Download as PDF, PPTX



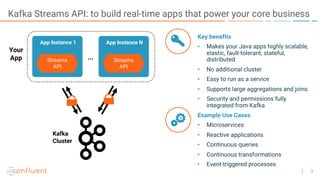




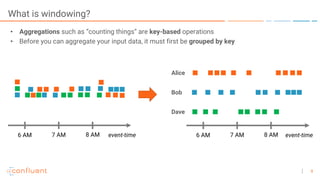
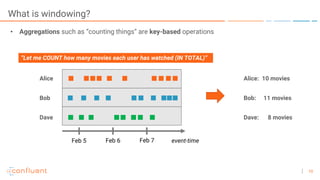
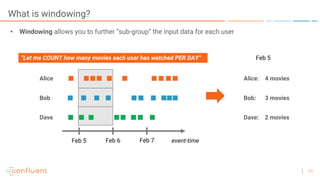
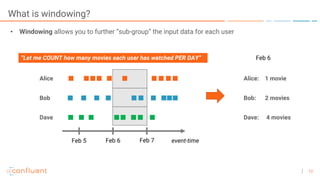
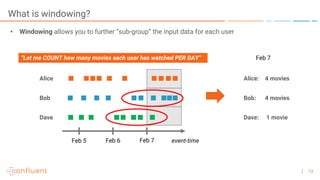
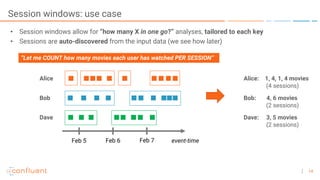

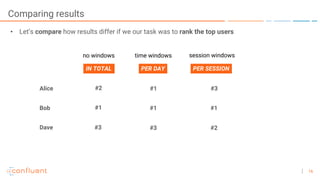


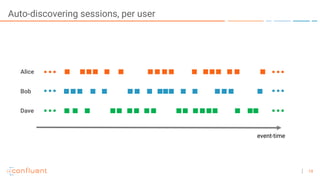
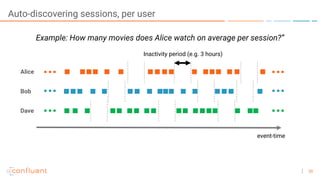
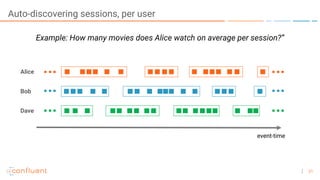

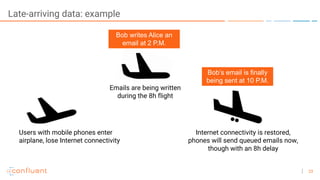




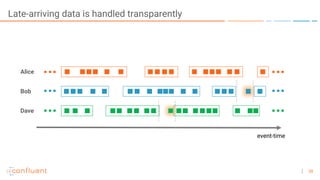
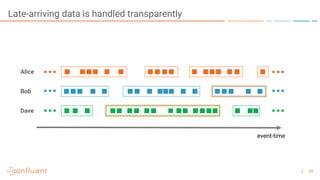

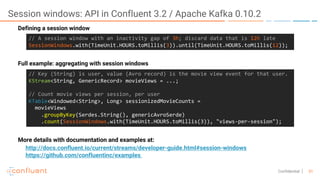




The document outlines a series of online talks regarding Apache Kafka and its Streams API, highlighting the importance of session windows for analyzing user behavior in real-time. It provides several use case examples across different industries such as travel, finance, and retail, emphasizing how Kafka can enhance decision-making and efficiency. Additionally, it discusses the handling of late-arriving data and the functionalities of session windows within the Kafka Streams API.






























































































