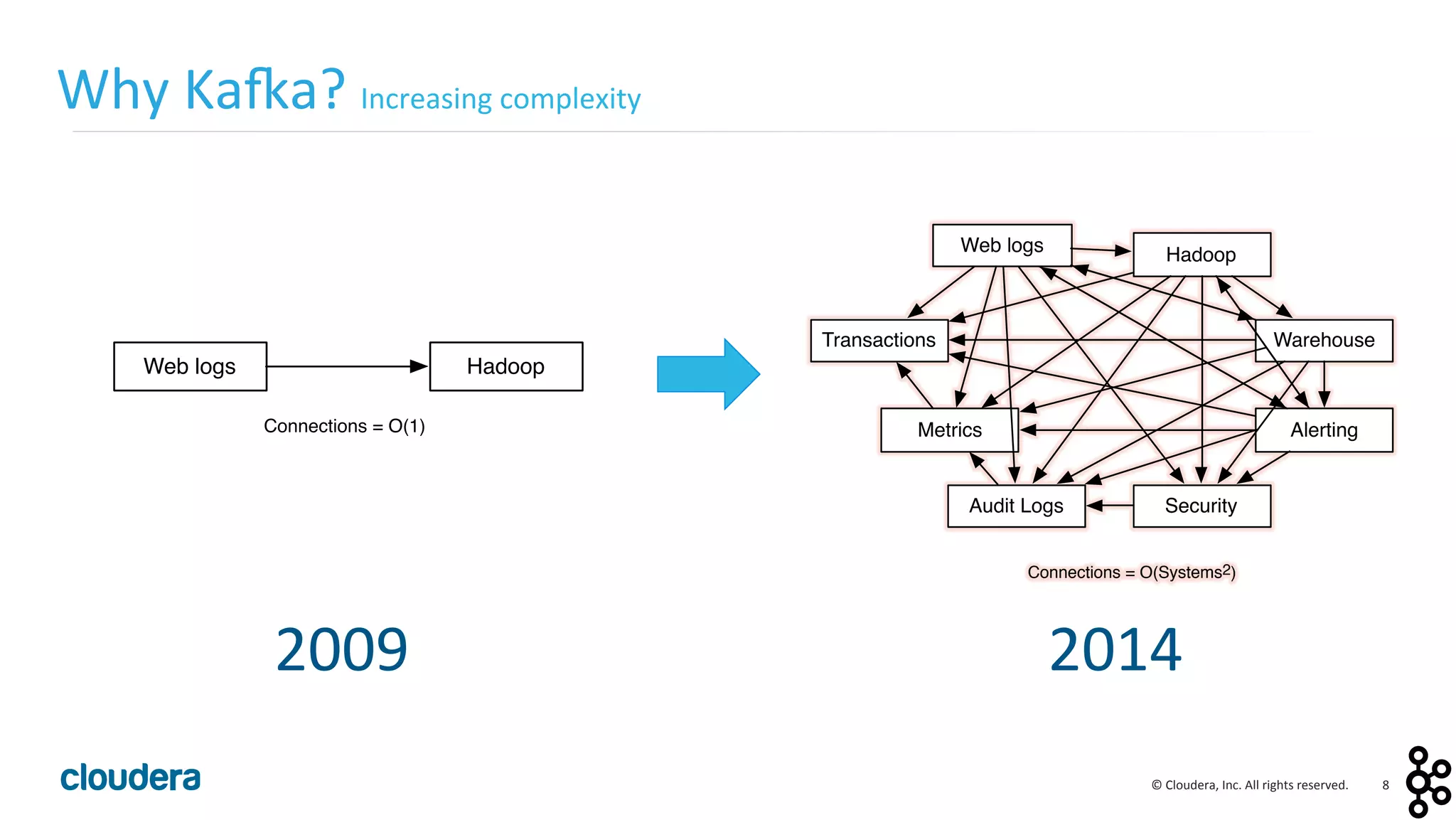
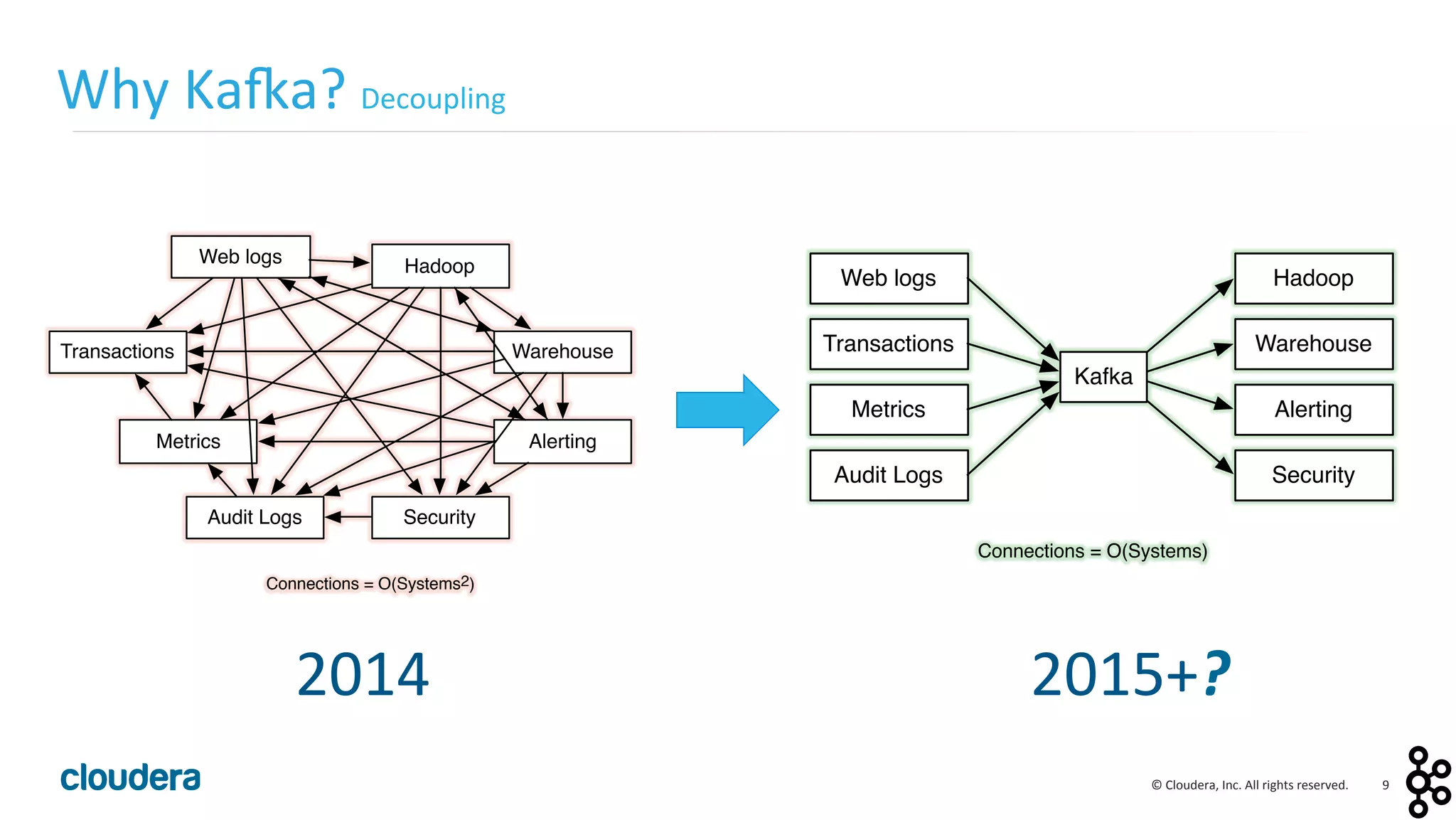

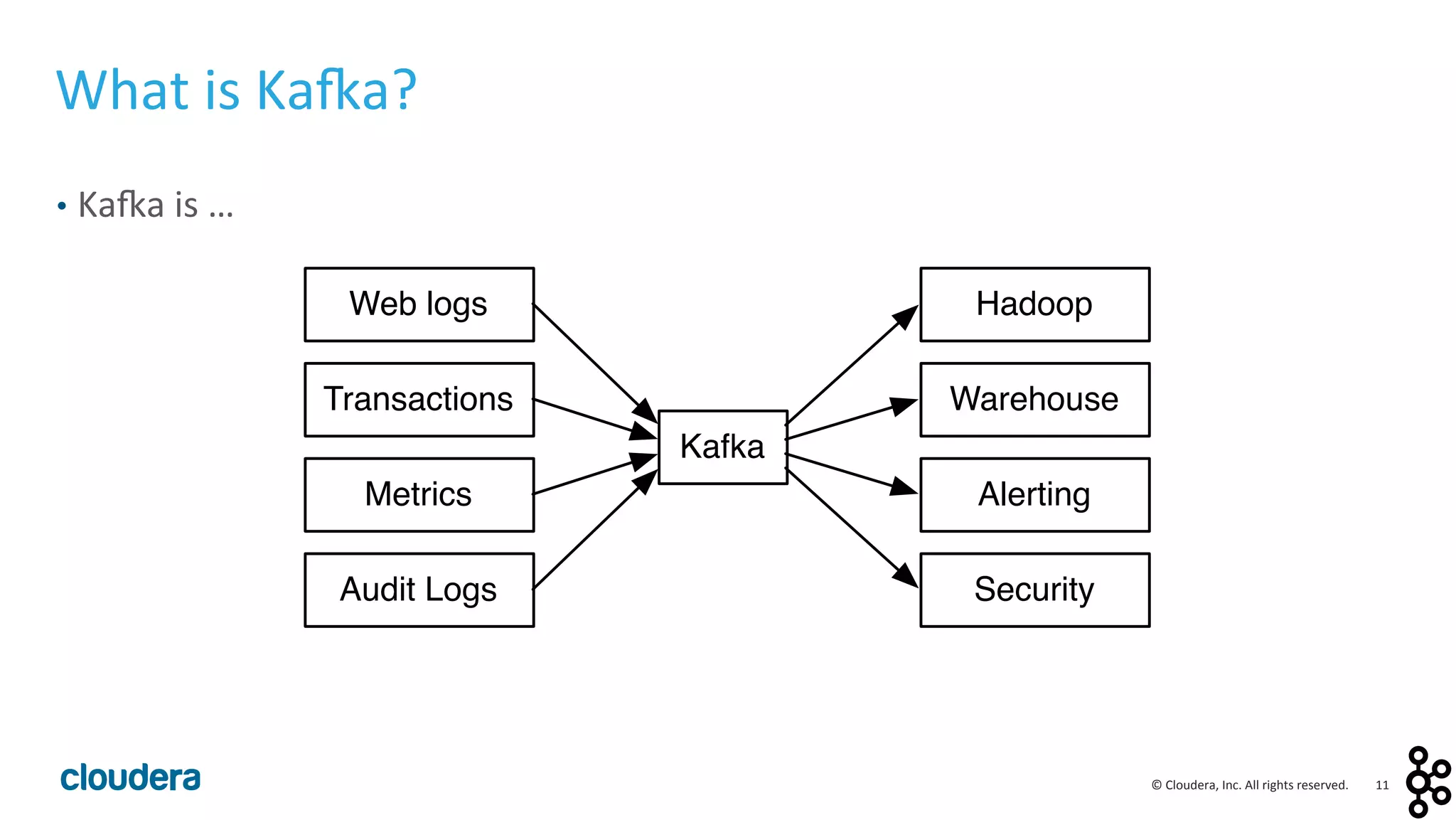
