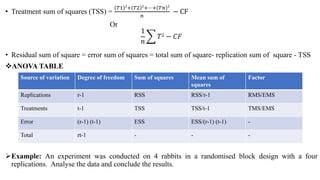
The document covers the design and analysis of experiments with a focus on factorial design, detailing its historical development, advantages, and disadvantages. It describes key designs in experiments, including completely randomized, randomized complete block, and factorial designs, along with statistical methods such as ANOVA for analyzing experimental data. Additionally, practical examples illustrate how factorial experiments assess the effects of multiple factors simultaneously, highlighting efficiency and the complexity of statistical analysis.
















![• For factor C it is shown in round balls. (High and low values)
• For factor B it is shown in dotted lines (high and low).
Estimating simple effect:
Simple effect of A at low level of B and C=
𝑎
𝑛
−
(1)
𝑛
Simple effect of A at high level of B and low level of C =
𝑎𝑏
𝑛
−
𝑏
𝑛
Simple effect of A at low level of B and high level of C=
𝑎𝑐
𝑛
-
𝑐
𝑛
Simple effect of A at high level of B and C=
𝑎𝑏𝑐
𝑛
−
𝑏𝑐
𝑛
Estimating the main effect:
Main effect of A can be written in short as
• Main effect of A =
𝑎−1 (𝑏−1)(𝑐+1)
4𝑛
a-1 means it should be kept in mind that 1 is given in brackets i.e., [a-(1)].
• Main effect of B =
1
4𝑛
[b+ab+bc+abc-(1)-a-c-ac]](https://image.slidesharecdn.com/factorialdesign-220702075203-a9d9e614/85/factorial-design-pptx-18-320.jpg)
![In short ,
• Main effect of B =
(𝑎+1)(𝑏−1)(𝑐+1)
4𝑛
• Main effect of C=
1
4𝑛
𝑐 + 𝑎𝑐 + 𝑏𝑐 + 𝑎𝑏𝑐 − 1 − 𝑎 − 𝑏 − 𝑎𝑏
• Main effect of c =
(𝑎+1)(𝑏+1)(𝑐−1)
4𝑛
Estimating the interaction effect:
• Interaction effect of AB =
1
4𝑛
[(1)+ab+c+abc-a-b-ac-bc]
In short,
• Interaction of AB =
(𝑎−1)(𝑏−1)(𝑐+1)
4𝑛
• Interaction effect of AC =
1
4𝑛
1 + 𝑏 + 𝑎𝑐 + 𝑎𝑏𝑐 − 𝑎 − 𝑎𝑏 − 𝑐 − 𝑏𝑐
In short,
• Interaction of AC=
(𝑎+1)(𝑏+1)(𝑐−1)
4𝑛
• Interaction effect of BC =
1
4𝑛
[(1)+a+bc+abc-b-ab-c-ac]
In short,
• Interaction of BC=
(𝑎+1)(𝑏−1)(𝑐−1)
4𝑛](https://image.slidesharecdn.com/factorialdesign-220702075203-a9d9e614/85/factorial-design-pptx-19-320.jpg)

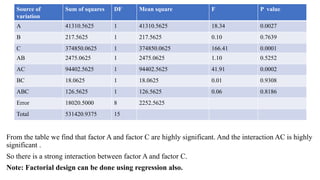
![• Calculation of sum of squares:
• In the 23 design with n replicates, the sum of squares for any effect is given by
SS=
𝐶𝑜𝑛𝑡𝑟𝑎𝑠𝑡 2
8𝑛
2x2x2=8 [So 8n is taken]
(23)
• Note: The number calculated in the effect of any factors which is inside the bracket is called the
contrast. Also we can take the numerator from the shortcut formula.
For Example:
• Main effect of A =
1
4𝑛
𝑎 + 𝑎𝑏 + 𝑎𝑐 + 𝑎𝑏𝑐 − 1 − 𝑏 − 𝑏𝑐
• The terms which are in bracket are taken as contrast.
In short,
• Main effect of A=
𝑎−1 (𝑏+1)(𝑐+1)
4𝑛
Numerator is contrast.](https://image.slidesharecdn.com/factorialdesign-220702075203-a9d9e614/85/factorial-design-pptx-21-320.jpg)



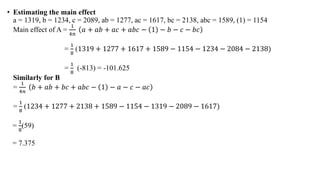
![• For factor C
=
1
4𝑛
(c +ac + bc + abc- (1) – a-b-ab)
=
1
8
( 2089+1617+2138+ 1589- 1154-1319-1234-1277) =
1
8
( 2449) = 306.125
• Interaction effect of AB
=
1
4𝑛
1 + as + c + abc − a − b − ac − bc
=
1
8
1154 + 1277 + 2089 + 1589 + 1319 − 1234 − 1617 − 2138 = -24.875
• Interaction effect of AC
=
1
4𝑛
1 + 𝑏 + 𝑎𝑐 + 𝑎𝑏𝑐 − 𝑎 − 𝑎𝑏 − 𝑐 − 𝑏𝑐
=
1
8
1154 + 1234 + 1617 + 1589 − 1319 − 1277 − 2089 − 2138
=
1
8
[-1229]
= -153.625](https://image.slidesharecdn.com/factorialdesign-220702075203-a9d9e614/85/factorial-design-pptx-26-320.jpg)
![• Interaction effect of BC
=
1
4𝑛
[ (1) + a + bc + abc – b – ab – c – ac]
=
1
8
[ 1154 + 1319 + 2138 + 1589 – 1234 -1277 – 2089 – 1617]
=
1
8
[ -17]
= -2.125
• Interaction effect of ABC
=
1
4𝑛
[abc + a + b+ c –ab – ac- bc -1]
=
1
8
[ 1589 + 1319 + 1234+ 2089 – 1277 – 1617-2138 – 1154] =
1
8
[45] = 5.625.
From the calculations
• The largest effects is for
• Factor C = 306.125
• Factor A = -101.625
• AC = -153.625](https://image.slidesharecdn.com/factorialdesign-220702075203-a9d9e614/85/factorial-design-pptx-27-320.jpg)