Downloaded 53 times



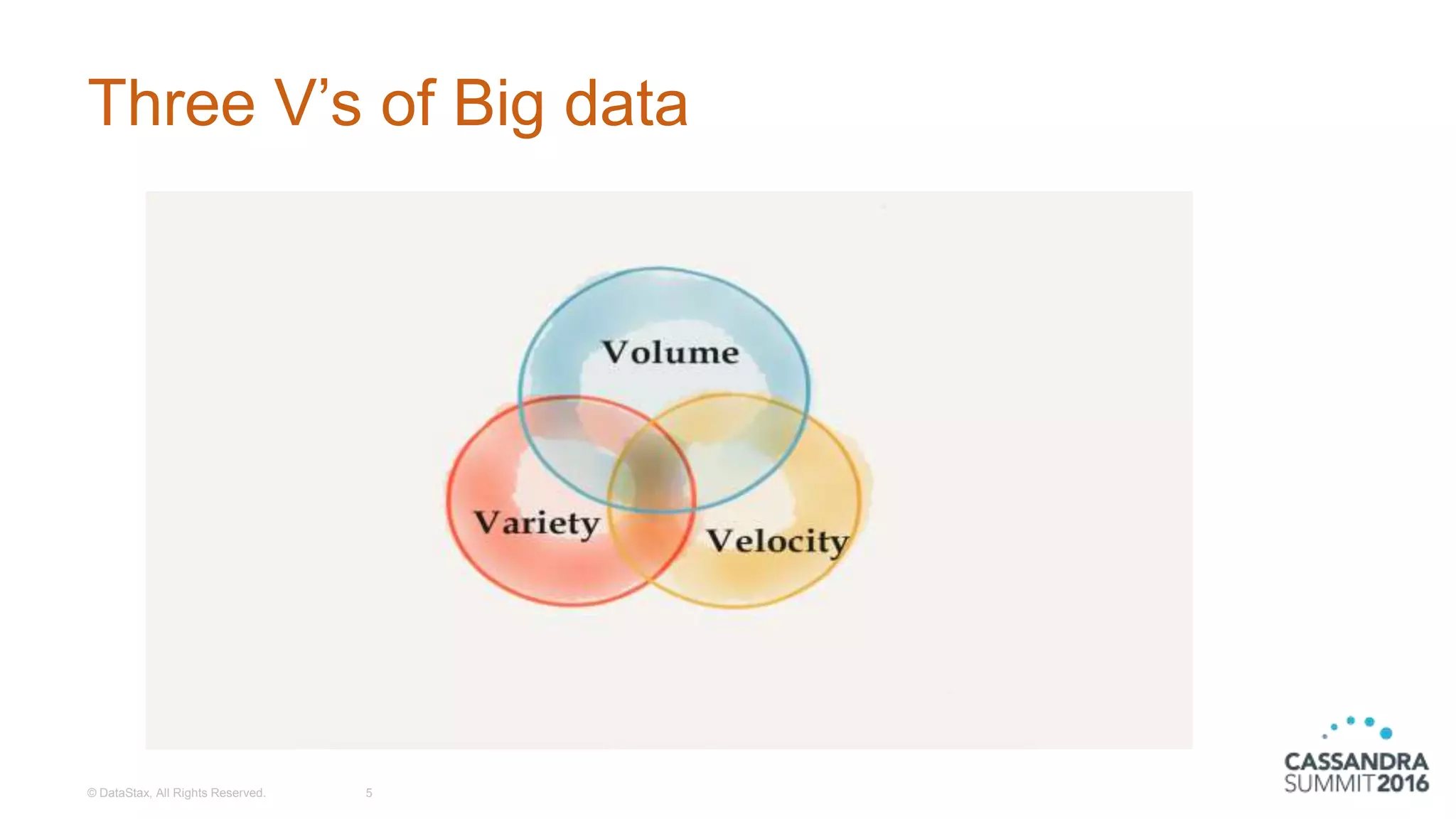
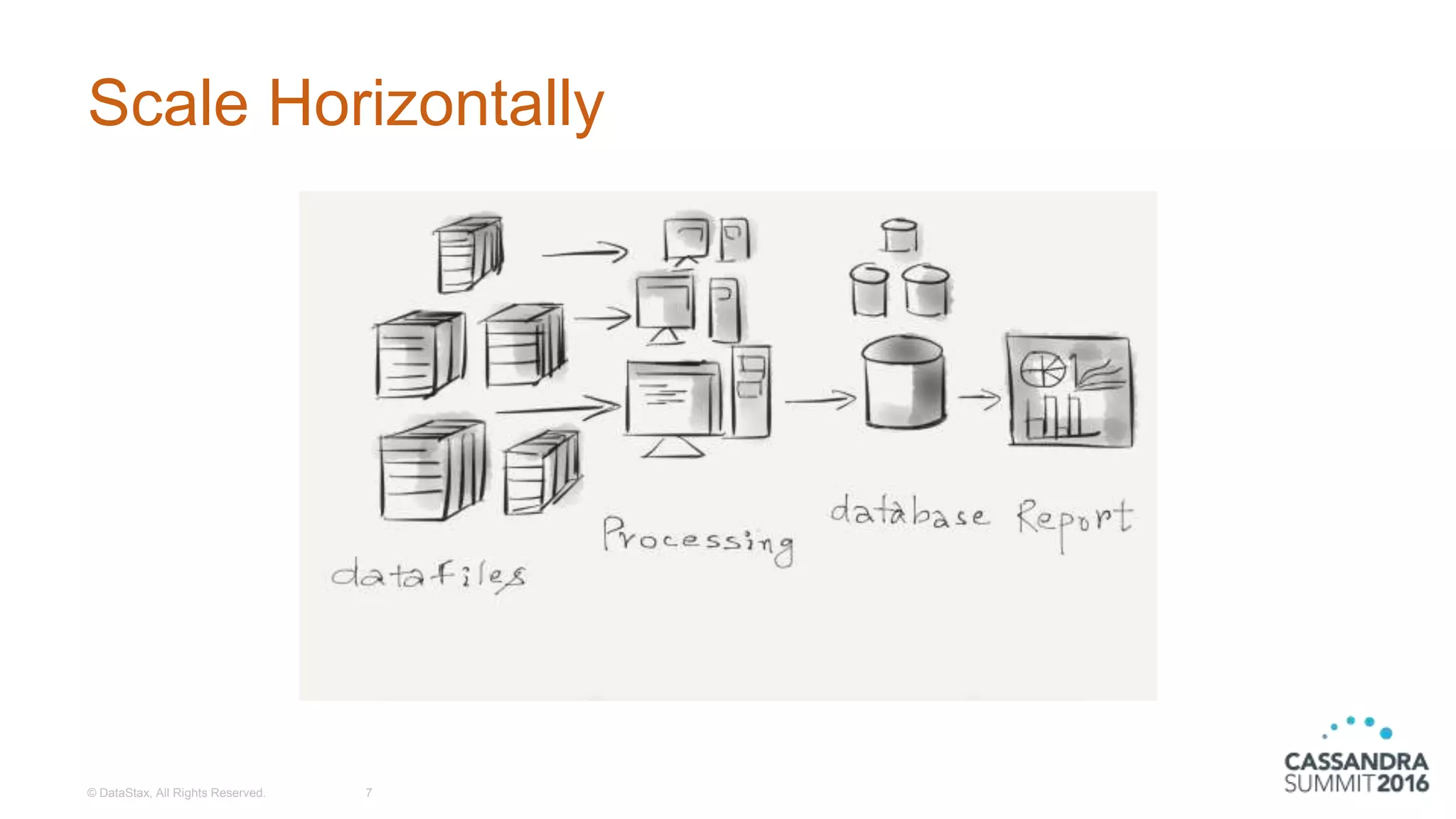


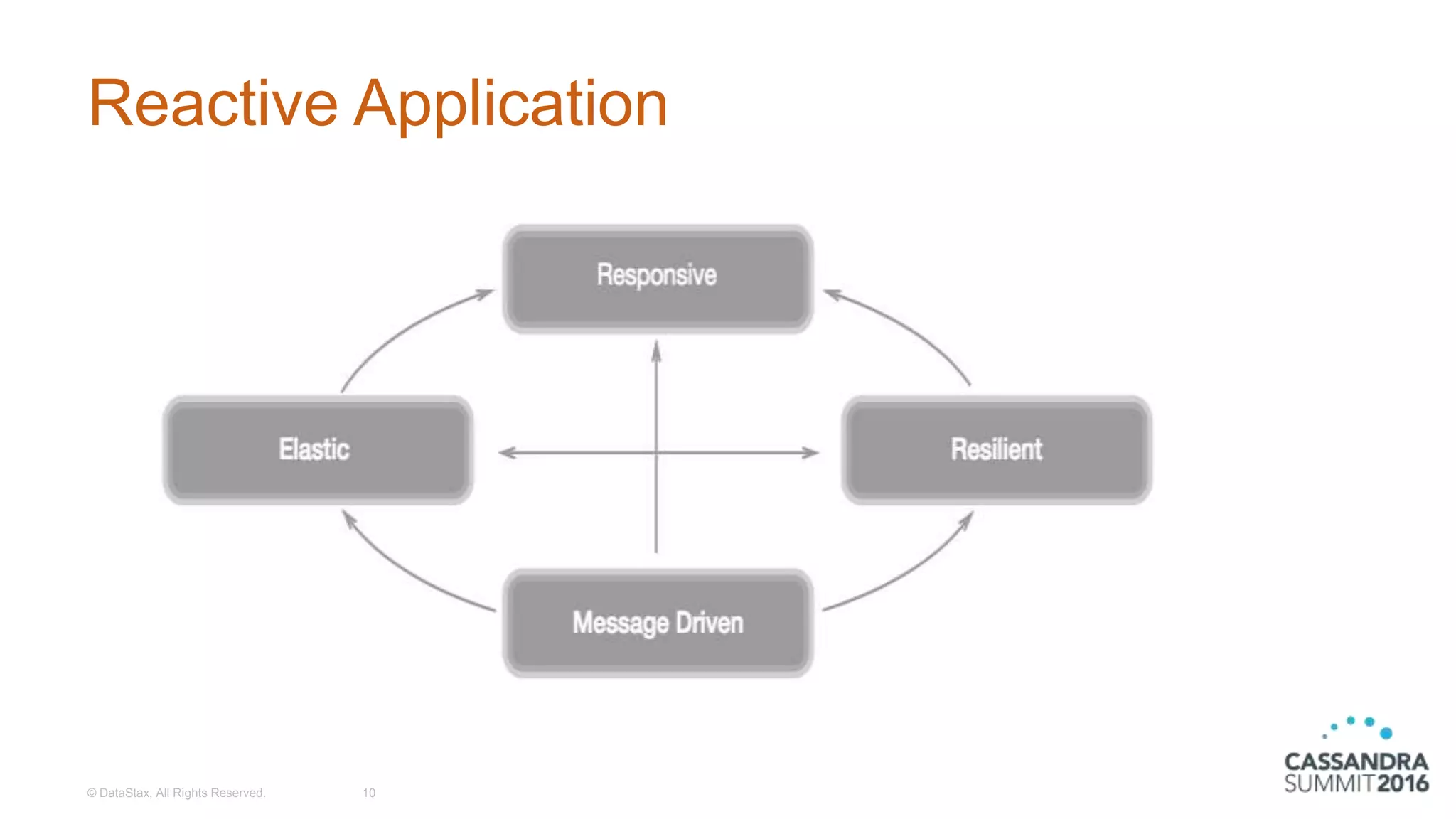

