Downloaded 85 times




















![© Cloudera, Inc. All rights reserved. 31
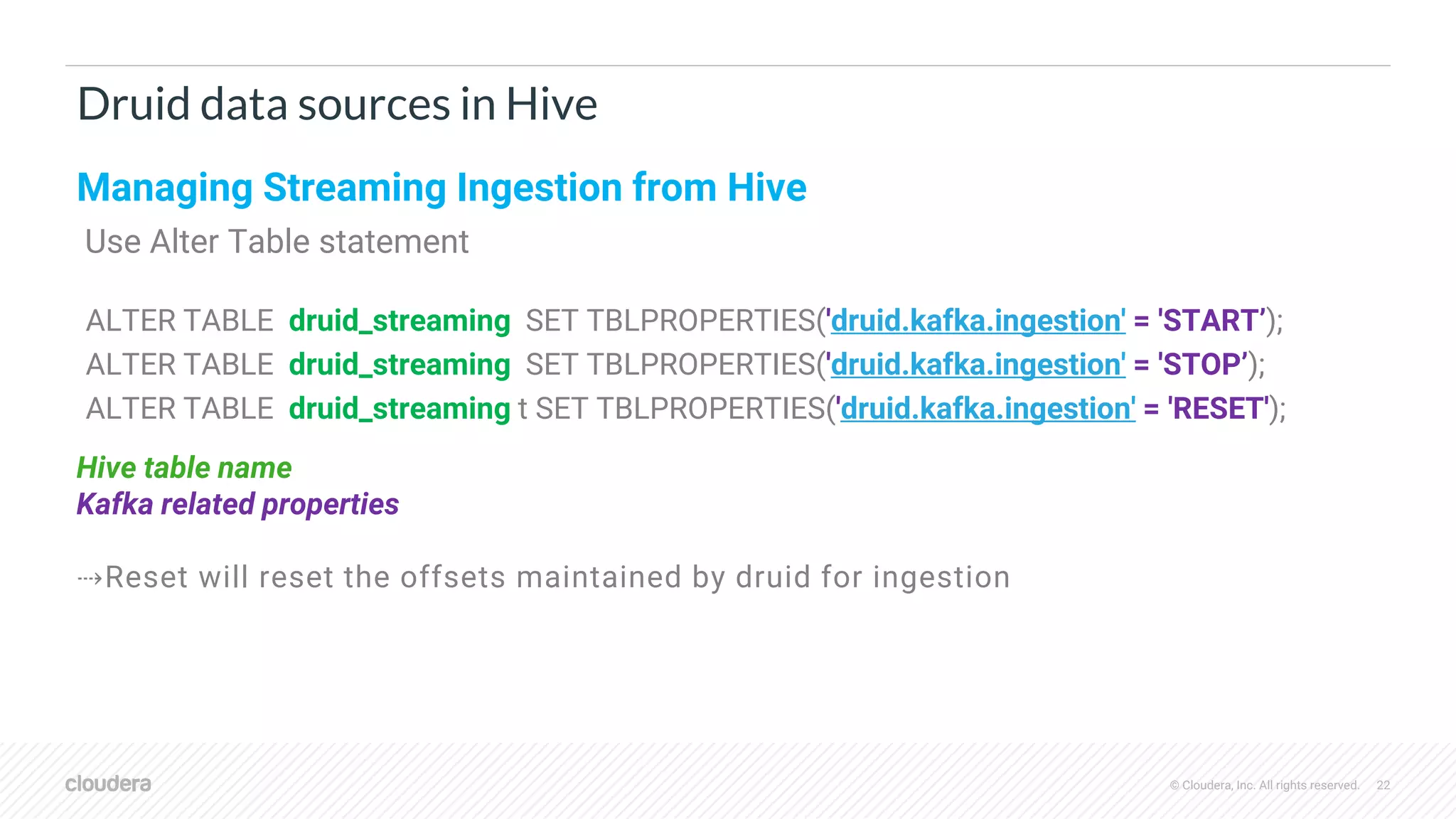
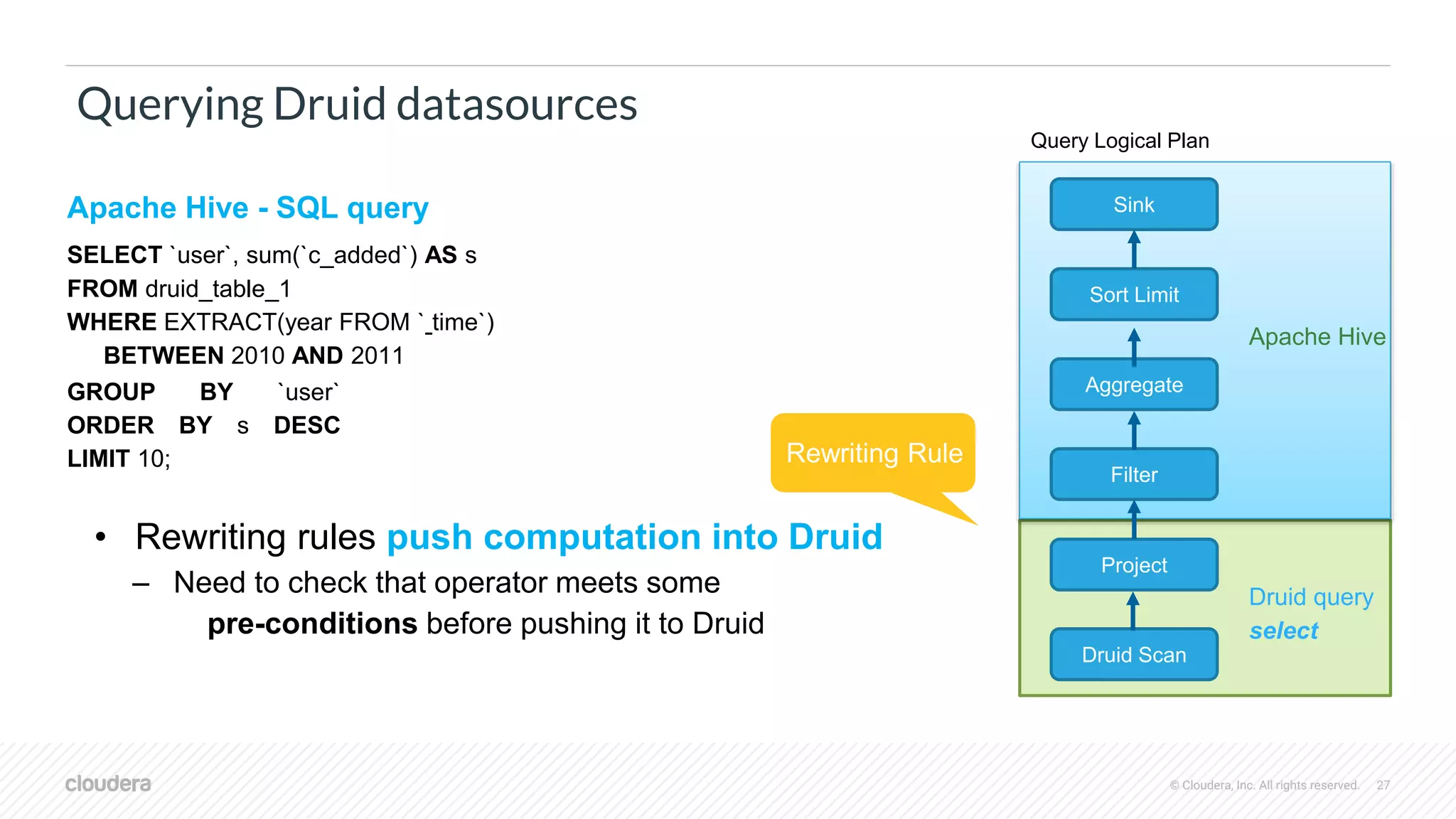
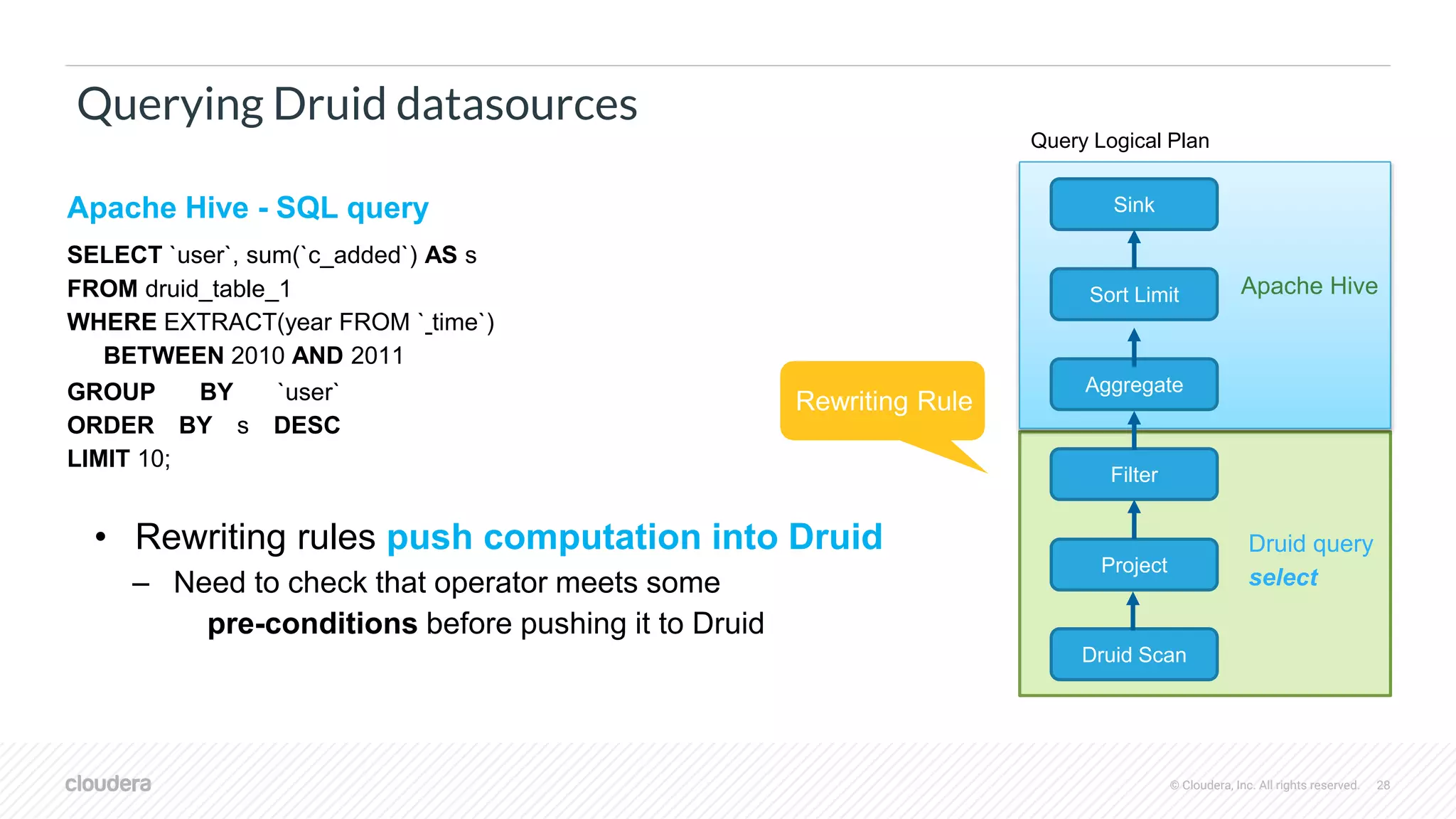
