Download to read offline






![@chbatey
RDD Operations
• Transformations - Similar to Scala collections API
• Produce new RDDs
• filter, flatmap, map, distinct, groupBy, union, zip, reduceByKey, subtract
• Actions
• Require materialization of the records to generate a value
• collect: Array[T], count, fold, reduce..](https://image.slidesharecdn.com/3-dundee-sparkoverviewforcdevelopers-150710123410-lva1-app6891/85/3-Dundee-Spark-Overview-for-C-developers-9-320.jpg)
![@chbatey
Word count
val file: RDD[String] = sc.textFile("hdfs://...")
val counts: RDD[(String, Int)] = file.flatMap(line =>
line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")](https://image.slidesharecdn.com/3-dundee-sparkoverviewforcdevelopers-150710123410-lva1-app6891/85/3-Dundee-Spark-Overview-for-C-developers-10-320.jpg)
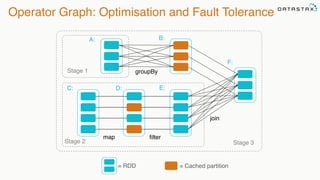

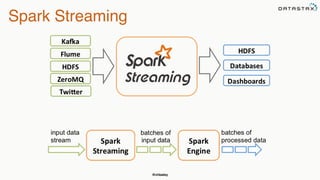


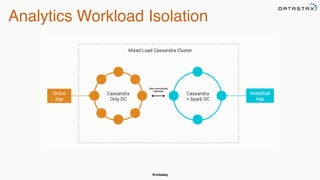
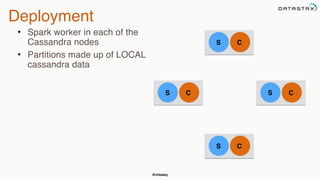


![@chbatey
Boiler plate
import com.datastax.spark.connector.rdd._
import org.apache.spark._
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
object BasicCassandraInteraction extends App {
val conf = new SparkConf(true).set("spark.cassandra.connection.host", "127.0.0.1")
val sc = new SparkContext("local[4]", "AppName", conf)
// cool stuff
}
Cassandra Host
Spark master e.g spark://host:port](https://image.slidesharecdn.com/3-dundee-sparkoverviewforcdevelopers-150710123410-lva1-app6891/85/3-Dundee-Spark-Overview-for-C-developers-22-320.jpg)

![@chbatey
Reading data from Cassandra
CassandraConnector(conf).withSessionDo { session =>
session.execute("CREATE TABLE IF NOT EXISTS test.kv(key text PRIMARY KEY, value int)")
session.execute("INSERT INTO test.kv(key, value) VALUES ('chris', 10)")
session.execute("INSERT INTO test.kv(key, value) VALUES ('dan', 1)")
session.execute("INSERT INTO test.kv(key, value) VALUES ('charlieS', 2)")
}
val rdd: CassandraRDD[CassandraRow] = sc.cassandraTable("test", "kv")
println(rdd.max()(new Ordering[CassandraRow] {
override def compare(x: CassandraRow, y: CassandraRow): Int =
x.getInt("value").compare(y.getInt("value"))
}))](https://image.slidesharecdn.com/3-dundee-sparkoverviewforcdevelopers-150710123410-lva1-app6891/85/3-Dundee-Spark-Overview-for-C-developers-24-320.jpg)
![@chbatey
Word Count + Save to Cassandra
val textFile: RDD[String] = sc.textFile("Spark-Readme.md")
val words: RDD[String] = textFile.flatMap(line => line.split("s+"))
val wordAndCount: RDD[(String, Int)] = words.map((_, 1))
val wordCounts: RDD[(String, Int)] = wordAndCount.reduceByKey(_ + _)
println(wordCounts.first())
wordCounts.saveToCassandra("test", "words", SomeColumns("word", "count"))](https://image.slidesharecdn.com/3-dundee-sparkoverviewforcdevelopers-150710123410-lva1-app6891/85/3-Dundee-Spark-Overview-for-C-developers-25-320.jpg)








![@chbatey
Now now…
val cc = new CassandraSQLContext(sc)
cc.setKeyspace("test")
val rdd: SchemaRDD = cc.sql("SELECT store_name, event_type, count(store_name) from customer_events
GROUP BY store_name, event_type")
rdd.collect().foreach(println)
[SportsApp,WATCH_STREAM,1]
[SportsApp,LOGOUT,1]
[SportsApp,LOGIN,1]
[ChrisBatey.com,WATCH_MOVIE,1]
[ChrisBatey.com,LOGOUT,1]
[ChrisBatey.com,BUY_MOVIE,1]
[SportsApp,WATCH_MOVIE,2]](https://image.slidesharecdn.com/3-dundee-sparkoverviewforcdevelopers-150710123410-lva1-app6891/85/3-Dundee-Spark-Overview-for-C-developers-34-320.jpg)



![@chbatey
Save + Process
val rawEvents: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream[String, String, StringDecoder, StringDecoder]
(ssc, kafka.kafkaParams, Map(topic -> 1), StorageLevel.MEMORY_ONLY)
val events: DStream[CustomerEvent] = rawEvents.map({ case (k, v) =>
parse(v).extract[CustomerEvent]
})
events.saveToCassandra("streaming", "customer_events")
val eventsByCustomerAndType = events.map(event => (s"${event.customer_id}-${event.event_type}", 1)).reduceByKey(_ + _)
eventsByCustomerAndType.saveToCassandra("streaming", "customer_events_by_type")](https://image.slidesharecdn.com/3-dundee-sparkoverviewforcdevelopers-150710123410-lva1-app6891/85/3-Dundee-Spark-Overview-for-C-developers-40-320.jpg)



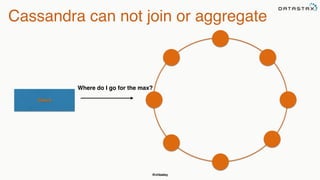
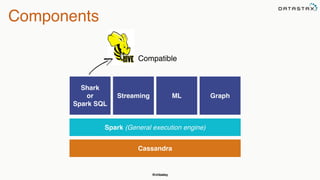
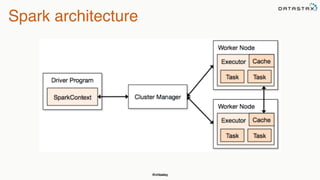
This document discusses using Apache Spark to perform analytics on Cassandra data. It provides an overview of Spark and how it can be used to query and aggregate Cassandra data through transformations and actions on resilient distributed datasets (RDDs). It also describes how to use the Spark Cassandra connector to load data from Cassandra into Spark and write data from Spark back to Cassandra.






























































































