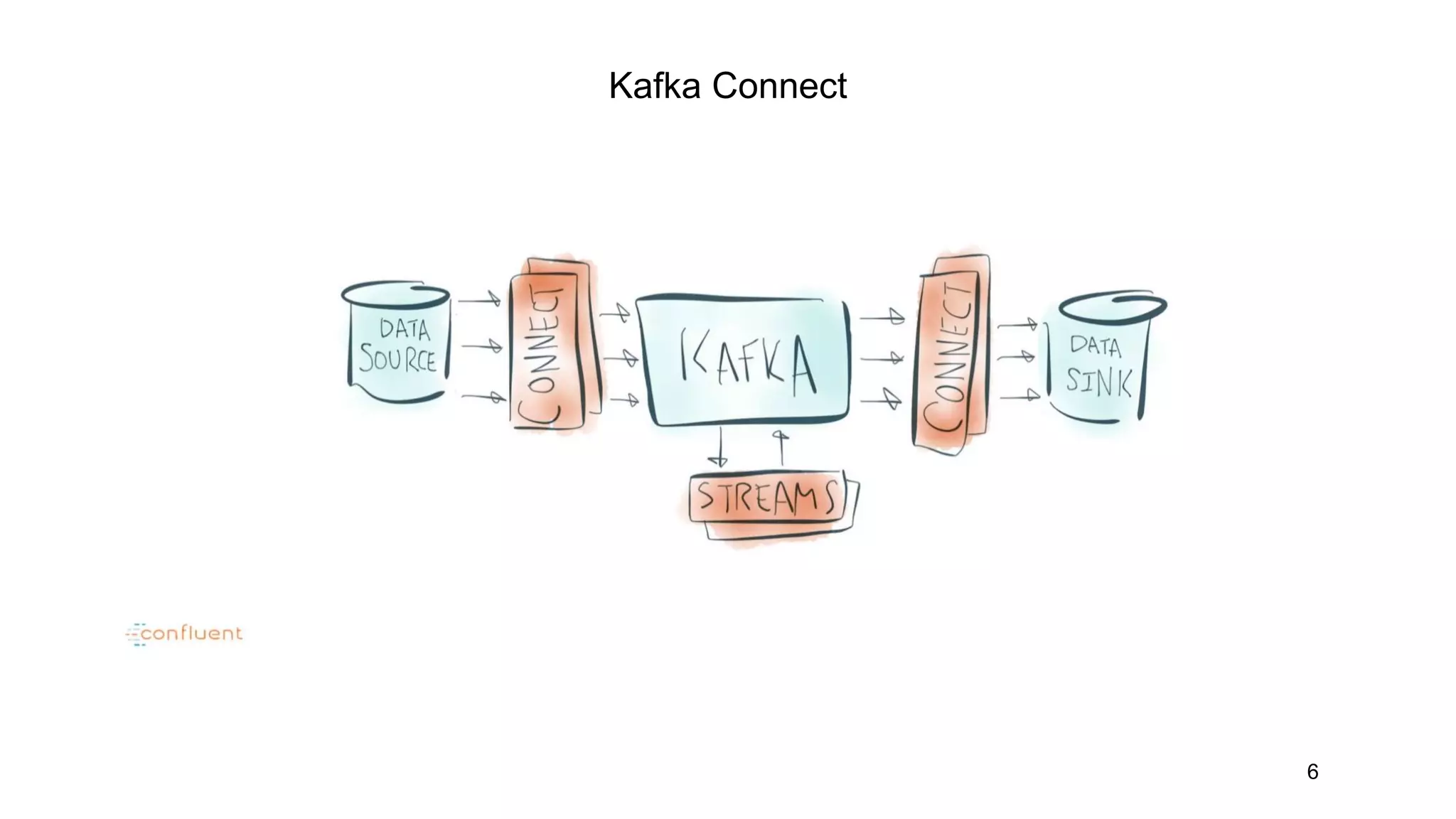
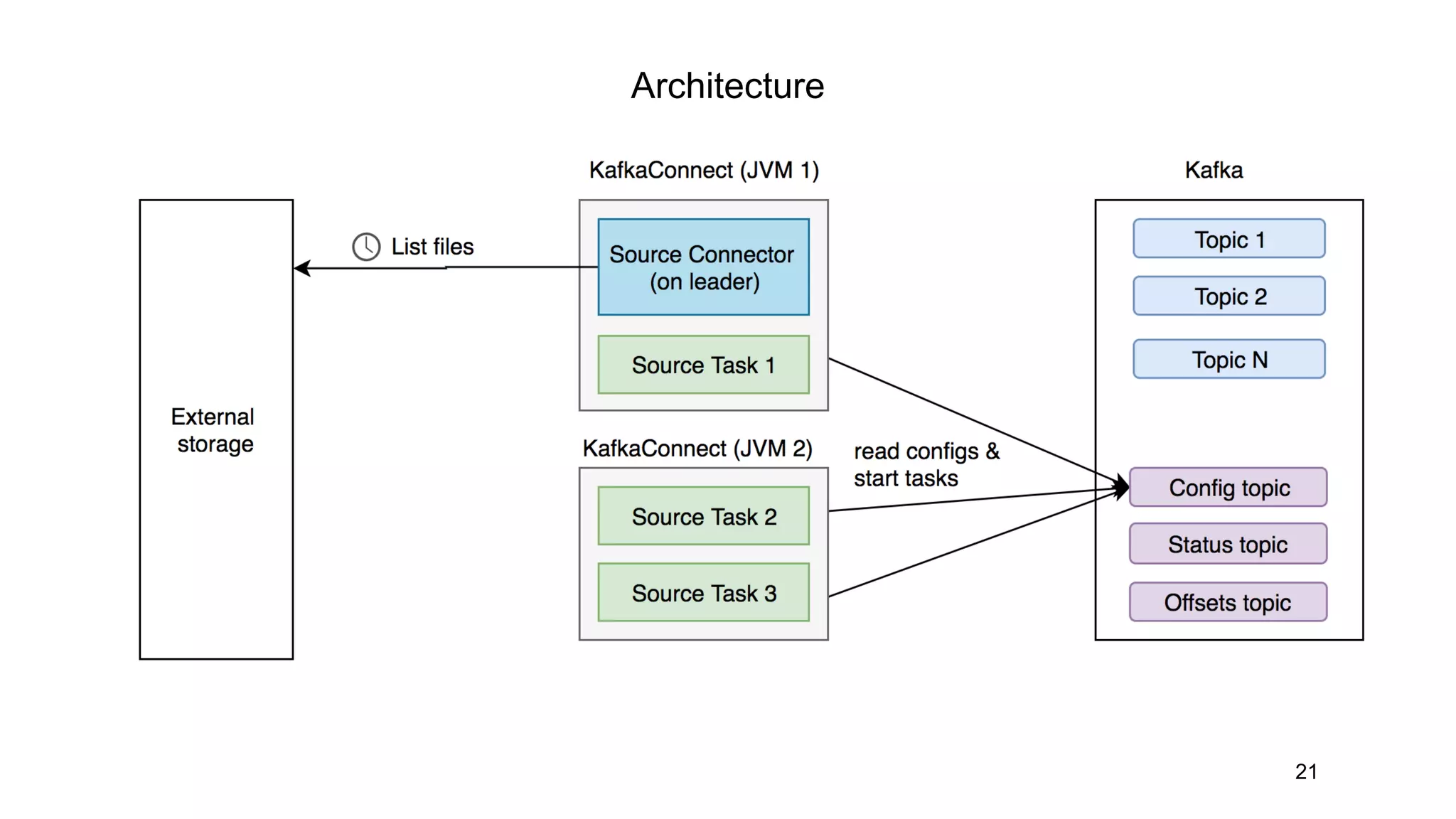
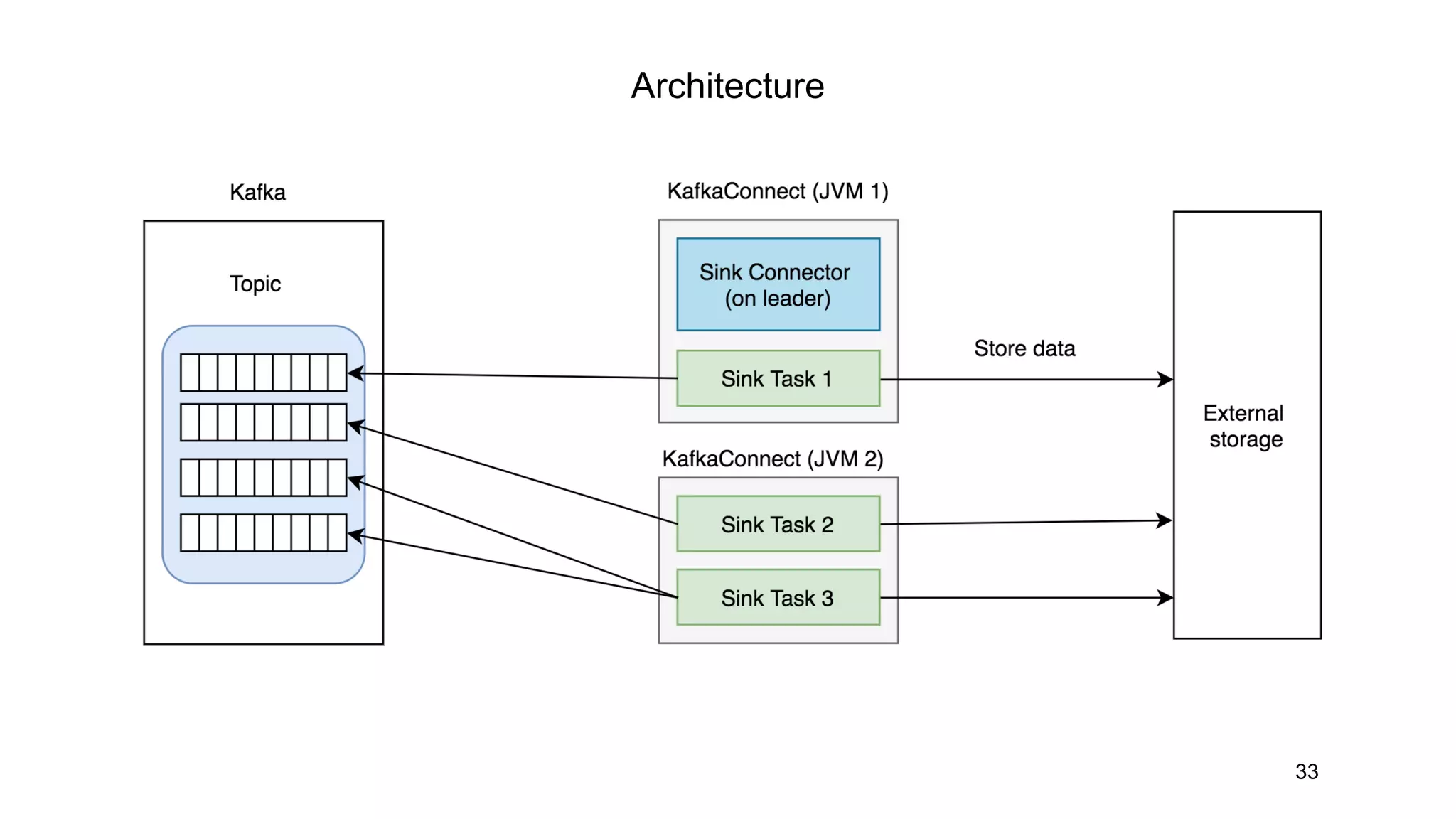
Kafka Connect allows data ingestion into and out of Kafka topics from external systems. It uses connectors that define how to read/write data from sources like files or databases and map them to Kafka topics. Connectors contain a SourceConnector that runs on the leader node and distributes work, and SourceTasks that do the actual data ingestion work. Sink connectors work similarly to ingest data from Kafka topics to external systems. While Kafka Connect provides a simple way to integrate systems with Kafka, it lacks some capabilities like exactly once delivery and backpressure control for ingestion speed.
