Download as PDF, PPTX






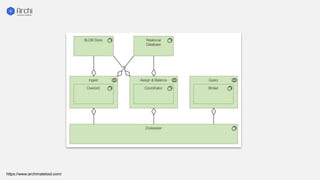

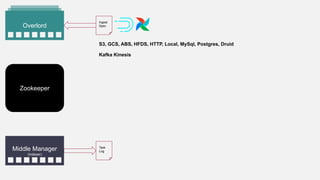

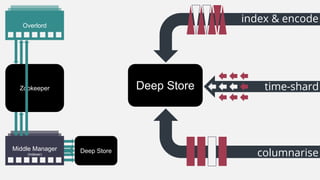


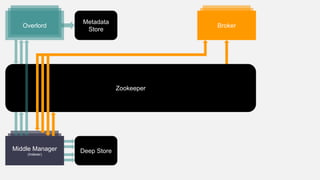
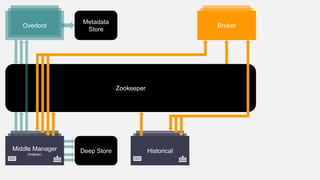
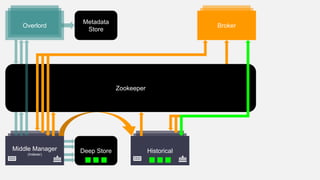
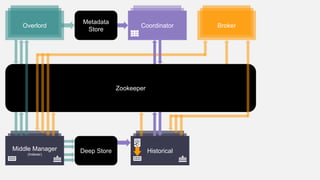
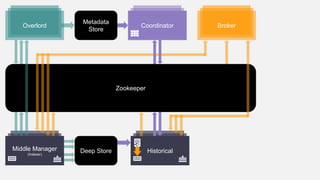
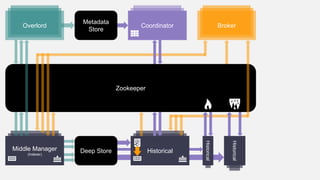
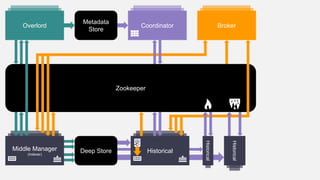
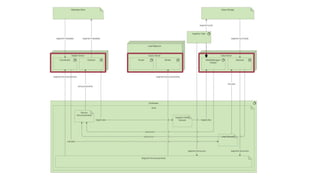

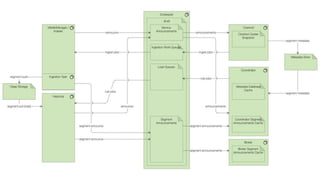
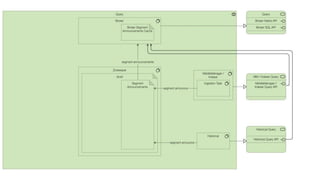
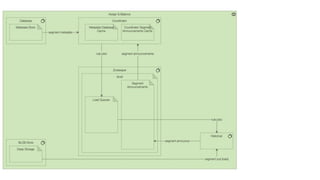
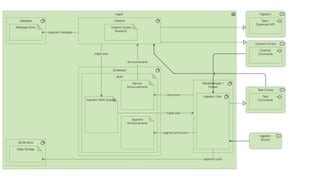





This document summarizes the key components and collaborations in Apache Druid. It describes Zookeeper's role in coordination, the Overlord's role in task management, the Broker's role in query routing, and the Middle Manager's role in ingestion and indexing. It provides diagrams illustrating how these components work together to ingest and store distributed data, and answer queries in a scalable way.

























![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)



























































