Downloaded 269 times































![IMPLEMENTATION (RUBY)
• A Model is ActiveRecord (Ruby on Rails ORM)
• ActiveRecord can persist itself to the database
• ActiveRecord::Callbacks:
– after_commit on [:create, :update] {
index_document }
– after_commit on [:destroy] { delete_document }
– after_create…
– after_save …
– after_destroy…
• Rake tasks to drop/recreate index, reindex
documents
• Zero-downtime reindexing using aliases
• Ruby/Rails client:
https://github.com/elastic/elasticsearch-rails](https://image.slidesharecdn.com/elasticsearch-150817175333-lva1-app6892/75/Elasticsearch-Logstash-Kibana-Cool-search-analytics-data-mining-and-more-42-2048.jpg)



![#4. [NDA]
http://cdn.4glaza.ru/images/products/large/0/bresser-junior-loupe-2x-4x-dop6.jpg](https://image.slidesharecdn.com/elasticsearch-150817175333-lva1-app6892/75/Elasticsearch-Logstash-Kibana-Cool-search-analytics-data-mining-and-more-47-2048.jpg)




































The document provides an overview of Elasticsearch, including its architecture, deployment, and ecosystem. It features a demo, real-life case studies, and details on the Elasticsearch query API and relevant concepts like filtering, sharding, and relevance scoring. Additionally, it discusses Elasticsearch integration with various programming languages and tools, illustrating its capabilities in full-text search and data management.
Introduction to the presentation and agenda outlining topics such as Elastic, demo time, architecture, case studies, and Elasticsearch ecosystem.
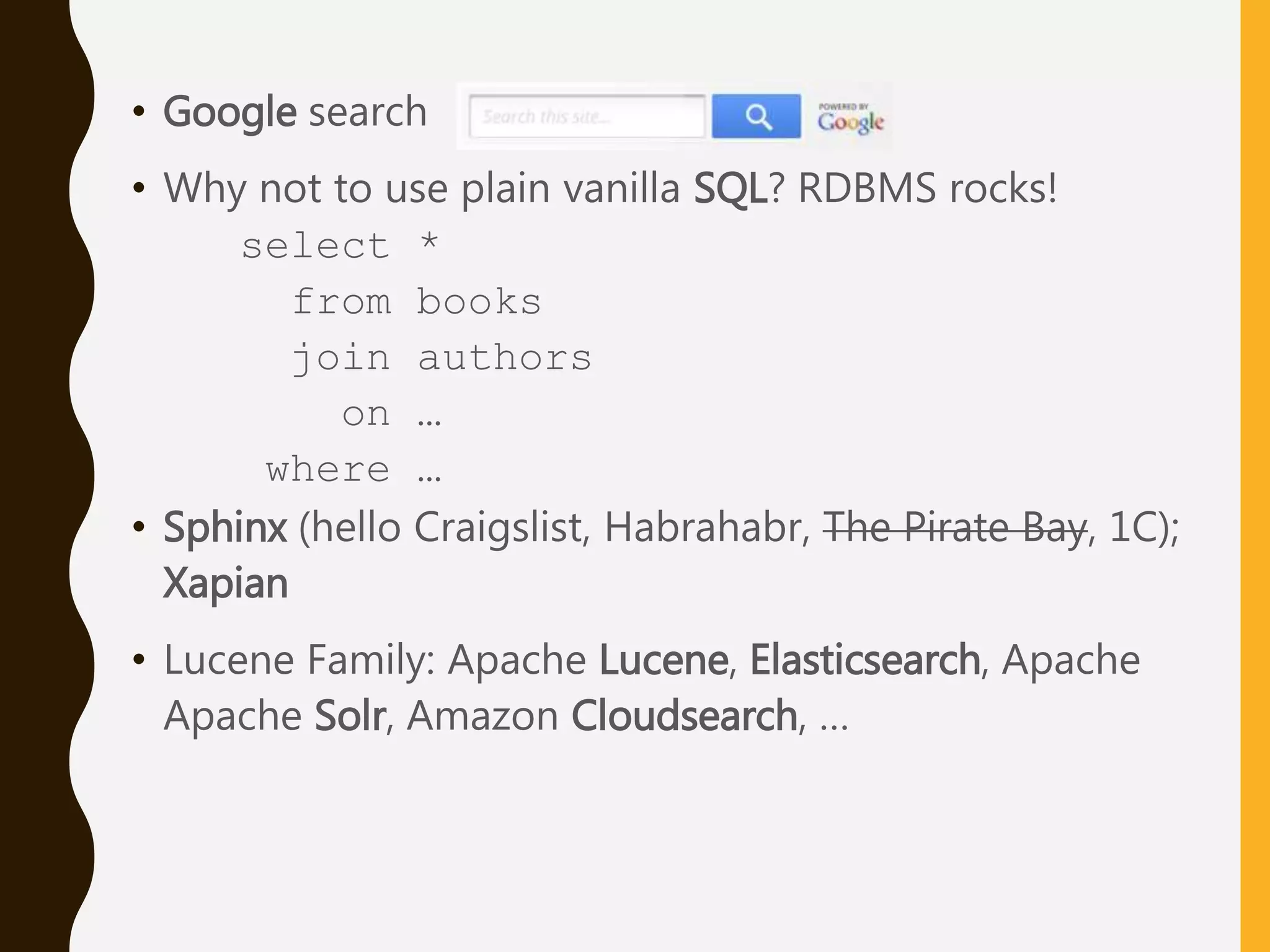
Discusses the need for searchability on websites, compares SQL databases with search engines like Sphinx and Lucene.
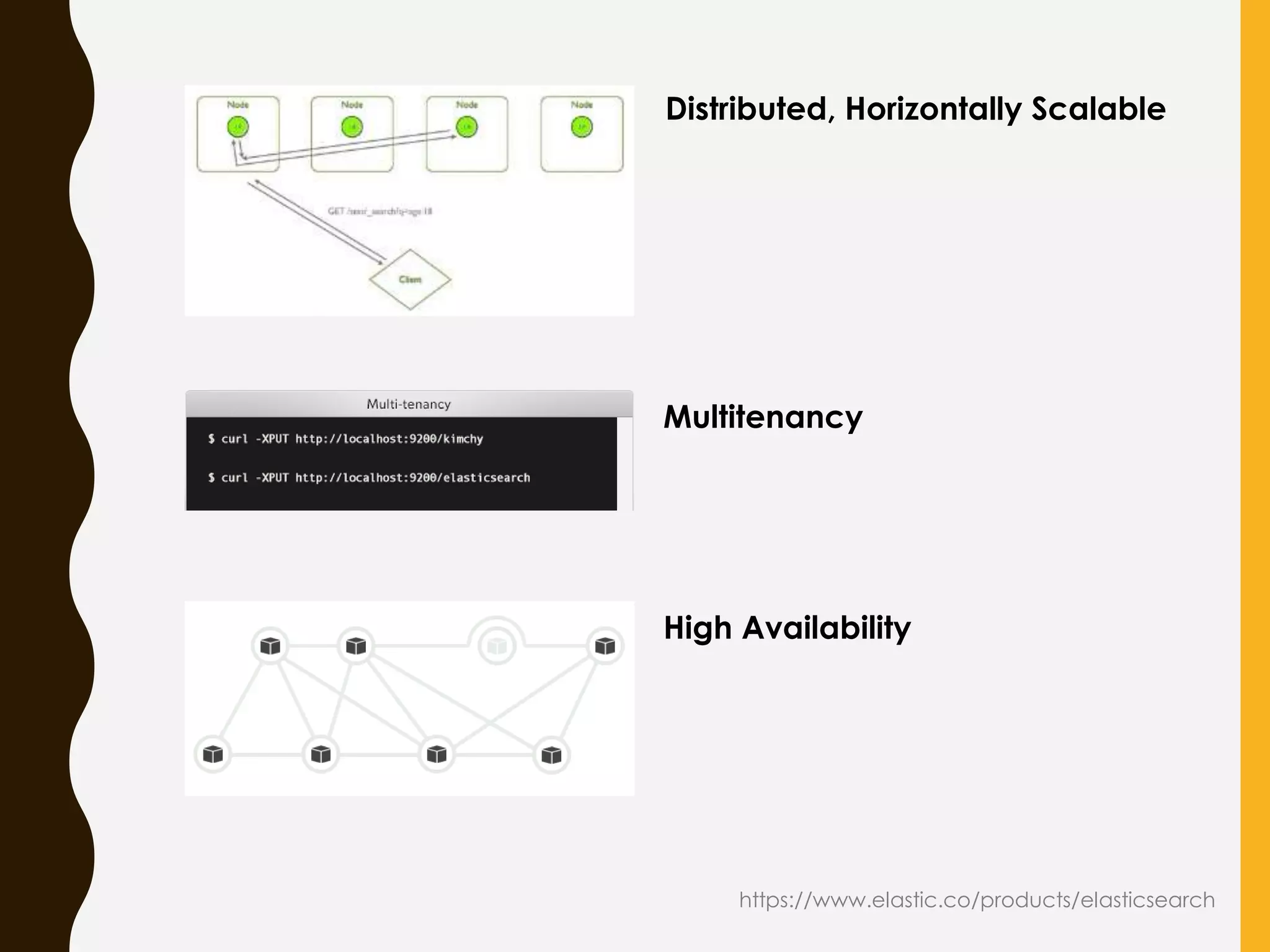
Introduction to Elasticsearch’s features including near real-time data, multilingual search, high availability, and open-source attributes.
Overview of Elasticsearch's evolution, company background, and significant milestones since its inception.
Preparation for the demo showcasing how to install and configure Elasticsearch, detailing prerequisites and installation methods.