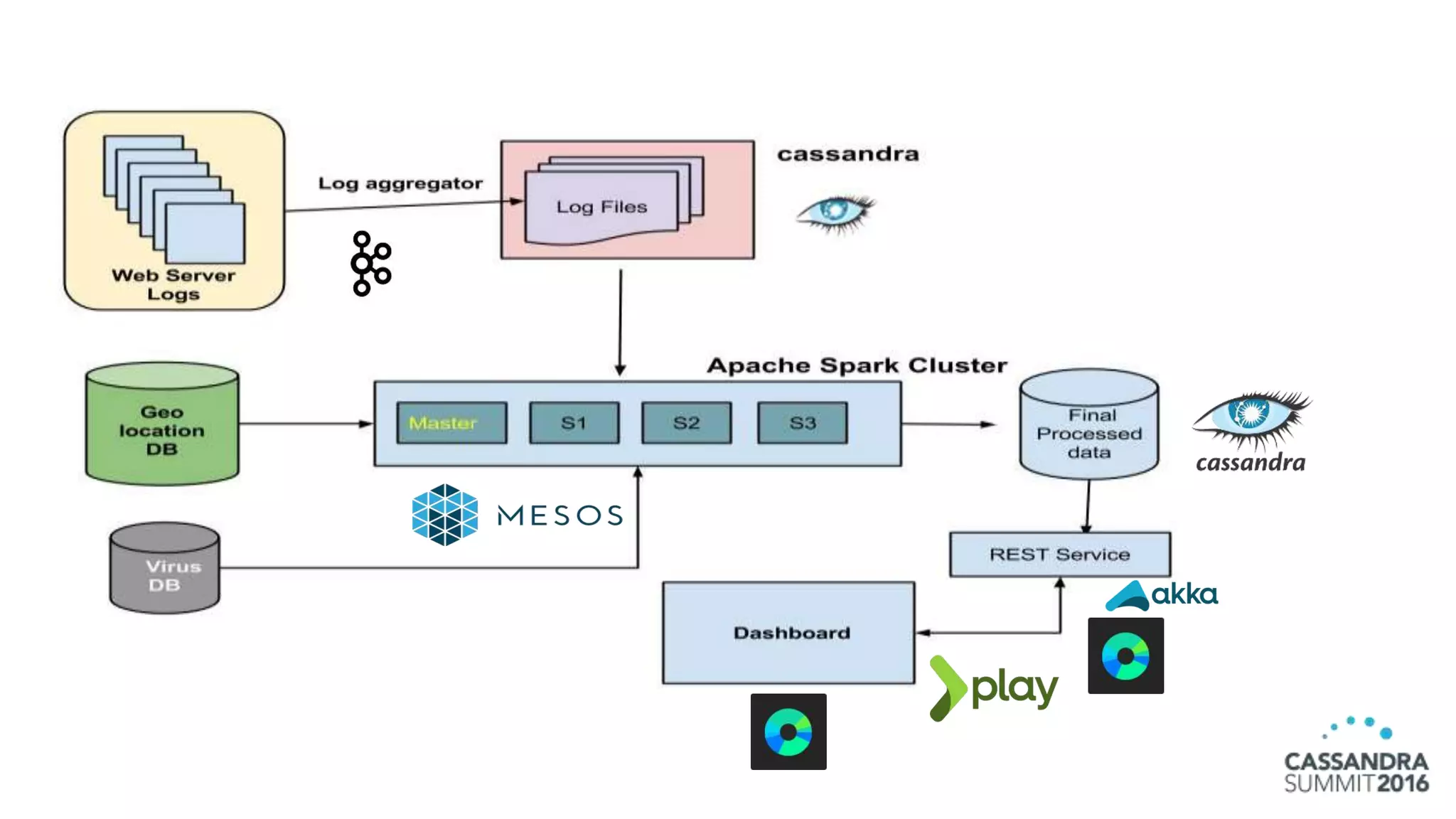


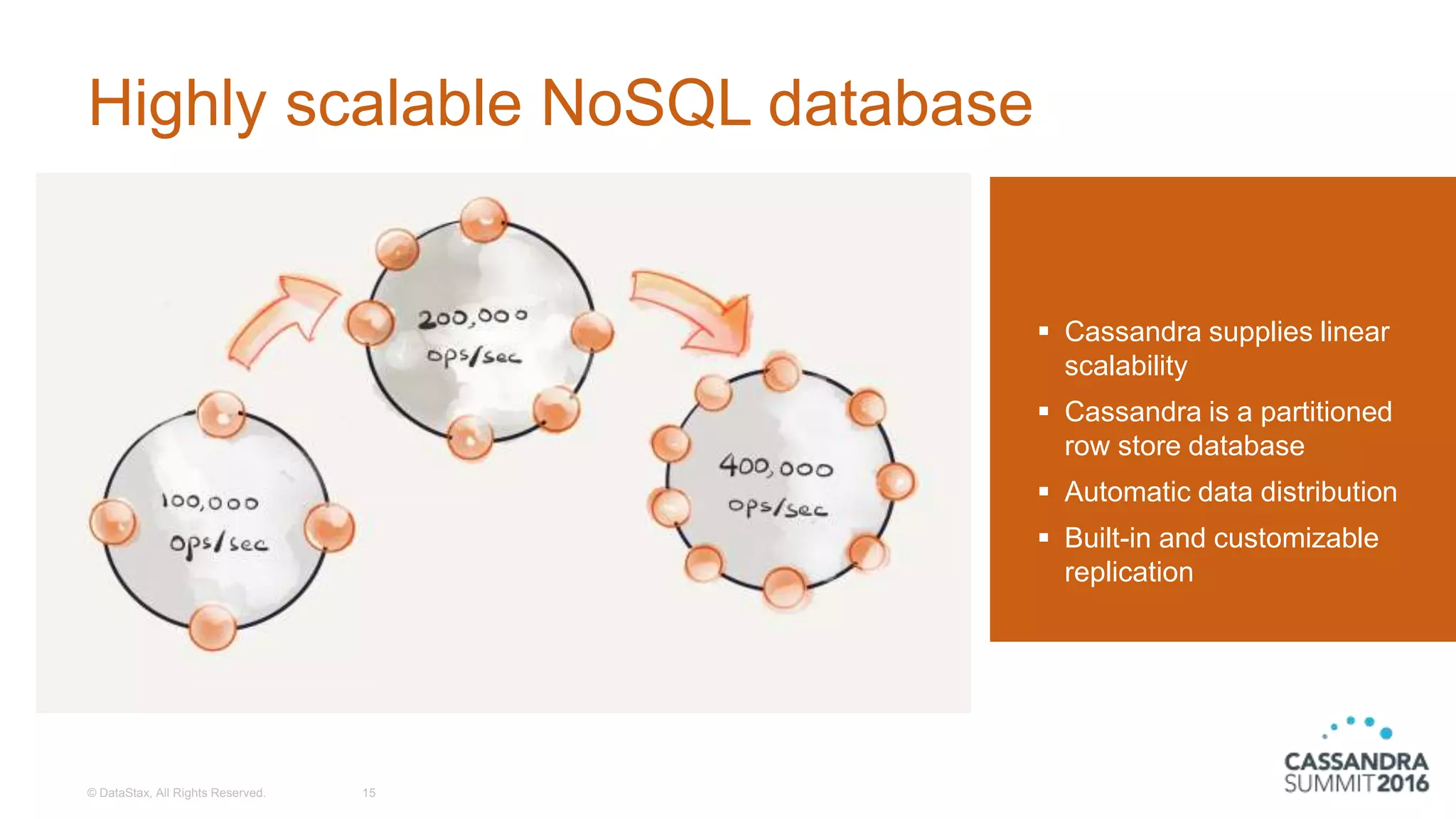
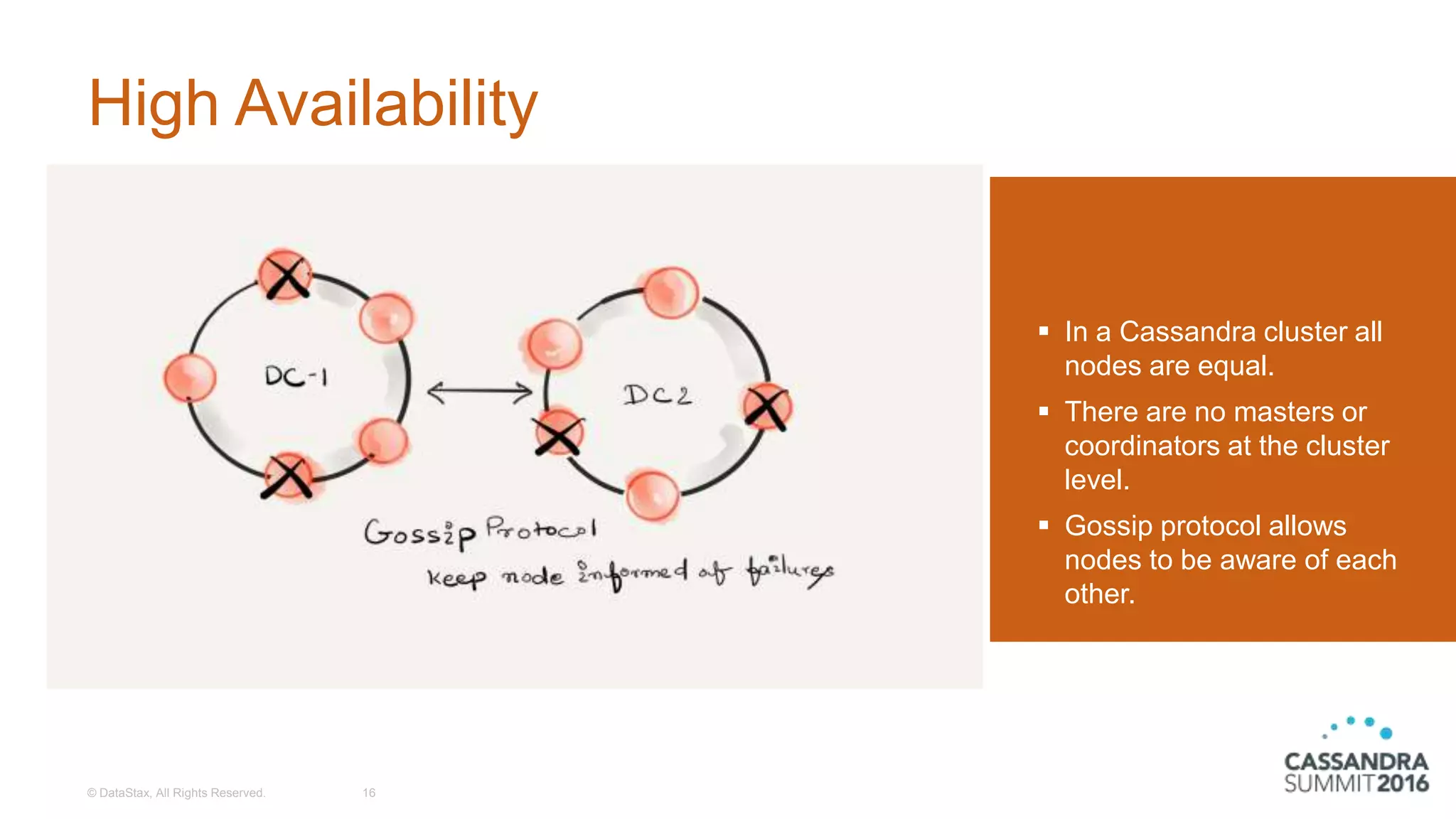
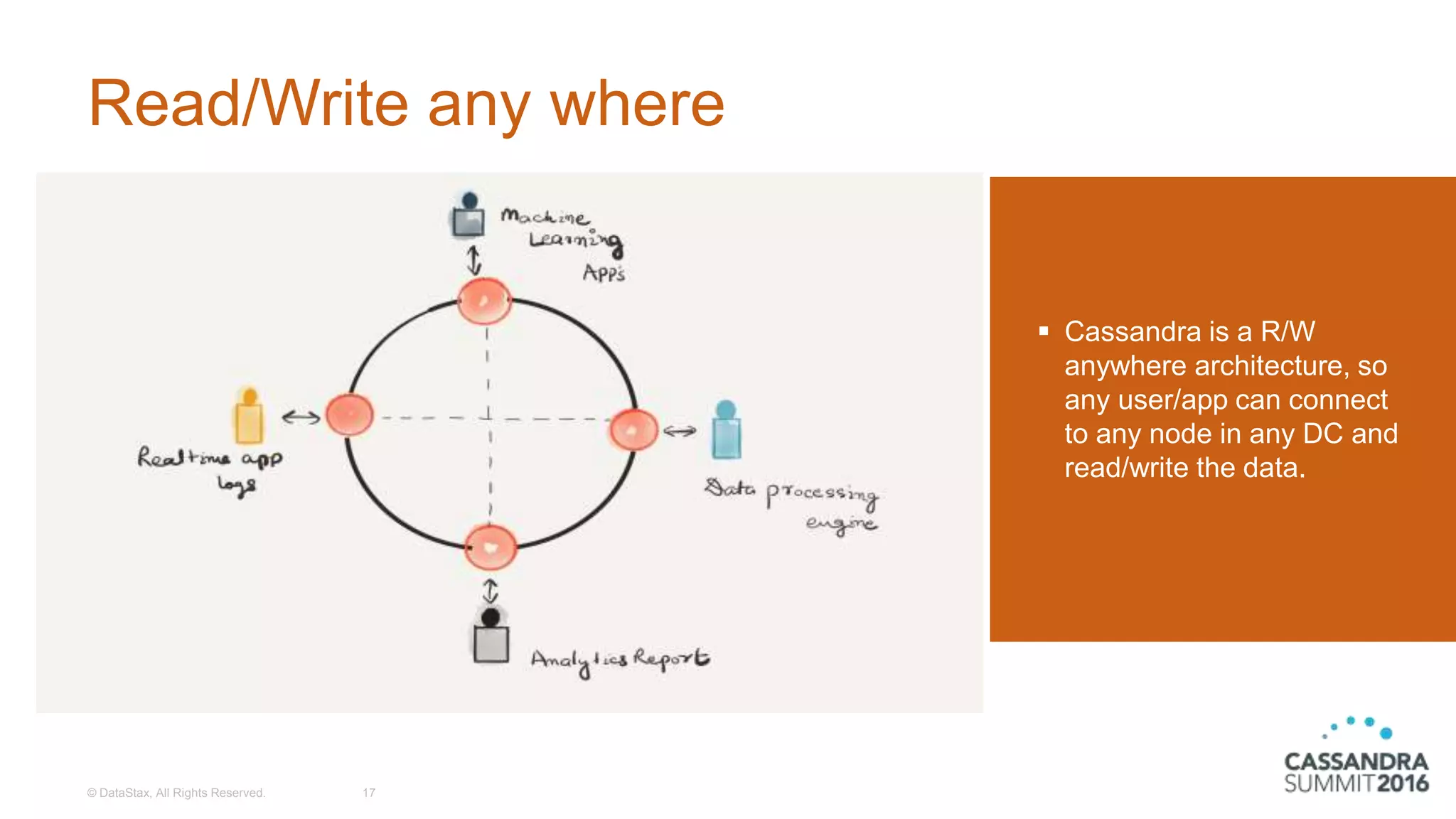
