Download as PDF, PPTX

















![Micro-batch
• RDD HBase
dstream.foreachRDD { rdd =>
val hbaseConf = createHbaseConfiguration()
val jobConf = new Configuration(hbaseConf)
jobConf.set("mapreduce.job.output.key.class", classOf[Text].getName)
jobConf.set("mapreduce.job.output.value.class", classOf[Text].getName)
jobConf.set("mapreduce.outputformat.class",
classOf[TableOutputFormat[Text]].getName)
new PairRDDFunctions(rdd.map(hbaseConvert)).saveAsNewAPIHadoopDataset(jobConf)
}
// RDD[(String, Map[K,V])] RDD[(String, Put)]
def hbaseConvert(t:(String, Map[String, String])) = {
val p = new Put(Bytes.toBytes(t._1))
t._2.toSeq.foreach(
m => p.addColumn(Bytes.toBytes("seg"),
Bytes.toBytes(m._1), Bytes.toBytes(m._2))
)
(t._1, p)
}
19
0.5 1](https://image.slidesharecdn.com/20151209sparkstreaming-160917053325/85/Spark-Streaming-19-320.jpg)



![Spark Streaming :
• : →
RDD → RDD DStream → DStream
• 1Micro-batch
23
// RDD → RDD
val input:RDD[String] = sparkContext.makeRDD(Seq("a", "b", “c"))
// DStream → DStream
val queue = scala.collection.mutable.Queue(rdd)
val dstream:DStream[String] =
sparkStreamingContext.queueStream(queue)](https://image.slidesharecdn.com/20151209sparkstreaming-160917053325/85/Spark-Streaming-23-320.jpg)

}
}
24](https://image.slidesharecdn.com/20151209sparkstreaming-160917053325/85/Spark-Streaming-24-320.jpg)

: JavaRDD[T] =
new JavaRDD[T](rdd)
implicit def toRDD[T](rdd: JavaRDD[T]): RDD[T] = rdd.rdd
}](https://image.slidesharecdn.com/20151209sparkstreaming-160917053325/85/Spark-Streaming-26-320.jpg)


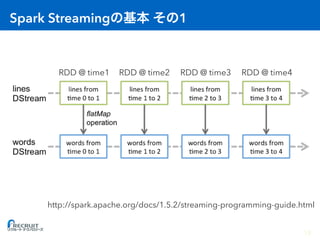
Spark Streaming allows processing of live data streams using Spark. It works by dividing the data stream into batches called micro-batches, which are then processed using Spark's batch engine to generate RDDs. This allows for fault tolerance, exactly-once processing, and integration with other Spark APIs like MLlib and GraphX.




















































![[Spark meetup] Spark Streaming Overview](https://cdn.slidesharecdn.com/ss_thumbnails/sparkmeetupstratiostreaming-150121022614-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)