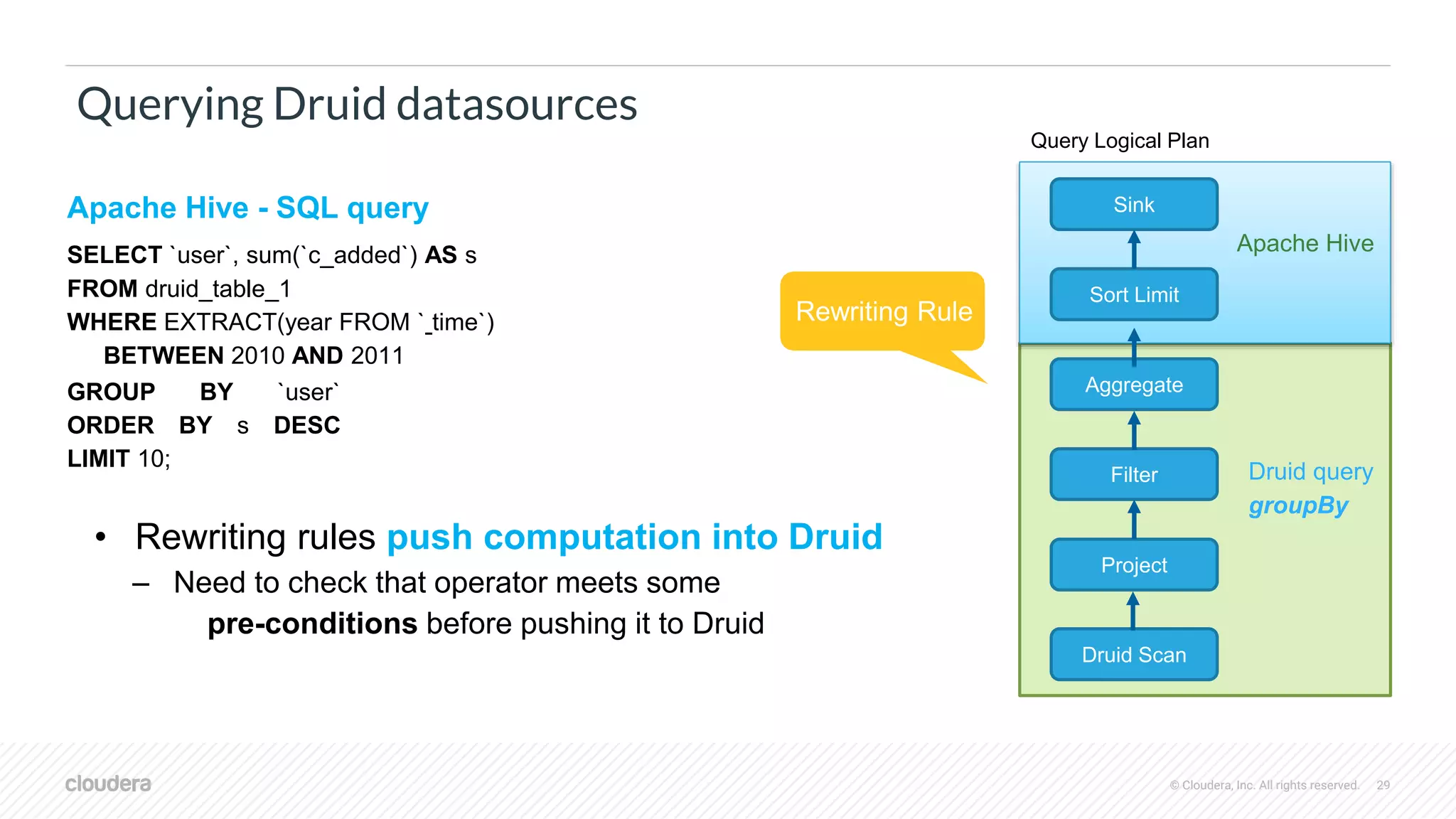
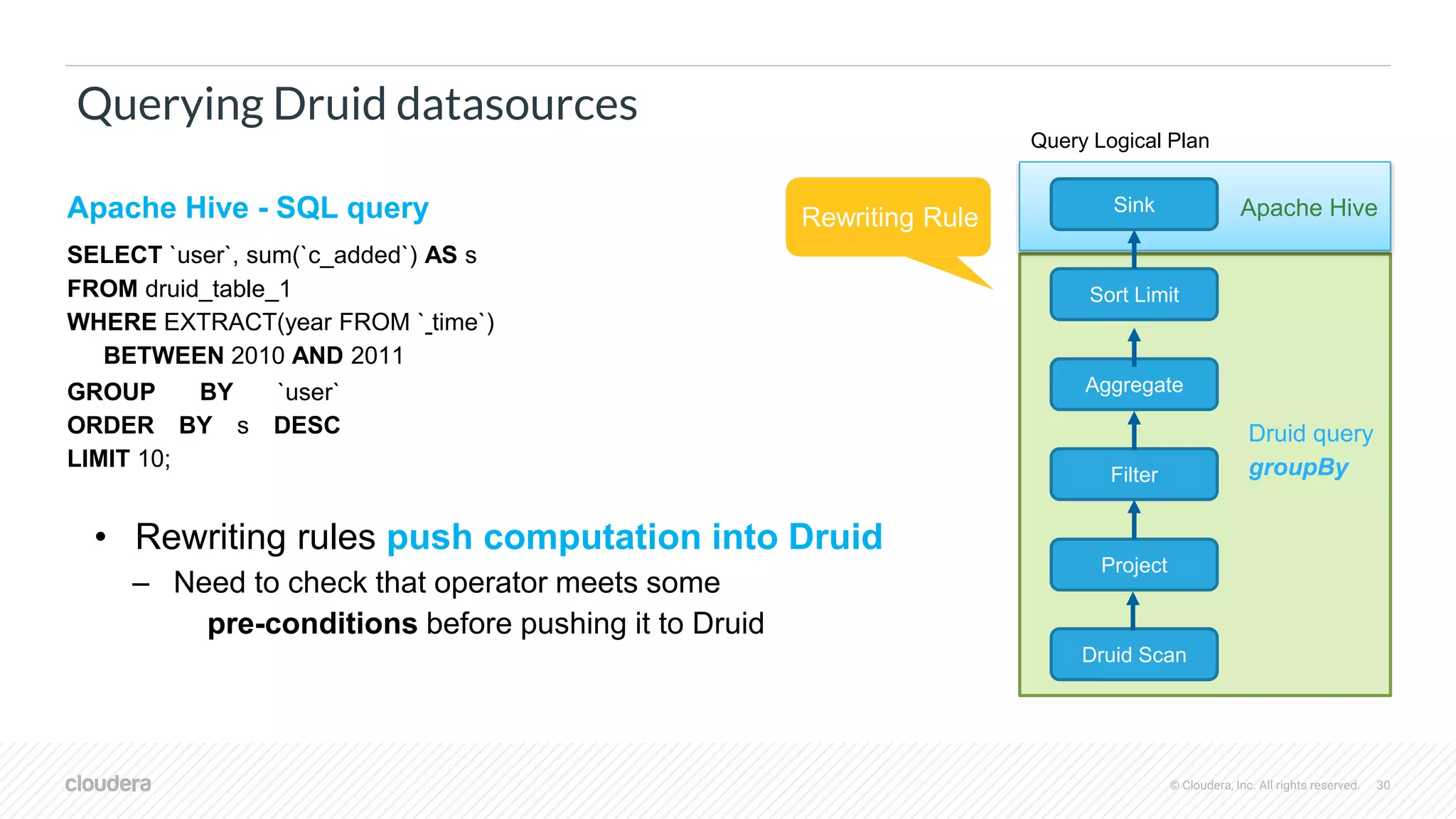
Querying Druid datasources
Filter
Project
Druid Scan
Sink
Sort Limit
Aggregate
Query Logical Plan
Apache Hive
Druid query
groupBy