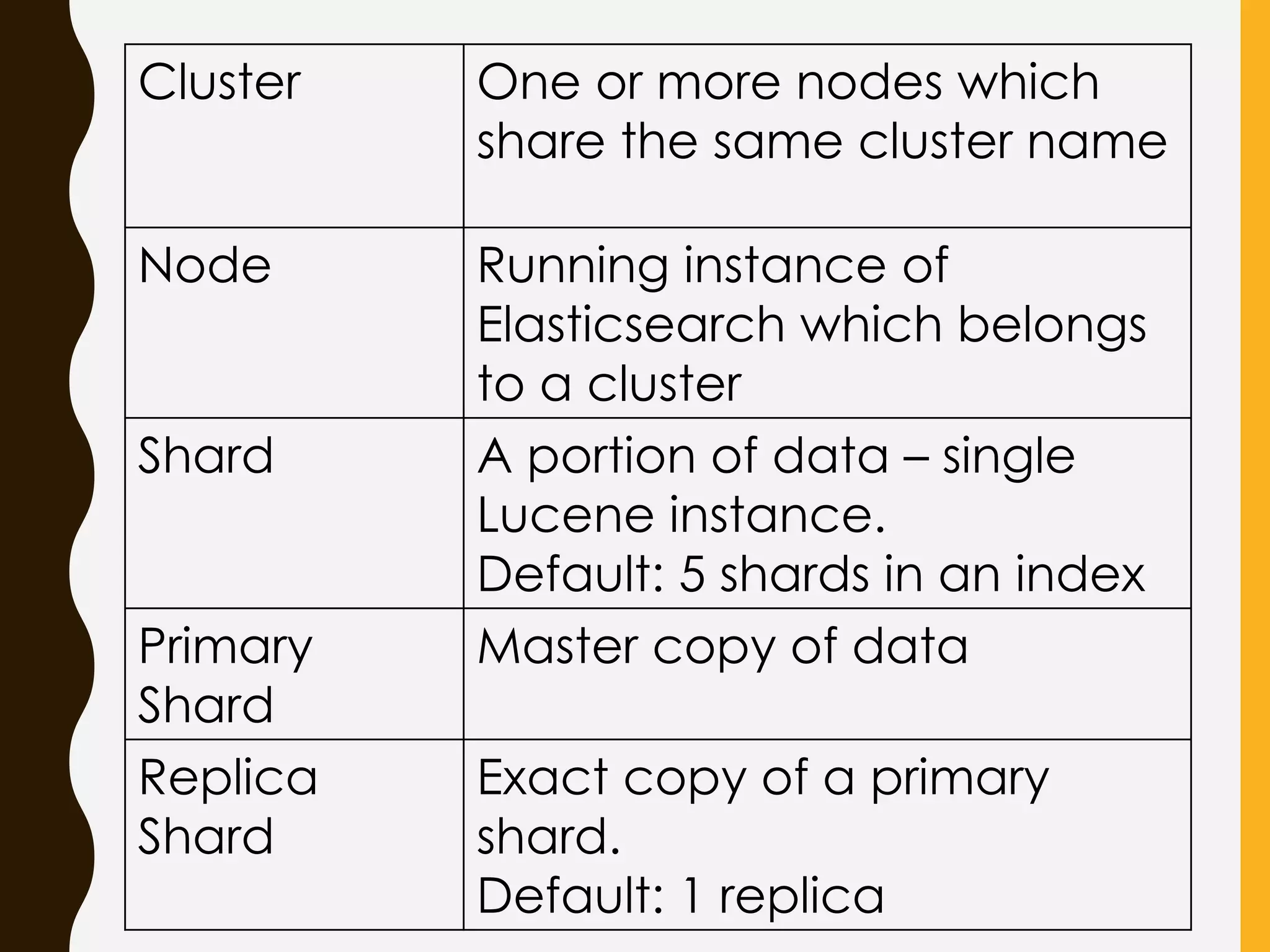
Important Elasticsearch terminology mapping to database constructs, such as Index, Type, Document, and Mapping.
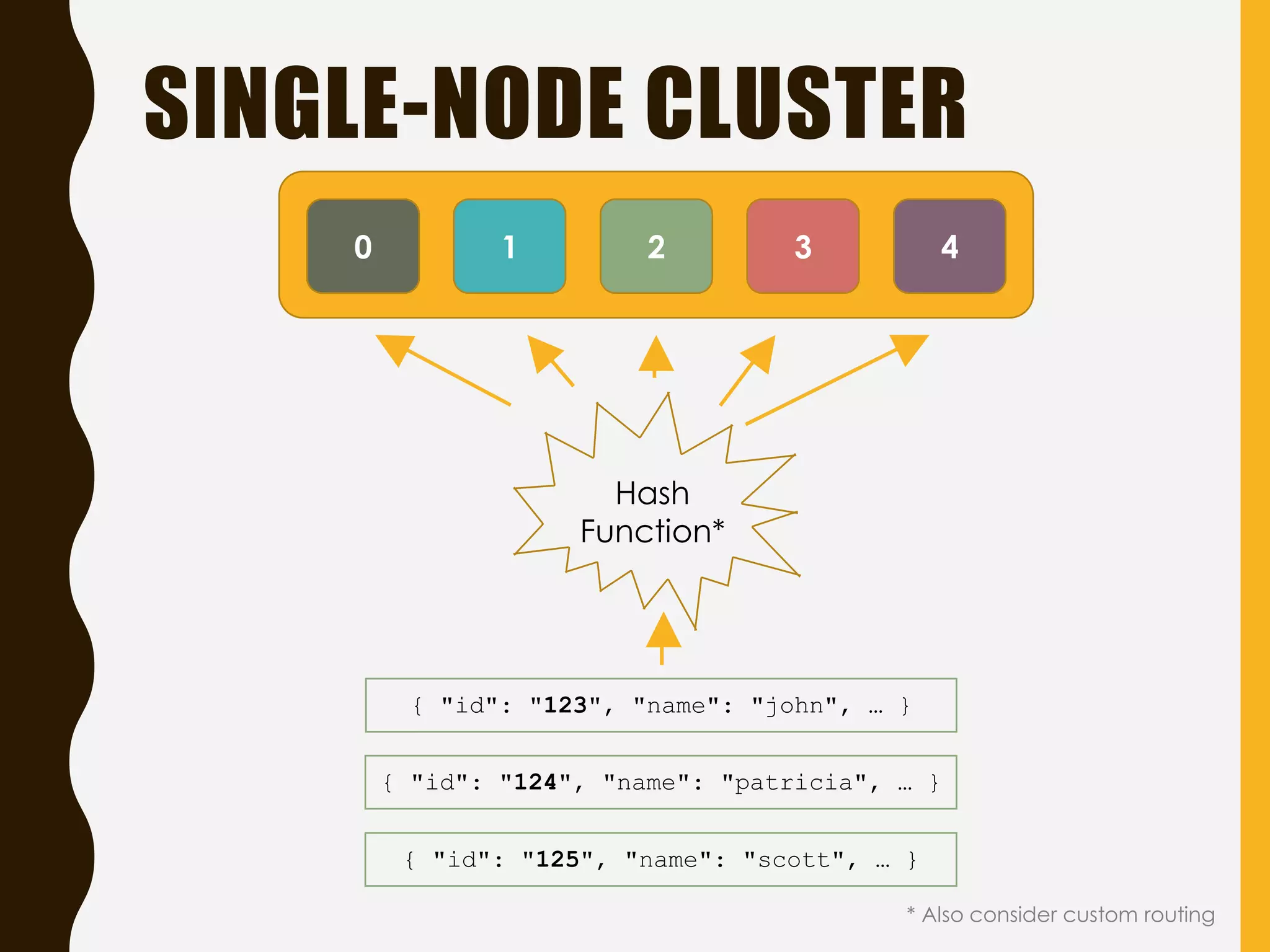
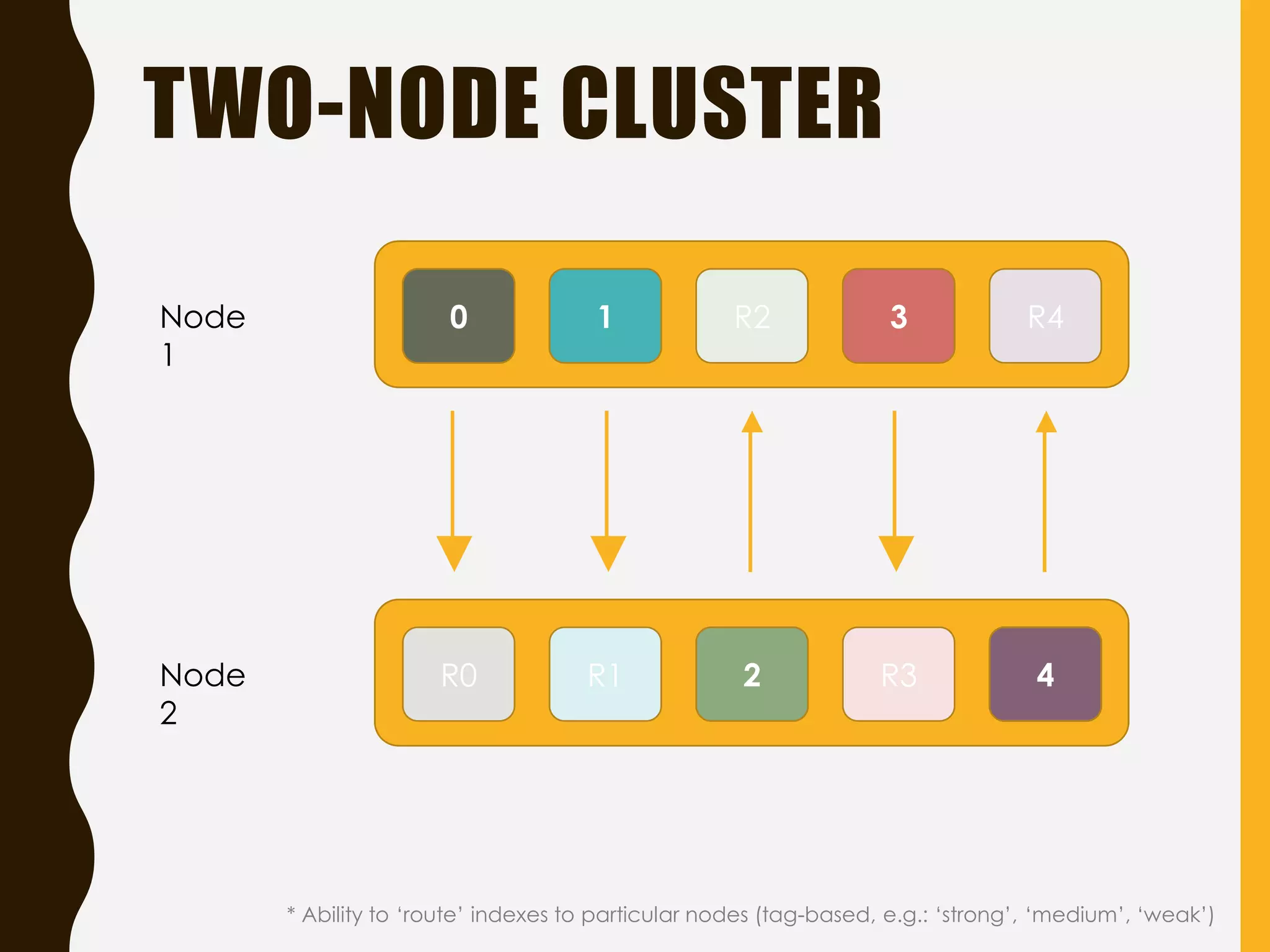
