

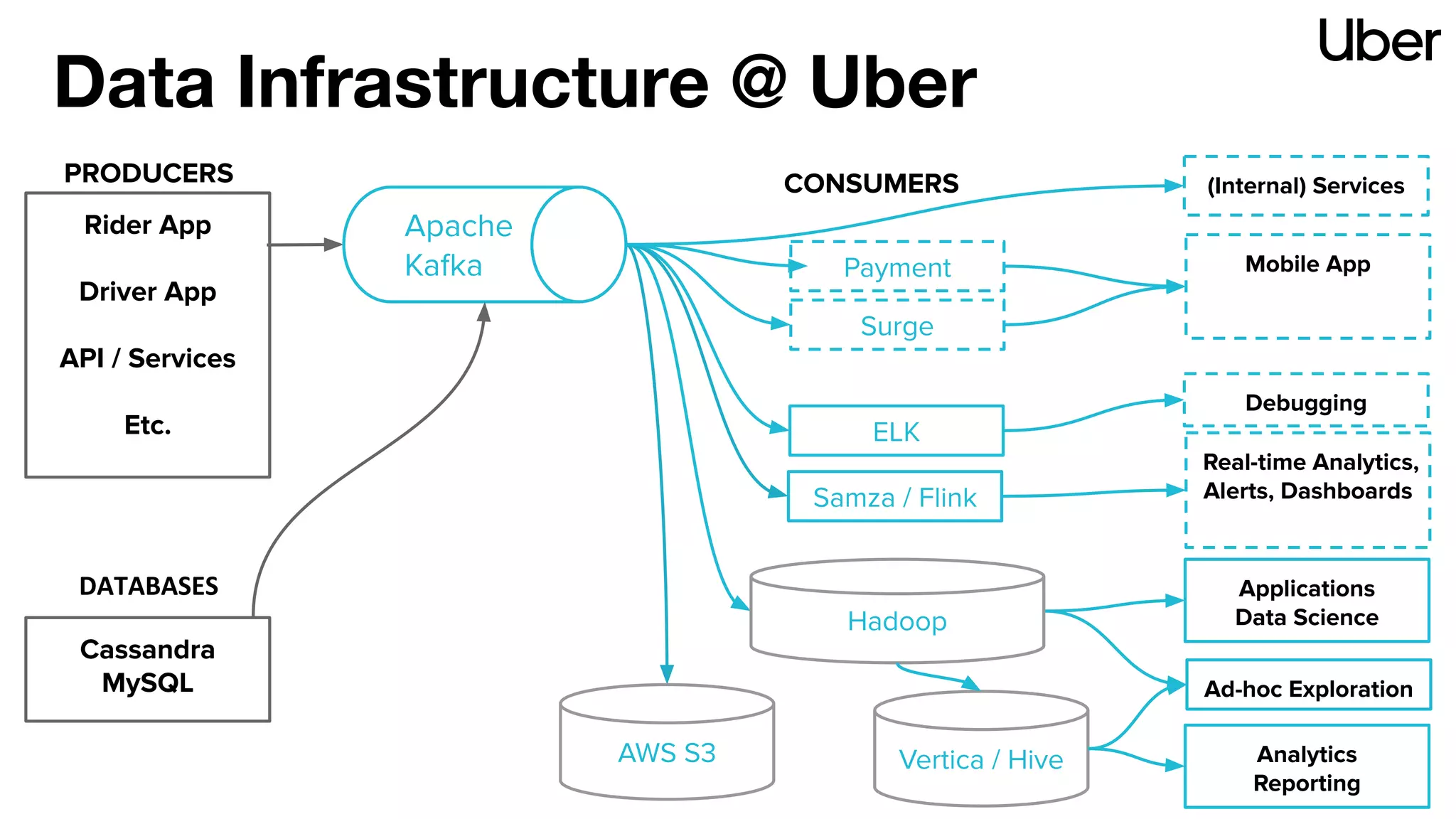
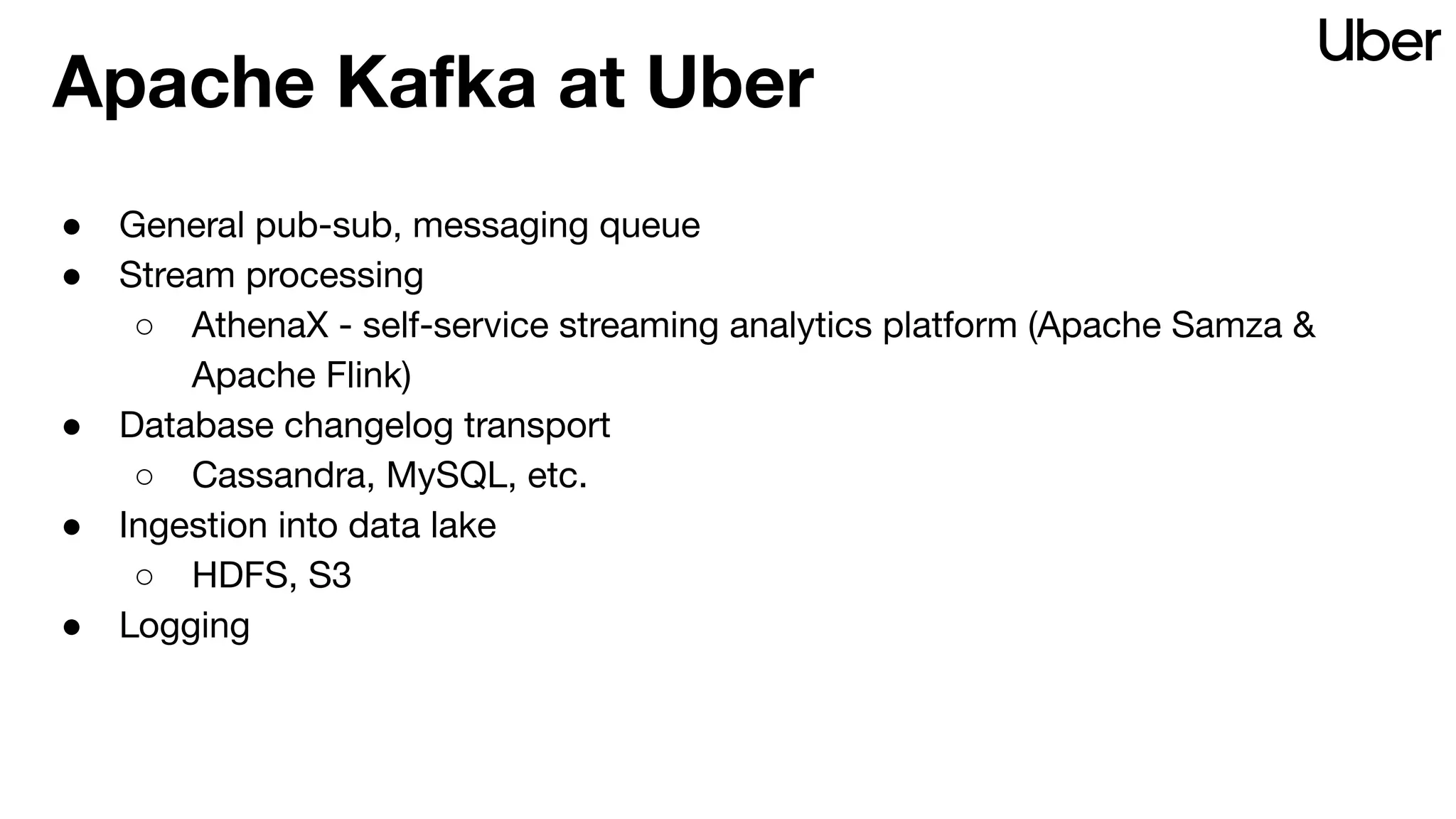


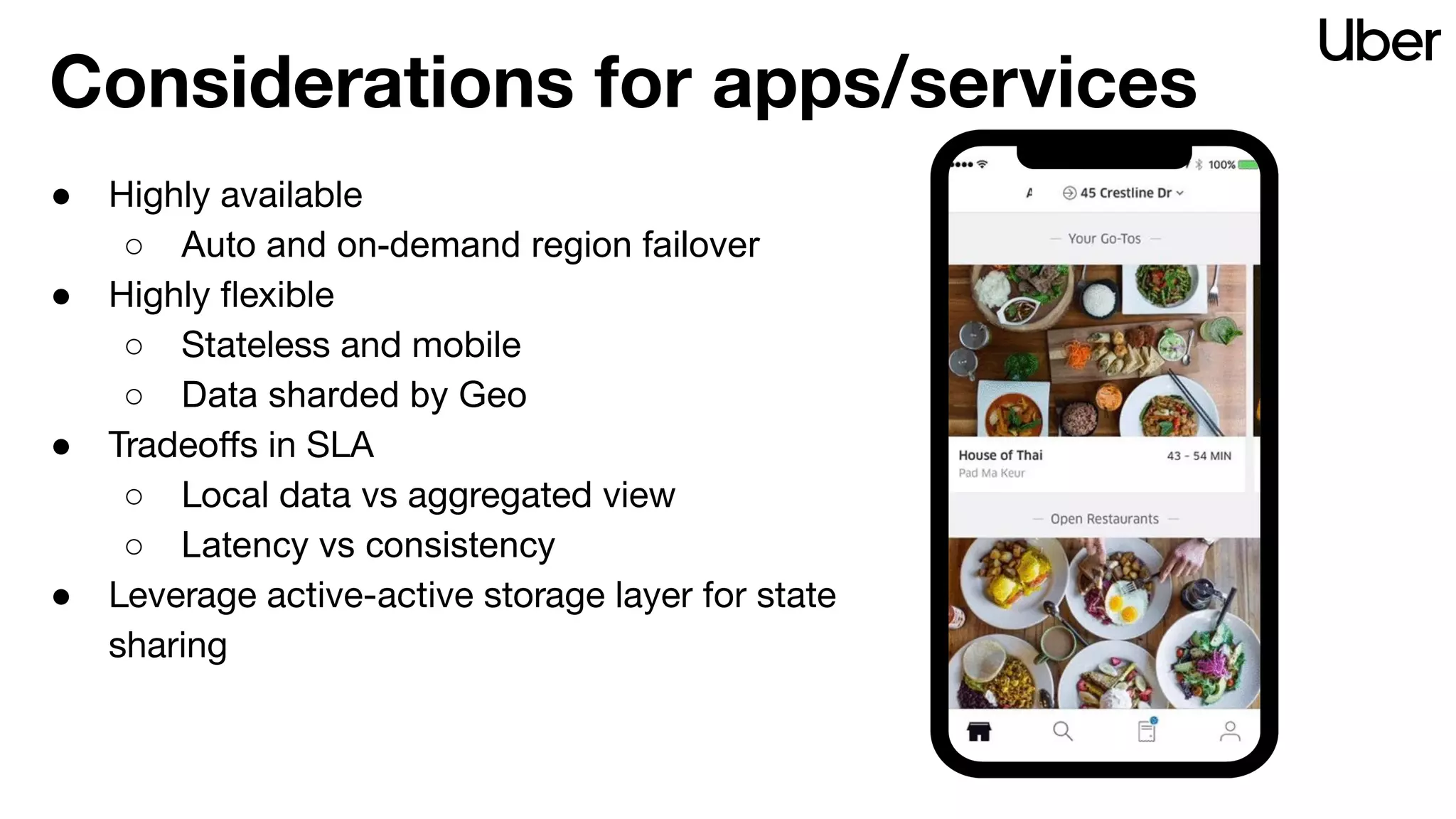