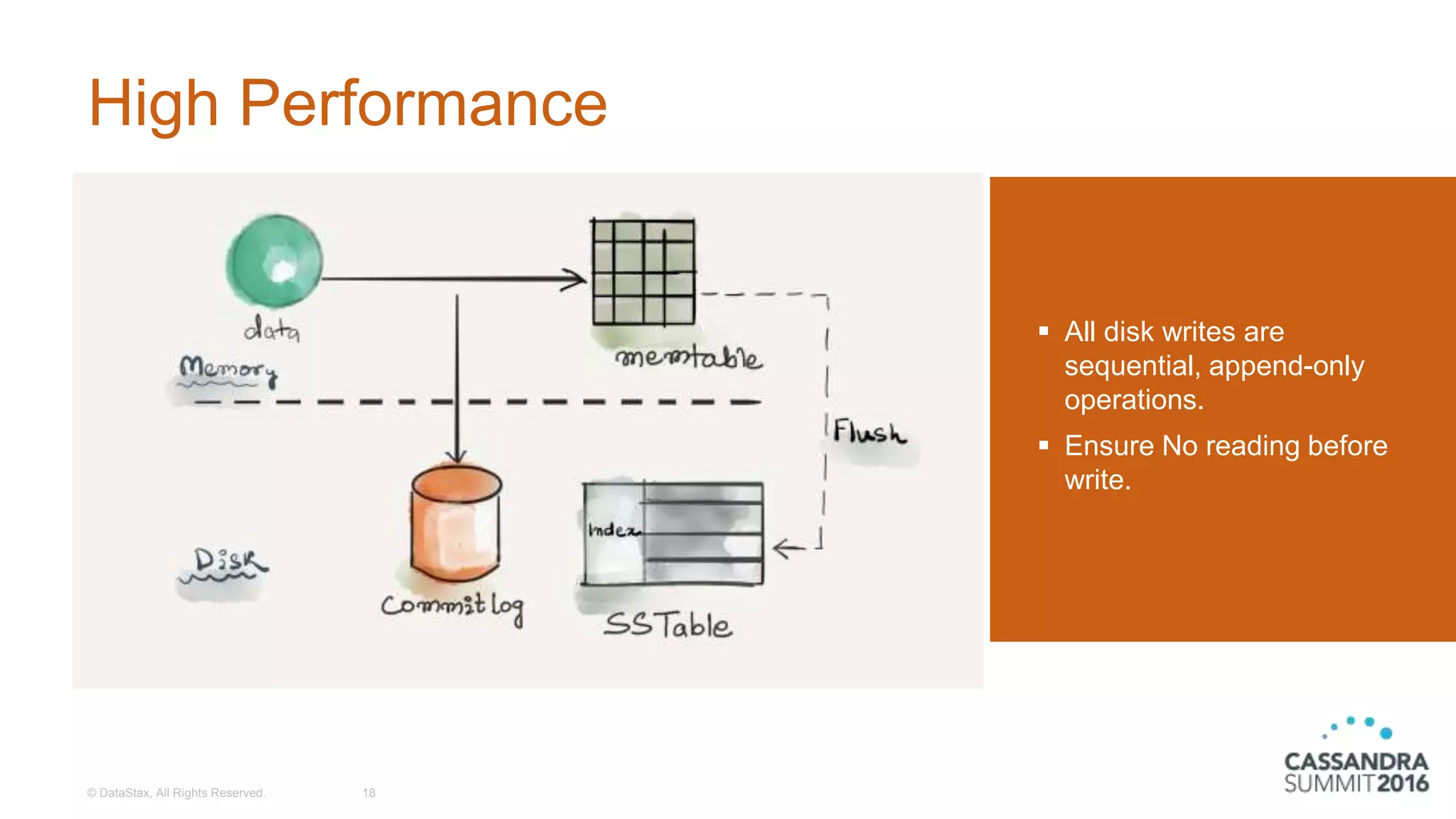
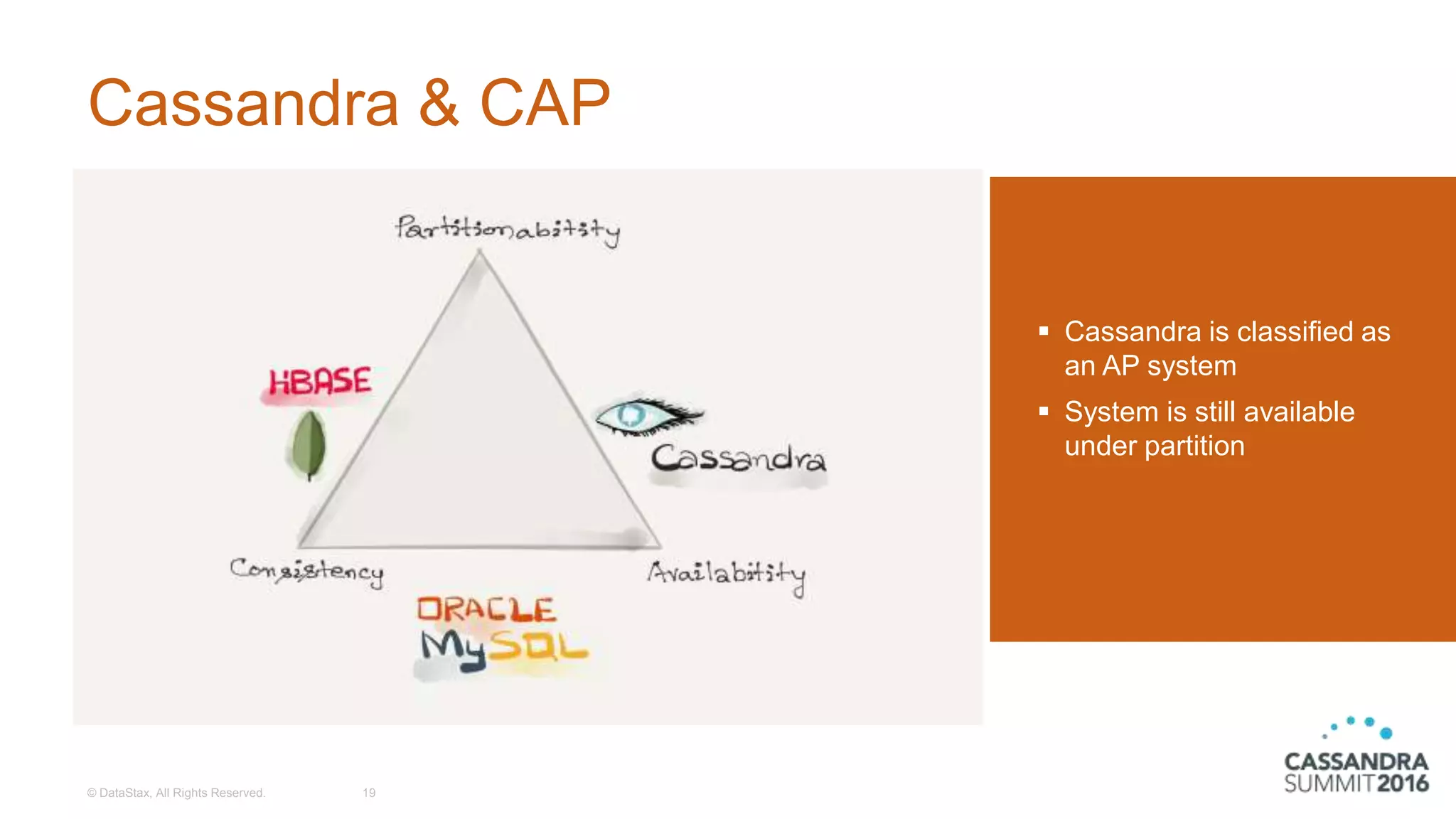

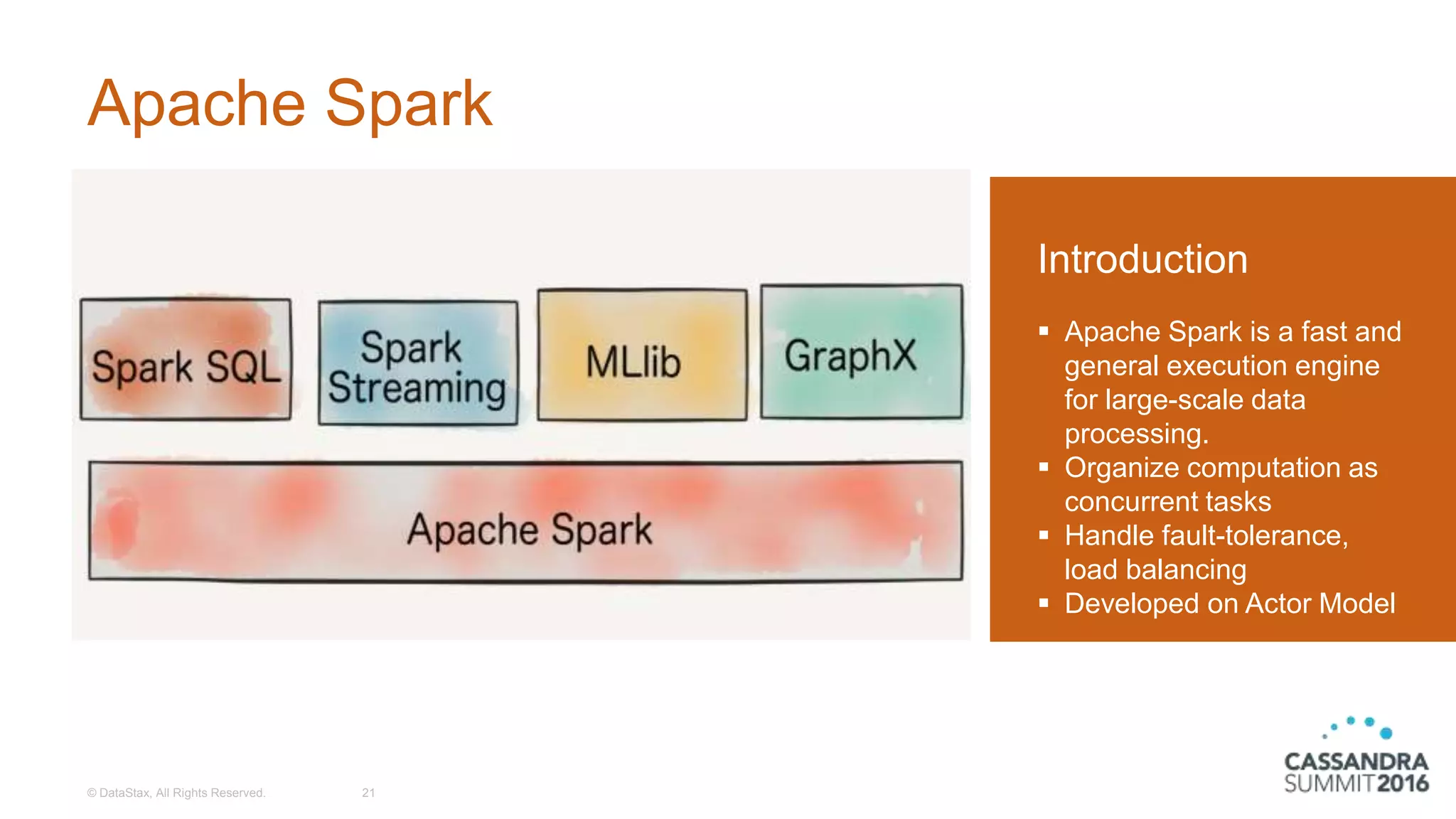

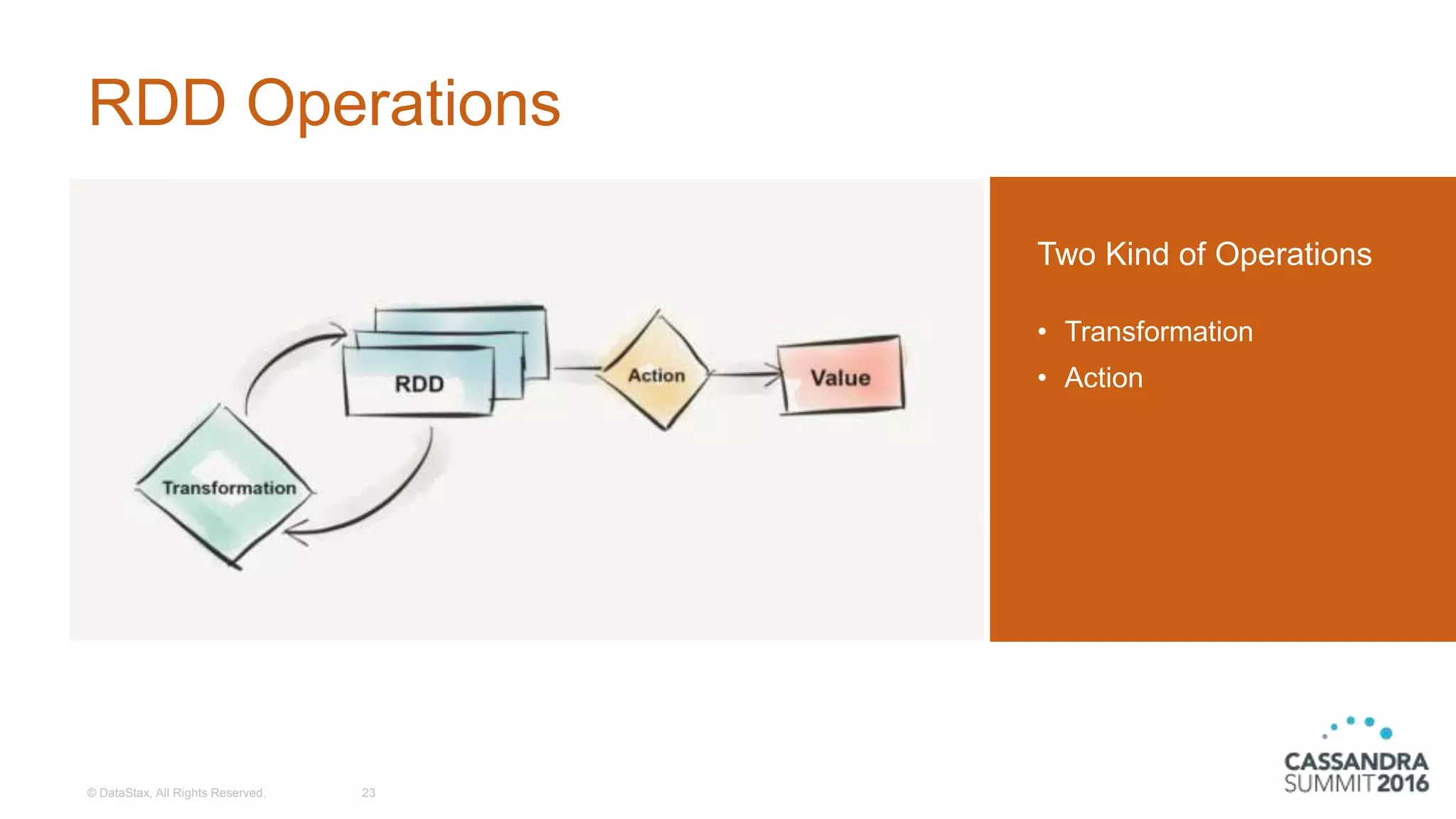