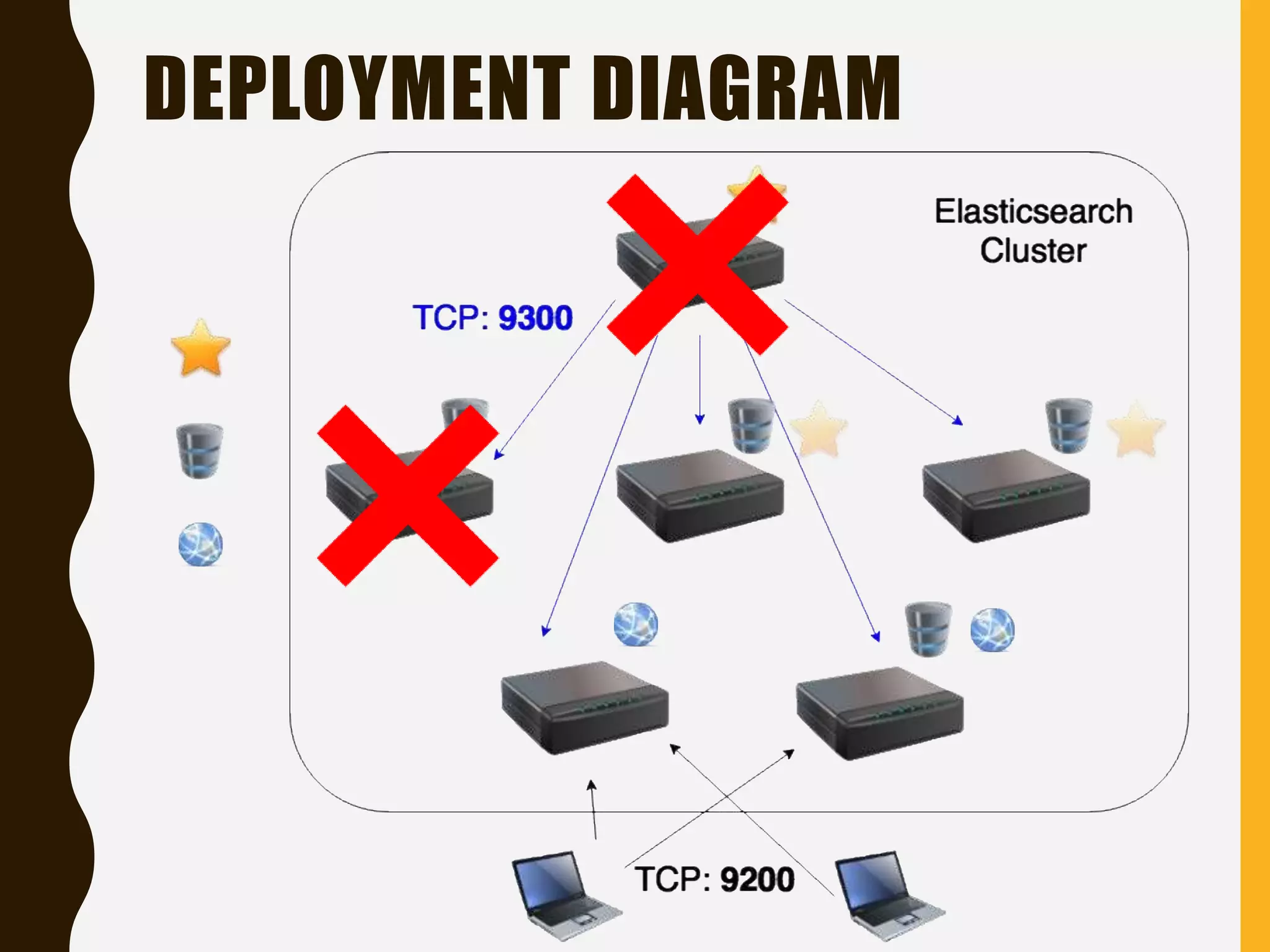
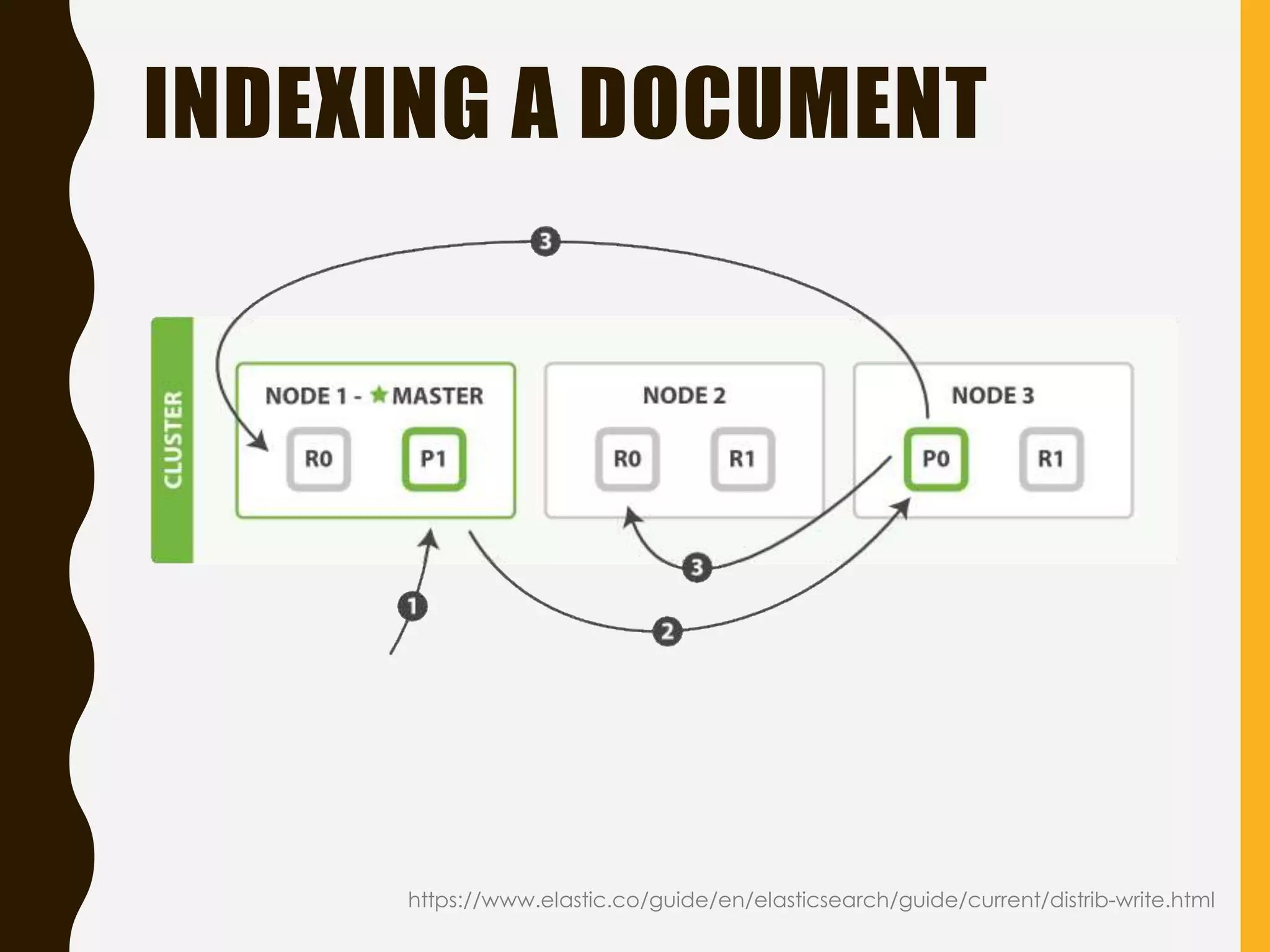
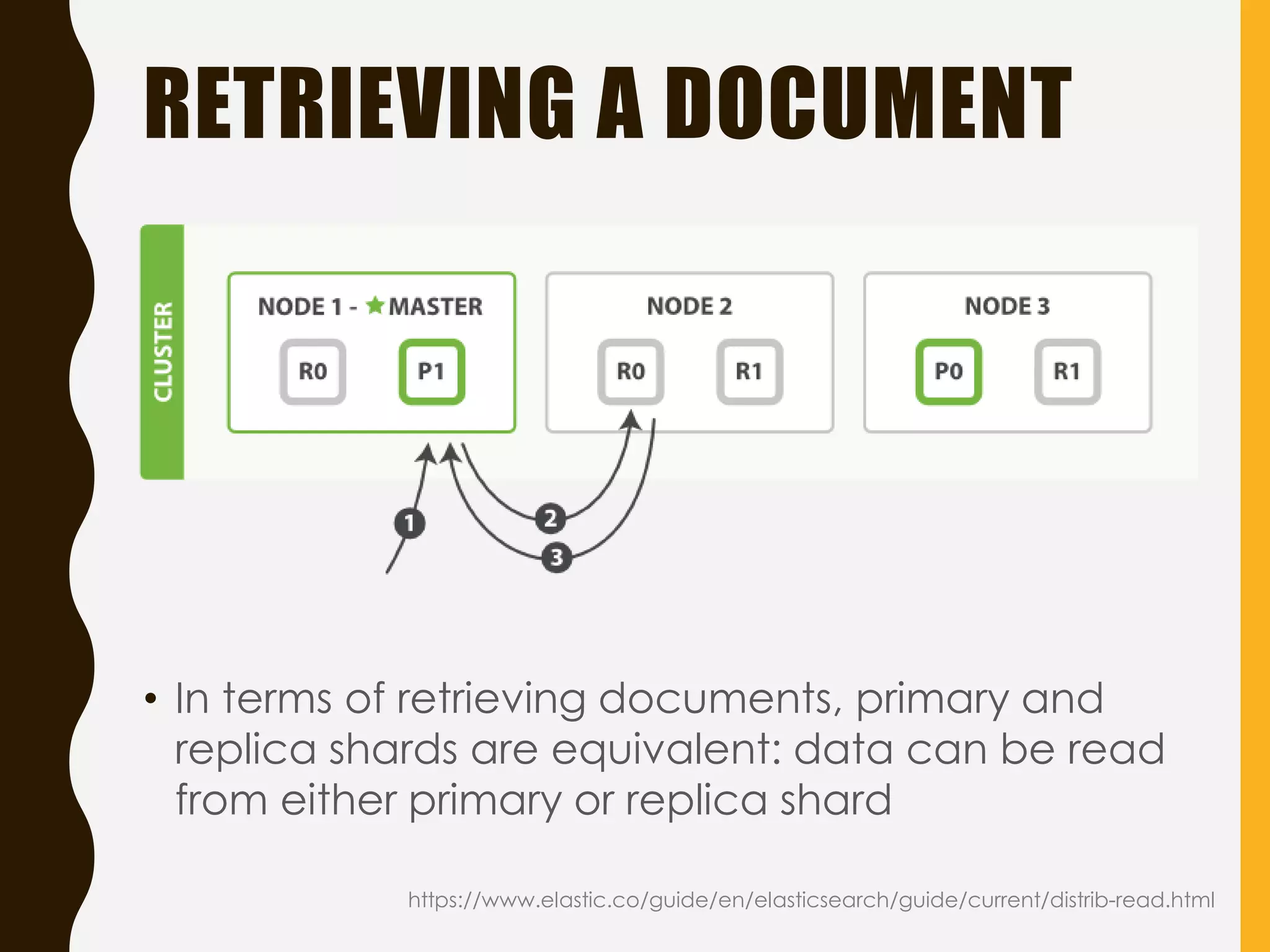
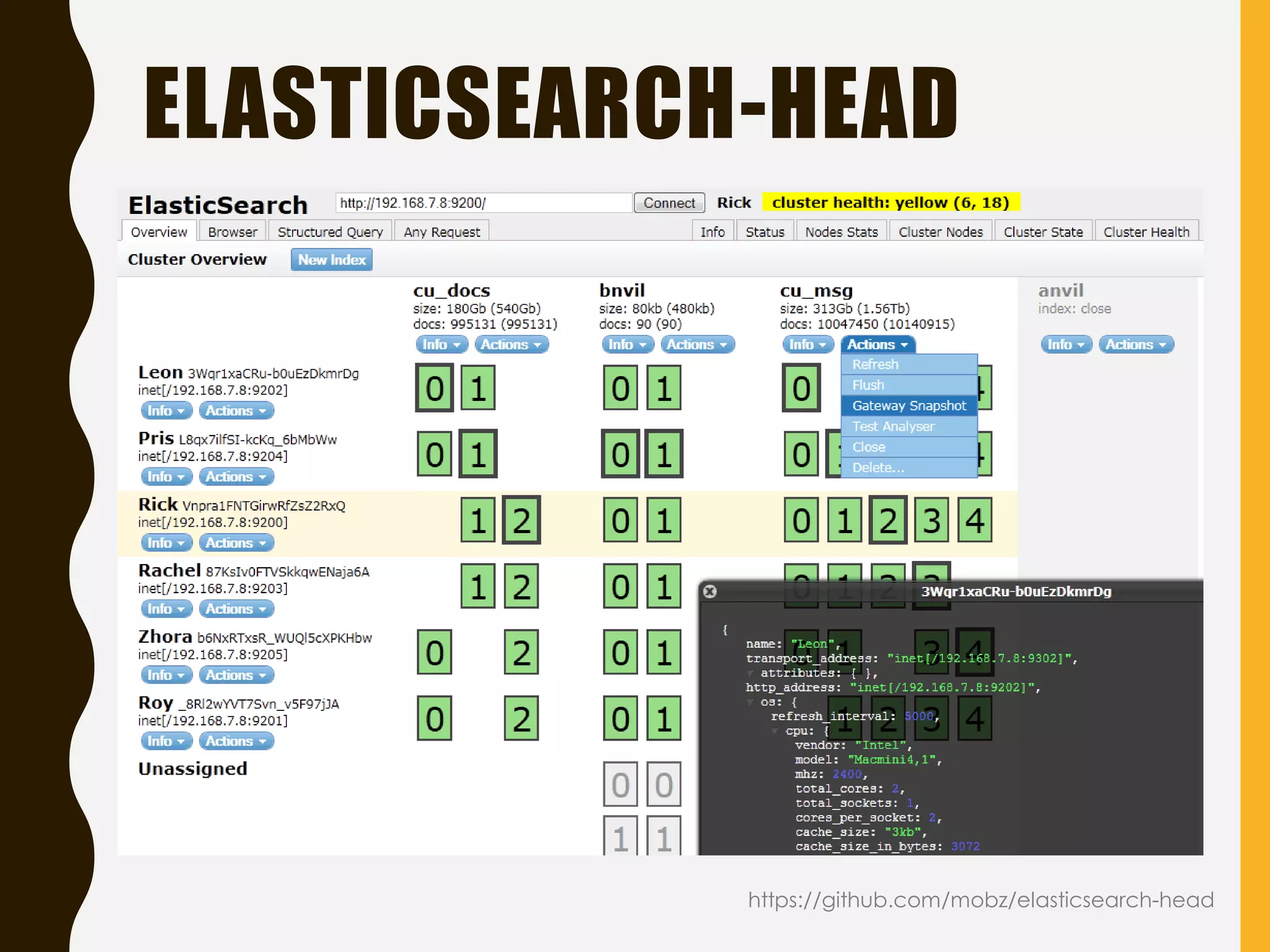
Explains Elasticsearch architecture, node types, shard