Download to read offline




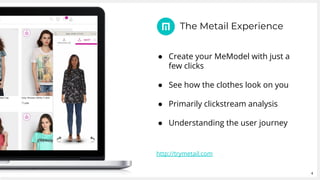


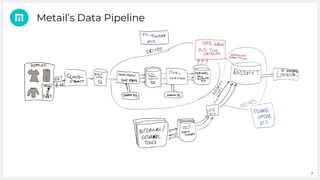
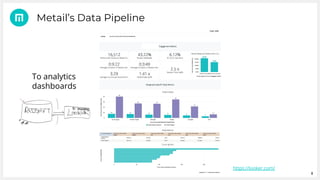



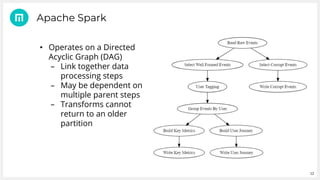



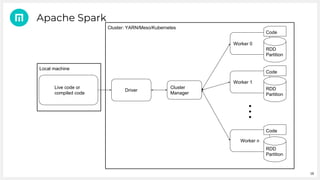




Metail uses Apache Spark and a functional programming approach to process and analyze data from its fashion recommendation application. It collects data through various pipelines to understand user journeys and optimize business processes like photography. Metail's data pipeline is influenced by functional paradigms like immutability and uses Spark on AWS to operate on datasets in a distributed, scalable manner. The presentation demonstrated Metail's use of Clojure, Spark, and AWS services to build a functional data pipeline for analytics purposes.



































































