Download to read offline








![PRODUCER SAMPLE CODE
import json
from kafka import KafkaProducer
# Send json data to a kafka topic
producer = KafkaProducer(value_serializer=json.dumps, bootstrap_servers=[kafka_url])
data = {key: value}
producer.send(“my-topic”, data )](https://image.slidesharecdn.com/kafka-overview-180110183659/85/Kafka-overview-14-320.jpg)
![CONSUMER SAMPLE CODE
from kafka import KafkaConsumer
# Connecting to kakfa and subscribing to a topic
consumer = KafkaConsumer(“my-topic”, group_id=“my-group”, bootstrap_servers=[kafka_url])
# Start consuming data
for msg in consumer:
print msg](https://image.slidesharecdn.com/kafka-overview-180110183659/85/Kafka-overview-15-320.jpg)




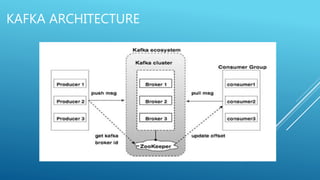
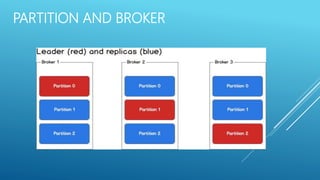
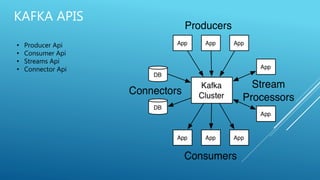
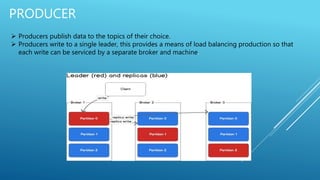
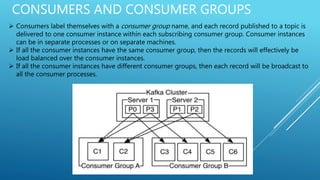
Apache Kafka is an open-source stream processing platform written in Scala and Java that provides a unified platform for handling real-time data feeds with high throughput and low latency. It operates as a cluster on one or more servers to store streams of records in categories called topics. Each record consists of a key, value, and timestamp. Producers publish data to topics while consumers subscribe to topics and receive messages. Topics are divided into partitions with replicas for redundancy.

































































