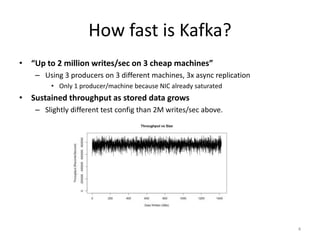
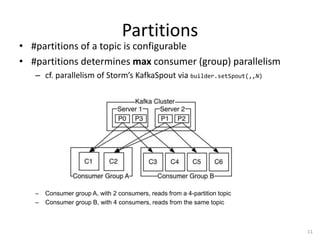
Kafka is a fast, scalable, and durable distributed commit log service that can handle millions of messages per second. It is used by many large companies as a messaging backbone and for real-time data processing. Kafka topics are partitioned and replicated for high throughput and fault tolerance. Producers write messages to topics that are consumed by consumer groups who track their progress using offsets.