This document discusses distributed tracing at Uber scale. It explains why companies implement distributed tracing, including for distributed transaction monitoring, performance optimization, root cause analysis, and service dependency analysis. It also discusses challenges with instrumentation and context propagation across services. Finally, it outlines strategies Uber used to encourage adoption of distributed tracing across many teams, such as appealing to developers' interests and measuring adoption through trace quality scores.









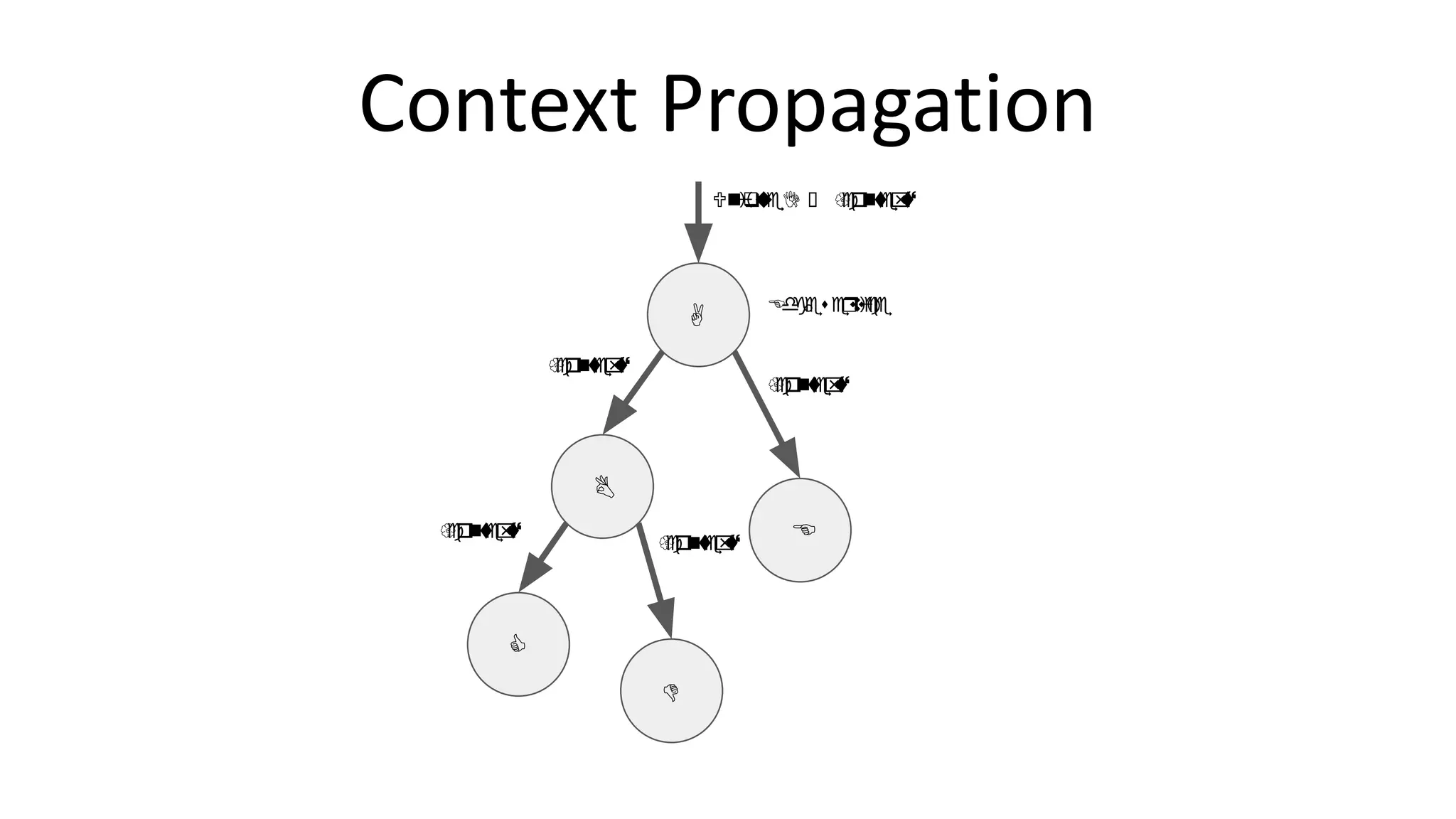
![Headers:
. . .
Trace ID
. . . Instrumentation
APPLICATION / MICROSERVICE
Handler
Context
[Span]
Client
Context
[Span]
Inbound
HTTP
Request
Instrumentation
Headers:
. . .
Trace ID
. . .
Outbound
HTTP
Request
Context Propagation](https://image.slidesharecdn.com/monitorama2017-170525221055/75/Distributed-Tracing-at-UBER-Scale-Creating-a-treasure-map-for-your-monitoring-data-13-2048.jpg)






































![[WSO2Con EU 2018] Tooling for Observability](https://cdn.slidesharecdn.com/ss_thumbnails/toolingforobservability-181114045018-thumbnail.jpg?width=640&height=640&fit=bounds)












