management, and deployment strategies to ensure scalability and resilience.
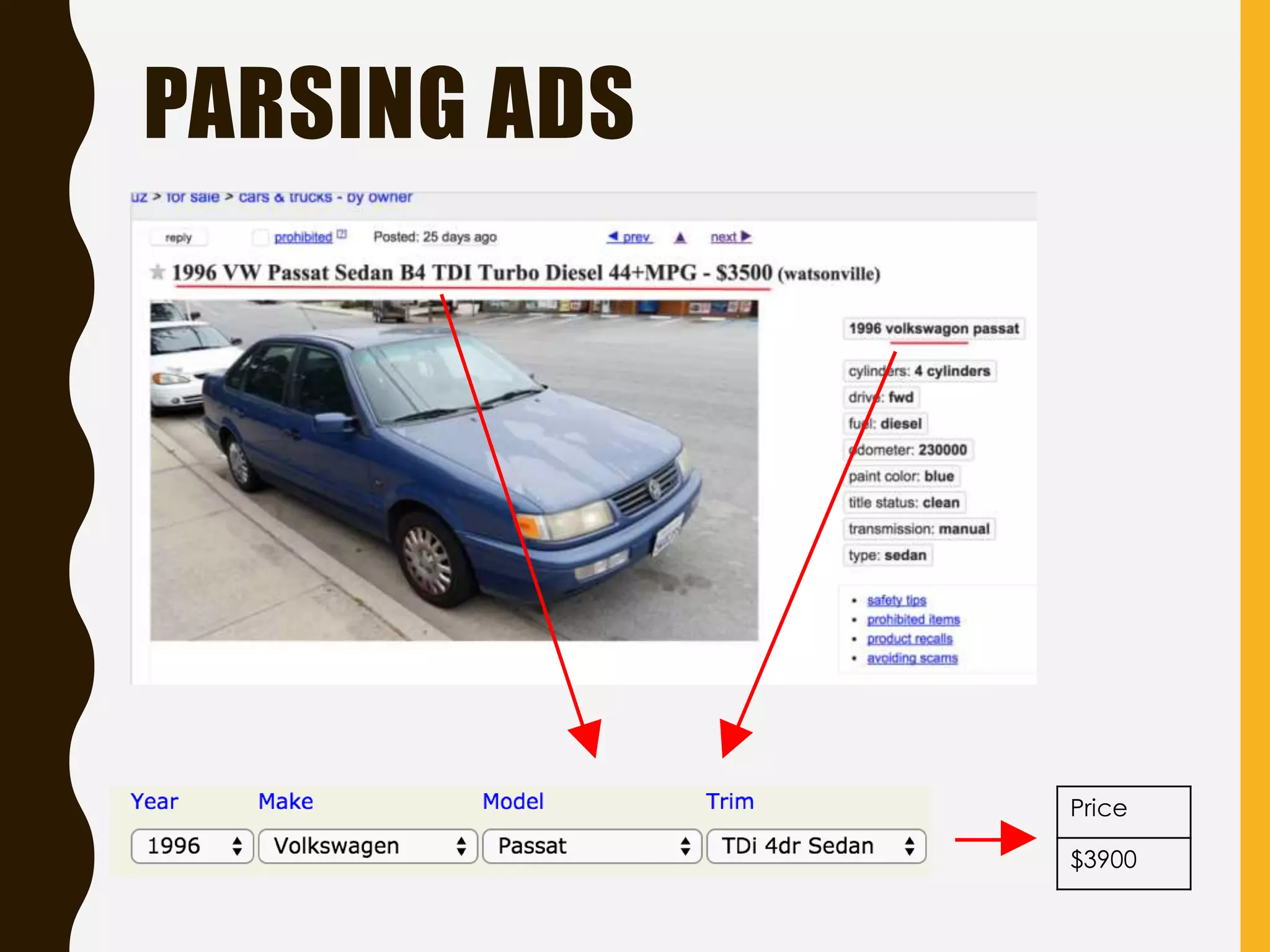
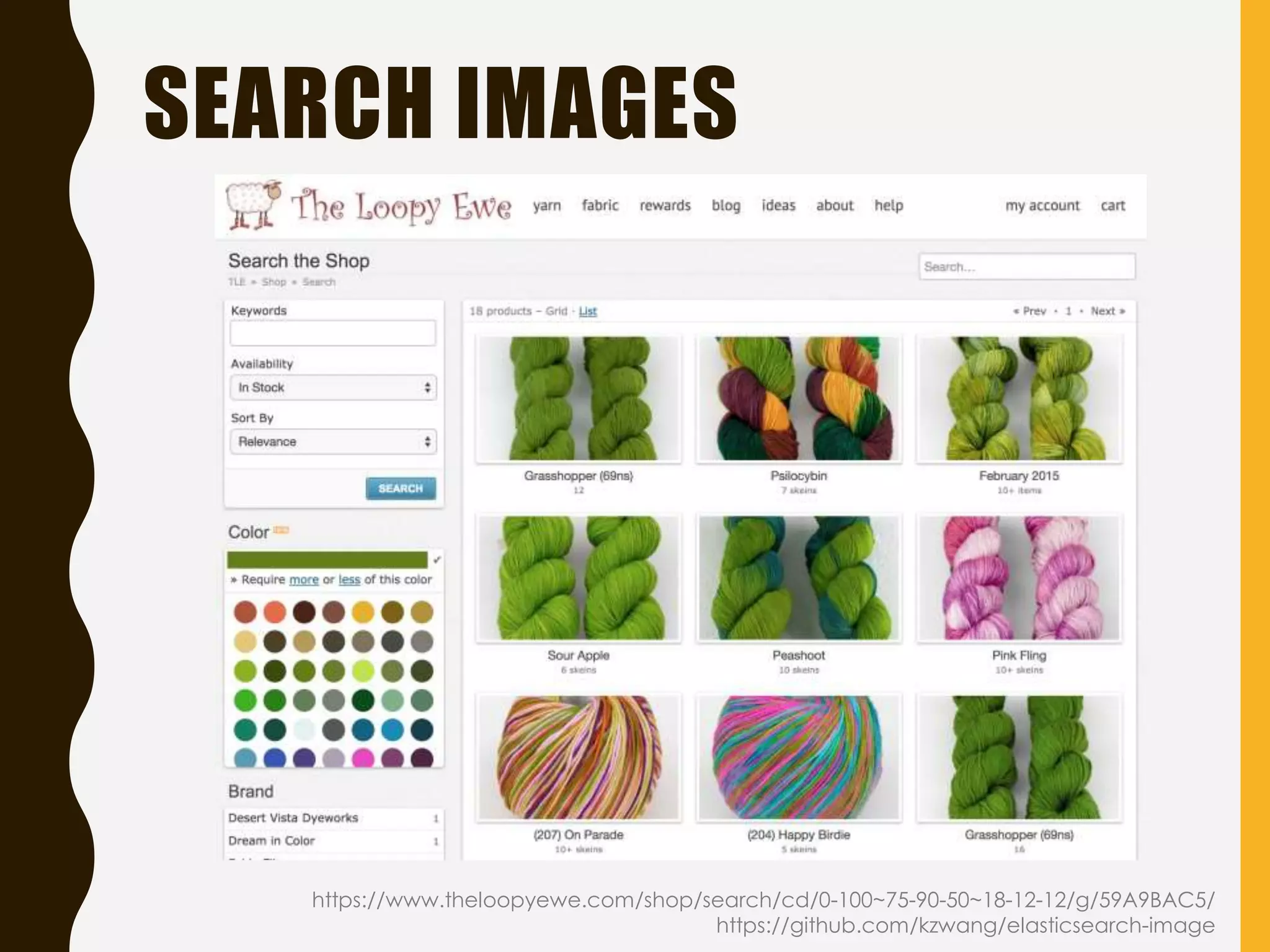
Focuses on four case studies demonstrating Elasticsearch's applications, including