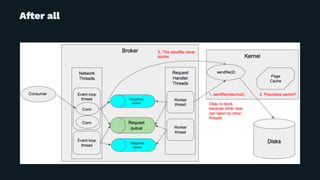
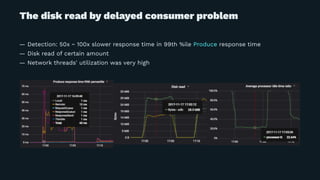
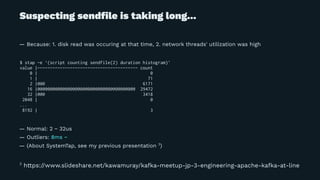
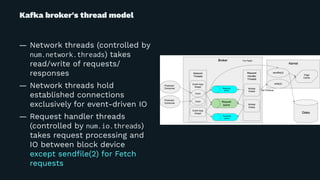
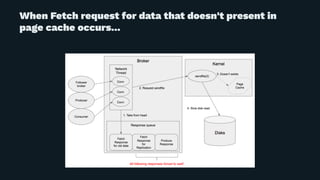
Yuto Kawamura from LINE Corporation presented on their use of Apache Kafka clusters to provide multitenancy for different internal teams. They face challenges in ensuring isolation between client workloads and preventing abusive clients. Their solutions include request quotas to limit client resource usage, slow logs to identify slow requests, and changes to the broker code to pre-warm caches and minimize the impact of disk reads during message fetching. With these approaches, they are able to reliably operate shared Kafka clusters with high throughput and multiple tenants.



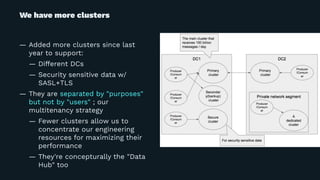






![Slowlog
— Log requests which took longer than certain threshold to process
— Kafka has "request logging" but it leads too many of lines
— Inspired by HBase's
# RequestChannel.scala#updateRequestMetrics
+ slowLogThresholdMap.get(metricNames.head).filter(_ >= 0).filter { v =>
+ val targetTime = requestId match {
+ case ApiKeys.FETCH.id => totalTime - apiRemoteTime
+ case _ => totalTime
+ }
+
+ targetTime >= v
+ }.foreach { _ =>
+ requestLogger.warn("Slow response:%s from connection %s;totalTime:%d...
+ .format(requestDesc(true), connectionId, totalTime, requestQueueTime...
+ }
[2016-12-26 16:04:20,135] WARN Slow response:Name: FetchRequest;
Version: 2 ... ;totalTime:1817;localTime: ...](https://image.slidesharecdn.com/kafka-meetup-2018-04-180424145909/85/Multitenancy-Kafka-clusters-for-everyone-at-LINE-12-320.jpg)
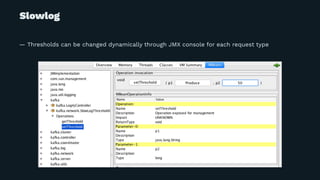






![... and more to minimize impact of increased syscall...
# Log.scala#read
@@ -585,6 +586,17 @@ class Log(@volatile var dir: File,
if(fetchInfo == null) {
entry = segments.higherEntry(entry.getKey)
} else {
+ // For last entries we assume that it is hot enough to still have all data in page cache.
+ // Most of fetch requests are fetching from the tail of the log, so this optimization
+ // should save call of readahead() + mmap() + mincore() * N significantly.
+ if (!isLastEntry && fetchInfo.records.isInstanceOf[FileRecords]) {
+ try {
+ info("Prepare Read for " + fetchInfo.records.asInstanceOf[FileRecords].file().getPath)
+ fetchInfo.records.asInstanceOf[FileRecords].prepareForRead()
+ } catch {
+ case e: Throwable => warn("failed to prepare cache for read", e)
+ }
+ }
return fetchInfo
}
— Perform cache warmup only if the read segment IS NOT the latest
— => can save unnecessary syscalls for 99% of Fetch requests](https://image.slidesharecdn.com/kafka-meetup-2018-04-180424145909/85/Multitenancy-Kafka-clusters-for-everyone-at-LINE-27-320.jpg)