Download to read offline





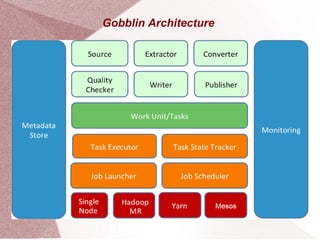

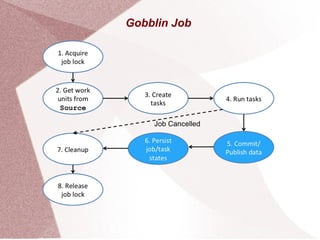

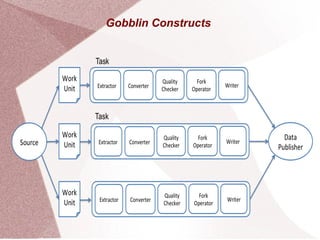






Apache Gobblin is a big data integration framework designed to simplify data ingestion, replication, organization, and lifecycle management for both streaming and batch processes. It supports multiple execution modes including standalone, MapReduce, and cloud-based options, and offers various sources and sinks for data processing. Gobblin jobs are created from pluggable constructs, managed by the runtime for tasks such as scheduling and error handling, with configuration defined via properties files.









































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)







