
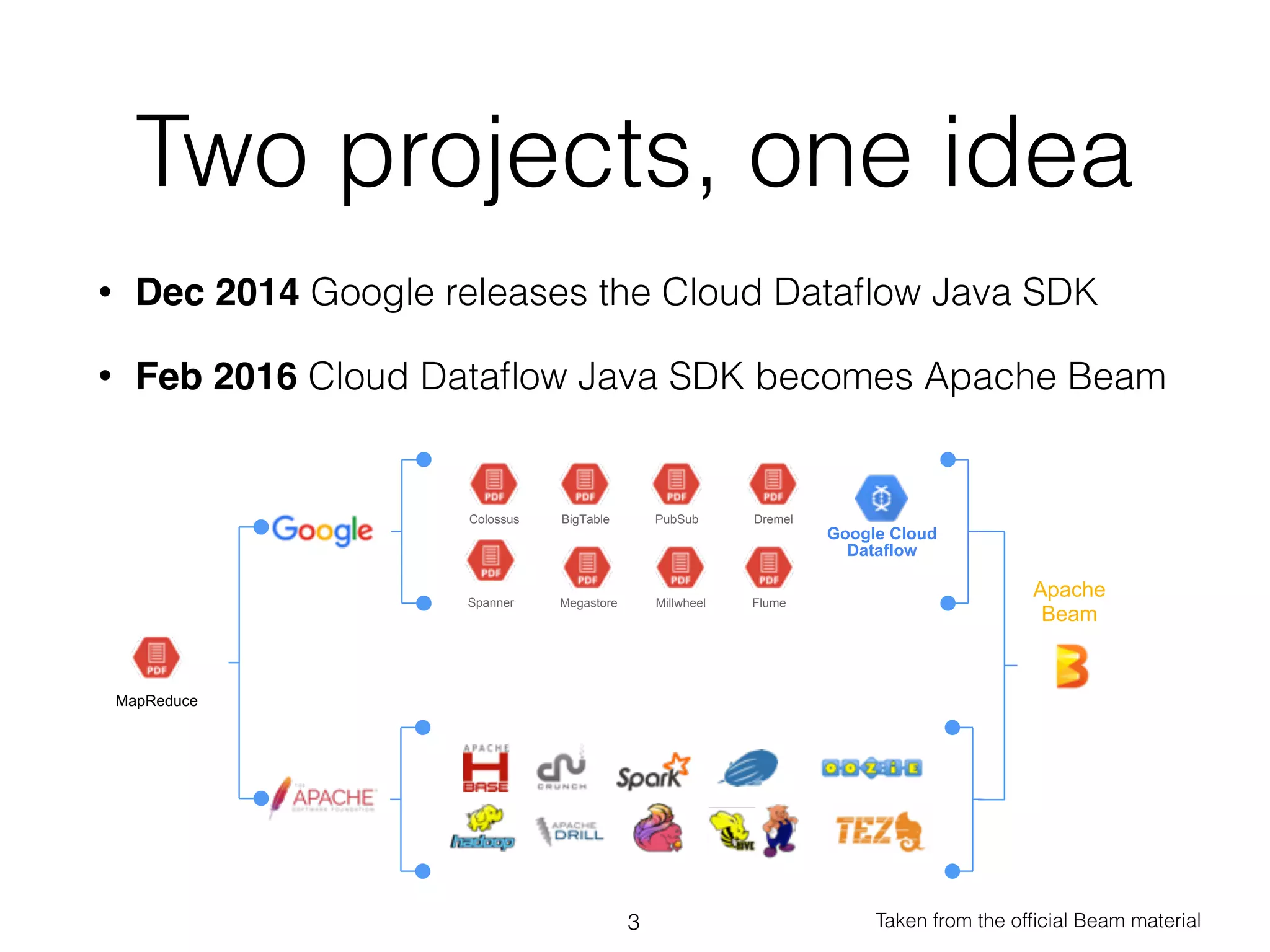
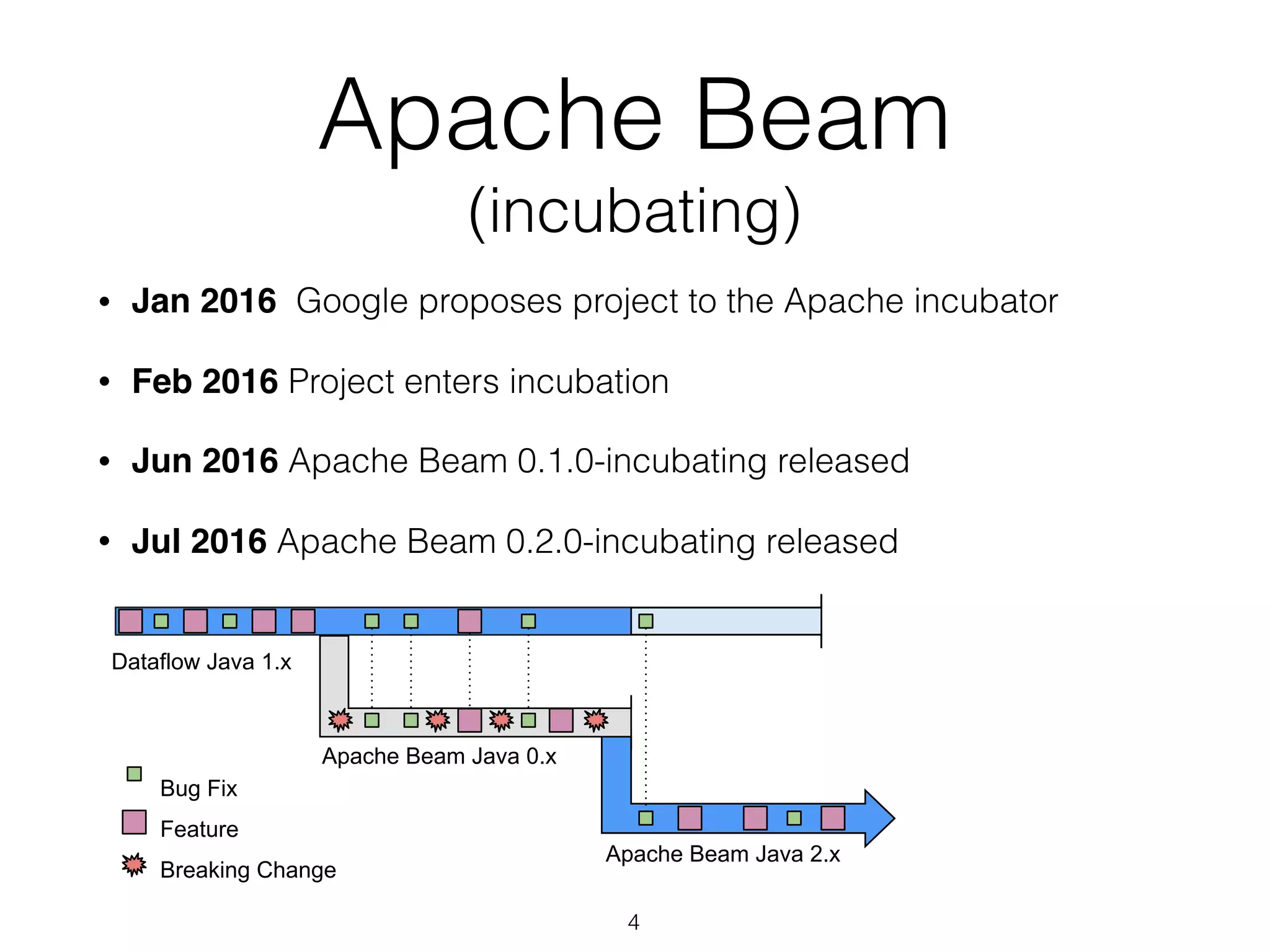

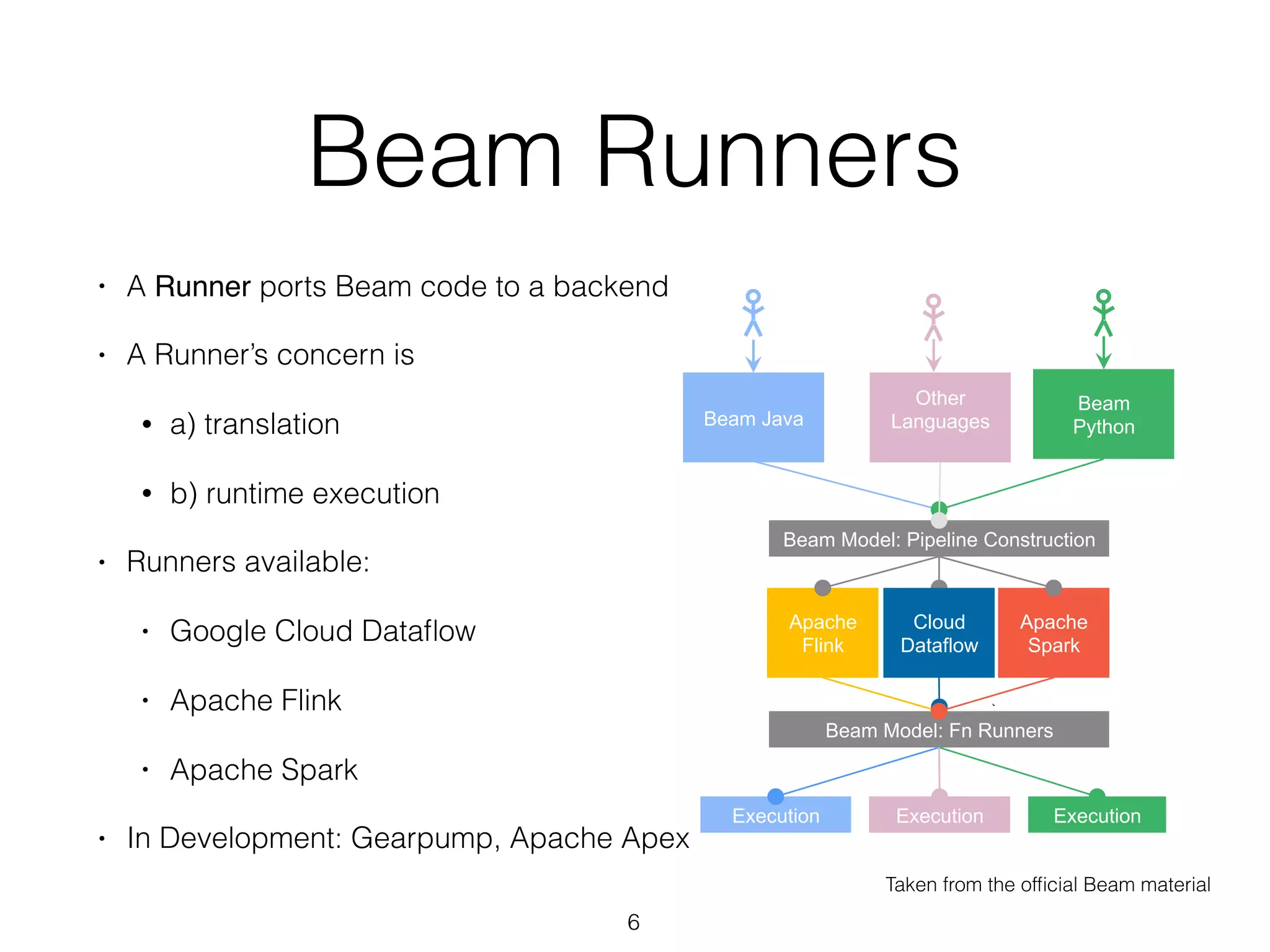