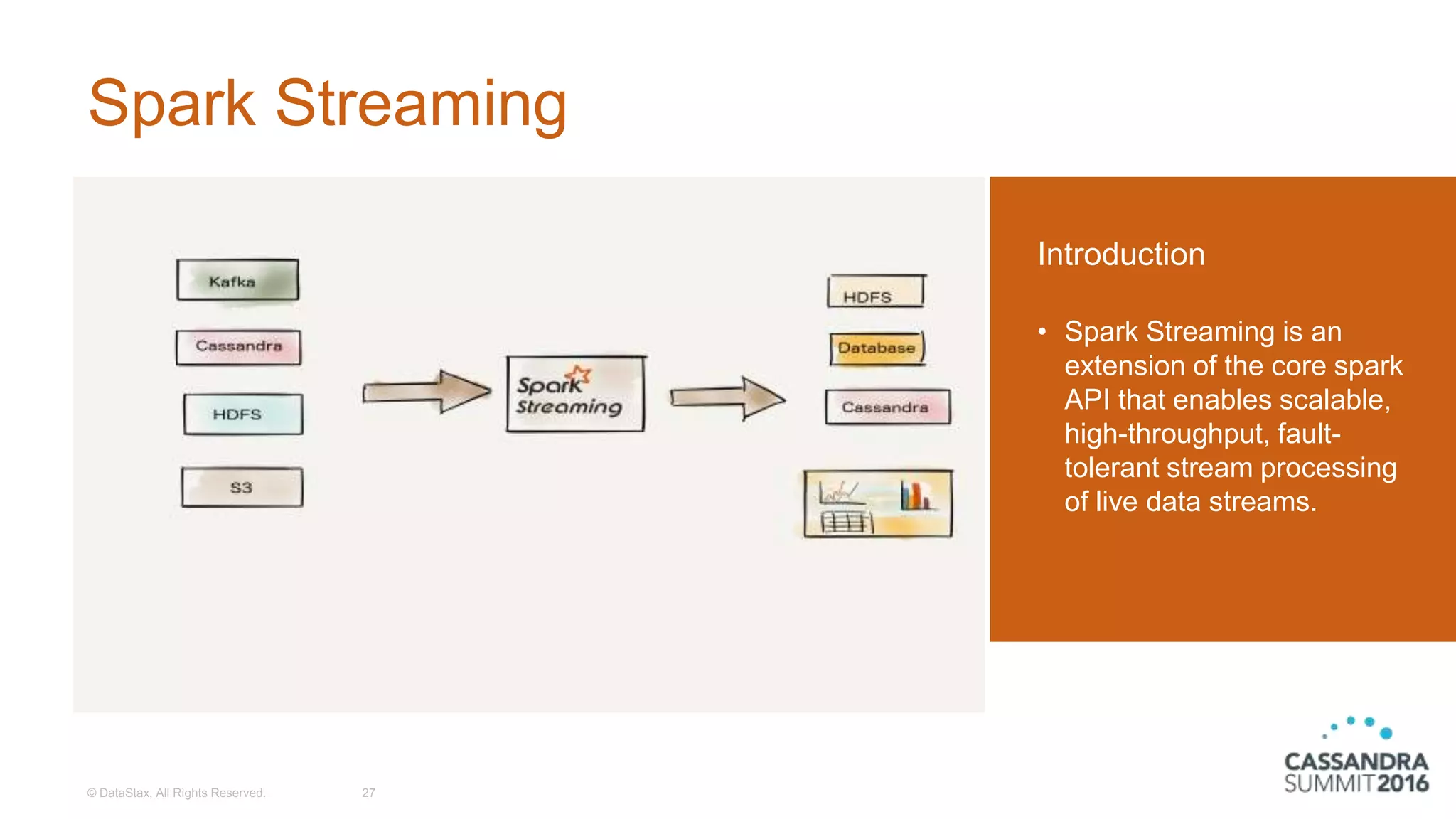
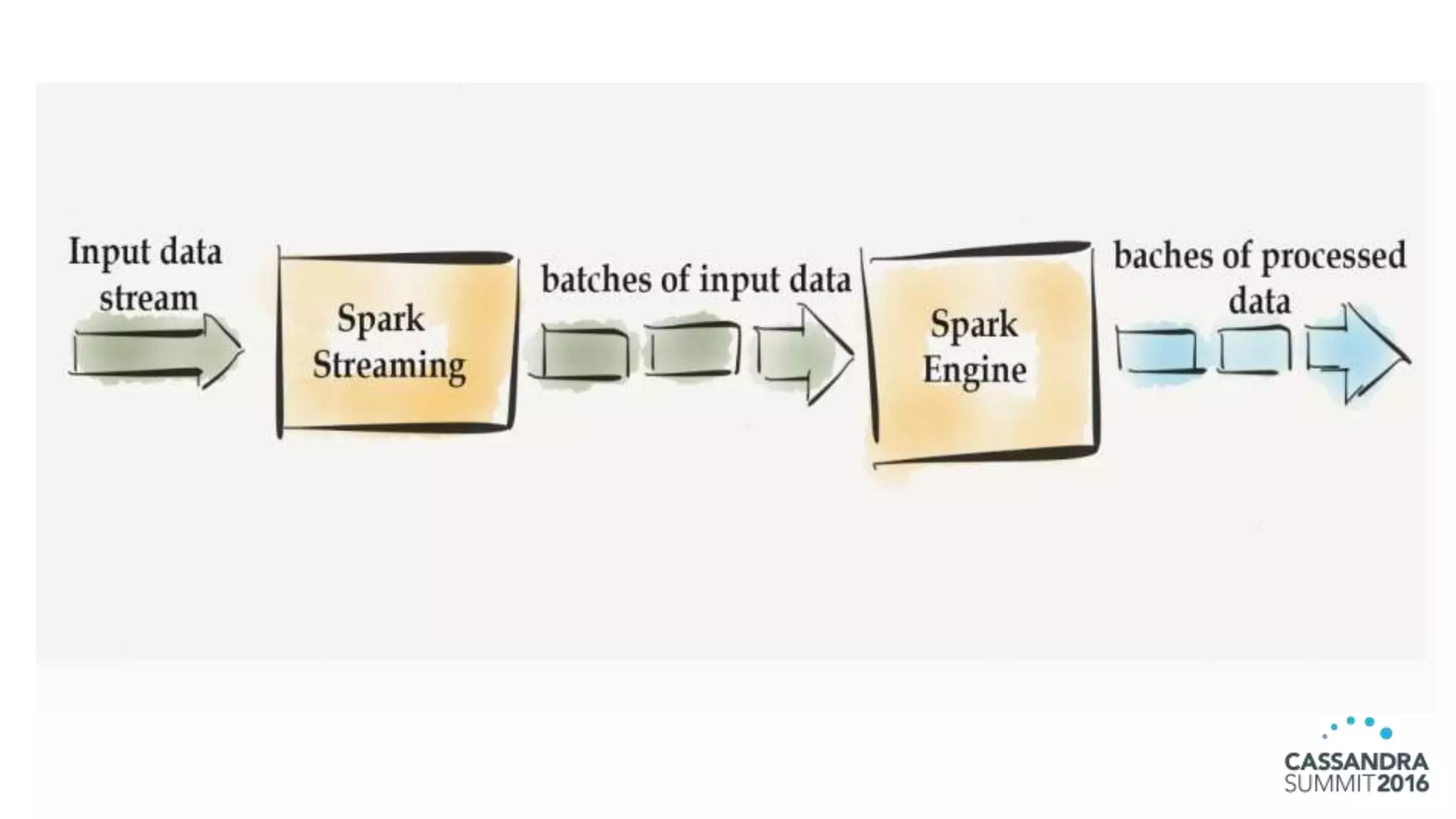
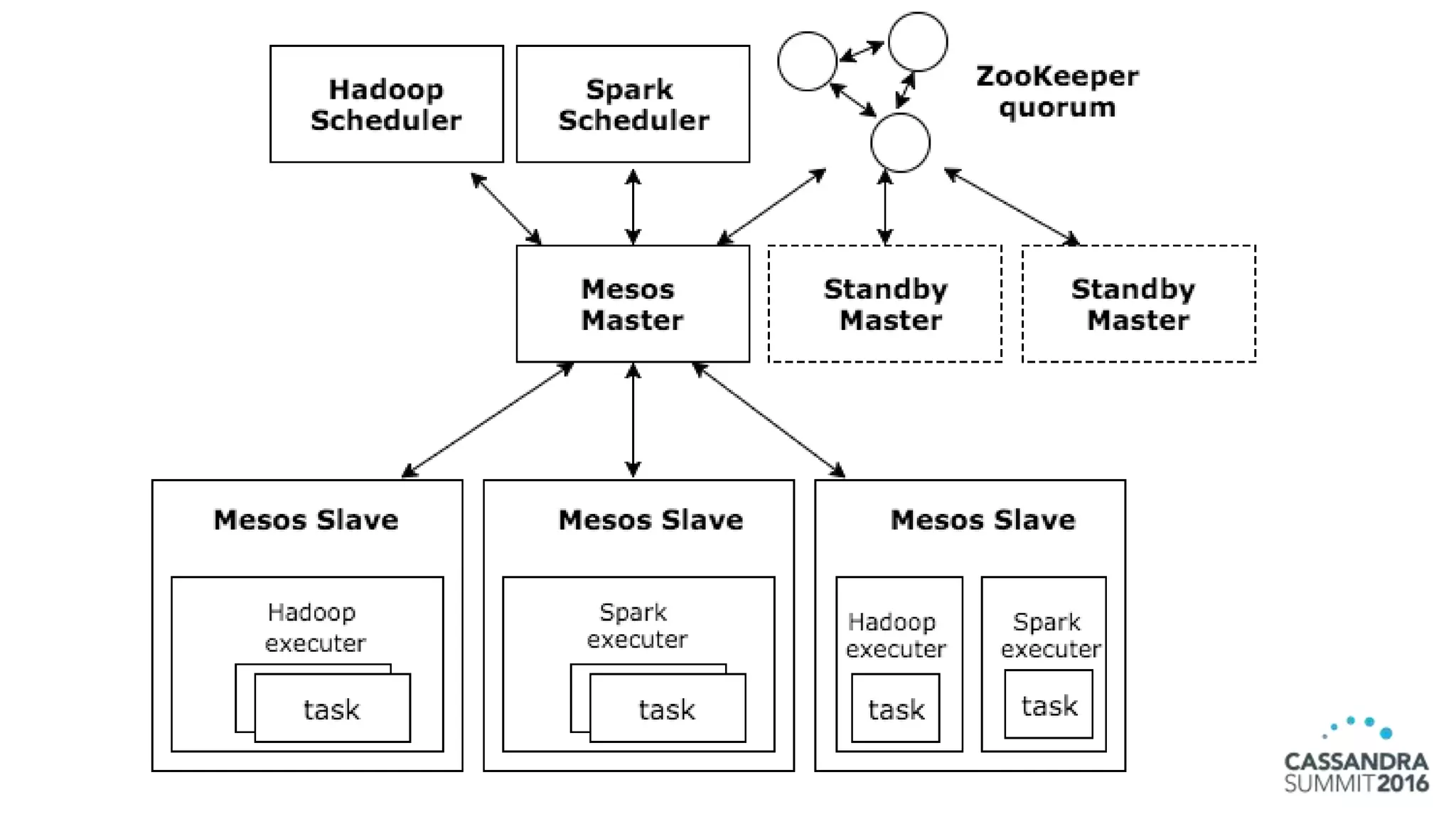






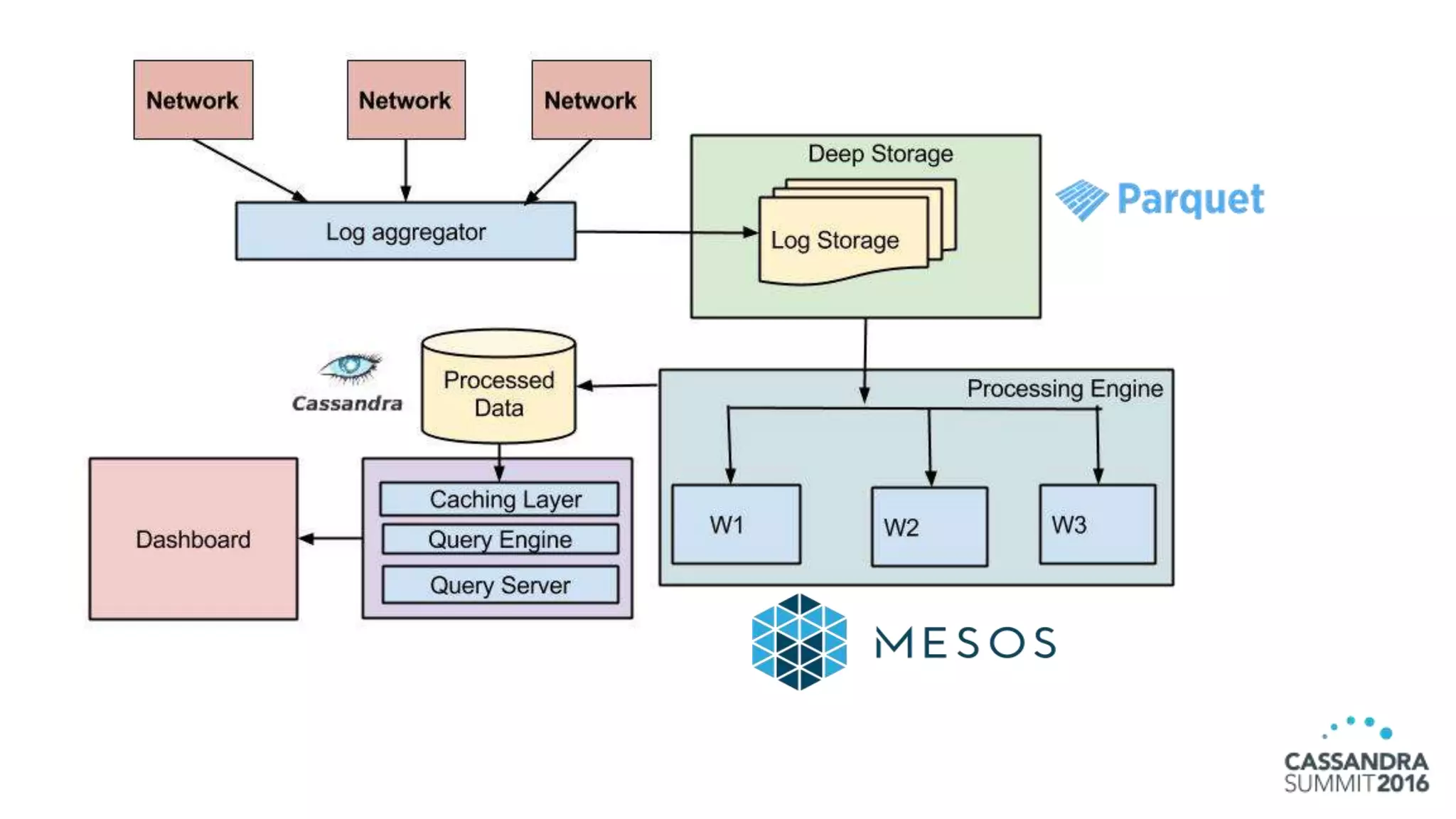