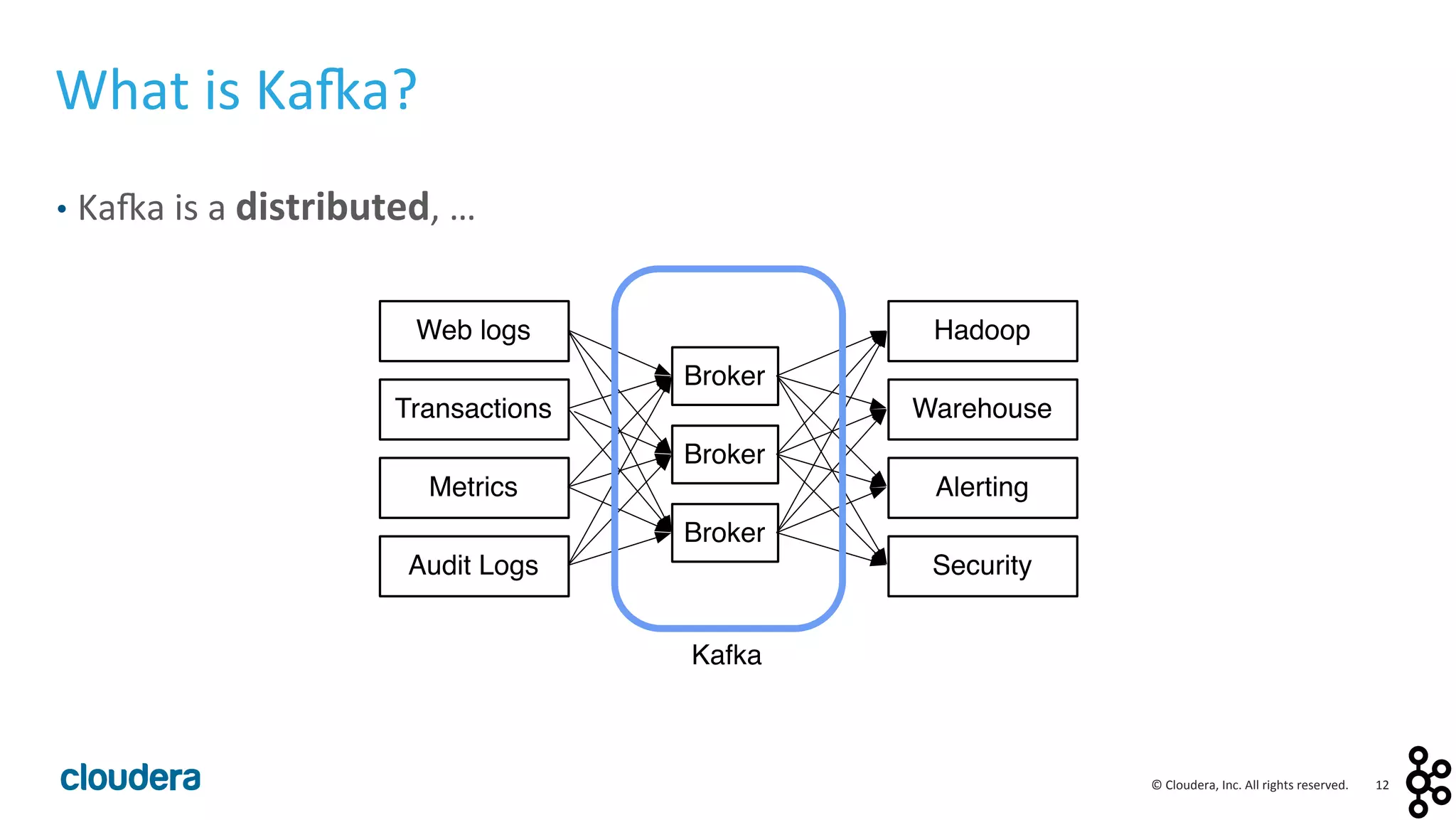
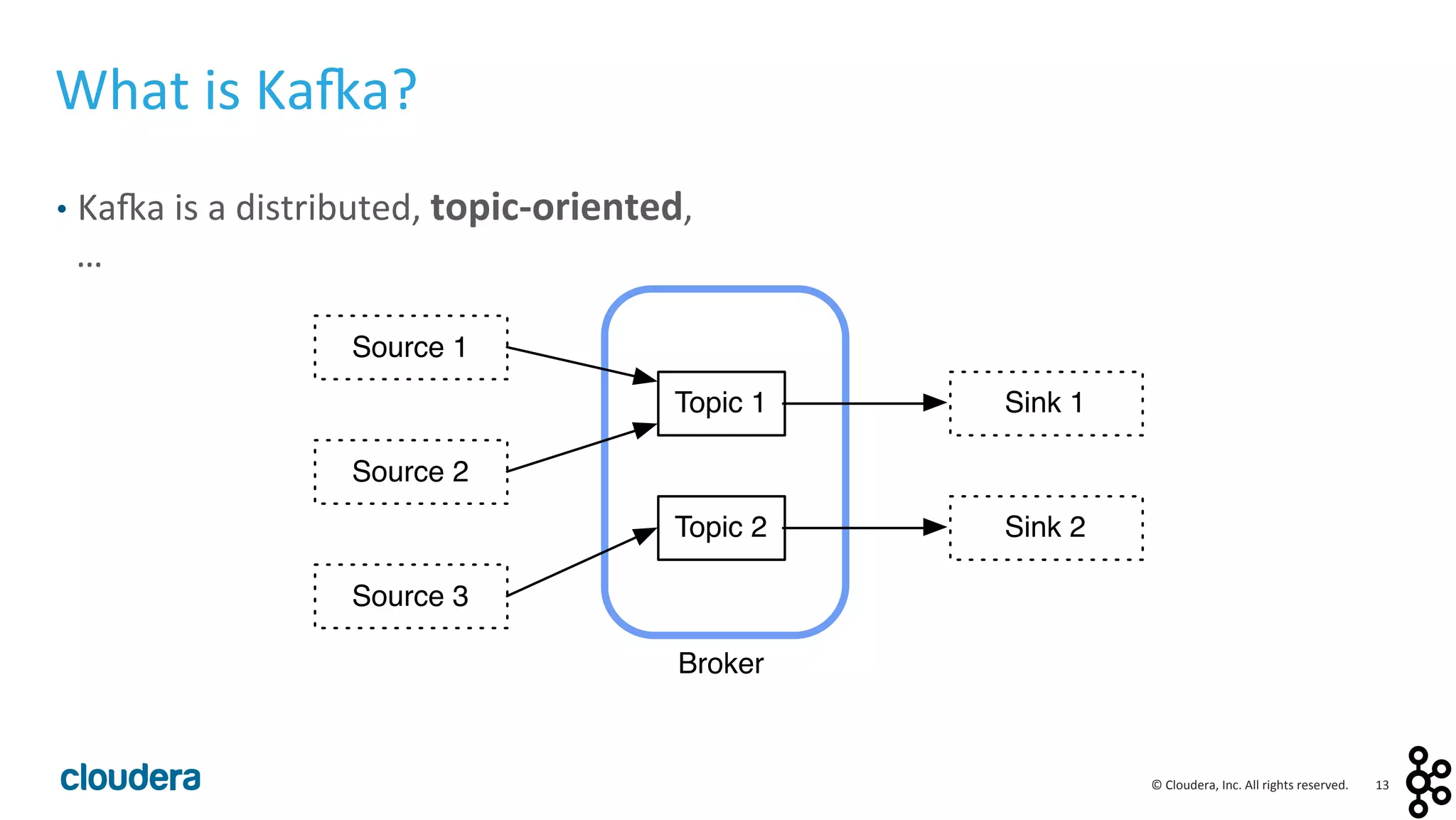
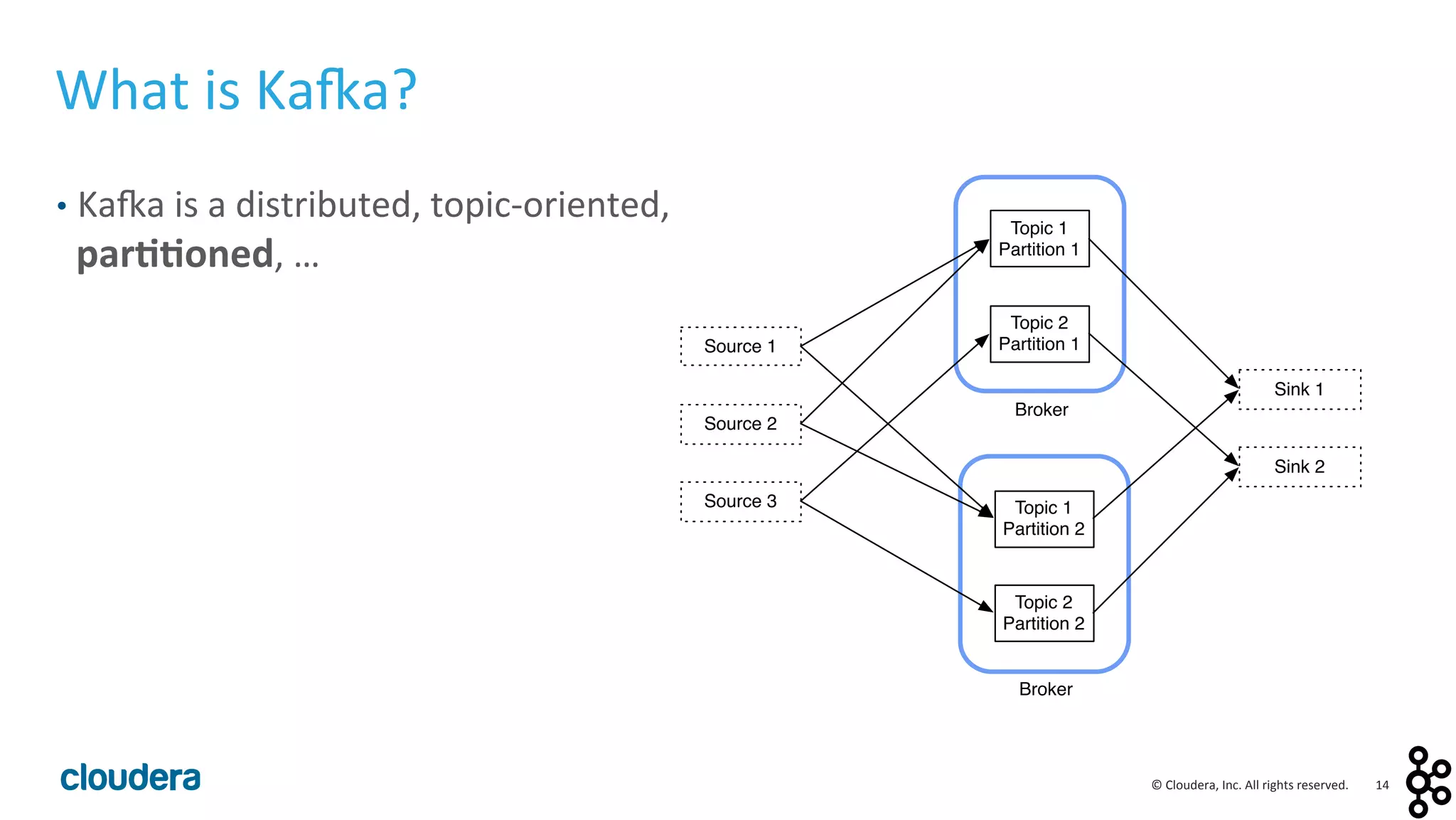