social marketing, job sites, and car trading.
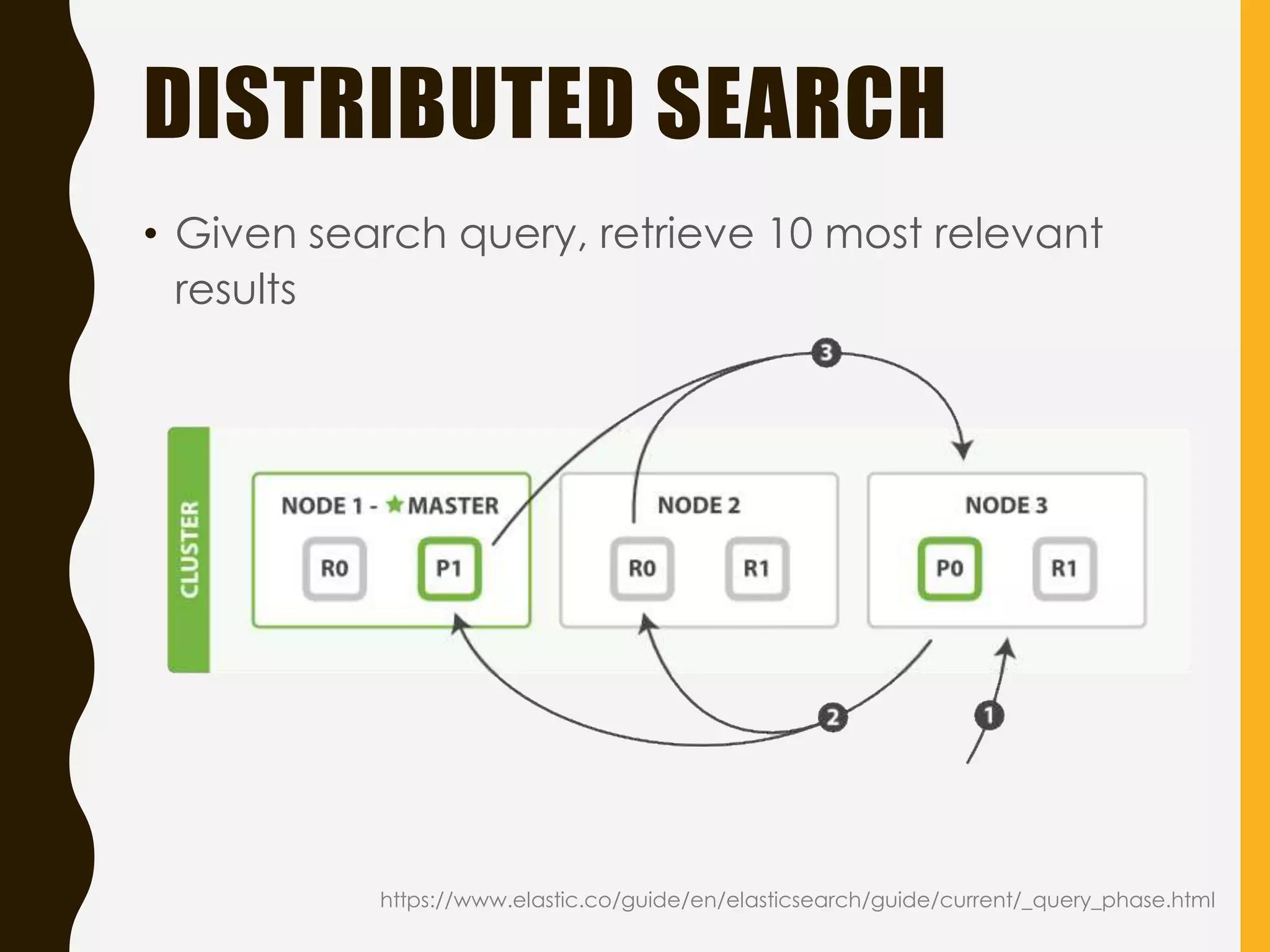
Discusses the Query API with filters vs. queries, relevance scoring, and additional features like autocomplete and document indexing.
