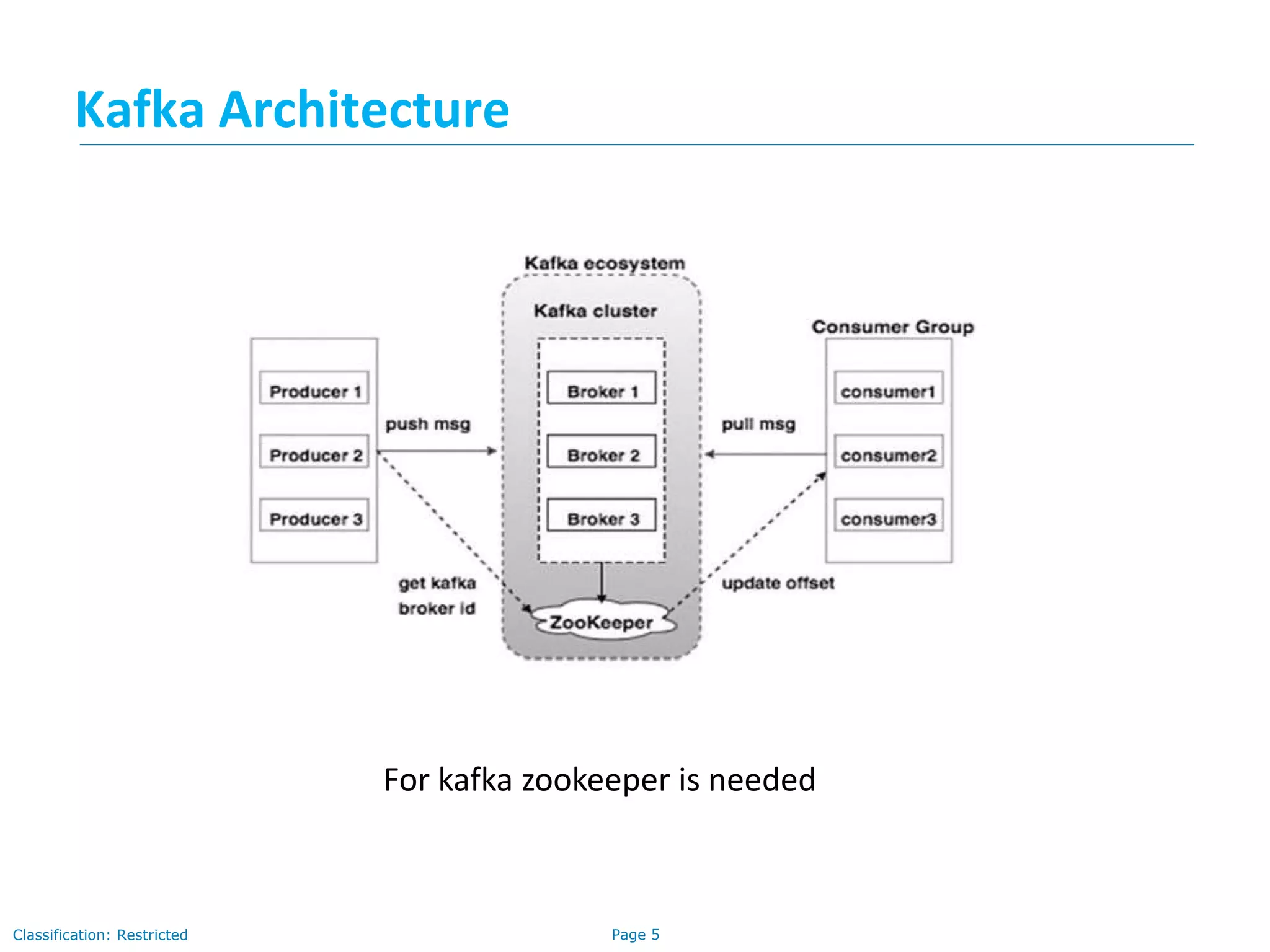
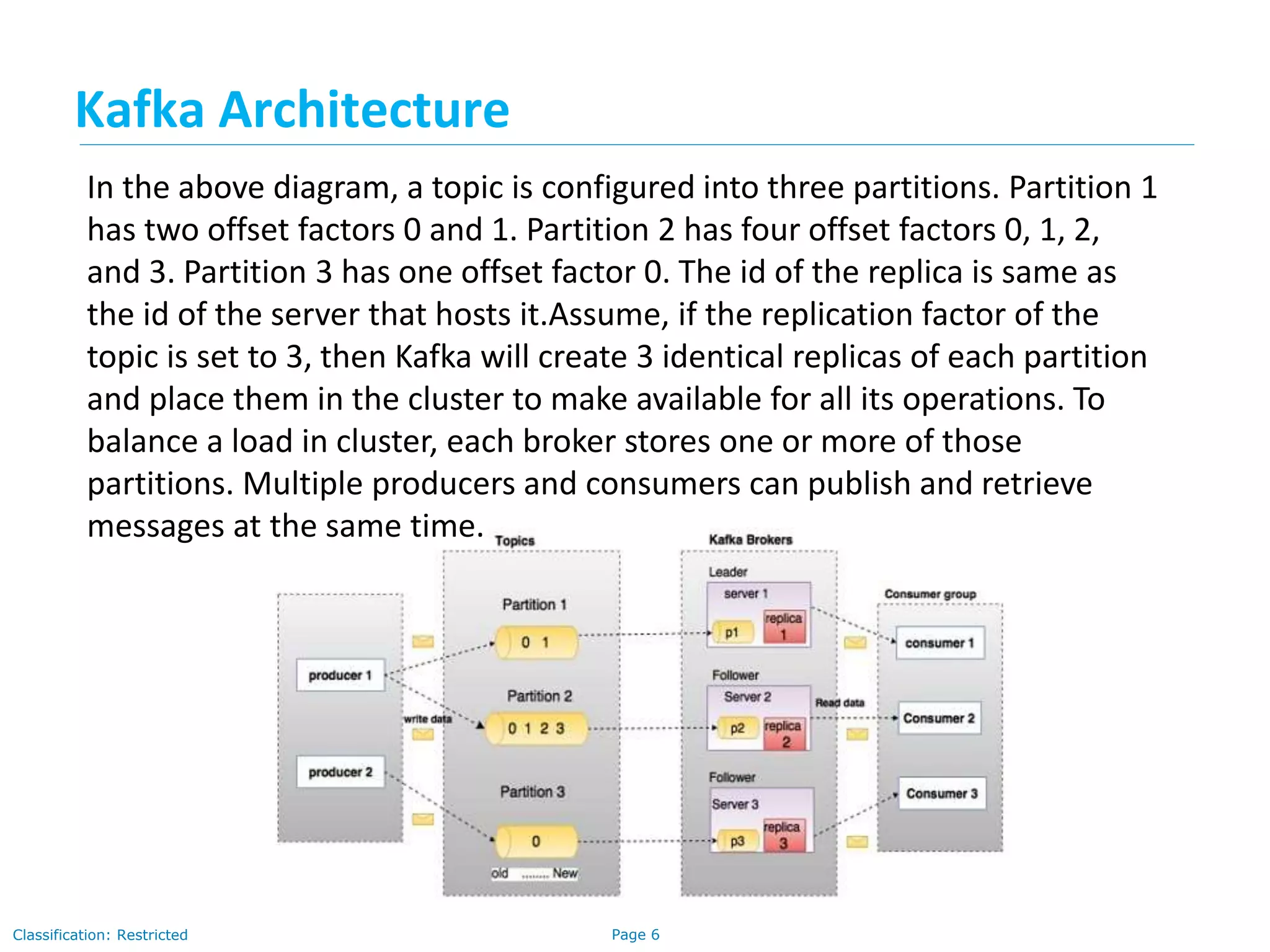
The document provides a comprehensive overview of Apache Kafka, a distributed publish-subscribe messaging system designed for handling high volumes of data with fault tolerance and scalability. It explains Kafka's architecture, components, the role of Zookeeper in coordination, and the messaging workflow between producers and consumers. The document outlines important topics such as message persistence, the partitioning of topics, and the leader election process in Zookeeper, emphasizing how these elements interact to maintain robust data processing in distributed systems.










































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