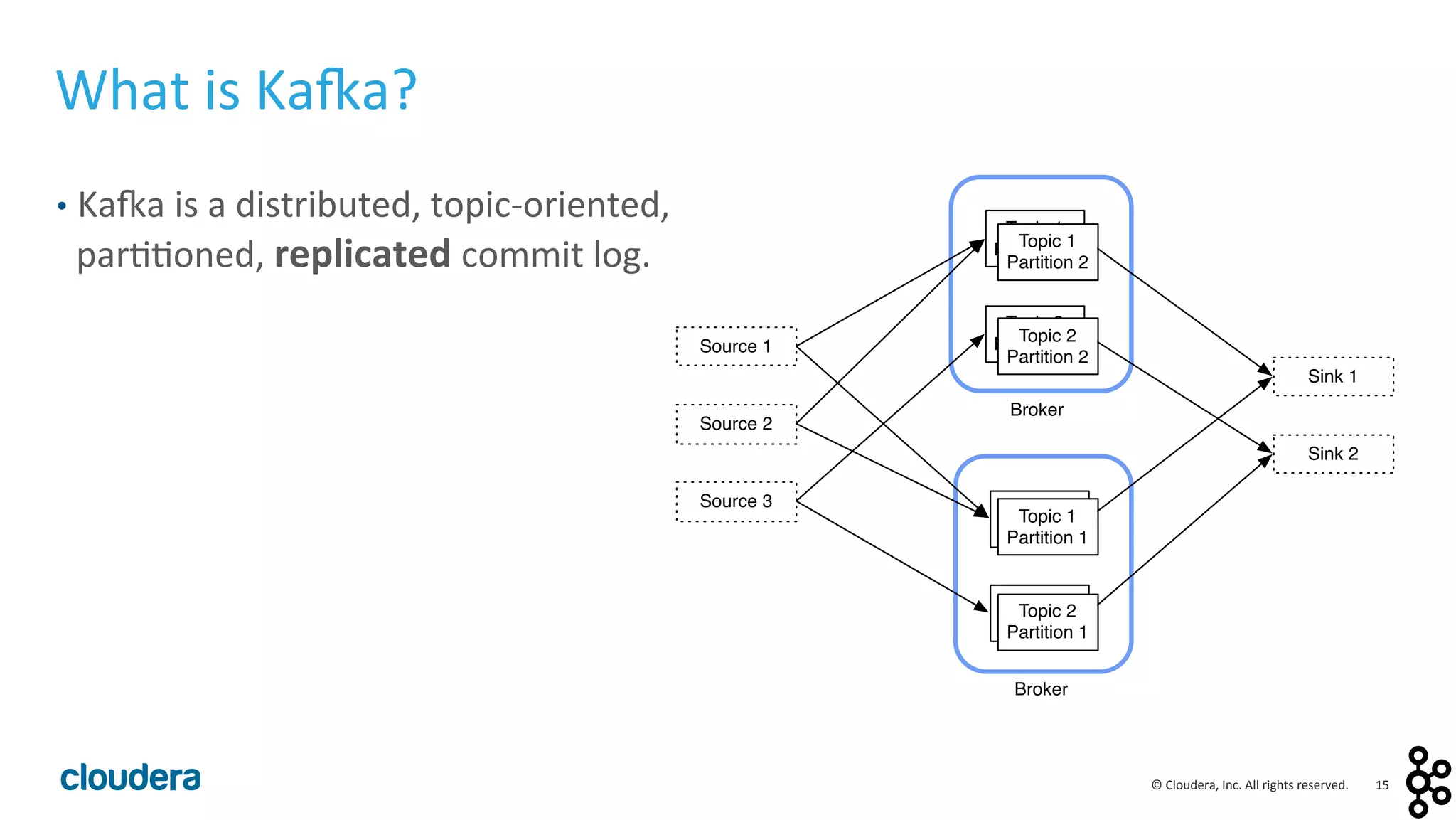
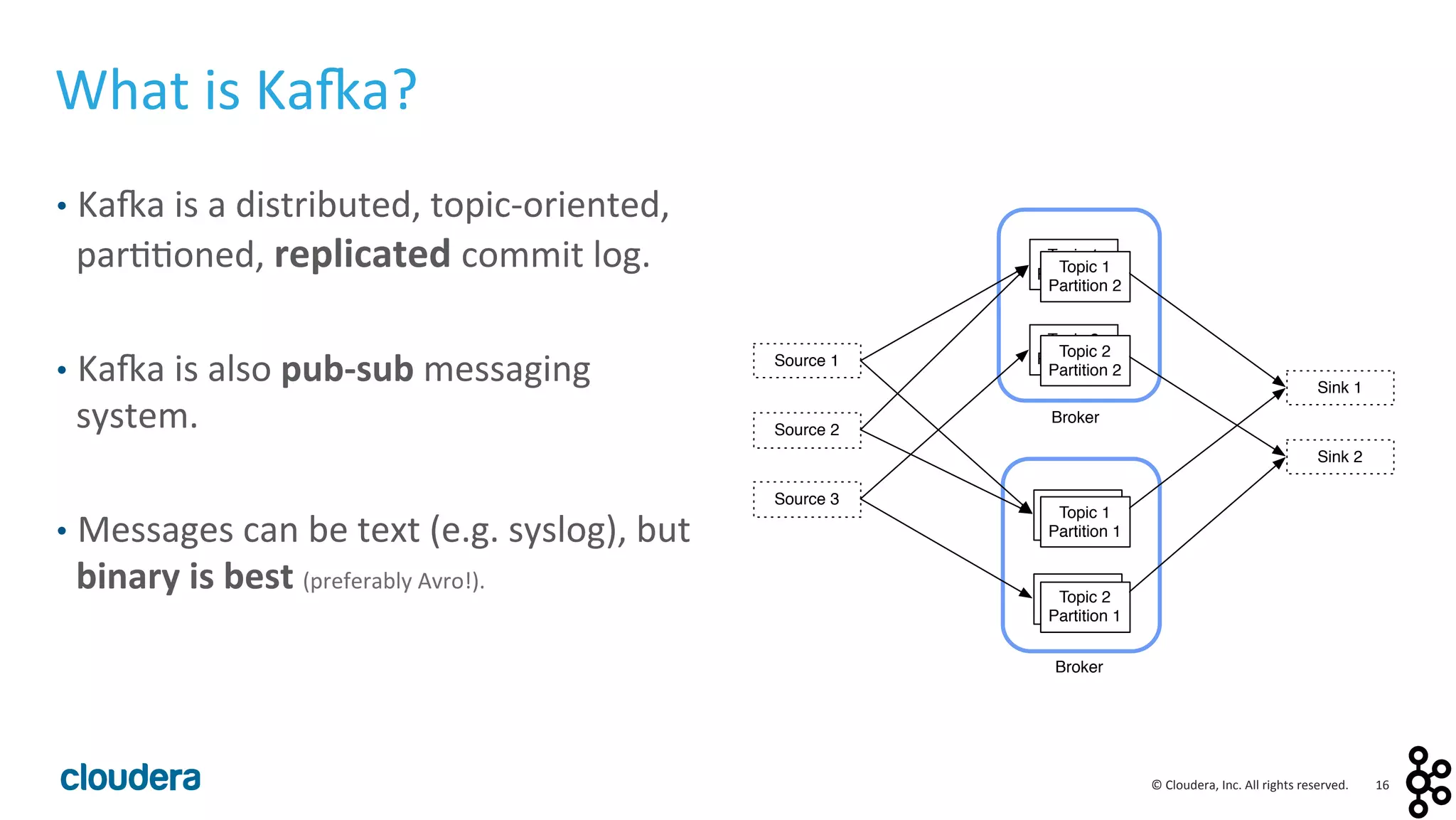
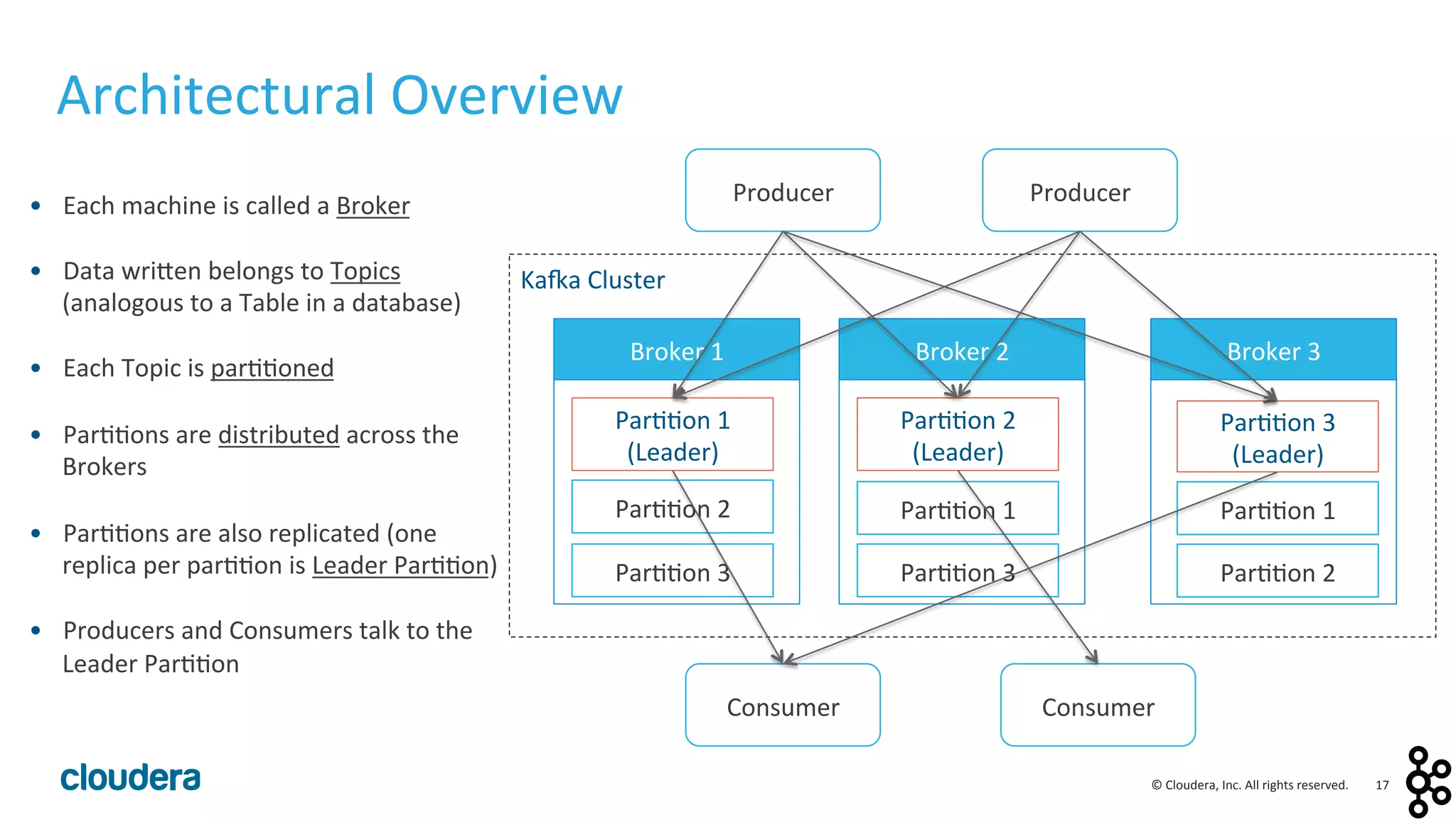