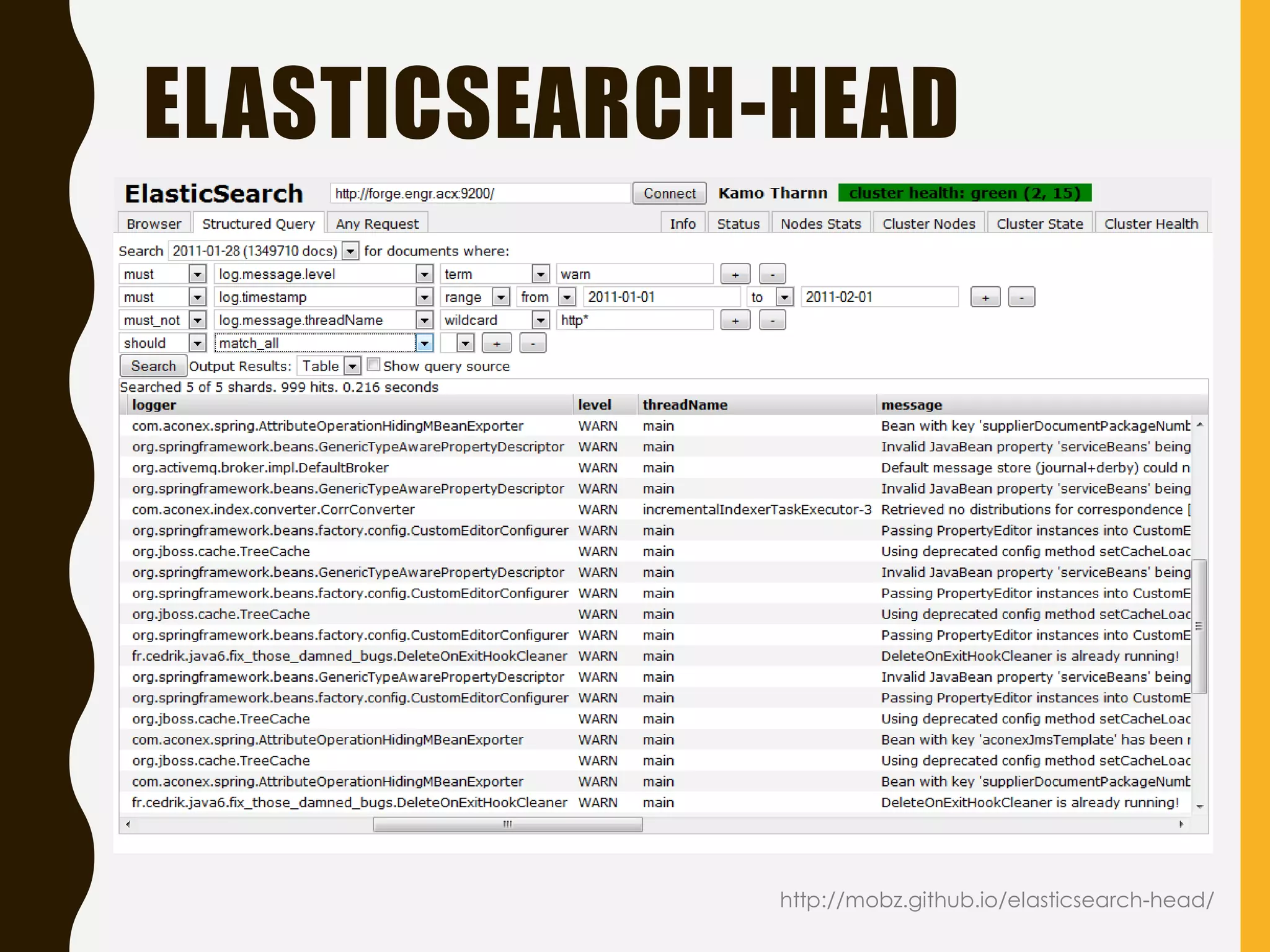
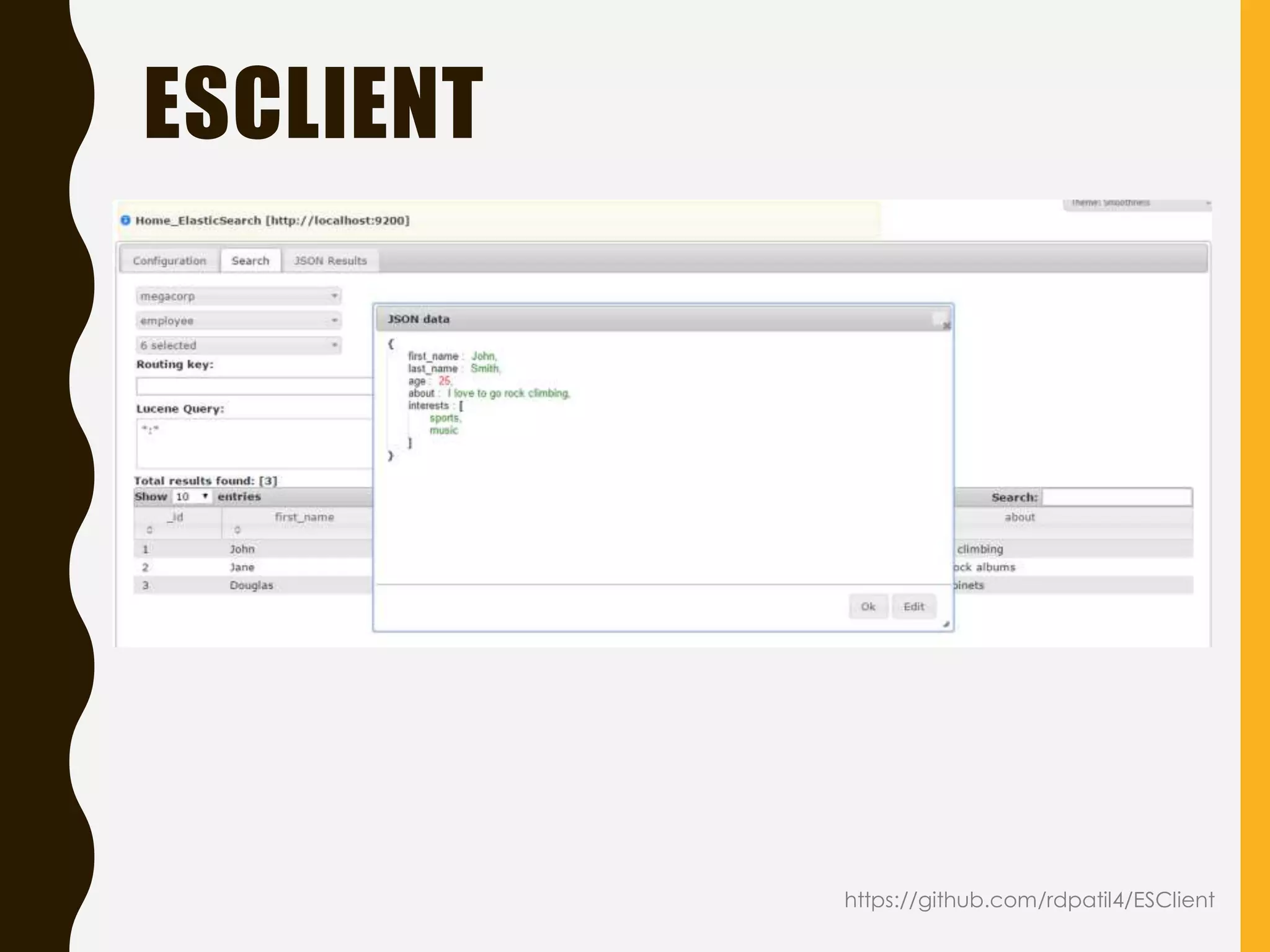
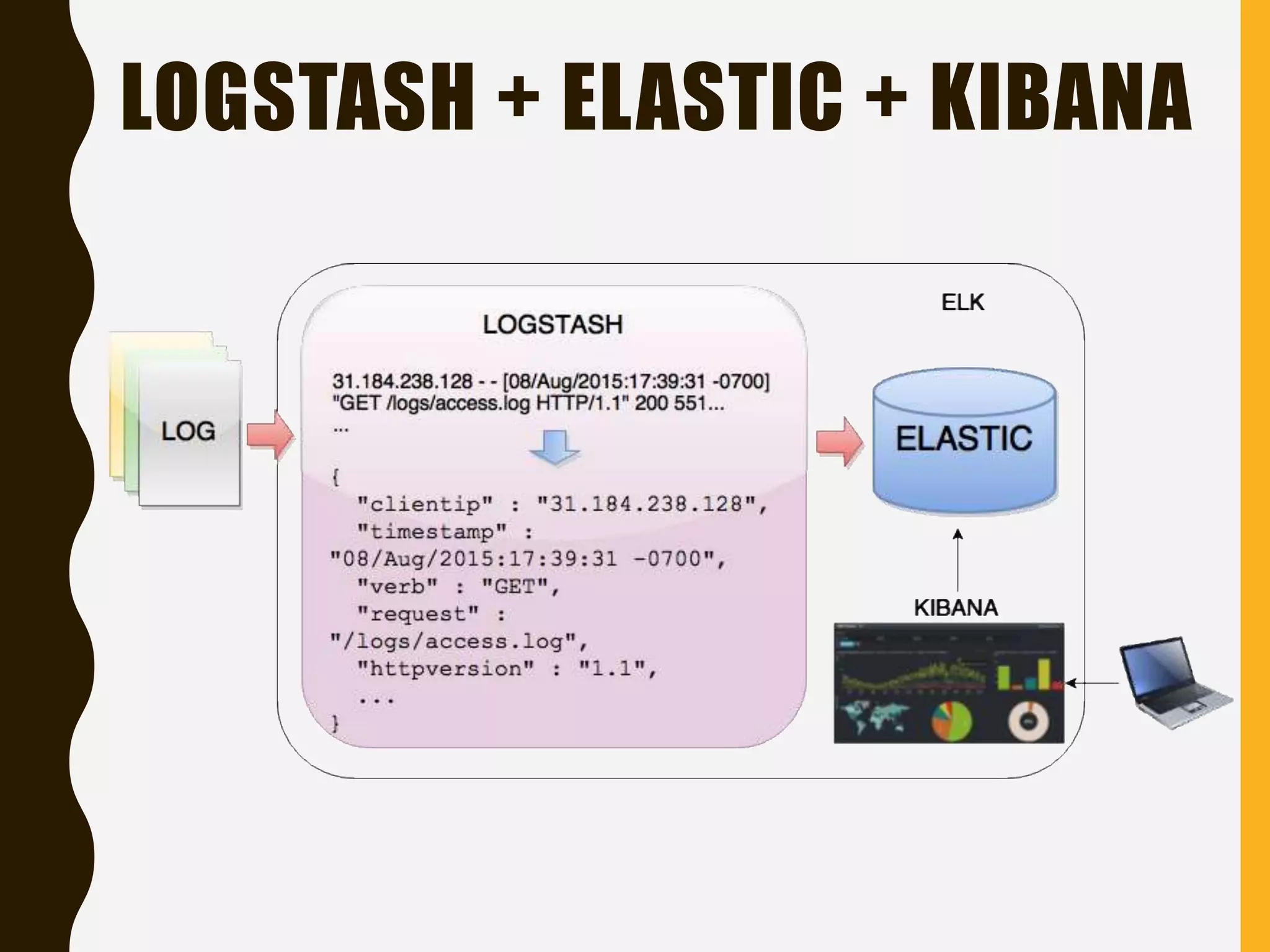
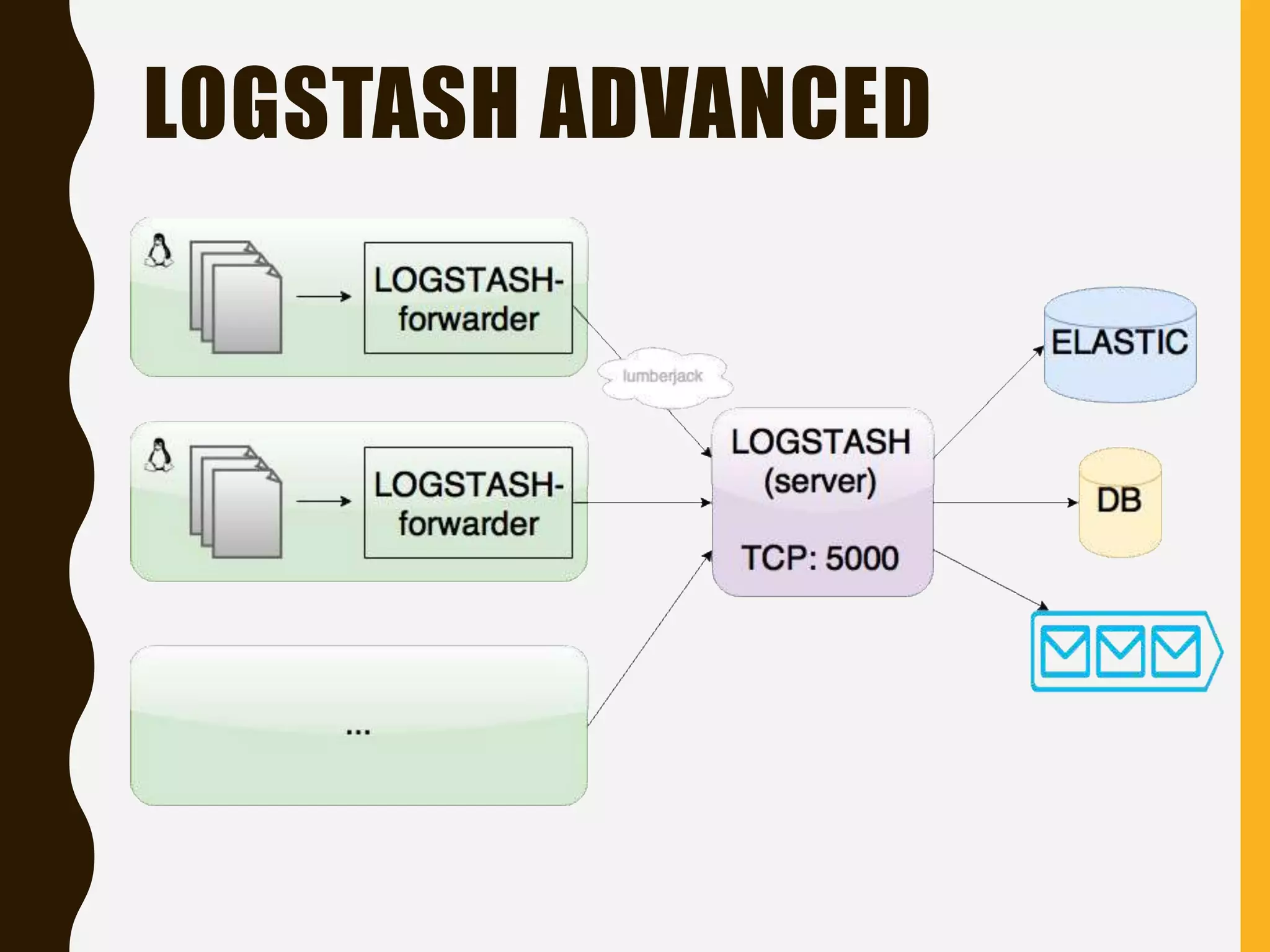
Explains the ELK stack integration, supported clients, and front-end tools for working with Elasticsearch.
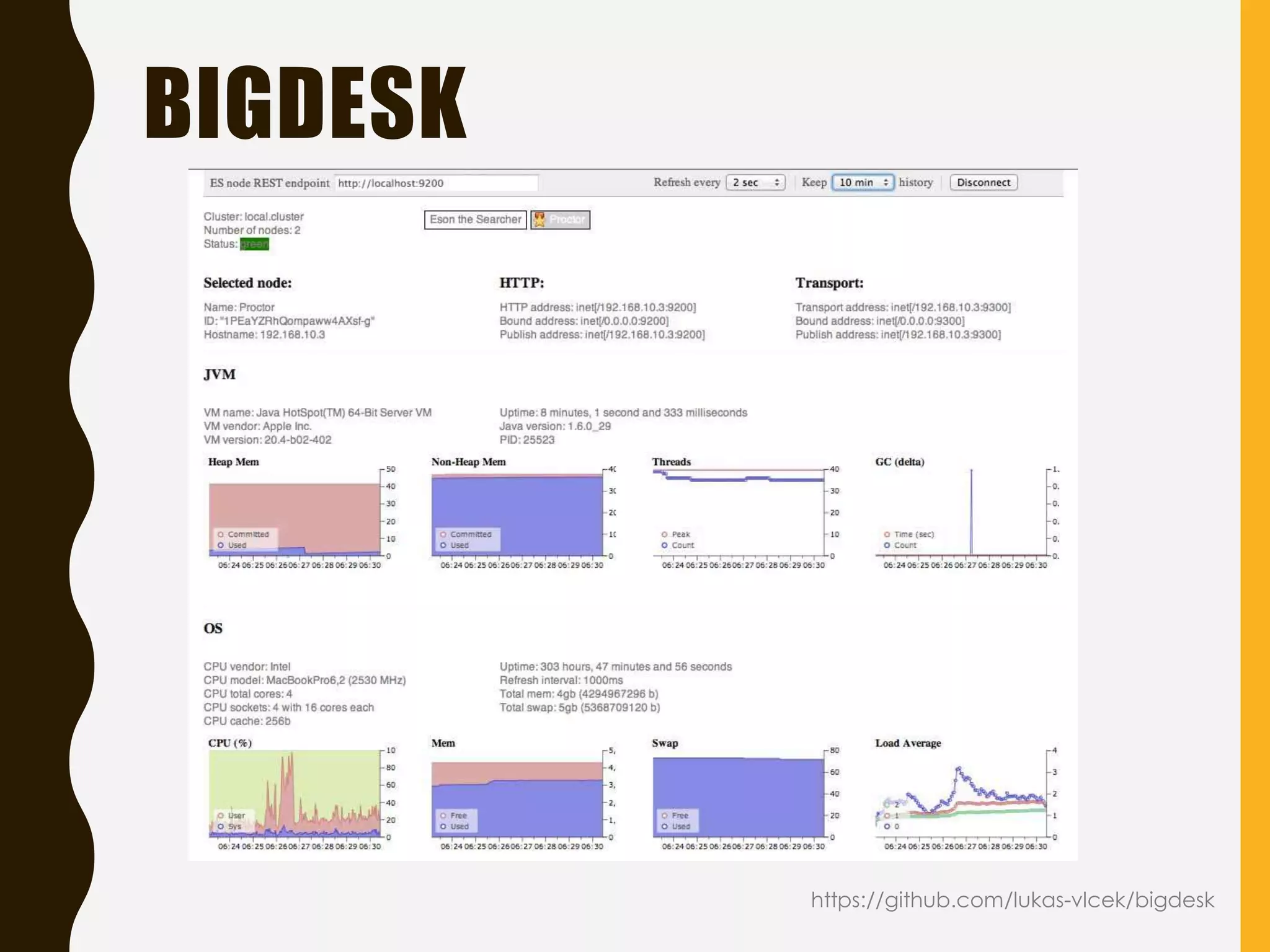
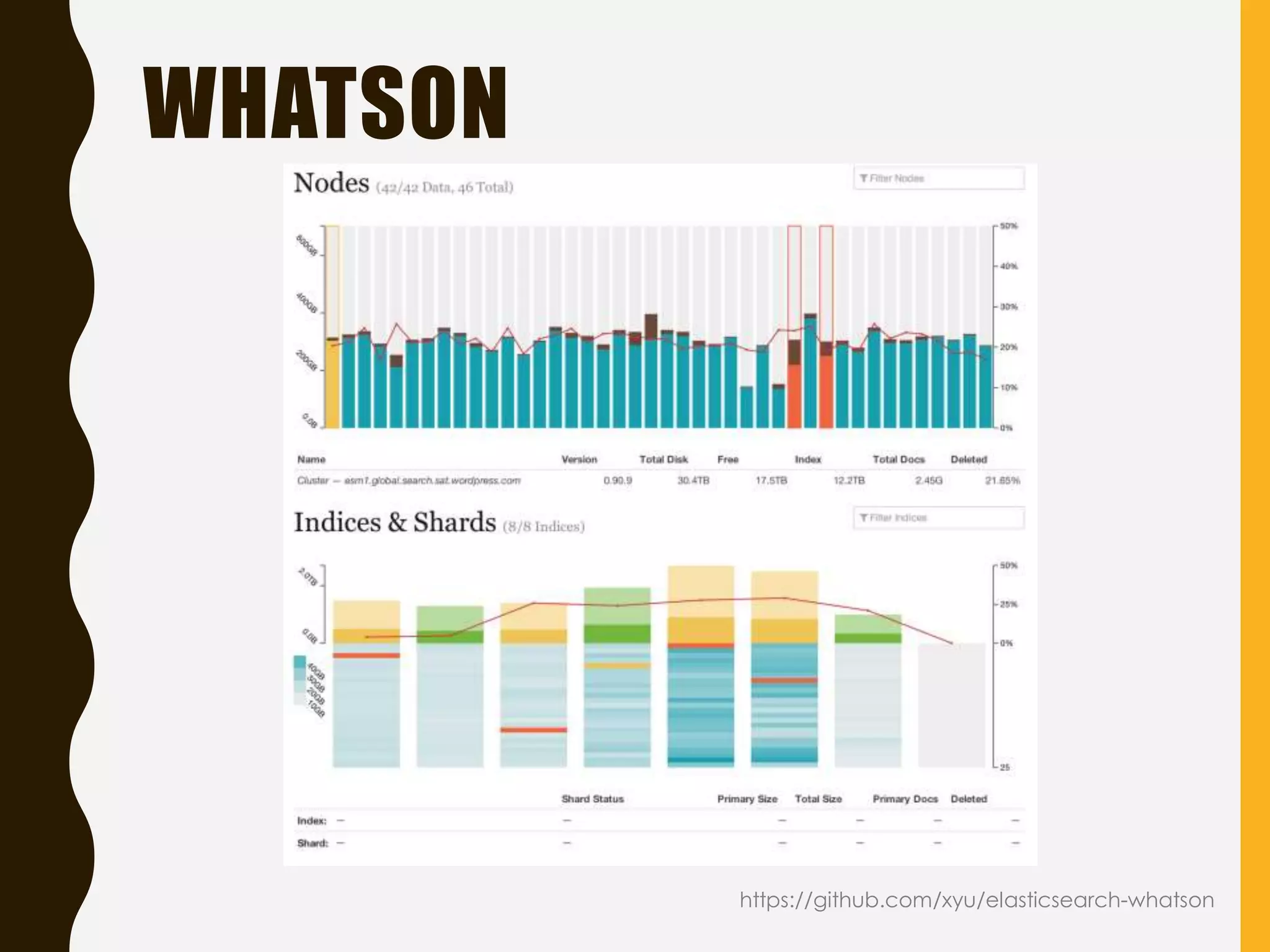
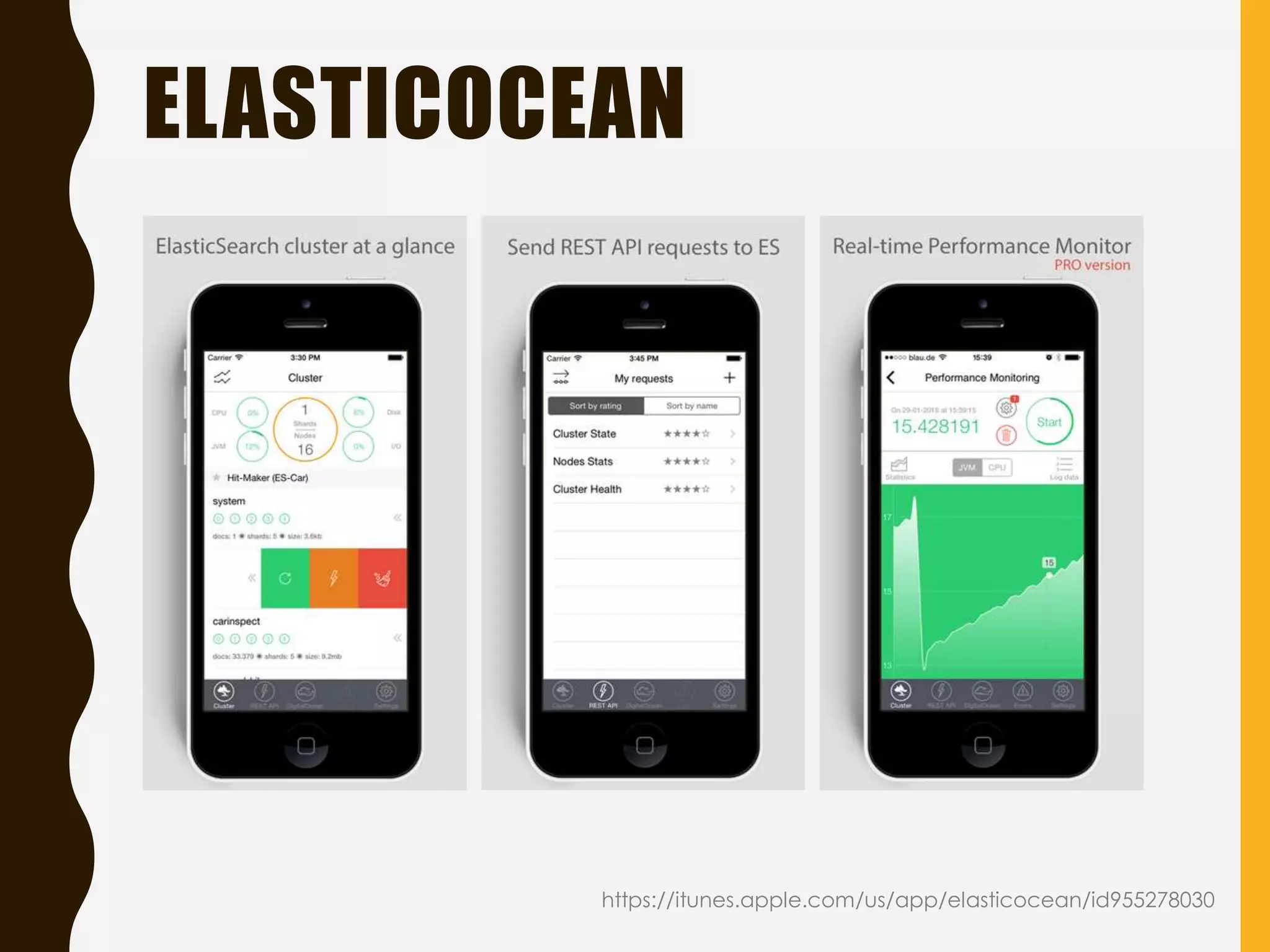
