Downloaded 20 times




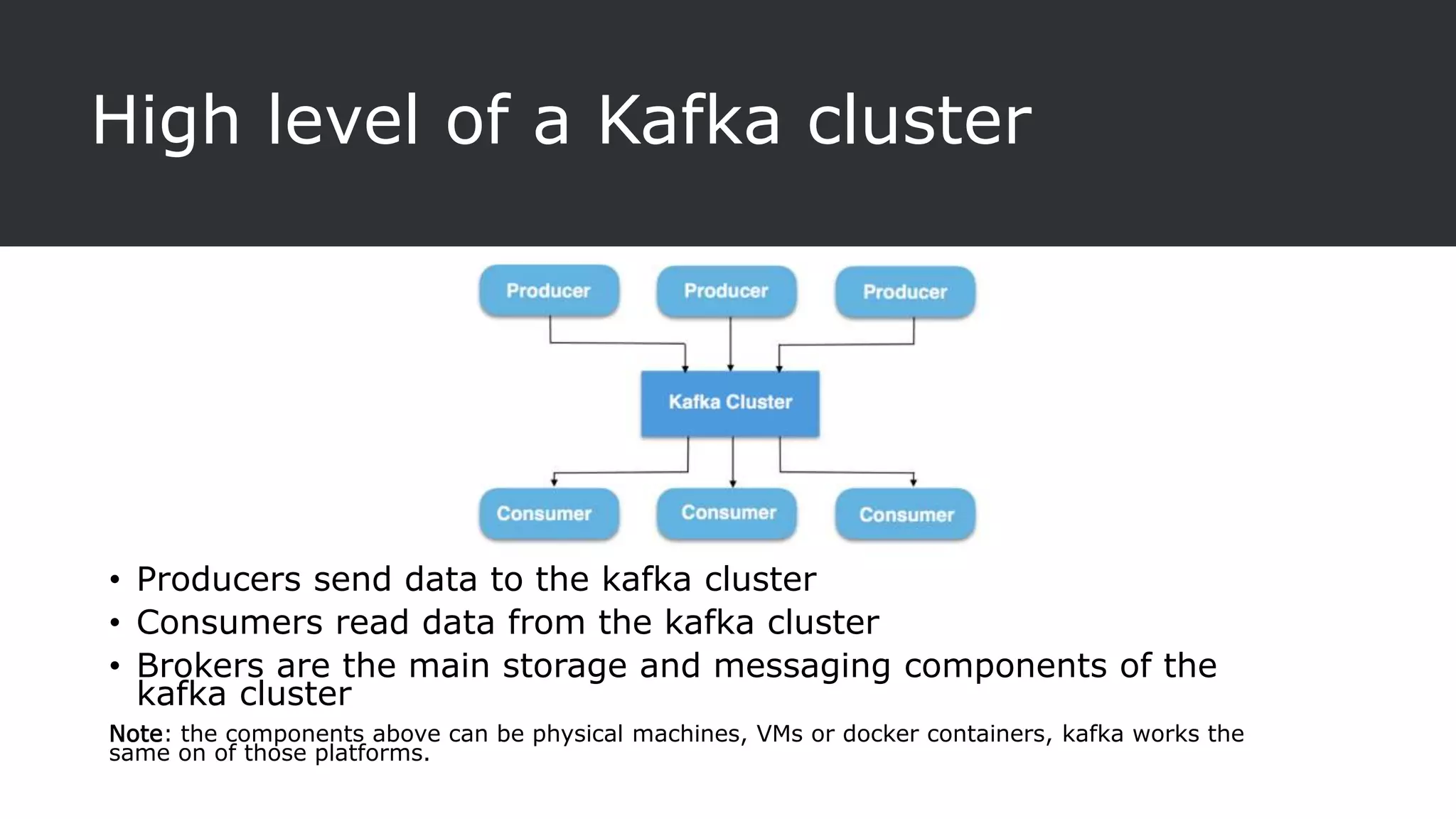


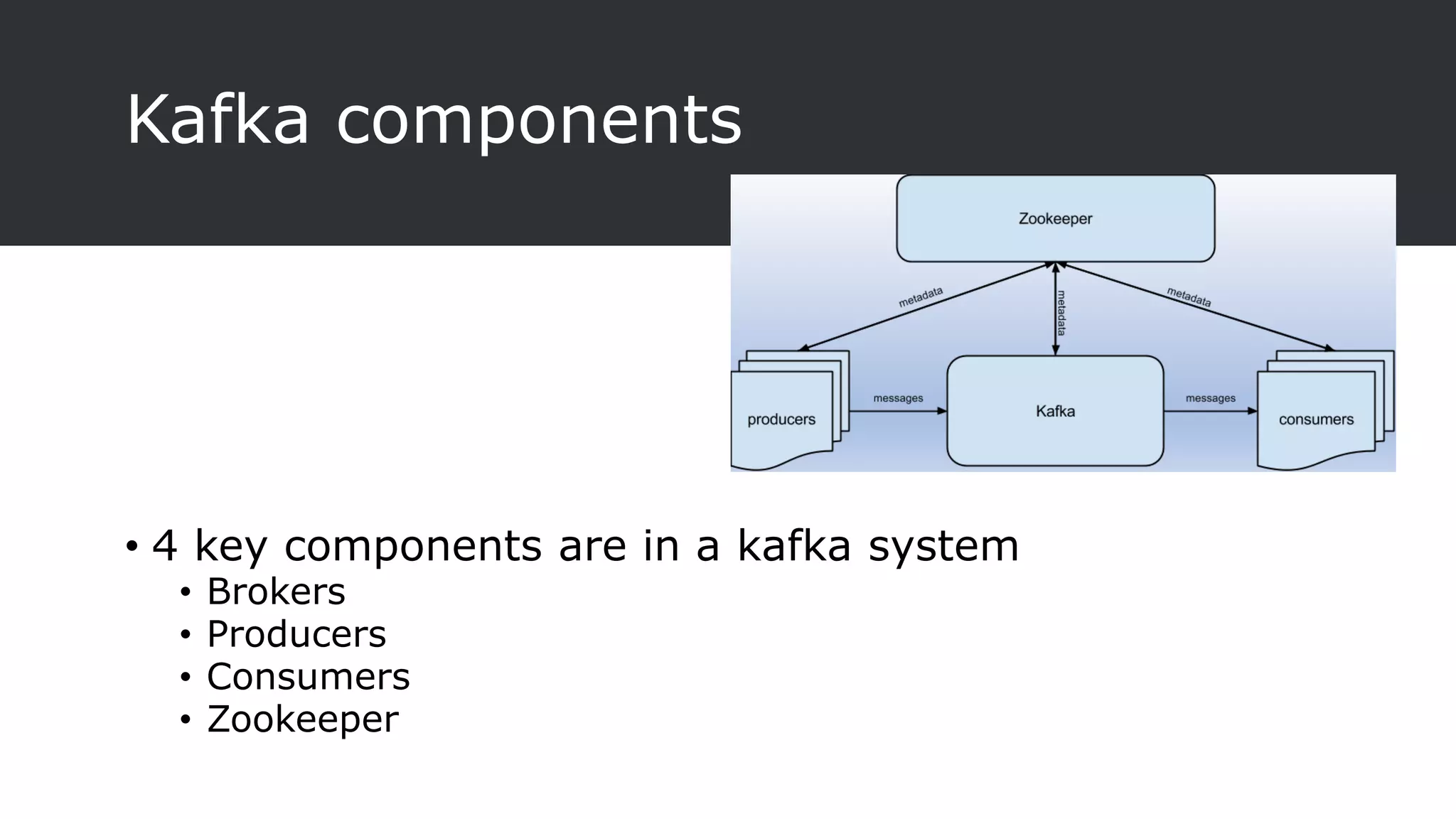








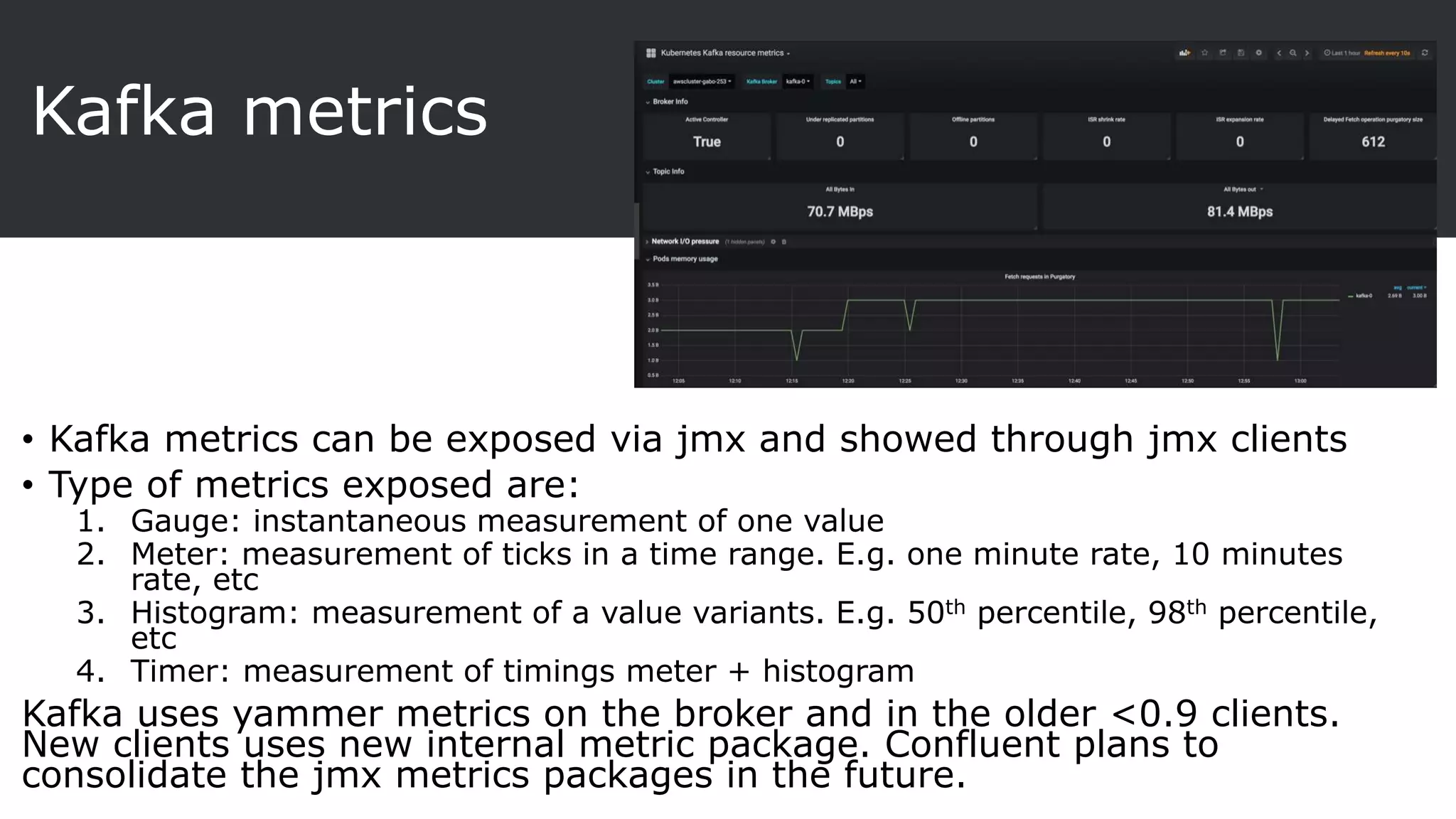