{
"queryType": "groupBy", DruidJSON
query
"dataSource":
"users_index",
"granularity": "all",
"dimension":
"user",
"aggregations":[ { "type": "longSum","name":"s","fieldName":"c_added"} ],
"limitSpec":{
"limit":10,
"columns":[ {"dimension":"s","direction": "descending"} ]
},
"intervals":[ "2010-01-01T00:00:00.000/2012-01-01T00:00:00.000"]
}
File Sink Druid Scan
Query Physical Plan](https://image.slidesharecdn.com/thurs400pmroom122-123druidandhivetogetherusecasesandbestpracticesnishantbangarwa-190321213845/75/Druid-and-Hive-Together-Use-Cases-and-Best-Practices-30-2048.jpg)



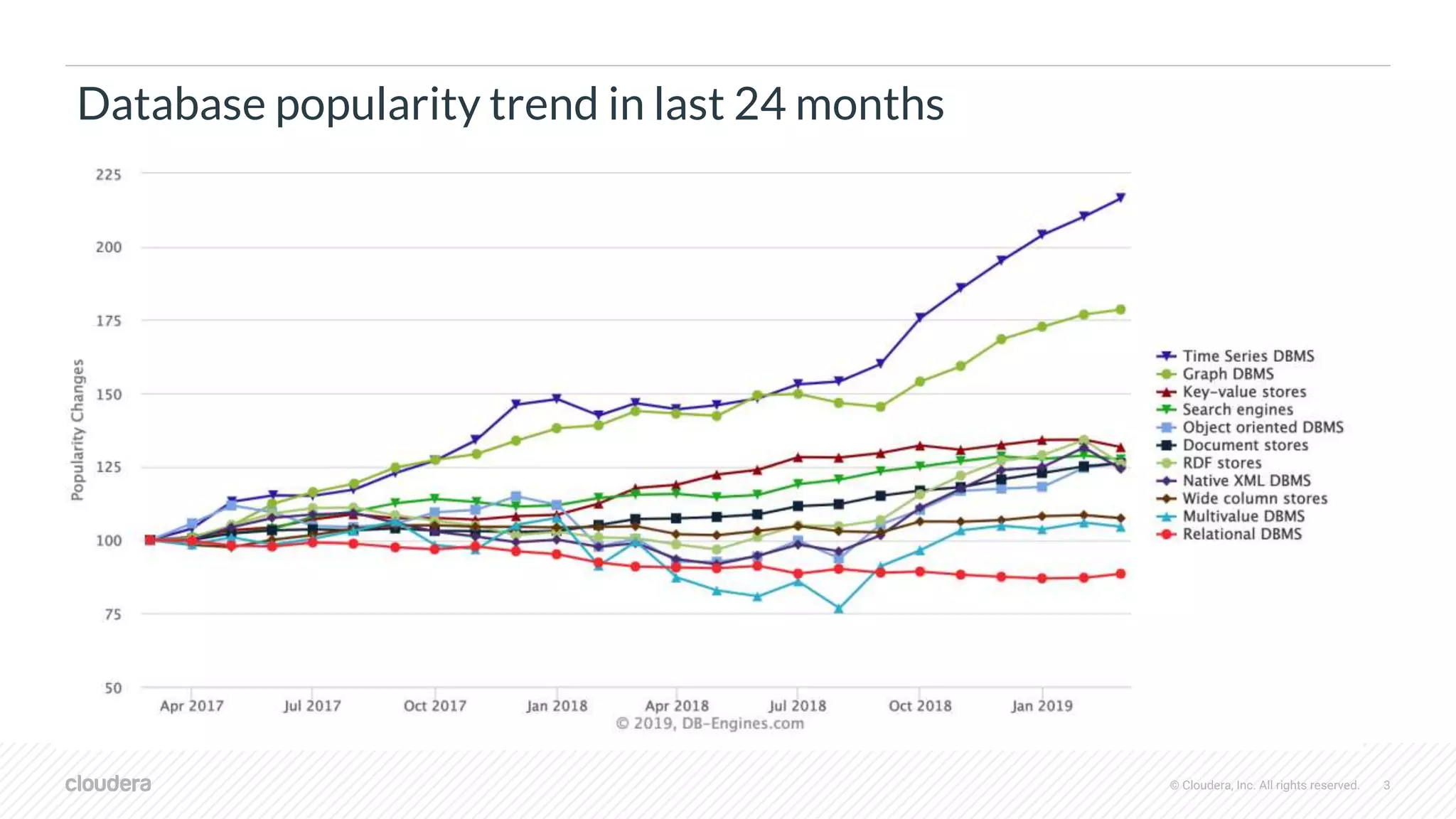