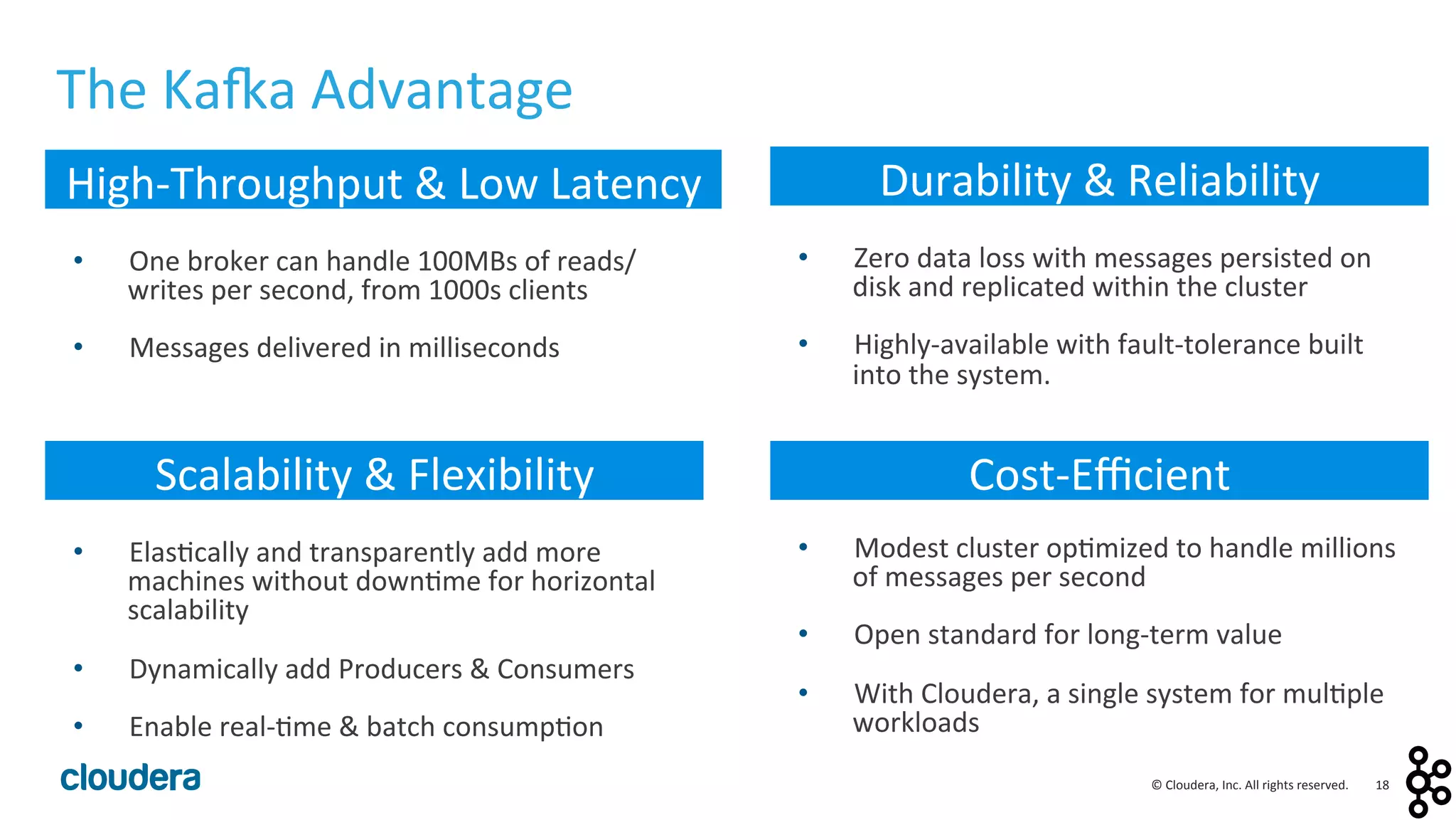






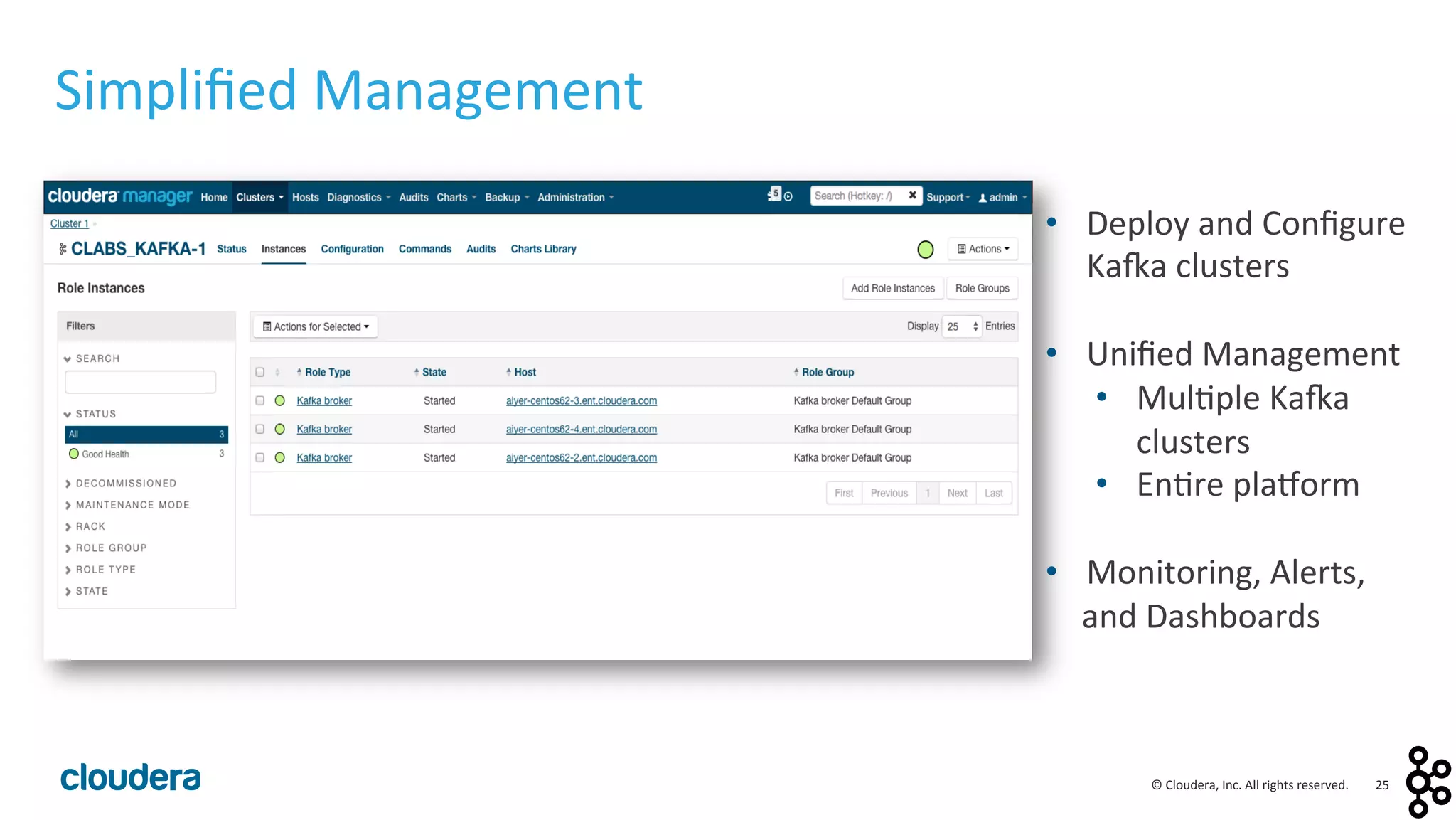
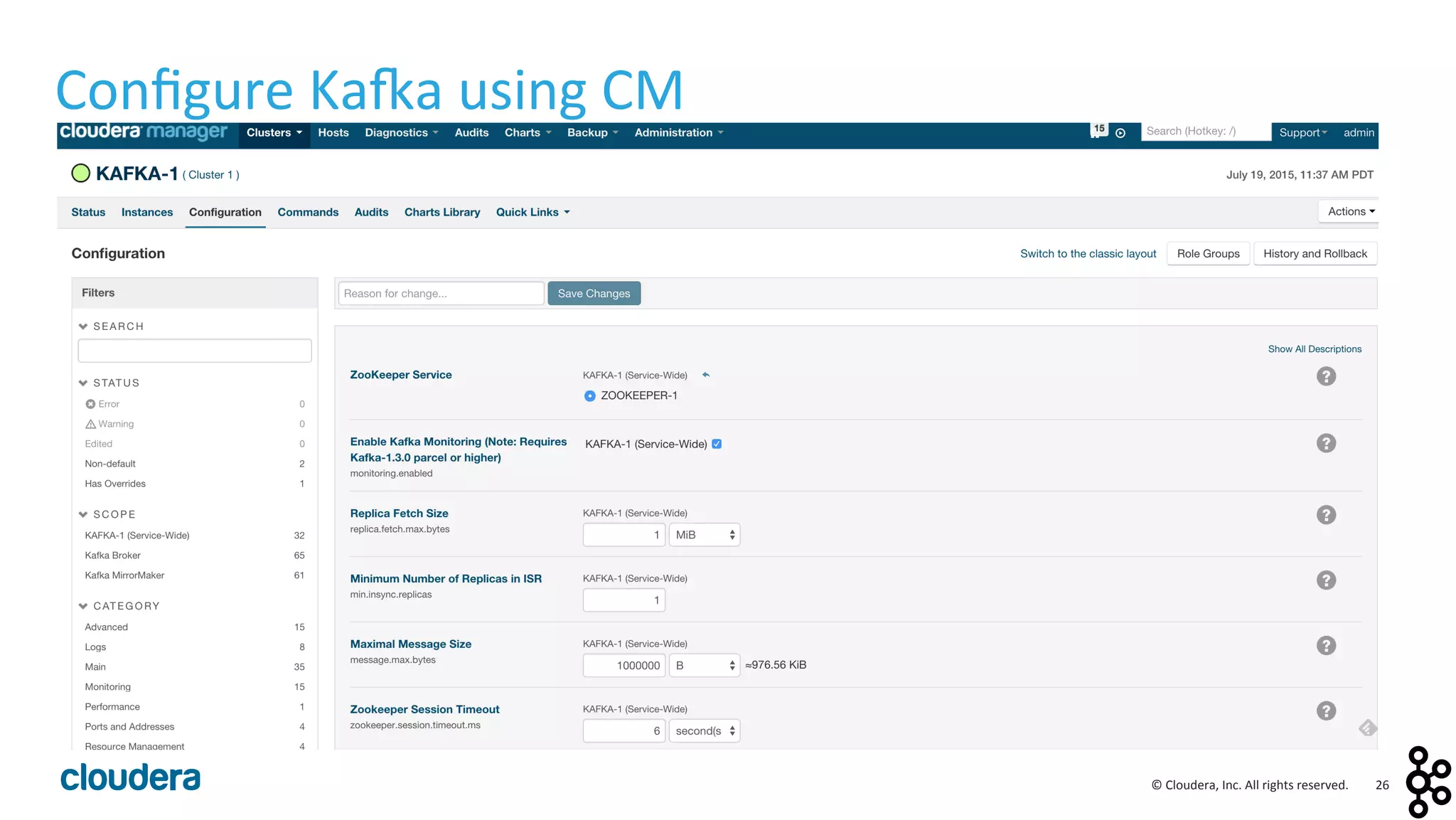
