Download as PDF, PPTX




![9
Major Changes in Storage Landscape
All spinning disks
Limited RAM
SSD/NAND cost effec1ve
RAM much cheaper
Intel 3Dxpoint
256GB, 512GB RAM common
.
The next boRleneck is CPU
[2007ish] [2013ish] [2017+]
50
50000
10000000
1 1000 1000000
3D Xpoint
SSD
Spinning Disk
Seek Time (in nanoseconds)
3D Xpoint
SSD
Spinning Disk](https://image.slidesharecdn.com/kuduformeetup-160527195512/85/Kudu-Fast-Analytics-on-Fast-Data-9-320.jpg)


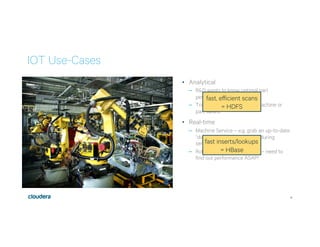
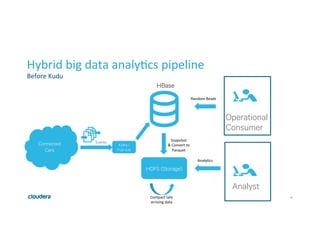
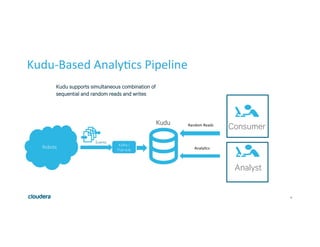


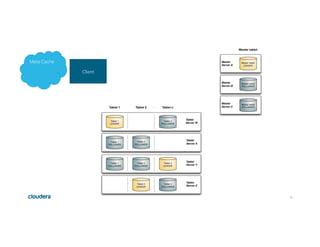
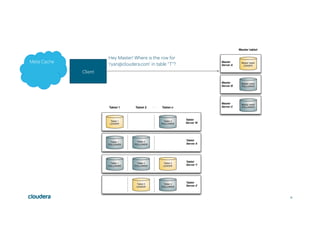
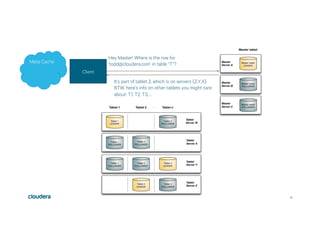
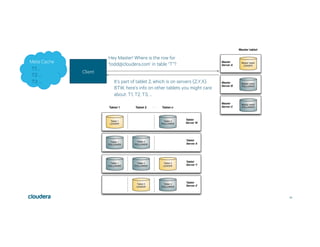
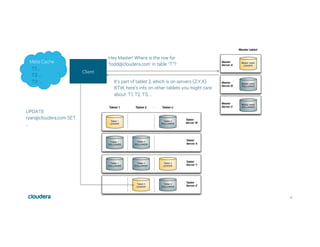






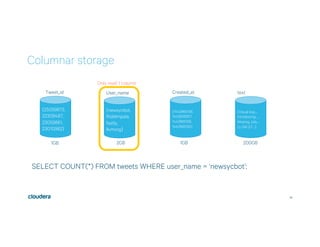
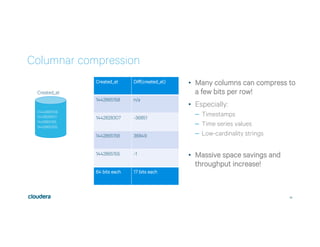
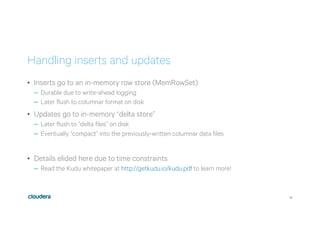






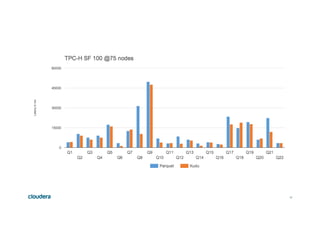
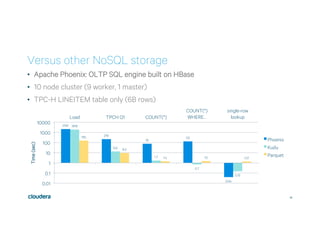
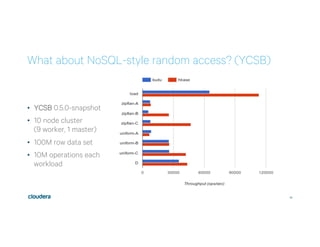




This document discusses Apache Kudu, an open source column-oriented storage system that provides fast analytics on fast data. It describes Kudu's design goals of high throughput for large scans, low latency for short accesses, and database-like semantics. The document outlines Kudu's architecture, including its use of columnar storage, replication for fault tolerance, and integrations with Spark, Impala and other frameworks. It provides examples of using Kudu for IoT and real-time analytics use cases. Performance comparisons show Kudu outperforming other NoSQL systems on analytics and operational workloads.













































































