



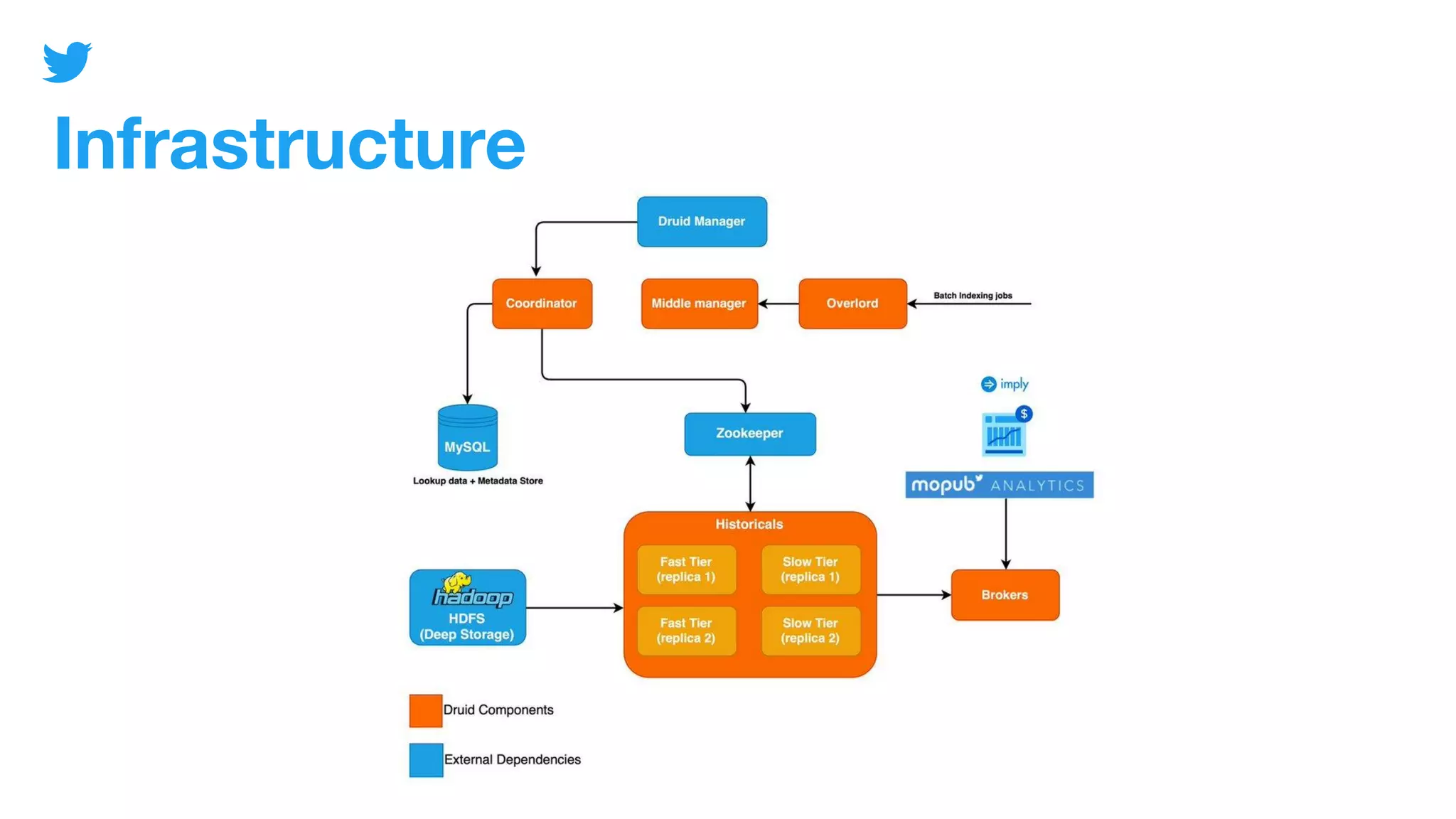
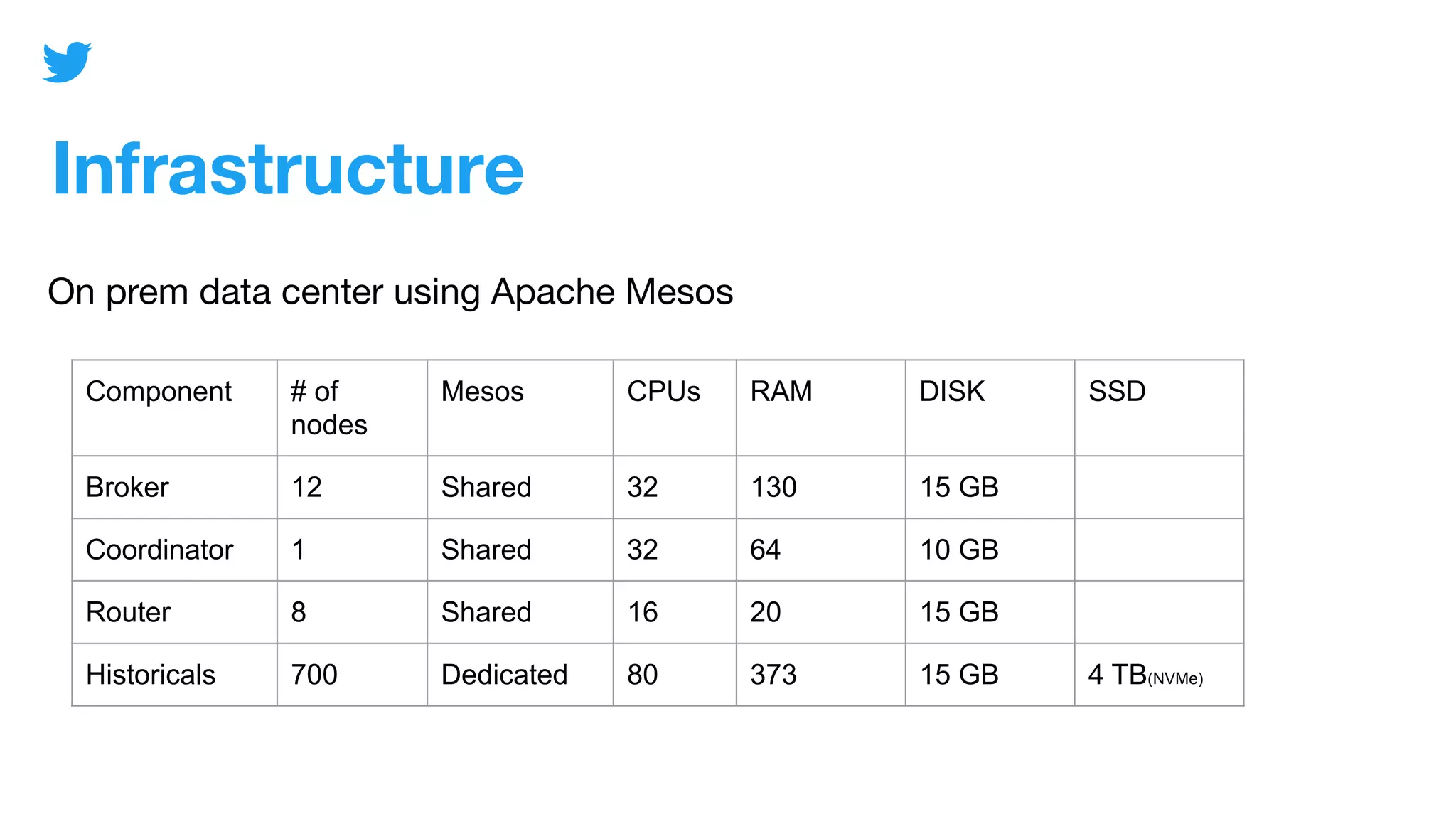




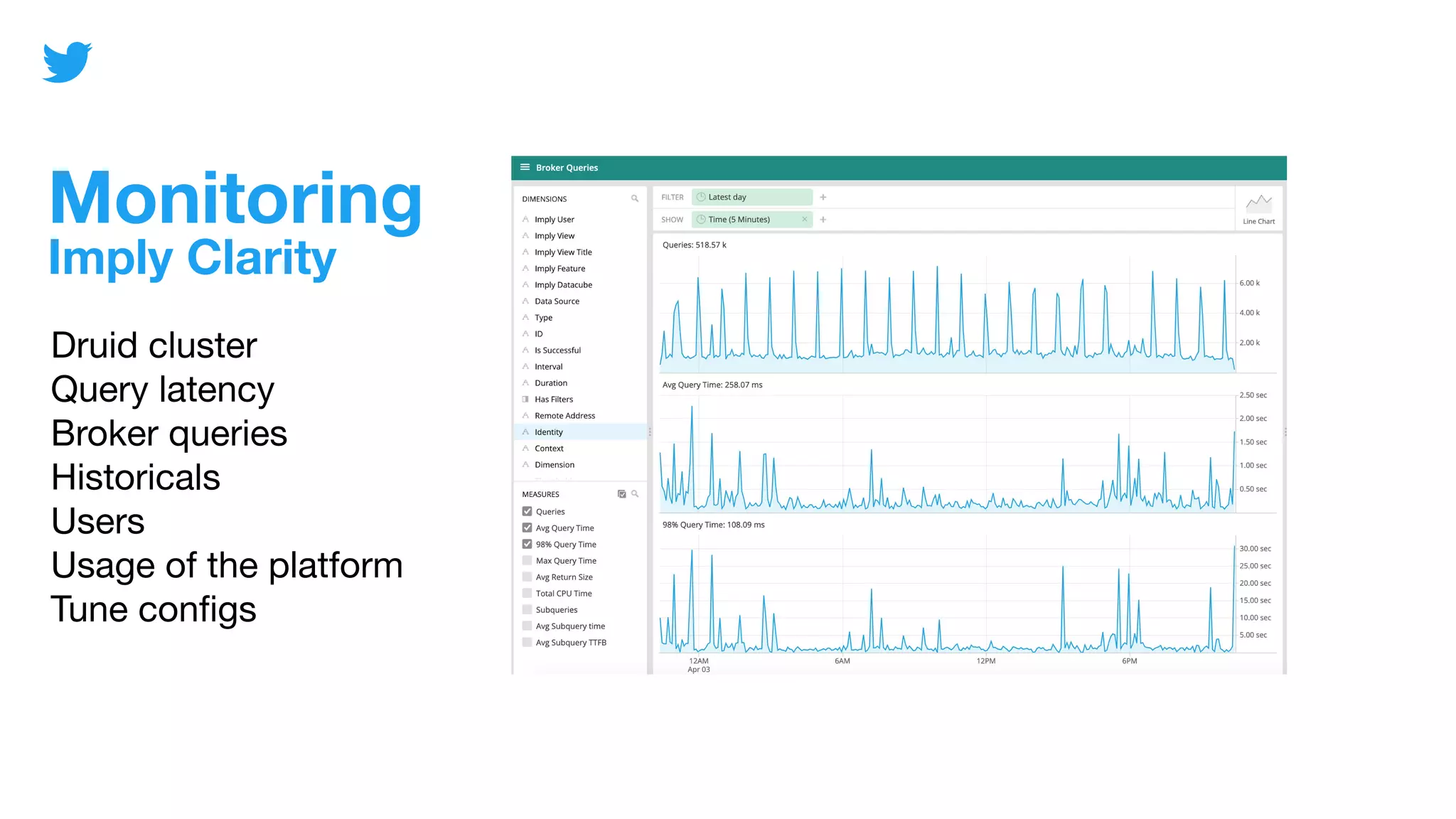










The document discusses Mopub's analytics infrastructure, detailing the handling of over 200 terabytes of raw data daily using Apache Druid. It highlights key components such as monitoring, tiering, and coordinator functionality while outlining performance testing and security measures in place. The presentation also promotes the upcoming Druid Summit event in November 2020.









































































