Downloaded 85 times






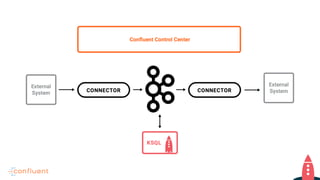





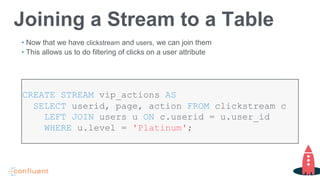







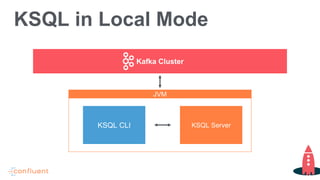

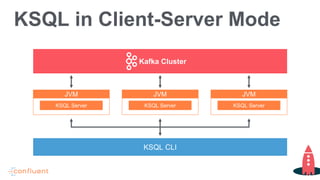

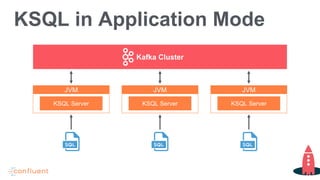





Tim Berglund, a senior director at Confluent, discusses ksql, the streaming SQL engine for Apache Kafka, focusing on its features like stream and table creation, usage patterns for streaming ETL, anomaly detection, and real-time monitoring. The session covers practical examples, including how to create and inspect streams and tables, as well as deployment patterns for ksql. Resources for further exploration are provided, including links to GitHub and the Confluent community.























































