12
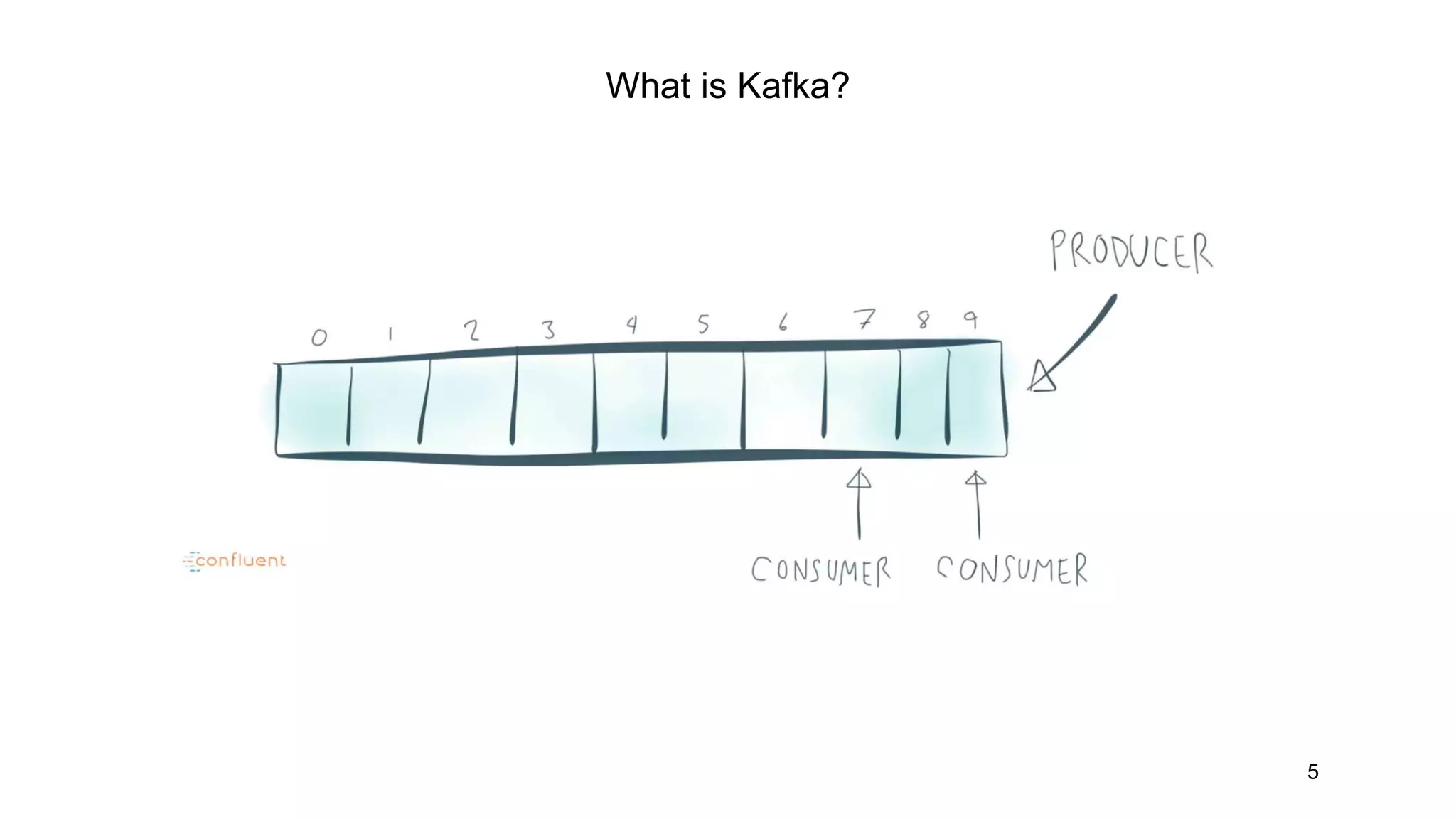
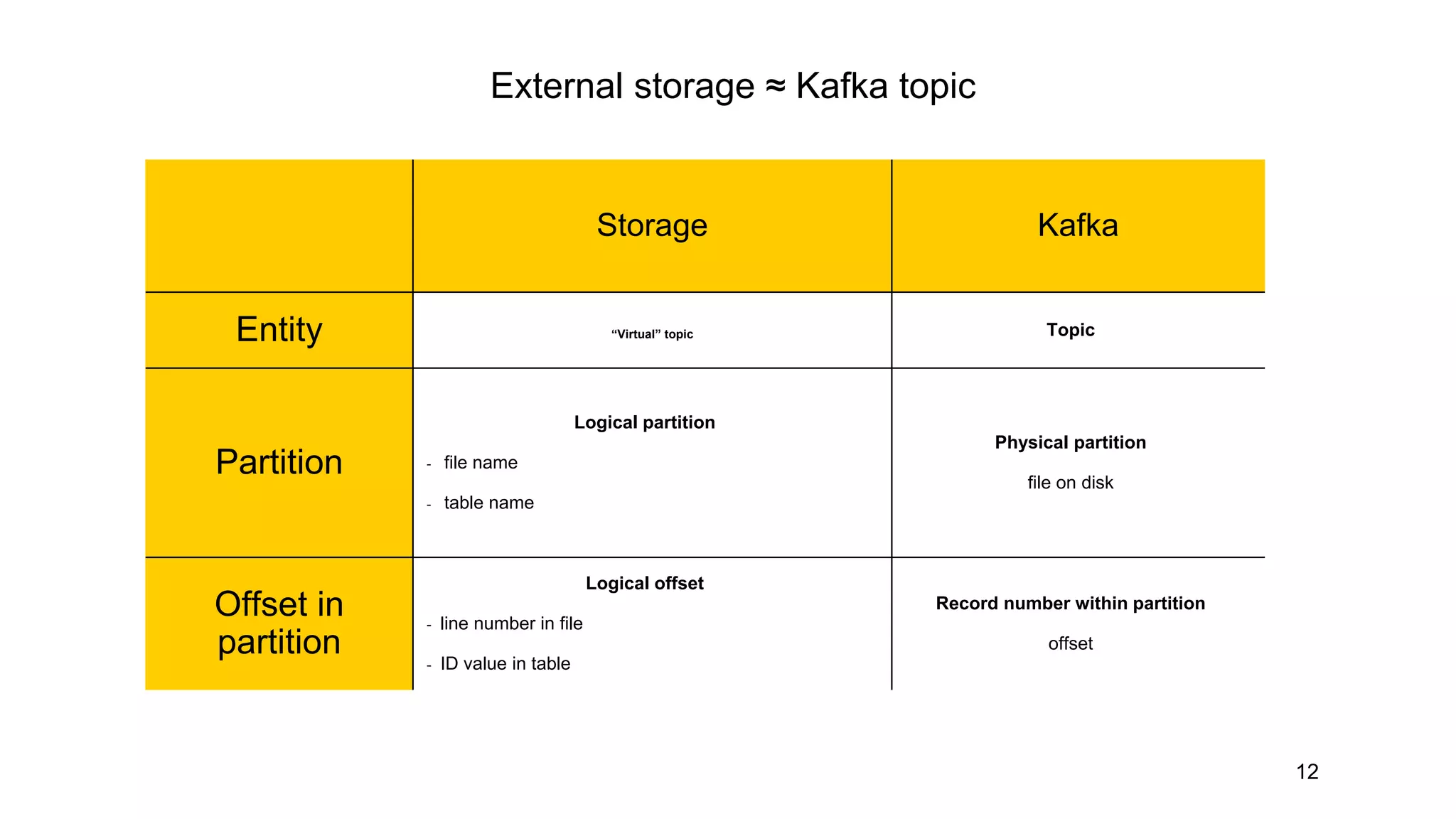
Storage Kafka
Entity “Virtual”topic Topic
Partition
Logical partition
- file name
- table name
Physical partition
file on disk
Offset in
partition
Logical offset
- line number in file
- ID value in table
Record number within partition
offset
External storage ≈ Kafka topic
13.
Components
13
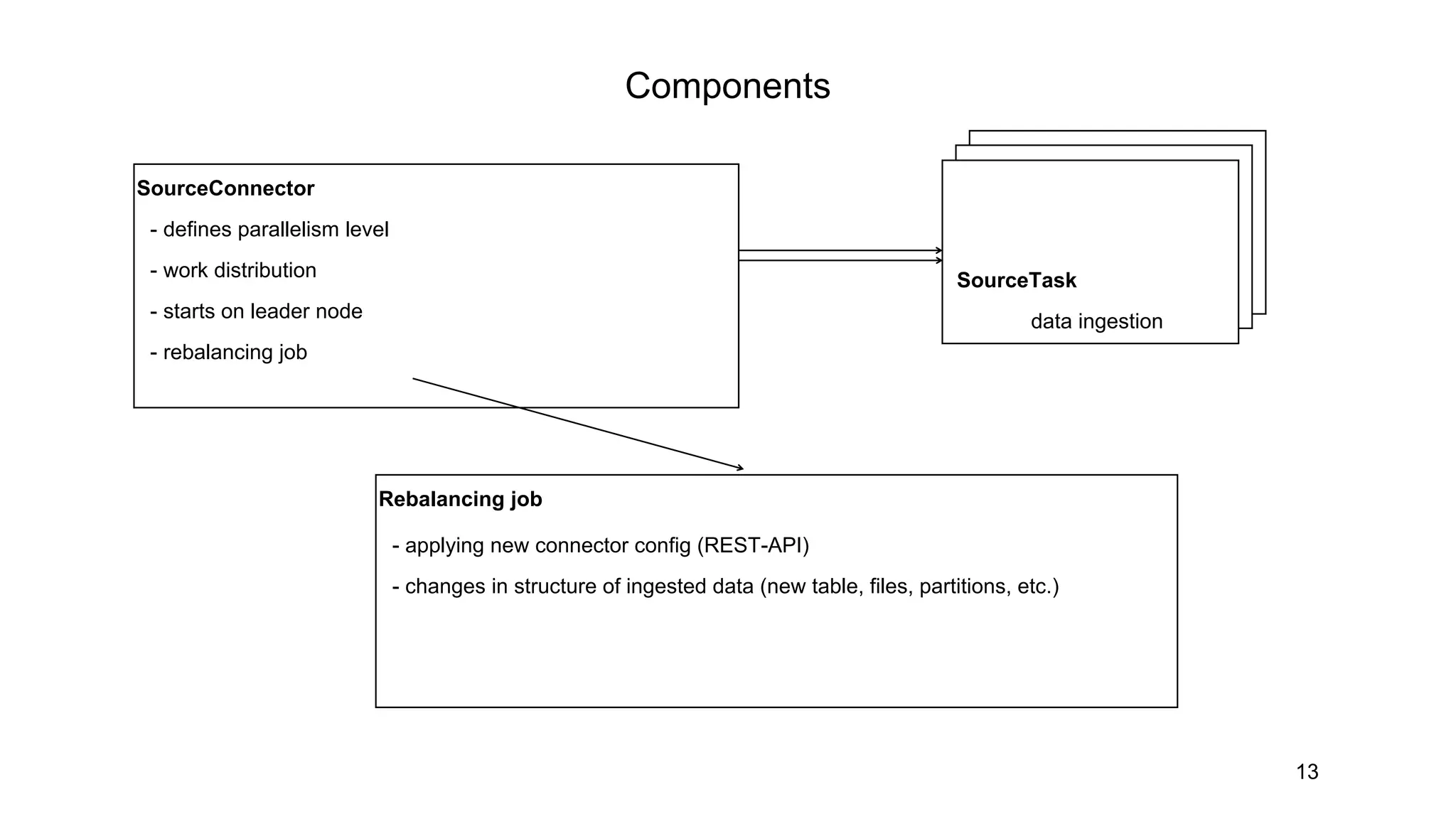
SourceConnector
- defines parallelismlevel
- work distribution
- starts on leader node
- rebalancing job
Rebalancing job
- applying new connector config (REST-API)
- changes in structure of ingested data (new table, files, partitions, etc.)
SourceTask
data ingestion
Storing in put()
36
〉put()should be quick (there is an internal timeout)
〉A limited number of records are passed in put()