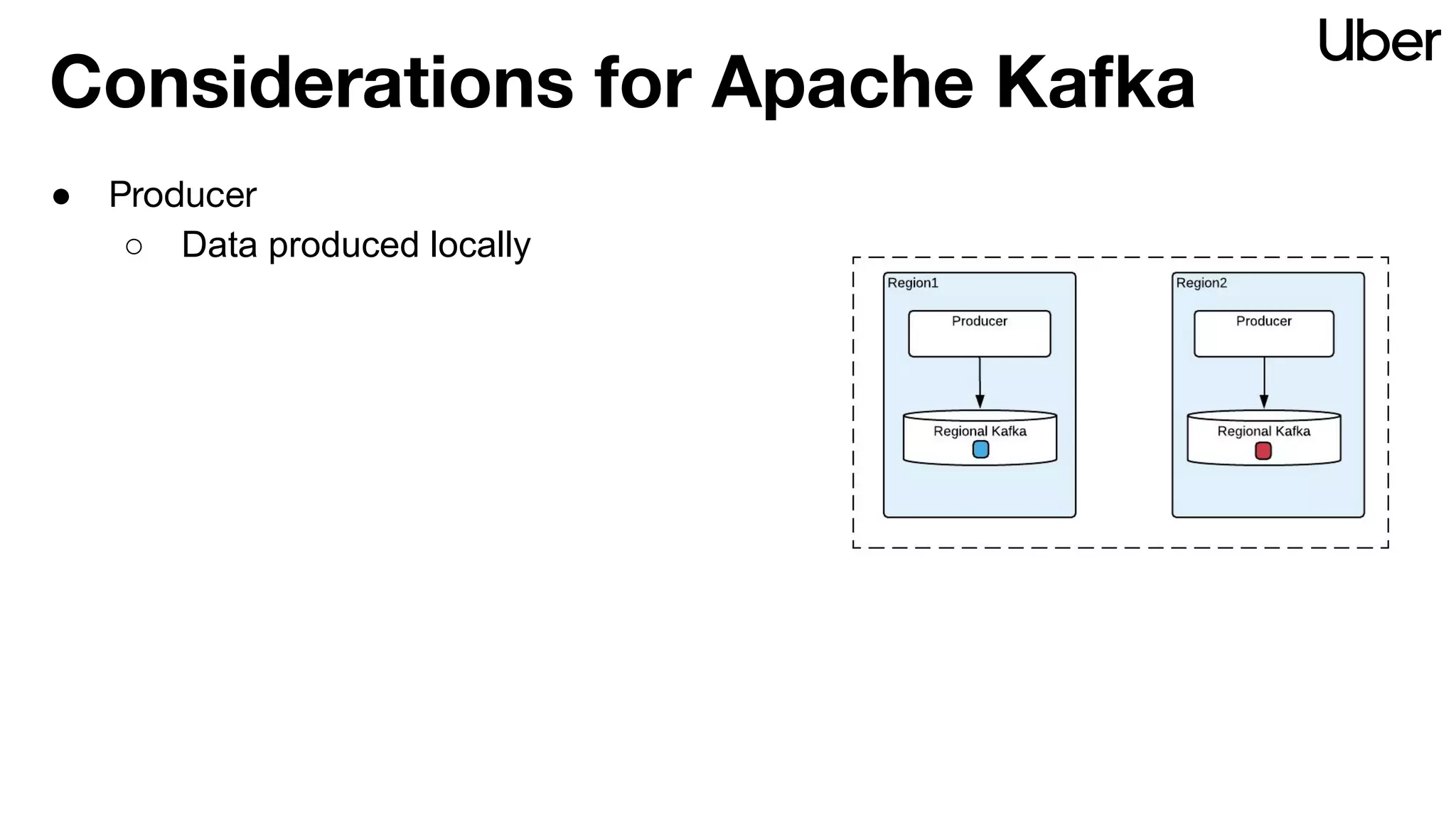
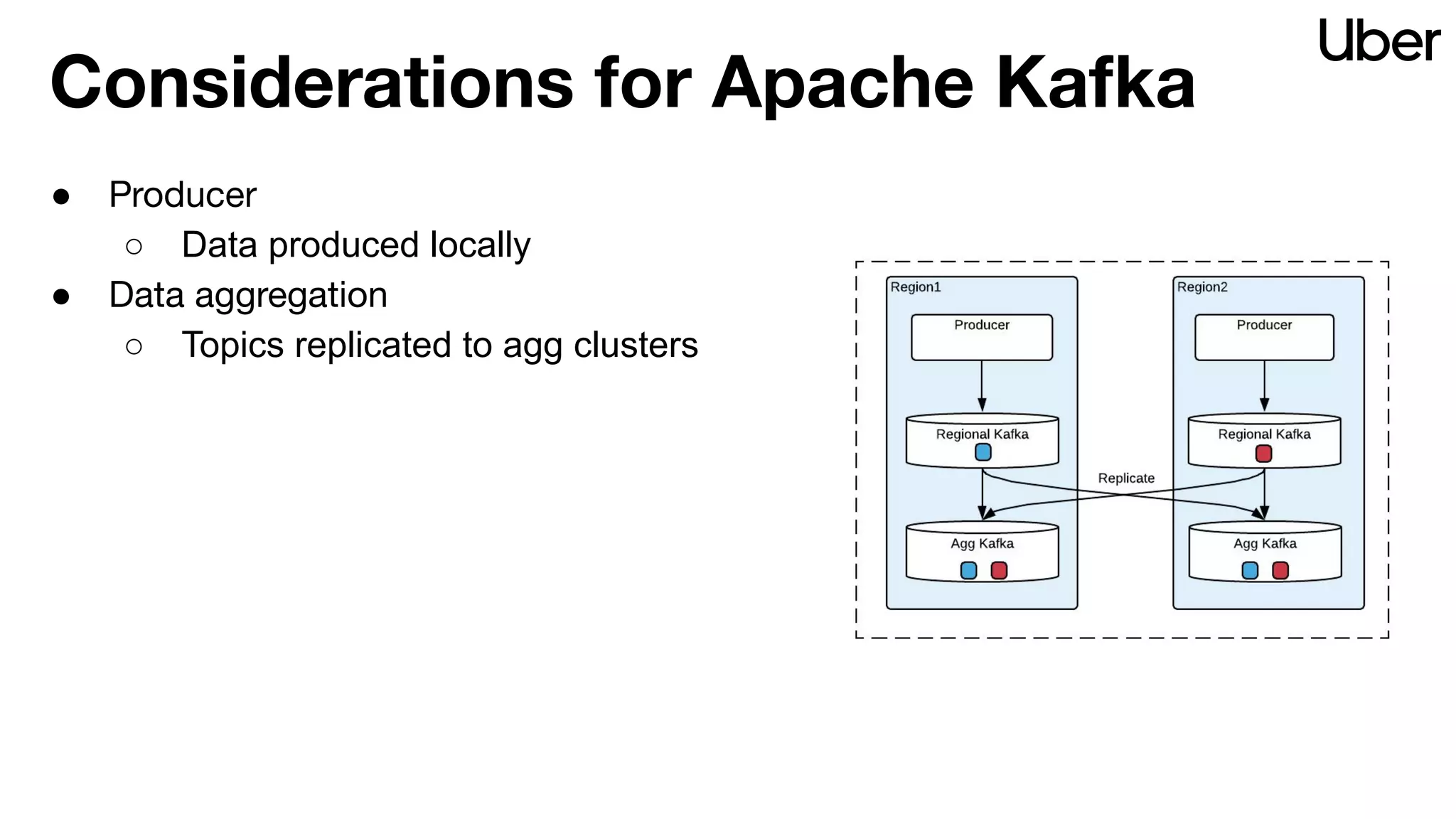
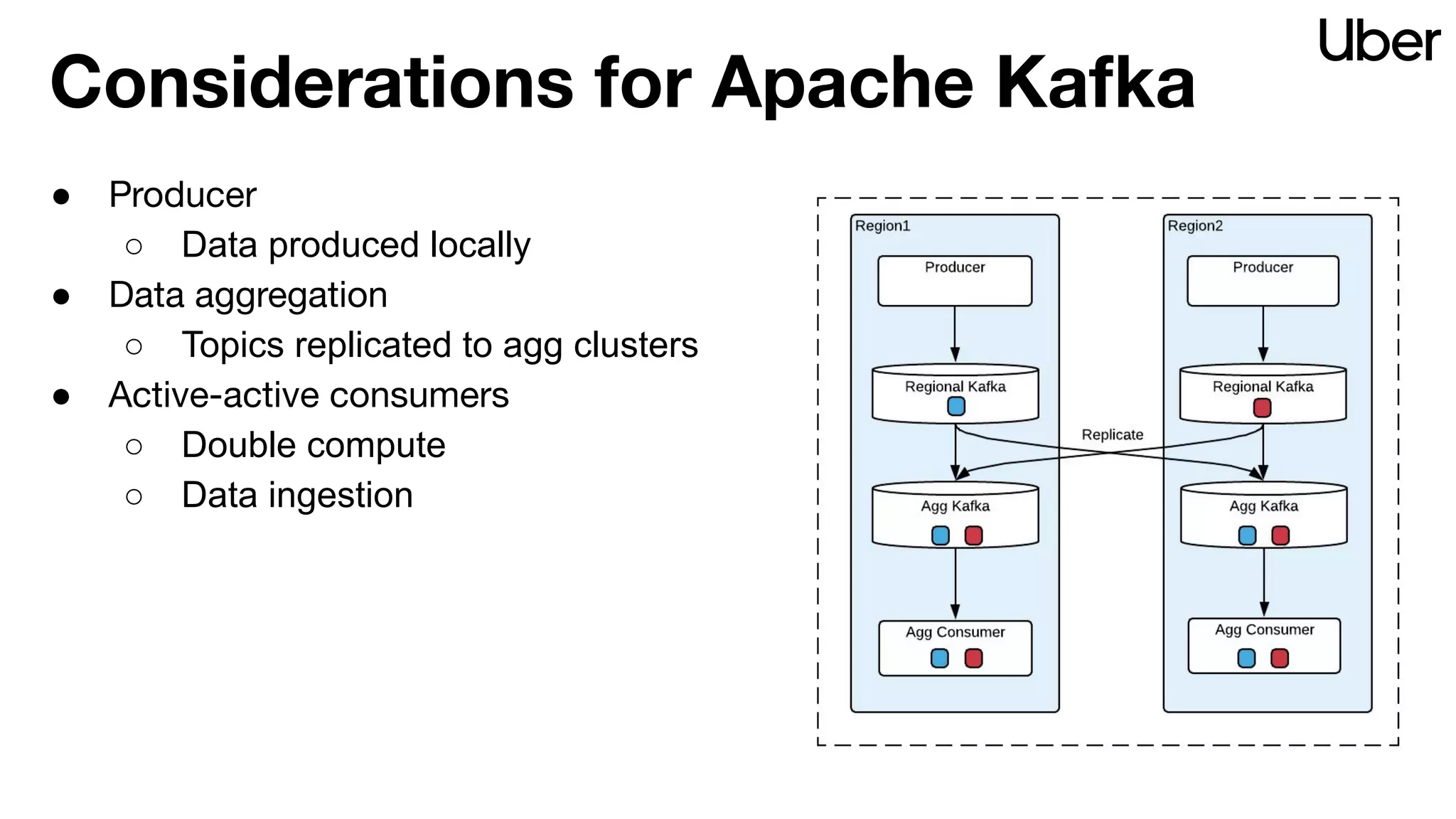

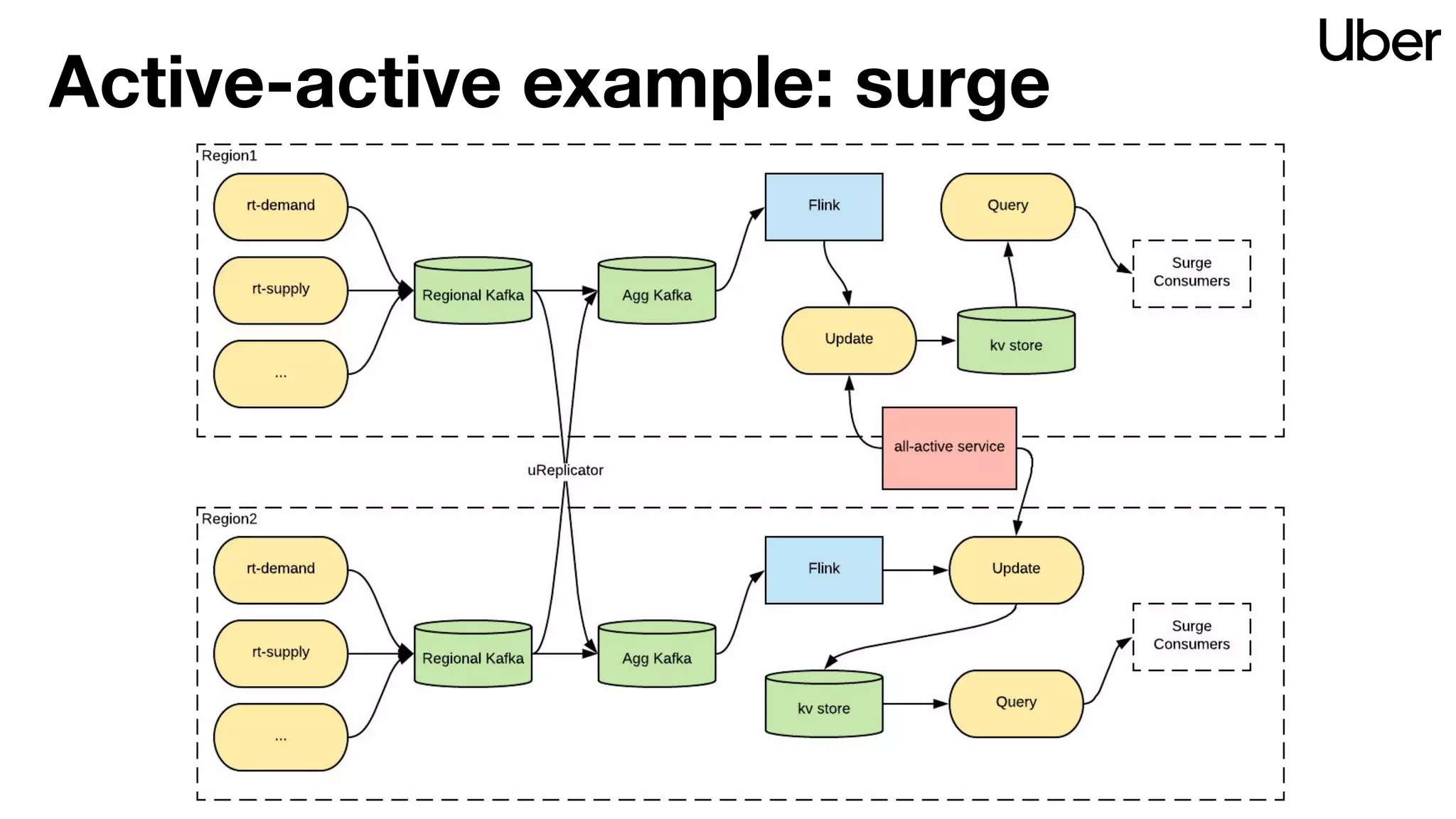