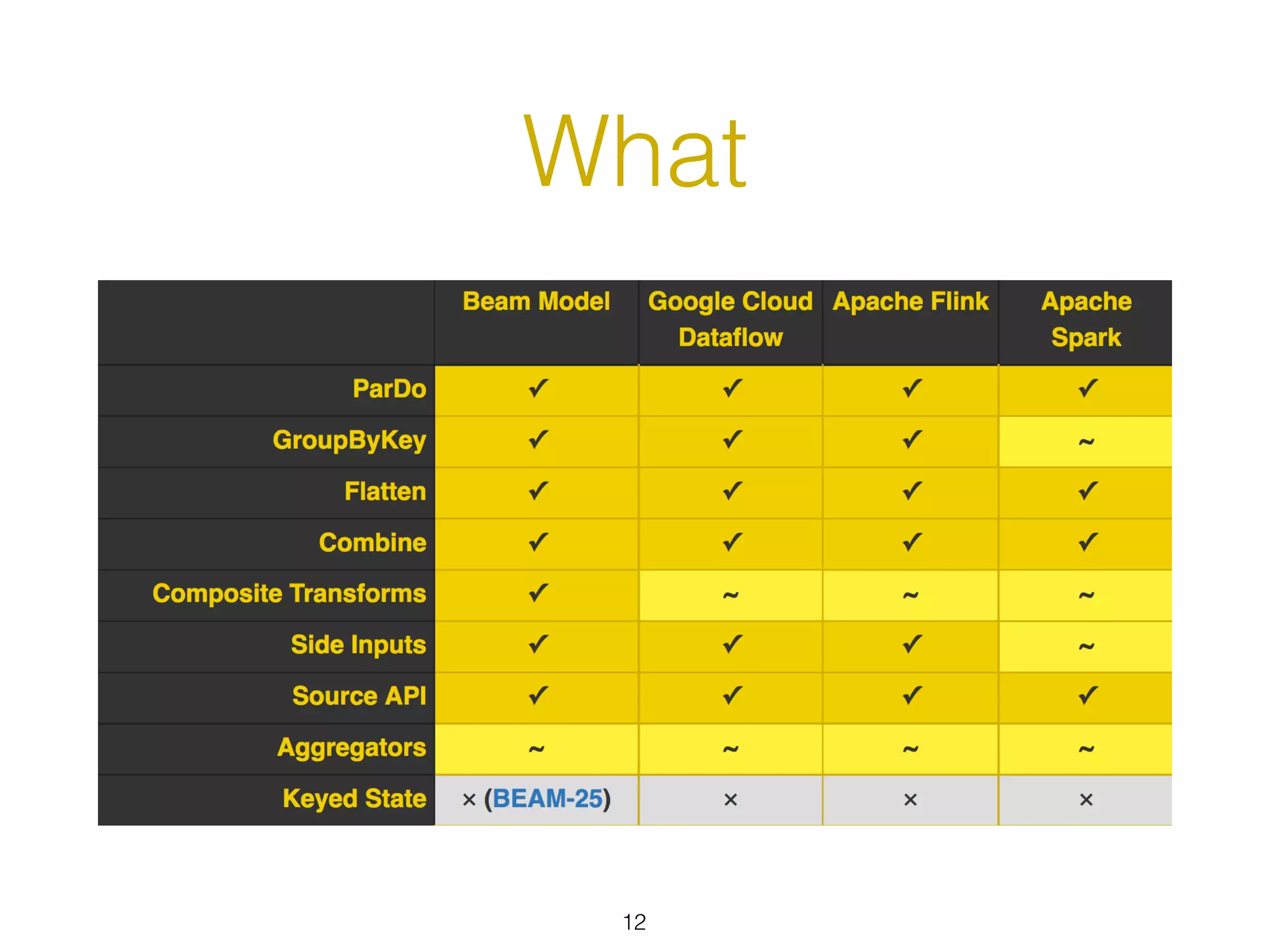
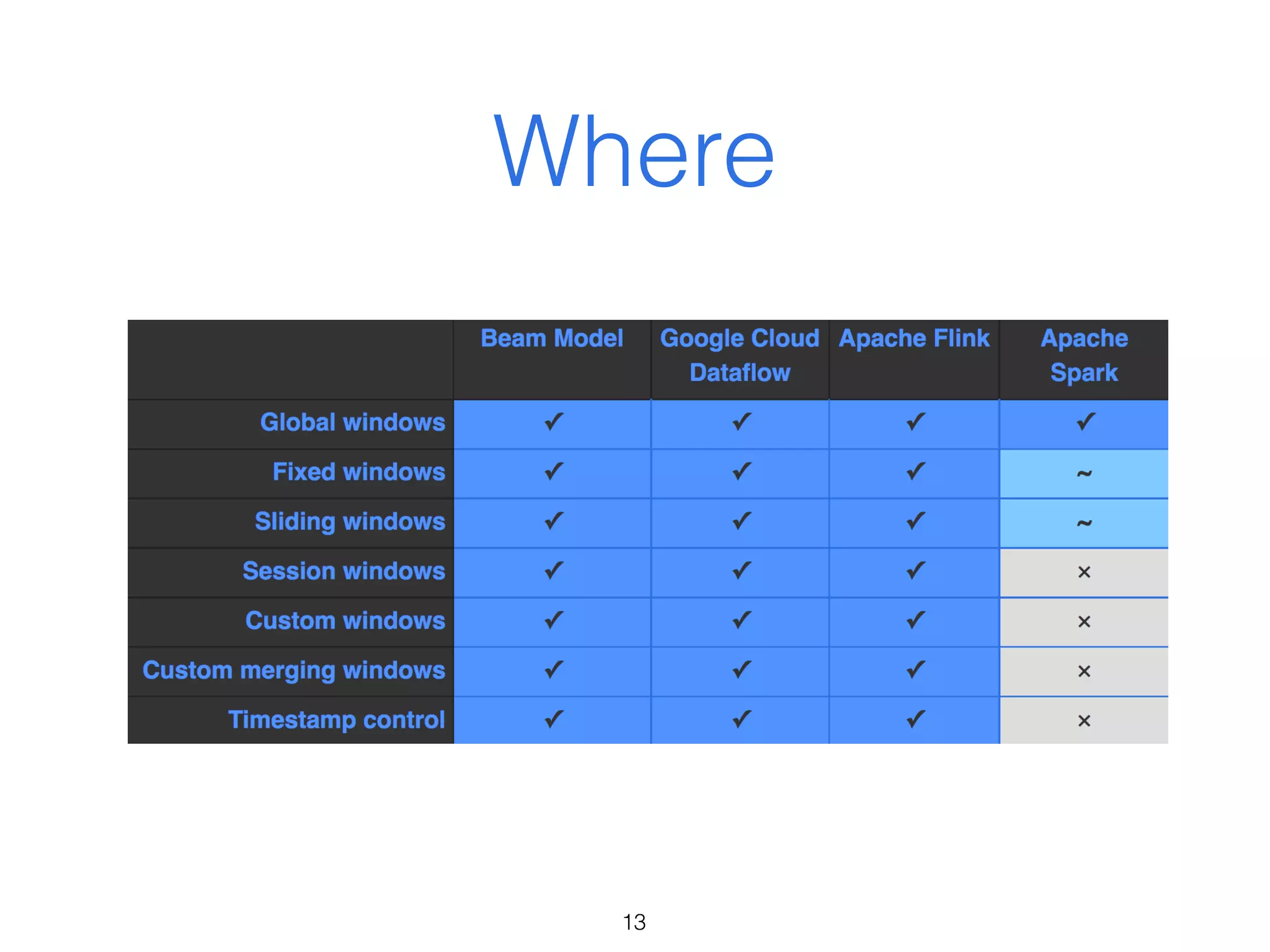
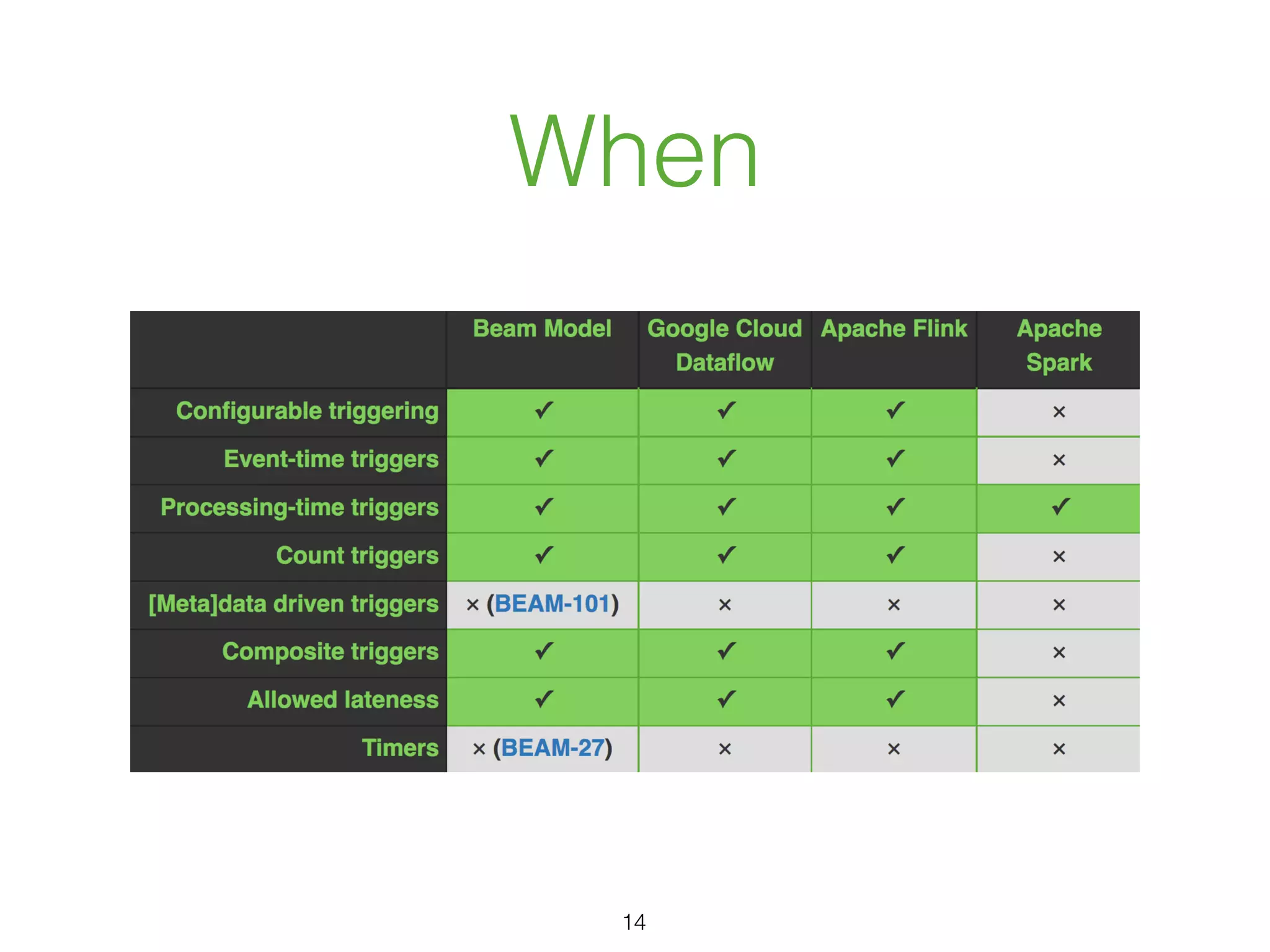