〉Automatic offset management (consumer)
37.
Storing in flush()
37
〉put()stores in temp file / memory
〉flush() uploads optimal data amount in storage
〉Manual offset management (uploading index-files)
Global rebalancing
43
〉JVM withKafkaConnect can host multiple connectors
〉Rebalancing one of them initiates the rebalancing of the rest
Solution: run 1 connector per 1 JVM
44.
Writing offsets withoutsending source record
44
〉Ingesting file without records (e.g. it is empty)
Solutions:
1) send marker SourceRecord with offset
2) get offsetStorageWriter by reflection and write offset directly
45.
Controlling ingestion speed(backpressure)
45
〉Source
- no control of ingestion speed for writes to Kafka
- solution: sleep() in poll() + producer tuning
〉Sink
- no control of speed of storing data in external storage
- solution: sleep() + throw new RetryableException in put()
46.
Exactly once delivery
46
〉notsupported
〉Source
- data and offsets are stored separately => duplicates are possible
- there is technical capability, but it has not been implemented
Solution:
- extra deduplication process (for instance, KafkaStreams)
- compacted data topic
〉Sink
- idempotence: loading index-file with data files + consistent file naming









































































![Building streaming data applications using Kafka*[Connect + Core + Streams] b...](https://cdn.slidesharecdn.com/ss_thumbnails/buildingstreamingdataapplicationsusingapachekafka-171011211455-thumbnail.jpg?width=640&height=640&fit=bounds)






