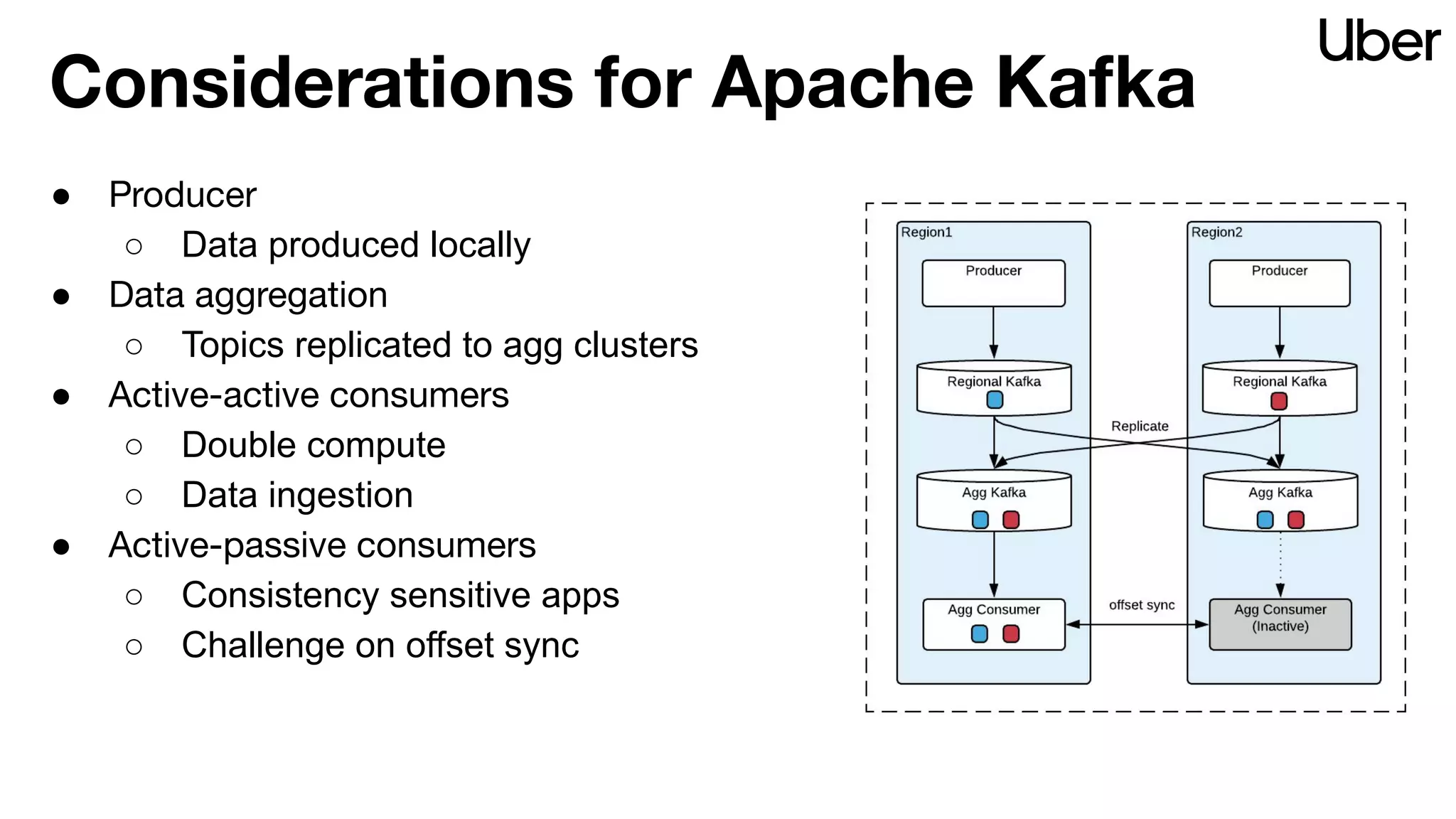
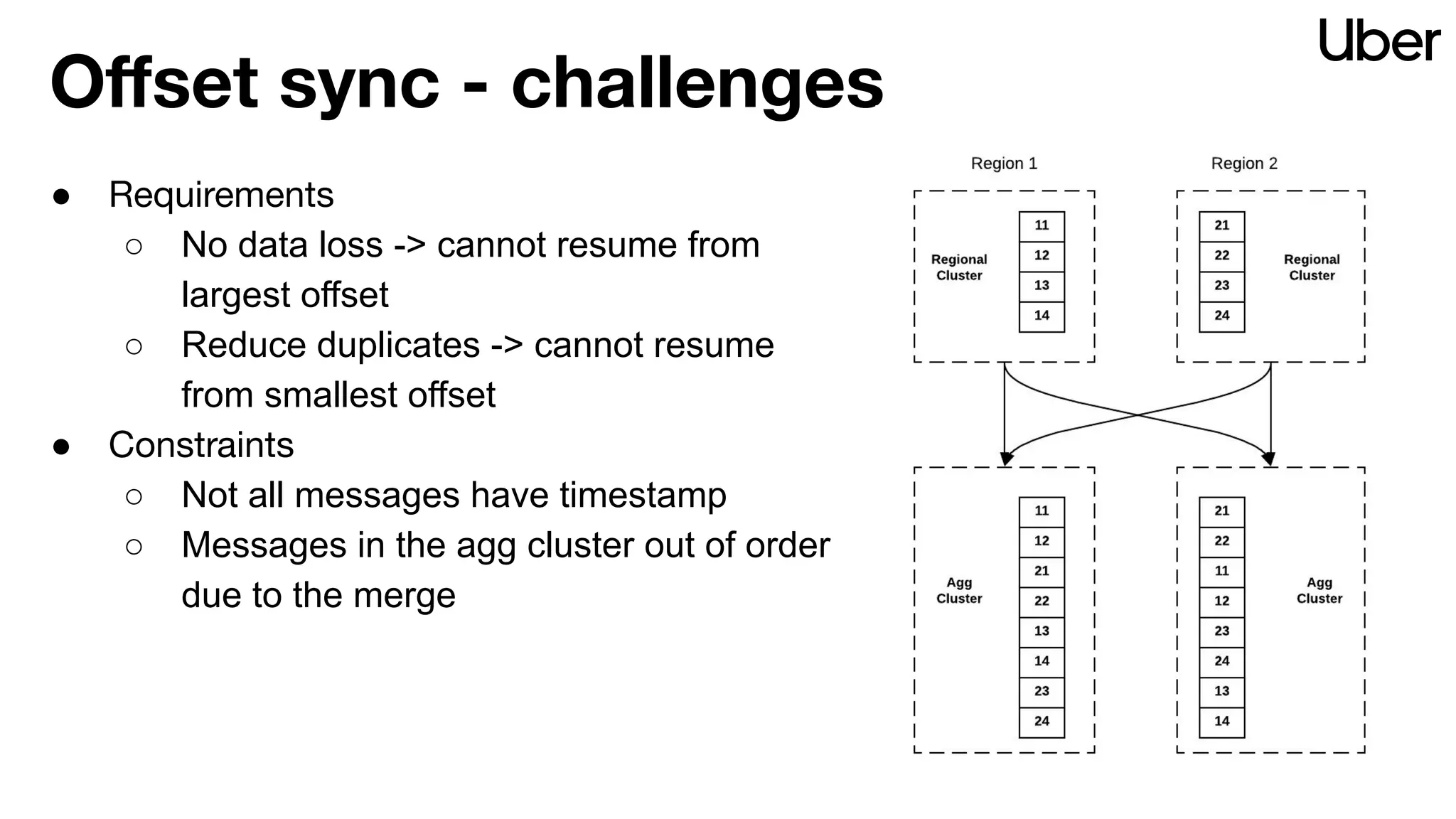

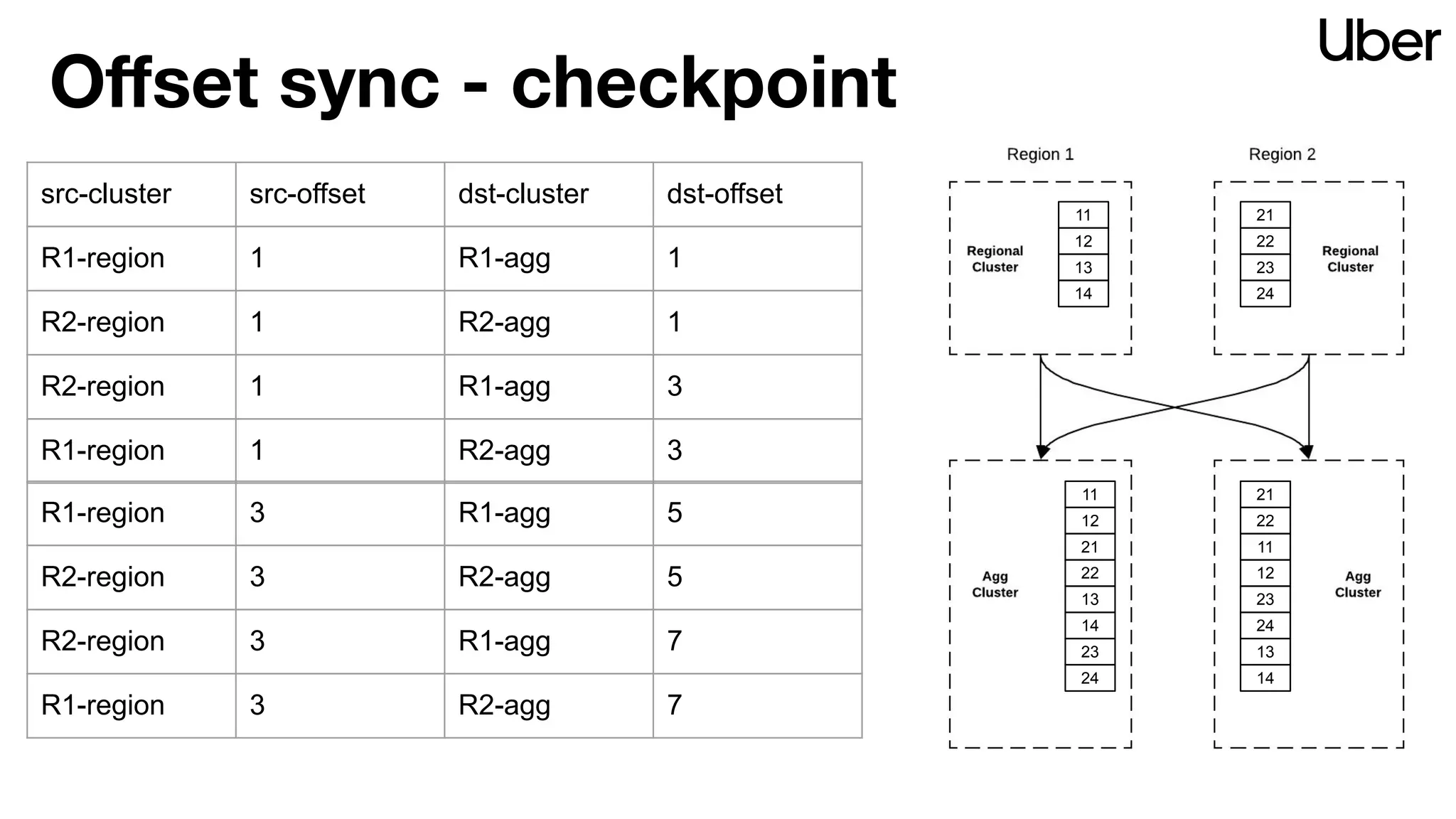