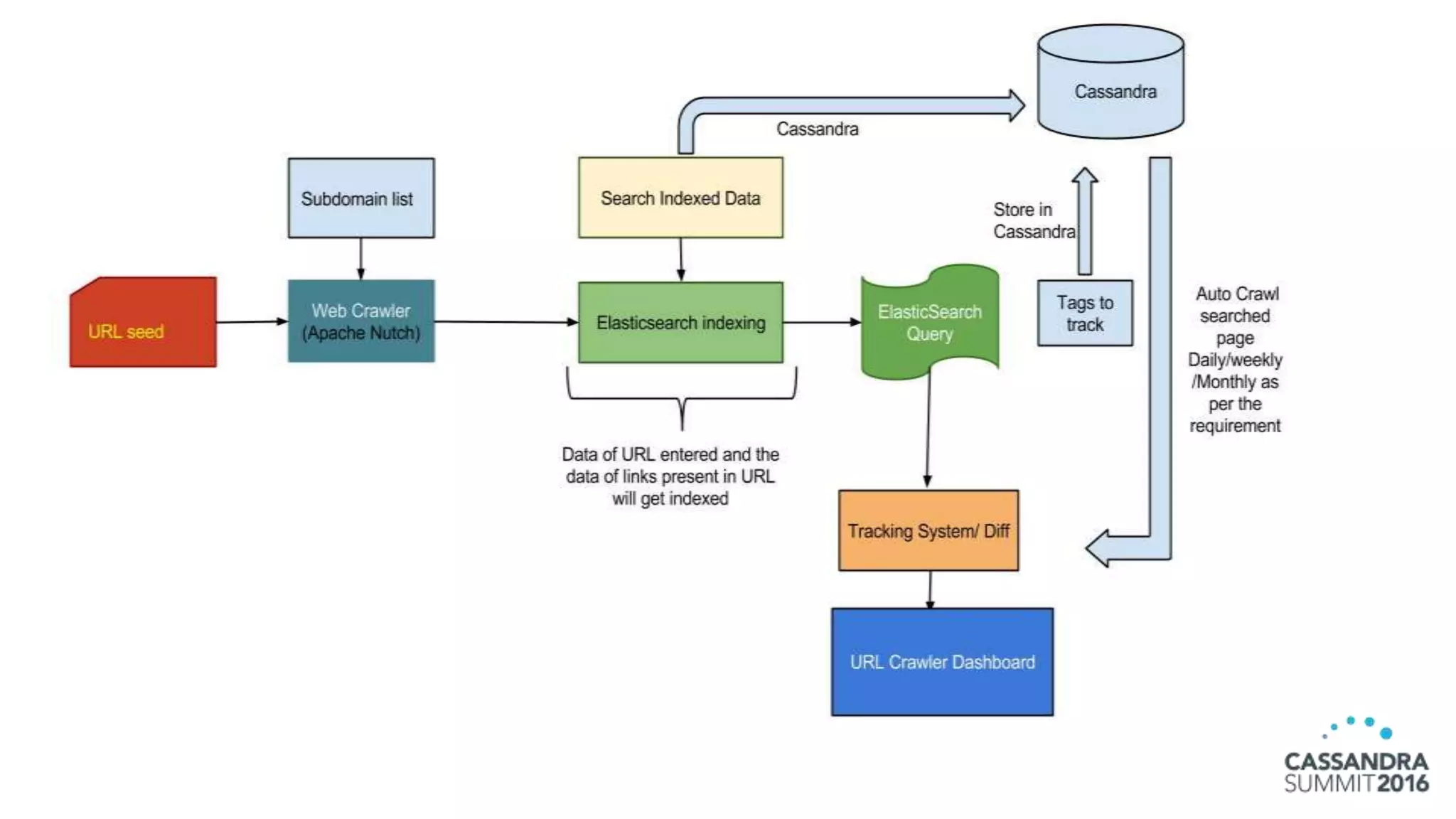


The document discusses the architecture and benefits of building reactive real-time big data systems using Spark Streaming and Cassandra, emphasizing their scalability and performance. It covers key concepts such as distributed applications, data management principles, and technical details on configuring Spark with Cassandra. Additionally, it highlights the integration of Spark Streaming for processing live data streams and utilizing the Spark Cassandra connector for efficient data access and manipulation.























































































