Download as PDF, PPTX


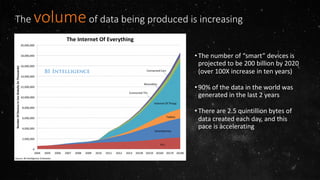



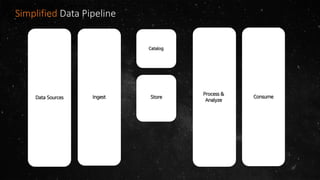
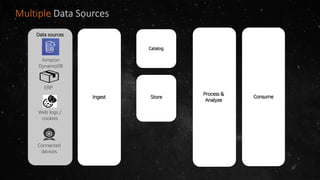

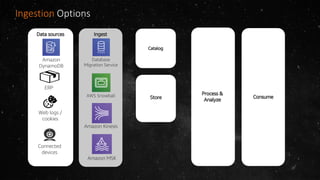


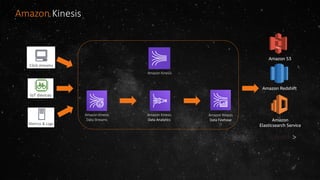
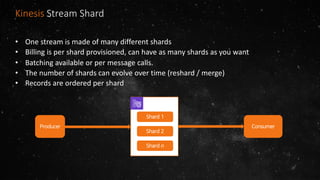
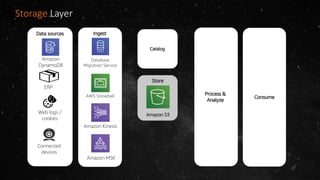

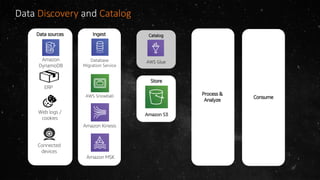

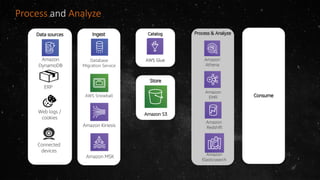

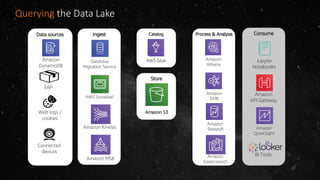

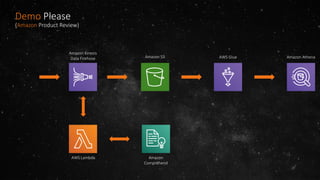
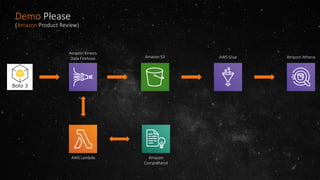



- The volume of data being produced is increasing exponentially, with 90% of all data generated in the last two years and 2.5 quintillion bytes created daily. - A data lake is a centralized repository that allows storing all structured and unstructured data at scale across different formats while supporting fast ingestion, querying, and consumption with schema defined during reading rather than writing. - AWS offers various services for ingesting, storing, processing, analyzing and querying data in the data lake including Amazon Kinesis for streaming data, Amazon S3 for storage, AWS Glue for data cataloging and ETL, Amazon Athena for interactive queries, and Amazon Redshift, EMR, and Elasticsearch for analytics.



















































