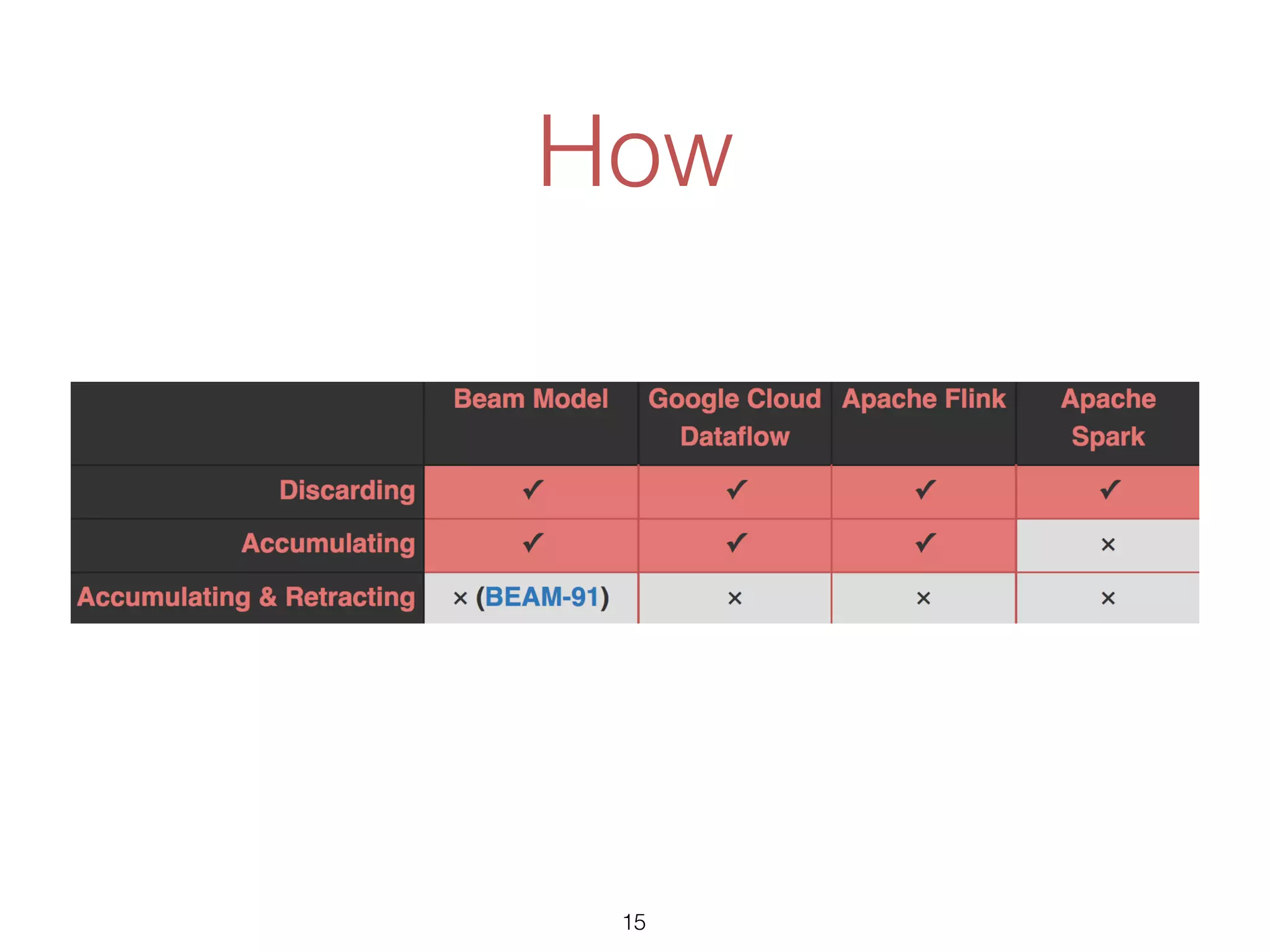






The document discusses the current state and roadmap of Apache Flink and Apache Beam, highlighting their evolution and integration since the introduction of Google Cloud Dataflow in 2014. It details the capabilities of the Flink runner, its strengths, and its ongoing development to enhance features such as side input streaming and dynamic scaling. Additionally, it outlines comparisons of various runners and their execution models for batch and streaming data processing.























































