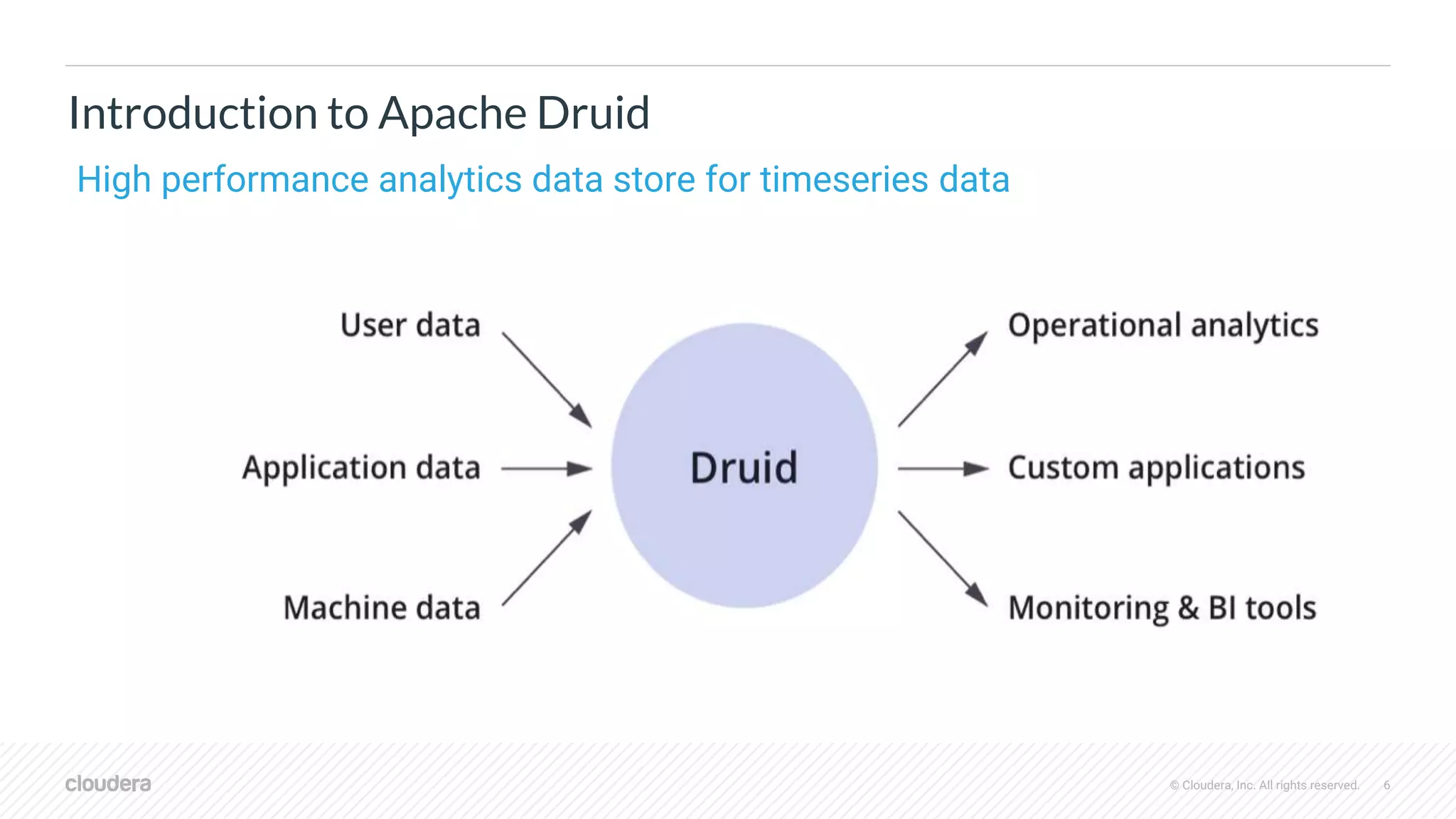
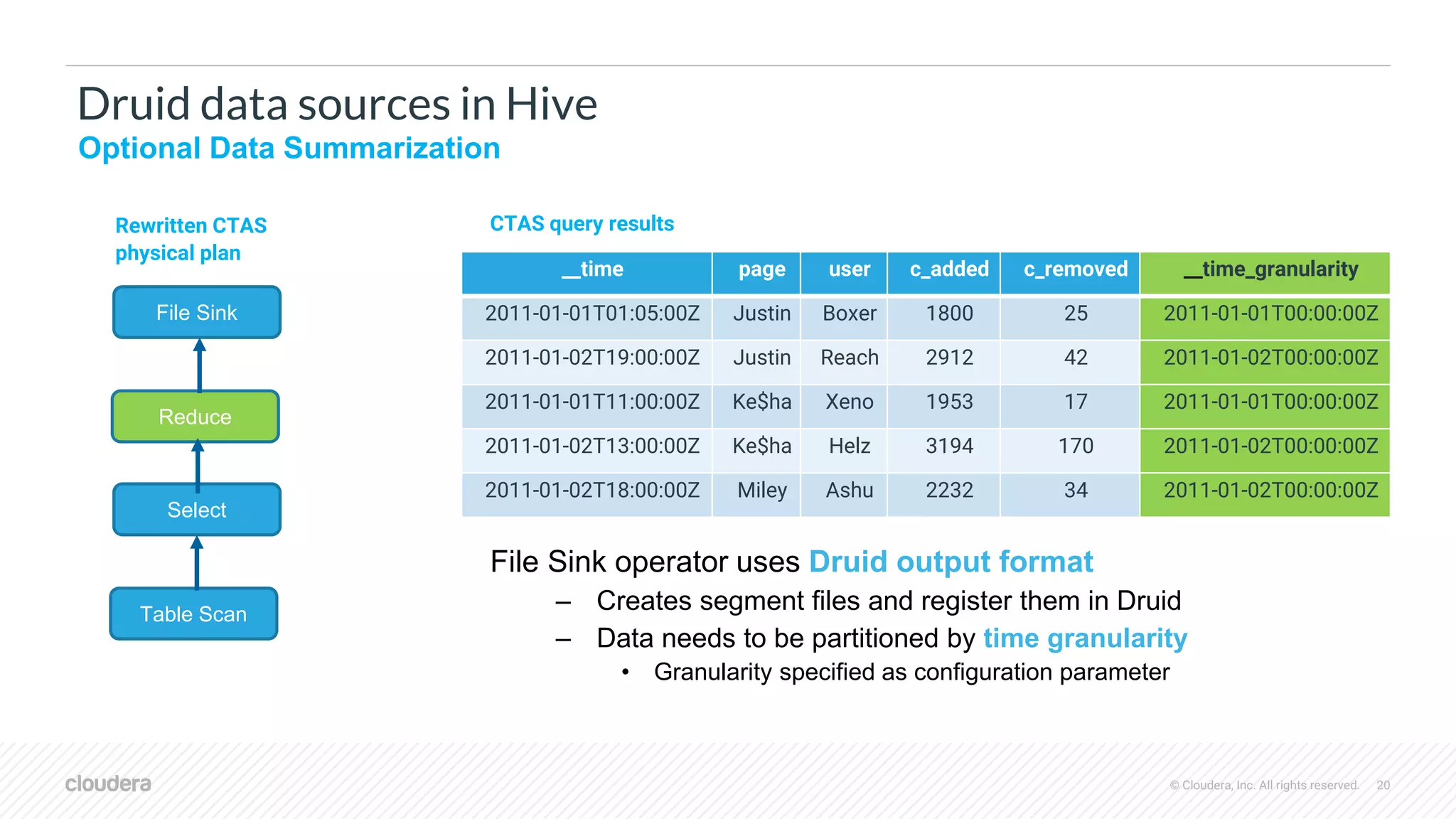
The document discusses the integration of Apache Druid and Apache Hive, focusing on their combined use cases, performance benefits, and best practices. It outlines when to use and not use Druid, its key features, and the architecture that supports real-time and batch data processing. Additionally, it provides insights into query federation, data source management, and performance metrics, along with useful resources for further exploration.







































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














