Download as PDF, PPTX








![Articles and Mentions
• High-throughput, low-latency, and exactly-once stream
processing with Apache Flink [1]
• Introducing Gelly: Graph Processing with Apache Flink [2]
• Apache Flink and the case for stream processing [3]
• Crunching Parquet Files with Apache Flink [4]
• The morning paper: Asynchronous Distributed Snapshots for
Distributed Dataflows [5]
• Five open source Big Data projects to watch [6]
• Big Data Performance Engineering: Examples from Hadoop,
Pig, HBase, Flink and Spark [7]
12
[1] http://data-artisans.com/high-throughput-low-latency-and-exactly-once-stream-processing-with-apache-flink/
[2] http://flink.apache.org/news/2015/08/24/introducing-flink-gelly.html
[3] http://www.kdnuggets.com/2015/08/apache-flink-stream-processing.html
[4] https://medium.com/@istanbul_techie/crunching-parquet-files-with-apache-flink-200bec90d8a7
[5] http://blog.acolyer.org/2015/08/19/asynchronous-distributed-snapshots-for-distributed-dataflows/
[6] http://www.zdnet.com/article/five-open-source-big-data-projects-to-watch/
[7] http://www.bigsynapse.com/addressing-big-data-performance](https://image.slidesharecdn.com/bayareaflinkcommunityupdateaugust2015-150828172720-lva1-app6892/85/Bay-Area-Apache-Flink-Meetup-Community-Update-August-2015-12-320.jpg)

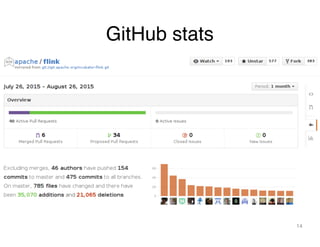



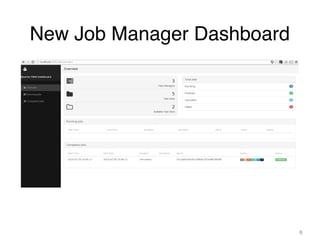
This document summarizes updates from Apache Flink community meeting in August 2015. Key points include: new project management committee and committer members joined Flink, discussions started for a new 0.9.1 release, and Flink is gaining popularity with over 1000 Twitter followers and 500 GitHub stars. Updates were provided on new features in development like a new JobManager dashboard, Gelly Scala API, and improvements to YARN integration. Upcoming events were also announced including Flink training sessions and new user group meetups forming in various cities.
























































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)



![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)






