





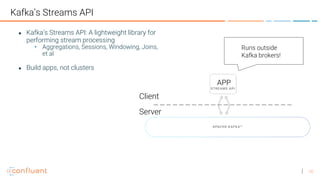
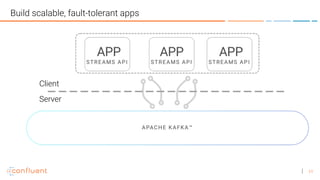
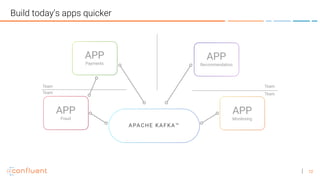












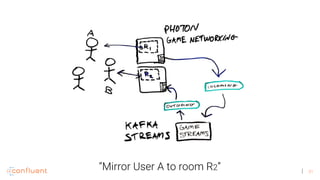
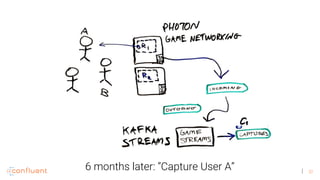


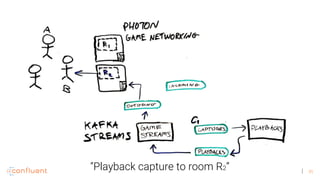
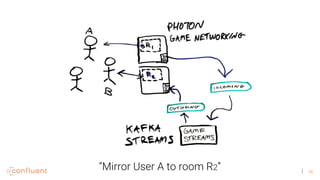





![44
Keep consistent topic naming
Kafka Stream jobs involve a lot of source + intermediate topics
We prefer:
[<data source>|<job application id>]-<avro record type>[_<specifier>]-<partition key>
Ex:
oltp_db-user-user_id
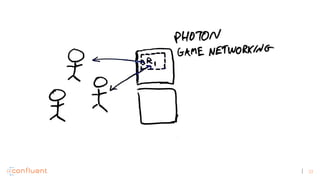
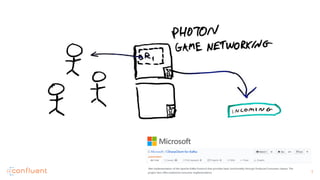
job_playbacks-photon_instantiations-game_stream_id](https://image.slidesharecdn.com/hadoopmadefast-whyvirtualrealityneededstreamprocessingtosurvive-170810212554/85/Hadoop-made-fast-Why-Virtual-Reality-Needed-Stream-Processing-to-Survive-44-320.jpg)






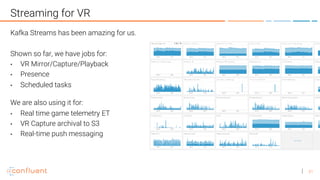


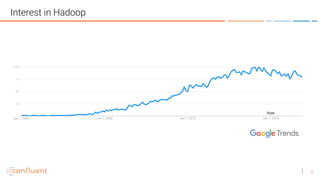
1. A streaming platform like Kafka can provide the benefits of Hadoop for batch processing but in a faster, real-time way by processing data as it arrives rather than storing all data. 2. Virtual reality applications require stream processing to power features like VR mirroring and capture in real-time. Kafka's stream processing capabilities address challenges like this for VR. 3. The document discusses how AltspaceVR uses Kafka stream processing for applications like VR mirroring and capture, presence tracking, scheduled tasks, and more to power their real-time VR experiences.























































































