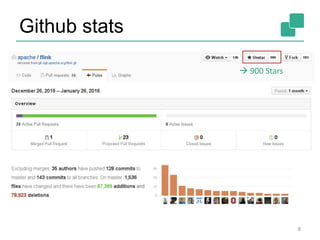
Downloaded 50 times












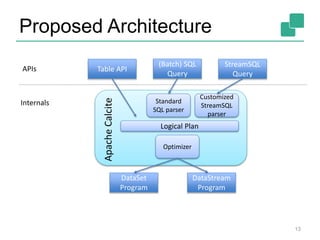
![SQL integration into APIs
14
val stream : DataStream[(String, Double, Int)]
= env.addSource(new FlinkKafkaConsumer(...))
val tabEnv = new TableEnvironment(env)
tabEnv.registerStream(stream, “myStream”,
(“ID”, “MEASURE”, “COUNT”))
val sqlQuery = tabEnv.sql(
“SELECT ID, MEASURE FROM myStream WHERE
COUNT > 17”)
Define Kafka input stream
Define table environment
SQL Query](https://image.slidesharecdn.com/13-meetup-slideshare-160127092432/85/January-2016-Flink-Community-Update-Roadmap-2016-14-320.jpg)

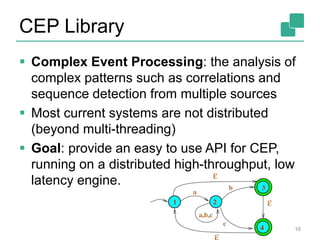
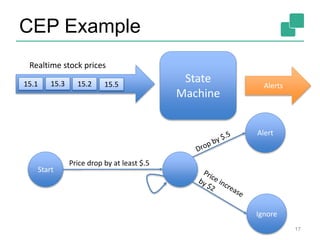







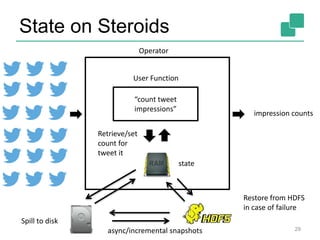

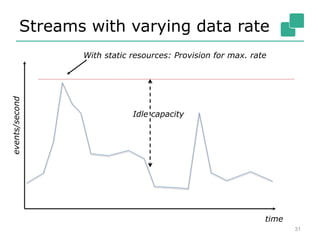
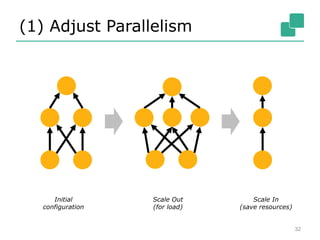

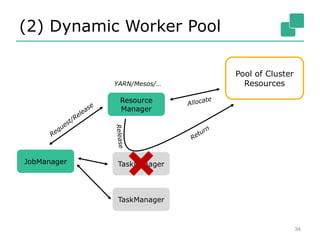


The Apache Flink community update for January 2016 covers recent developments such as the proposal of the DataFlow API, the integration of Kafka, and the addition of committer Chengxiang Li. Upcoming events include various talks and meetups, while the roadmap outlines plans for SQL support, complex event processing, and improved operator state management. New features like dynamic scaling, checkpointing, and miscellaneous enhancements are also discussed for future releases.




































































































