Download as PDF, PPTX














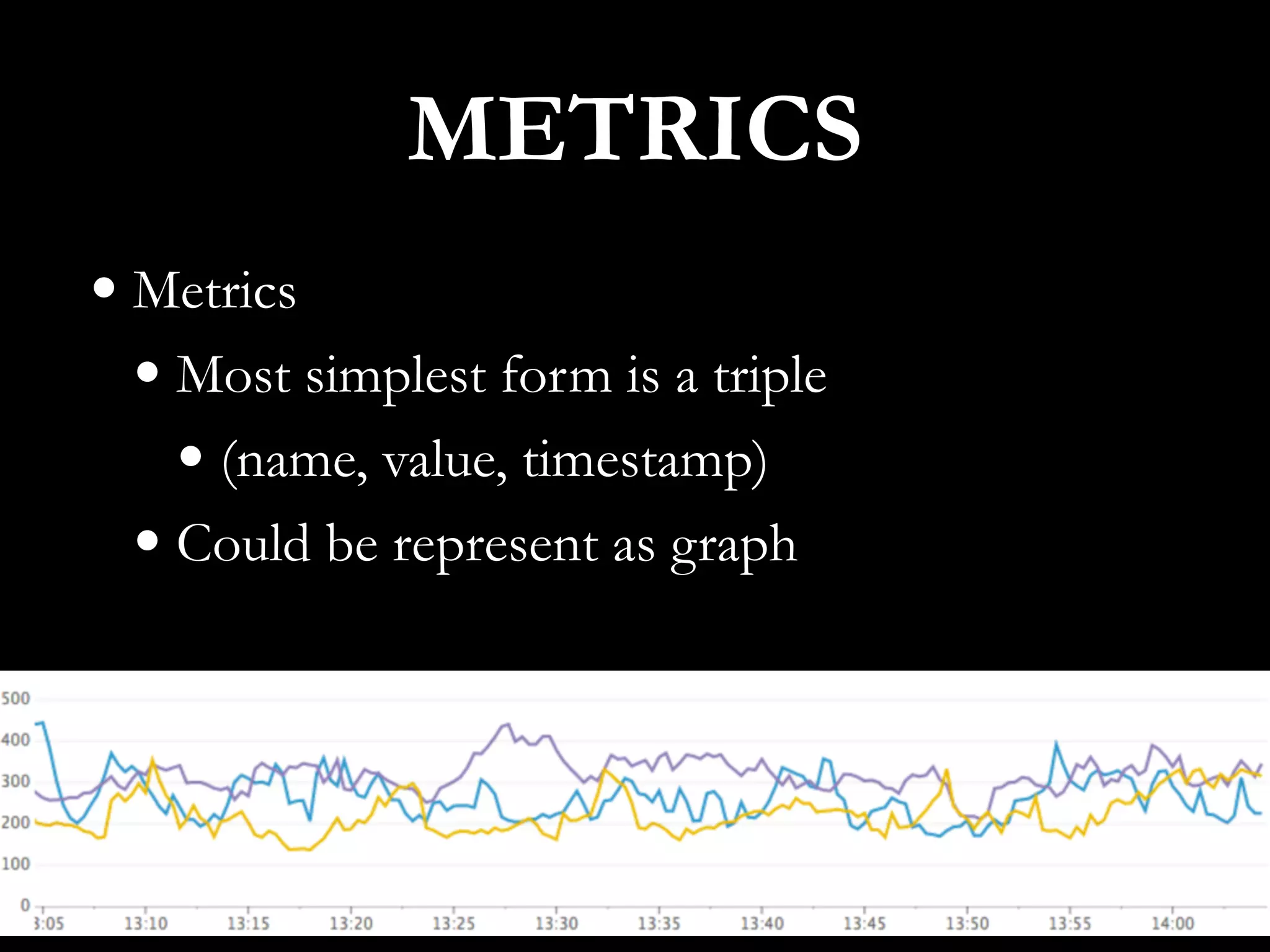



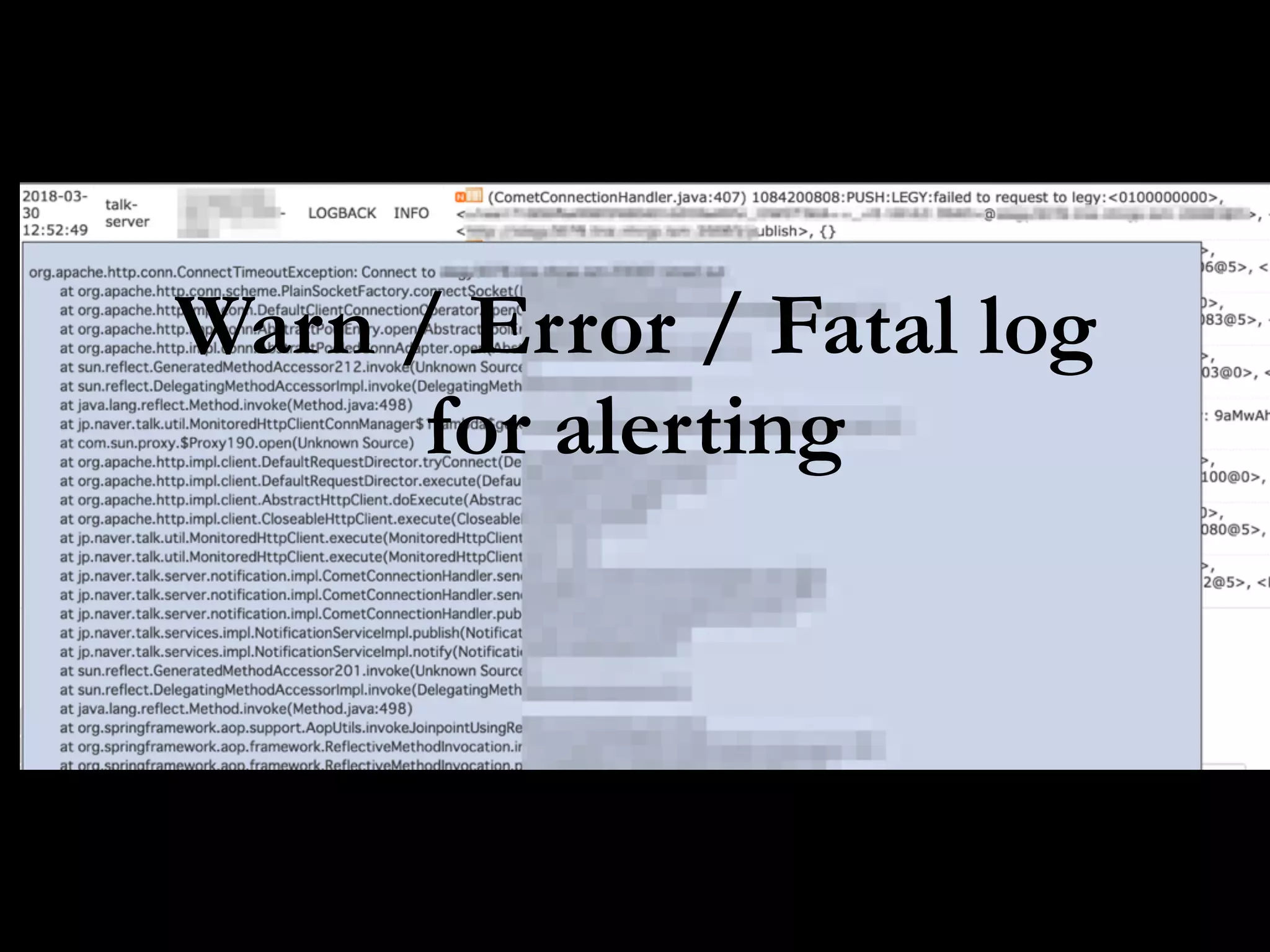


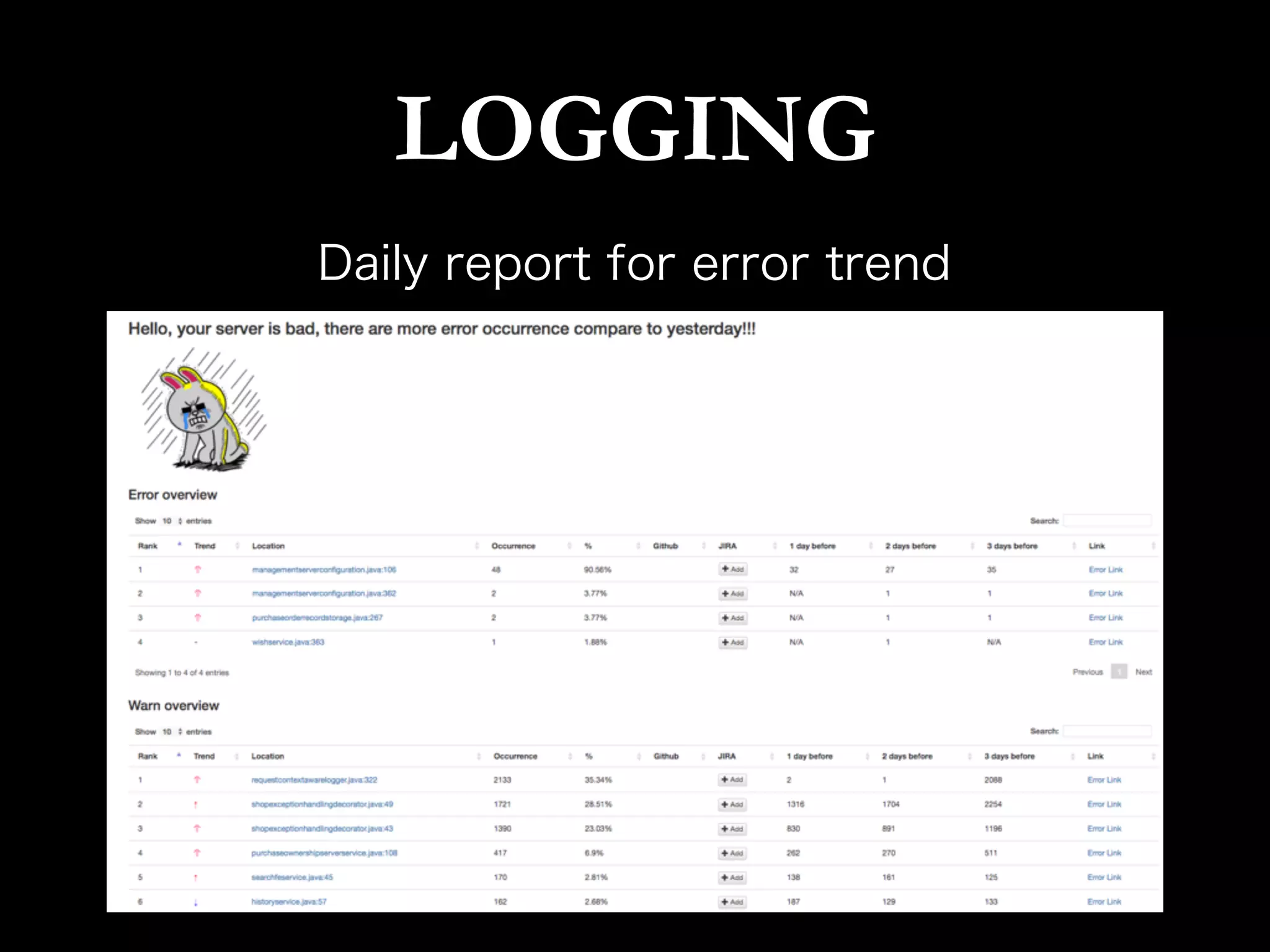


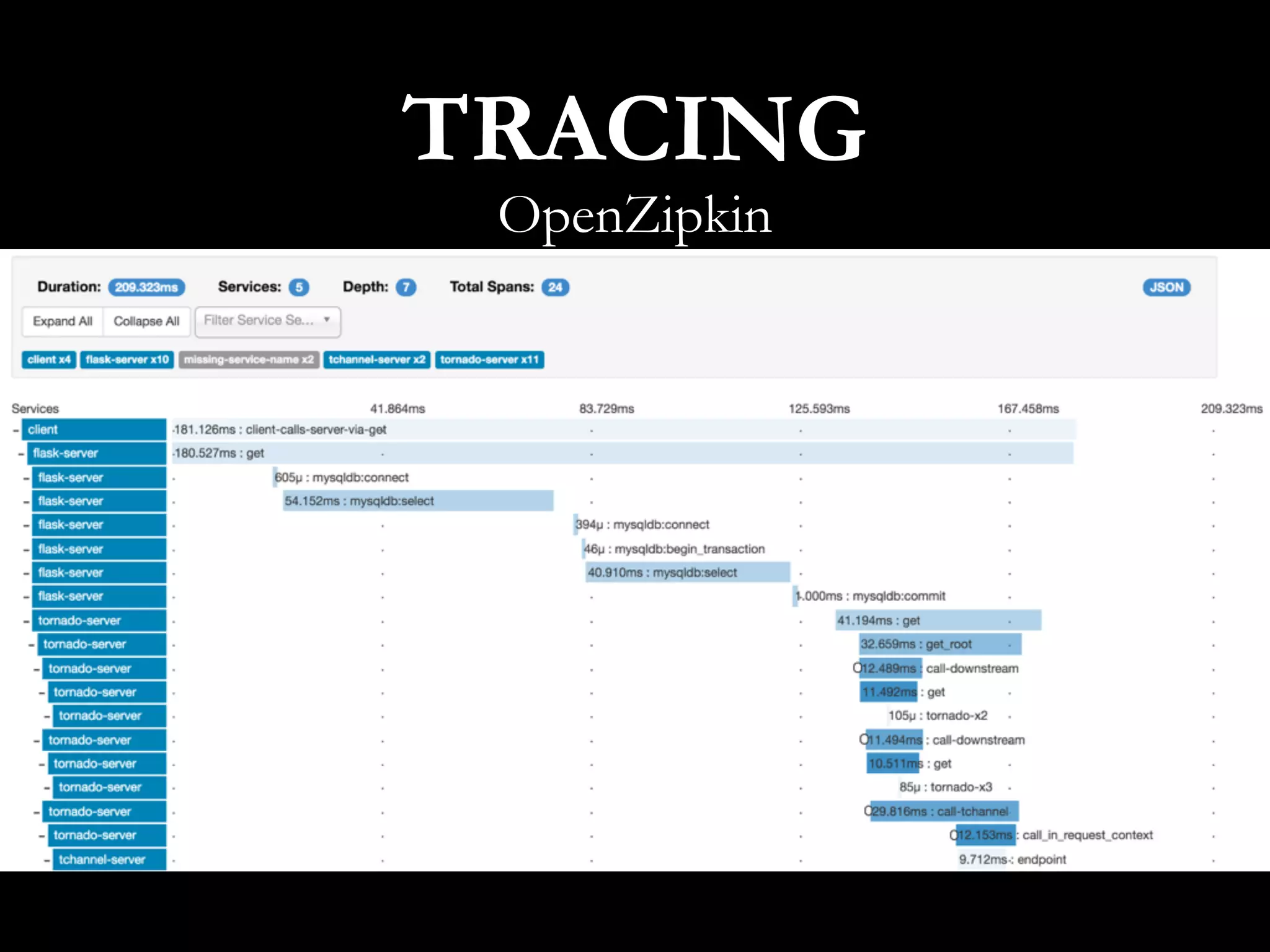





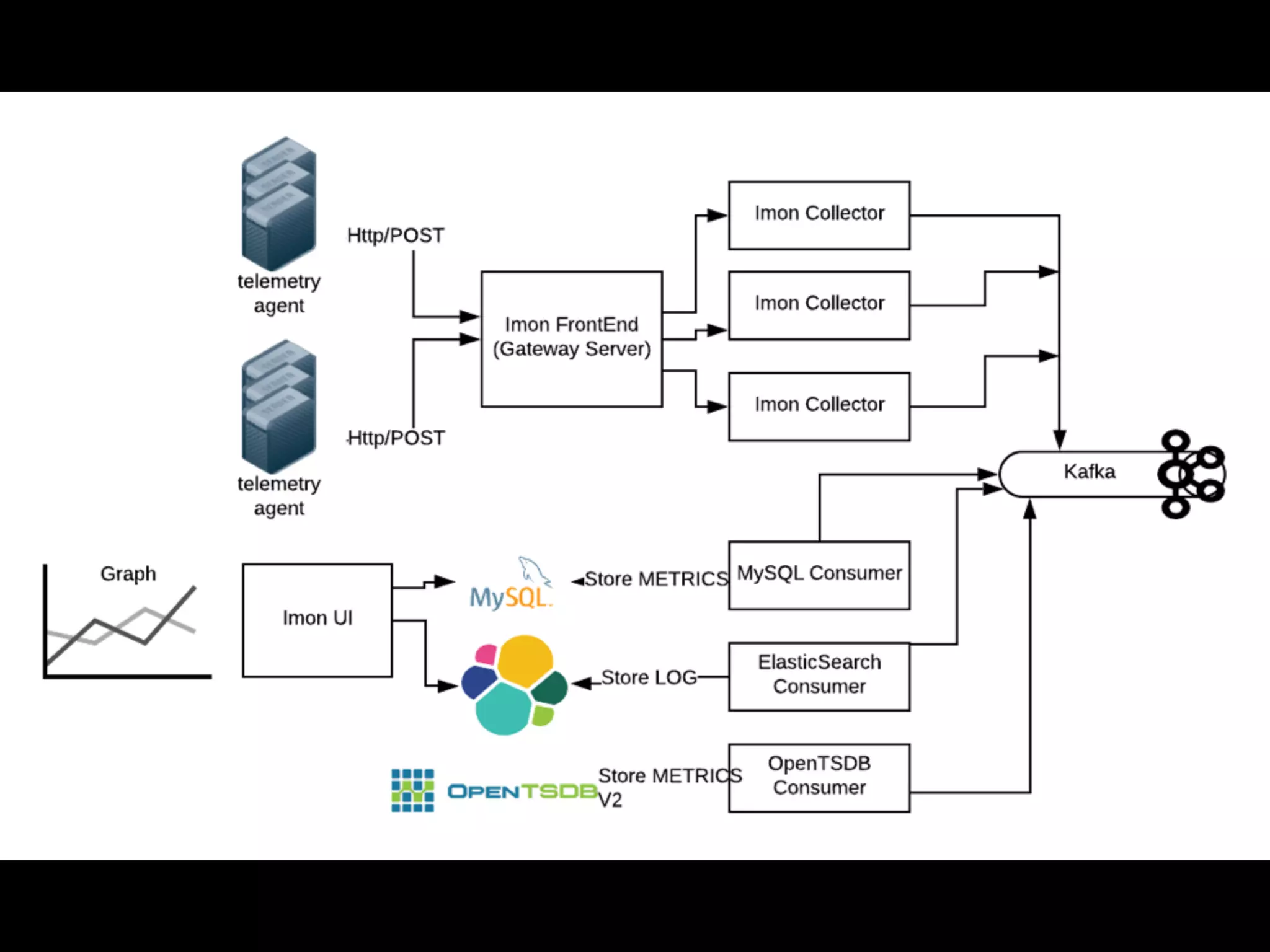










This document discusses metrics driven development from an observability perspective at LINE Corp. It summarizes LINE's observability stack, which includes metrics, logging, and tracing to monitor user experience and reliability across its many services and 170M users. The stack called IMON aggregates millions of metrics and log entries per minute from thousands of servers. Engineers are responsible for monitoring their applications and are required to do on-call rotations. Future work includes improving the telemetry system and driving an autonomous, data-driven engineering culture focused on stability.














![[Old] Site24x7 Real Browser Monitoring](https://cdn.slidesharecdn.com/ss_thumbnails/site24x7-webapp-rbm-slideshare-150916105158-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Webinar] End User Experience Monitoring with Site24x7](https://cdn.slidesharecdn.com/ss_thumbnails/enduserexperiencemonitoring07thoct2015-151008105654-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)














































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)











