Download as PDF, PPTX






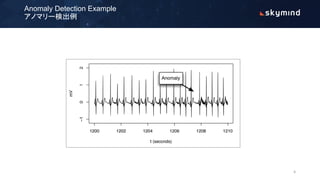
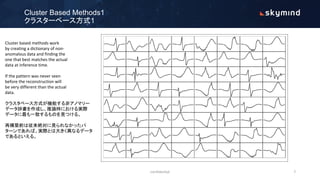
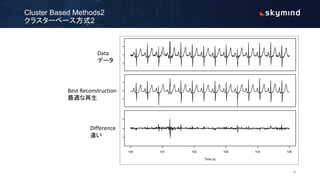
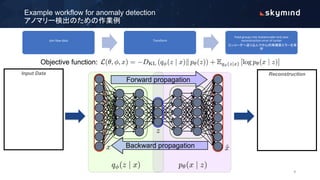










The document discusses various approaches to anomaly detection using deep learning, highlighting the limitations of methods such as probabilistic, distance, domain, reconstruction, and information theoretic-based techniques. It emphasizes the need for multiple algorithms to effectively handle large datasets, addressing issues of class imbalance and the necessity of efficient computation and storage solutions. Additionally, it outlines the training process of autoencoders for detecting anomalies and the design considerations for production environments.







































![[DL輪読会]Generative Models of Visually Grounded Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20170602-170602005505-thumbnail.jpg?width=640&height=640&fit=bounds)












