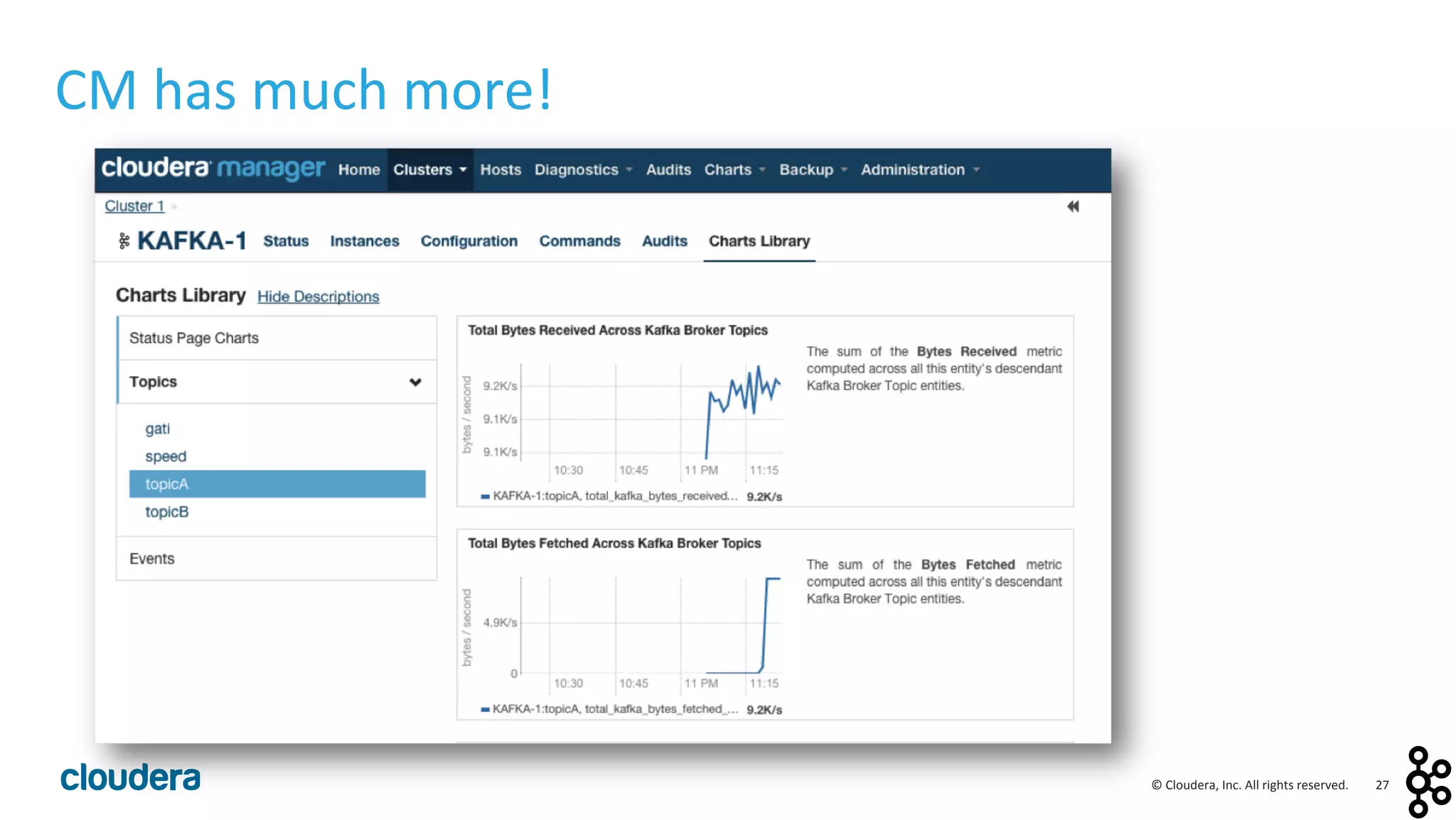









This document provides an overview and agenda for a presentation on Apache Kafka. The presentation will cover Kafka concepts and architecture, how it compares to traditional messaging systems, using Kafka with Cloudera, and a demo of installing and configuring Kafka on a Cloudera cluster. It will also discuss Kafka's role in ingestion pipelines and data integration use cases.























































































