Downloaded 73 times





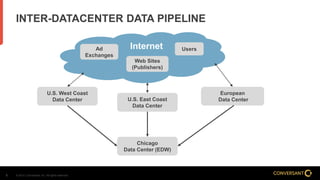
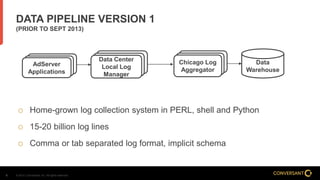

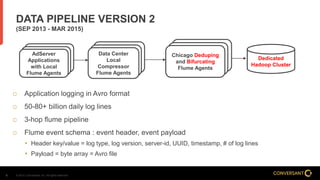

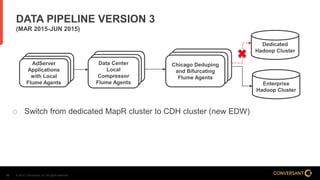

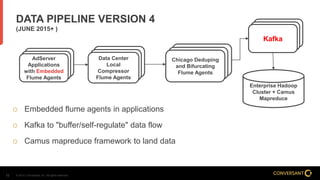


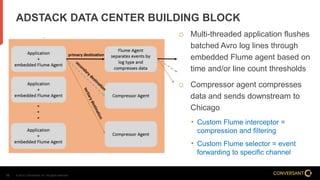
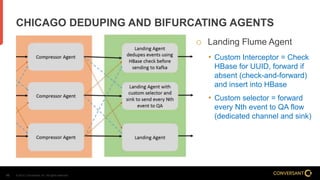
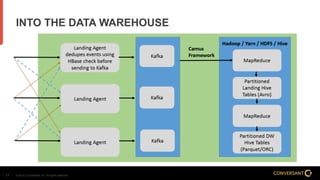


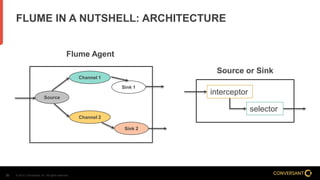

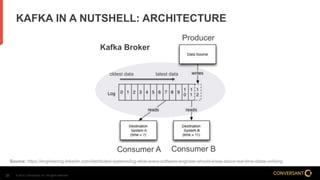

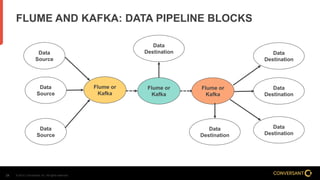







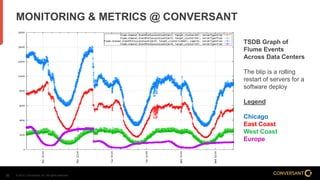
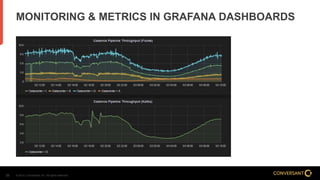



This document compares Apache Flume and Apache Kafka for use in data pipelines. It describes Conversant's evolution from a homegrown log collection system to using Flume and then integrating Kafka. Key points covered include how Flume and Kafka work, their capabilities for reliability, scalability, and ecosystems. The document also discusses customizing Flume for Conversant's needs, and how Conversant monitors and collects metrics from Flume and Kafka using tools like JMX, Grafana dashboards, and OpenTSDB.






























