Focus on health monitoring tools and performance metrics to watch for effective Elasticsearch operation.
Exploration of additional plugins and tools to extend Elasticsearch functionalities such as normalization, scripting, and data visualization.
Details on Elasticsearch's product offerings, including Found, Shield, and other tools for deployment and monitoring.
Highlights limitations of Elasticsearch, its comparative performance with other tools, and the need for proper tool selection.
Summarizes key points about Elasticsearch while encouraging exploration of its capabilities.
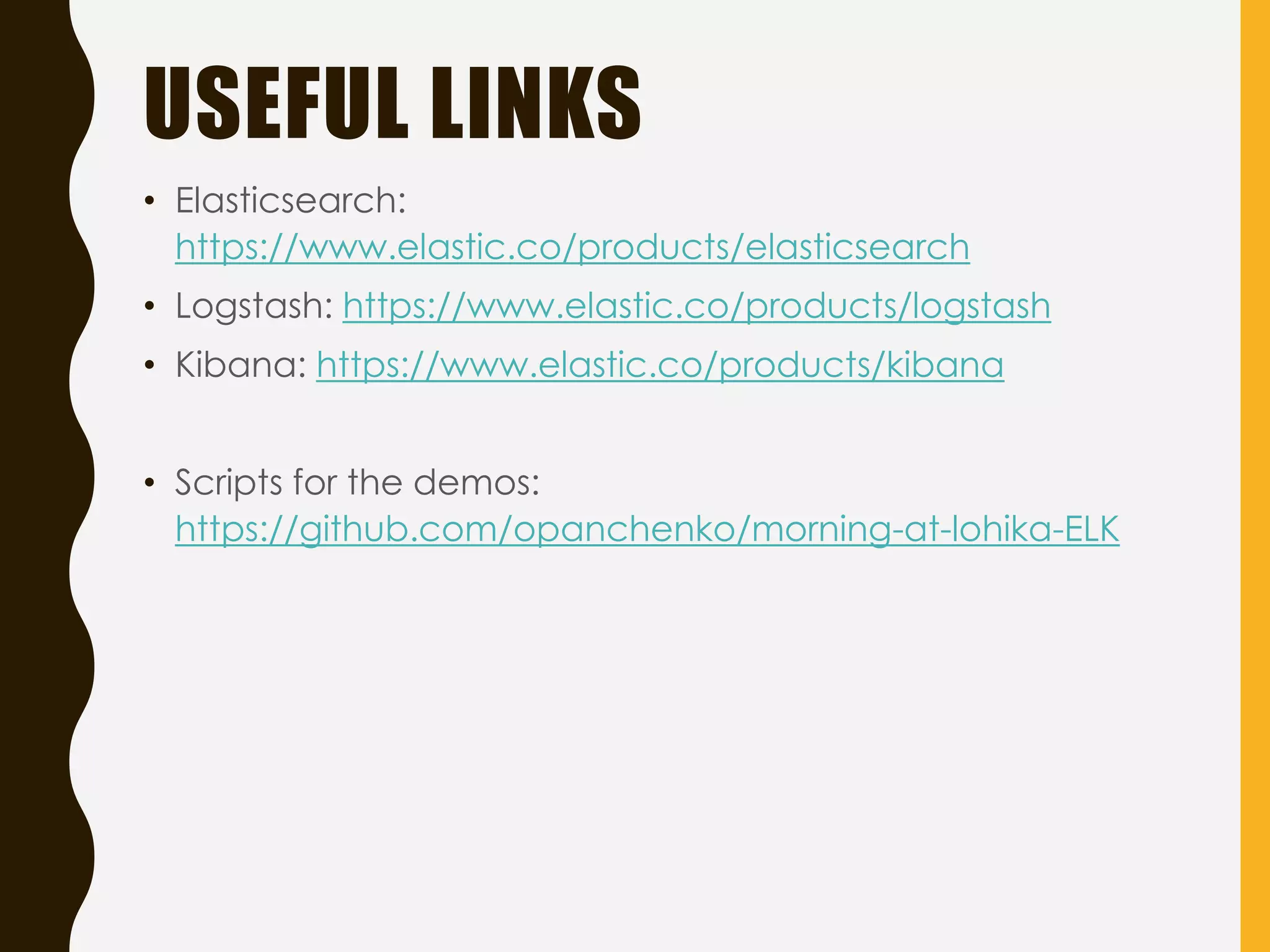
Provides useful links related to Elasticsearch, Logstash, Kibana, and demo scripts for deeper insights.




















































![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)