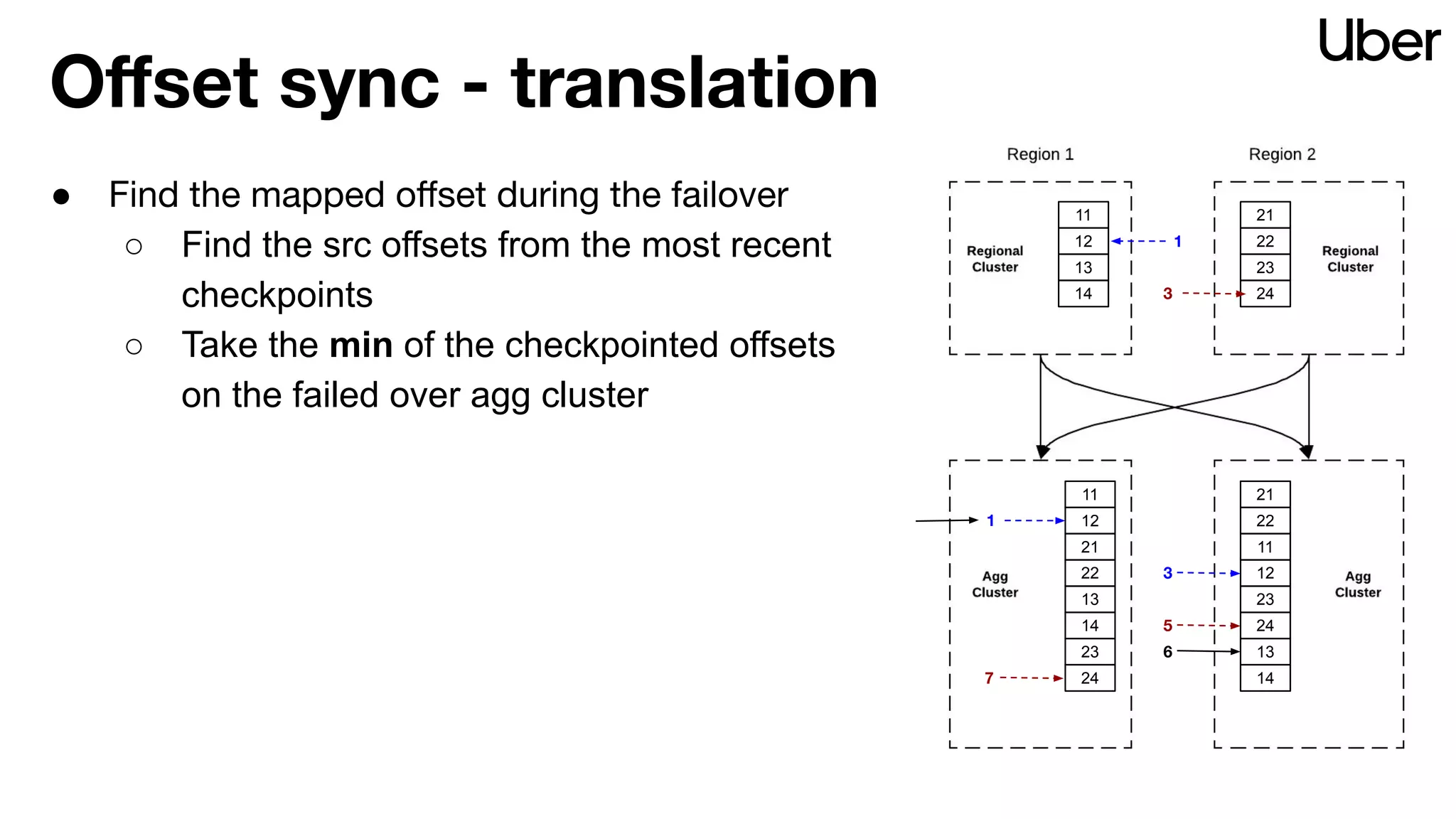



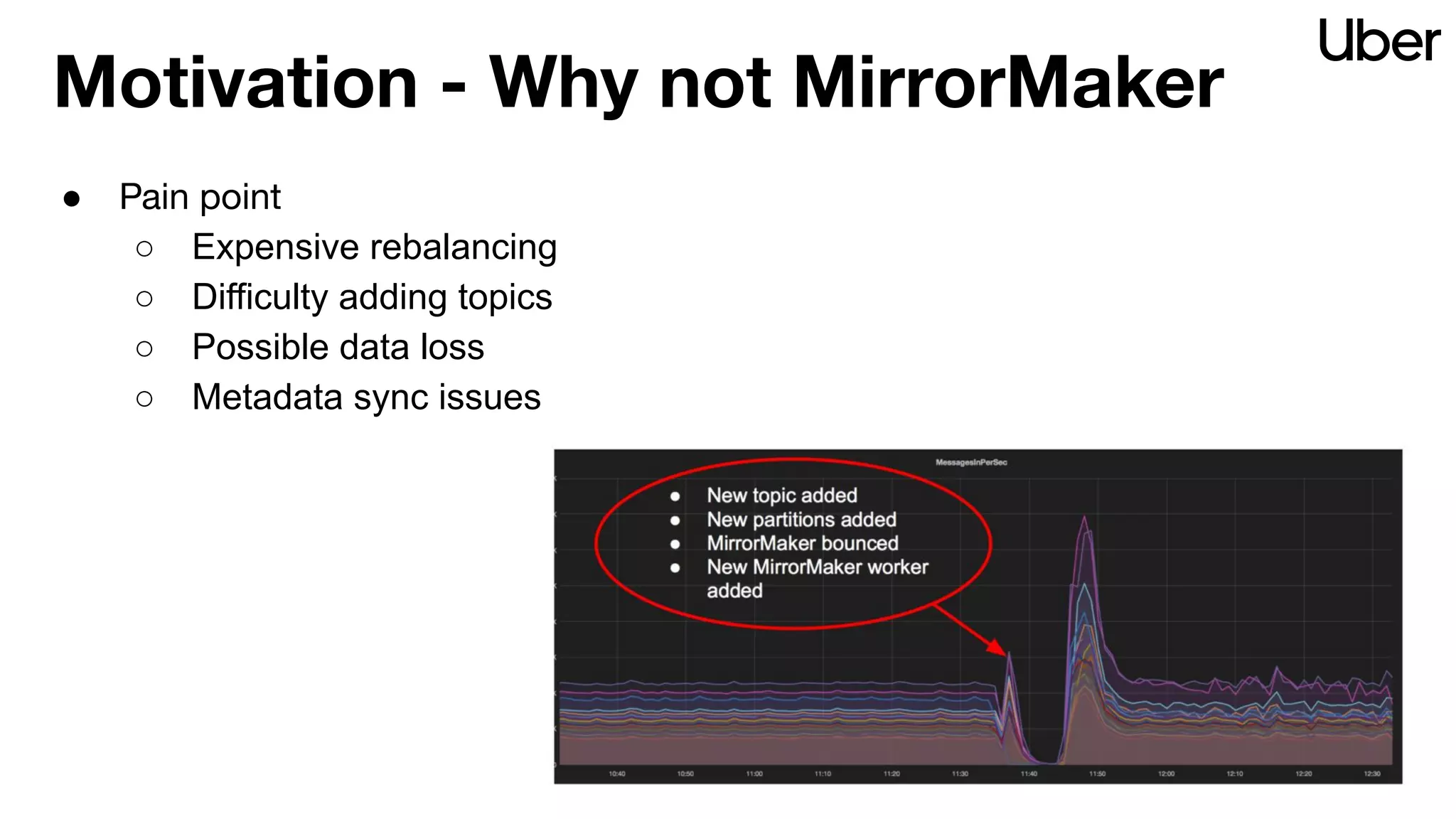

The document outlines Uber's strategy for disaster recovery in multi-region Apache Kafka ecosystems, emphasizing business resilience and seamless user experience. It details the replication service 'ureplicator', focusing on stability, ease of operation, and scalability while addressing offset synchronization challenges. The text also discusses trade-offs between data locality and latency, and outlines the architecture for efficient data ingestion and active-passive configurations.







































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