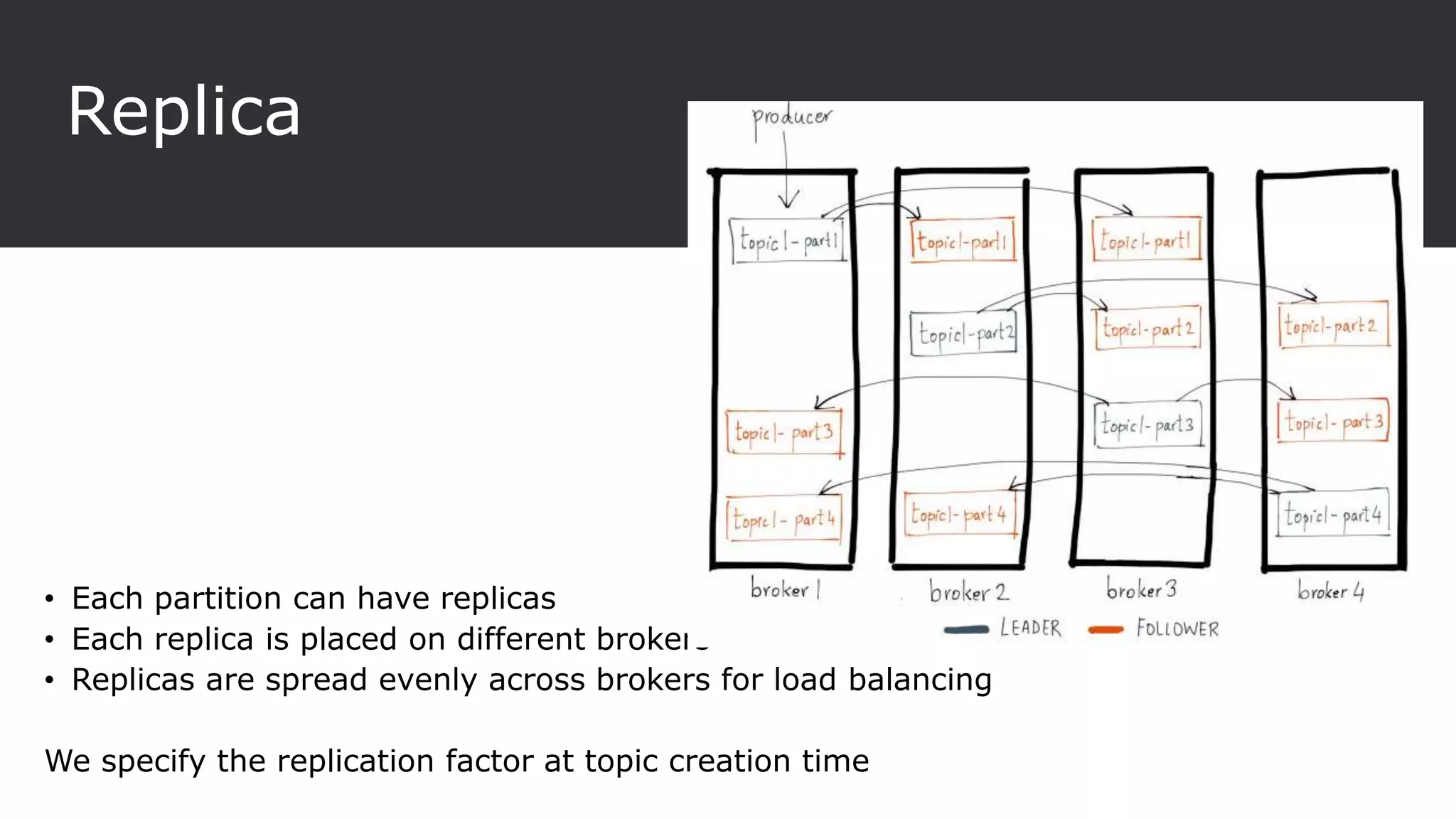




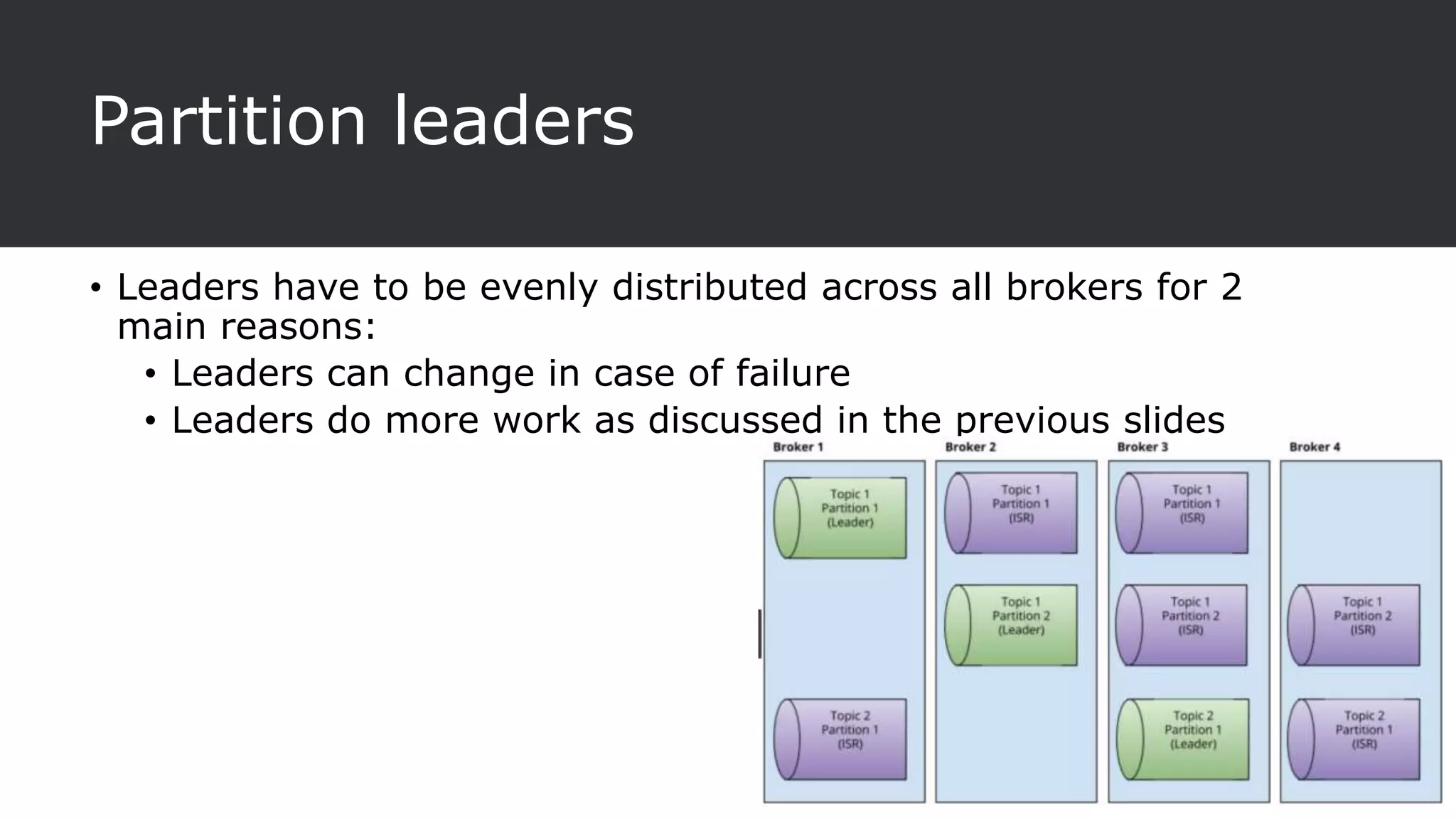
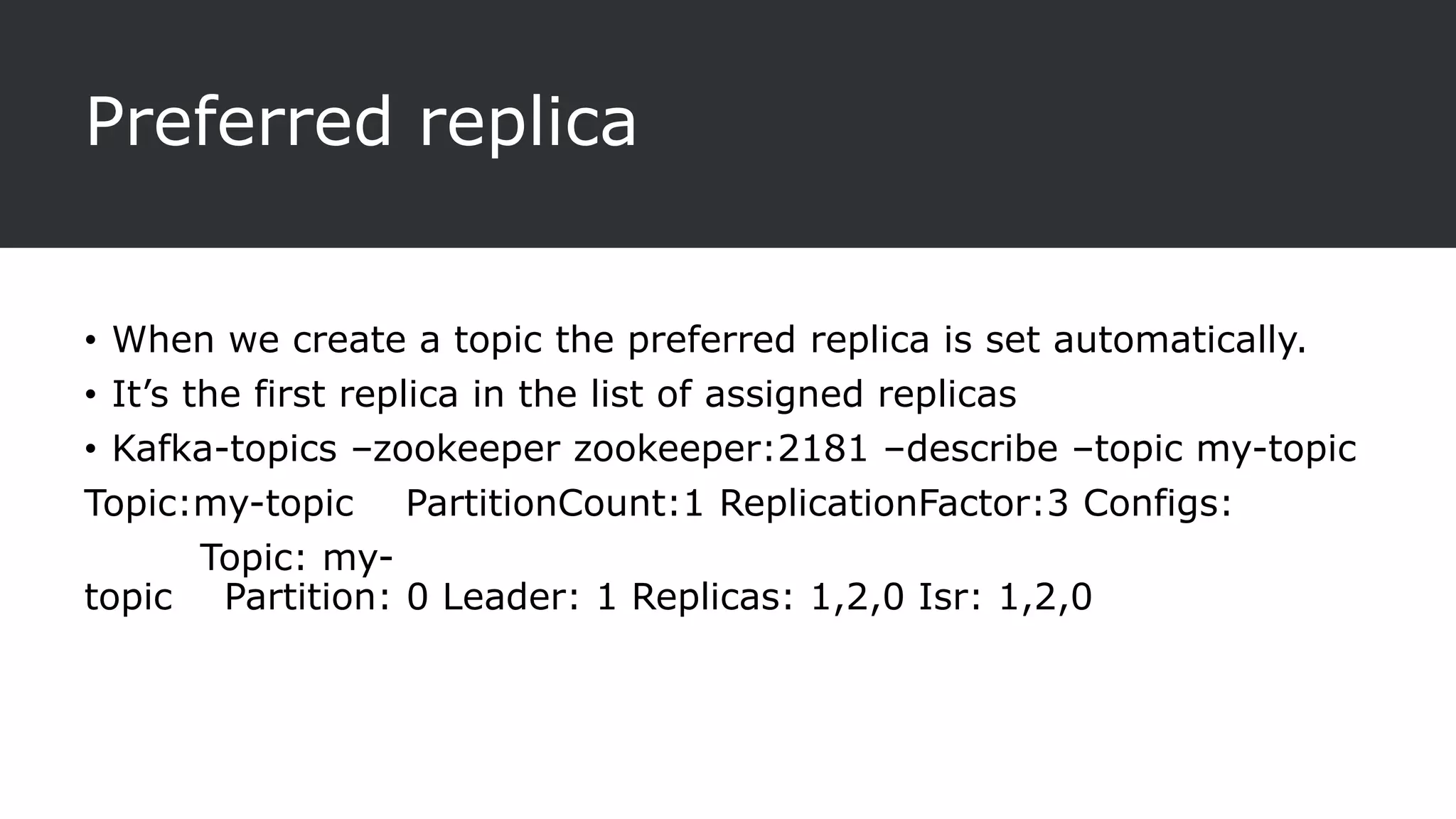




The document provides an overview of Apache Kafka, a distributed streaming platform known for its scalability, fault tolerance, and high throughput, and describes its architecture consisting of producers, consumers, brokers, and Zookeeper. It highlights the advantages of Kafka over traditional messaging queues, including message durability, real-time processing capabilities, and data partitioning for performance. Additionally, the document explains key components, the replication process for data durability, and Kafka's metrics for monitoring performance.



































































